啱啱,美團開源了他們的龍貓大模型LongCat-Flash。
一個擁有5600億參數的混合專家(MoE)模型。
它不僅在性能上追求卓越,更通過一系列架構和訓練上的創新,實現了驚人的計算效率和高級的Agent能力。
LongCat-Flash在保證強大能力的同時,將計算資源用在「刀刃」上。
它並非在處理每個任務時都激活全部5600億參數,而是通過精巧的設計,實現了動態的資源分配。
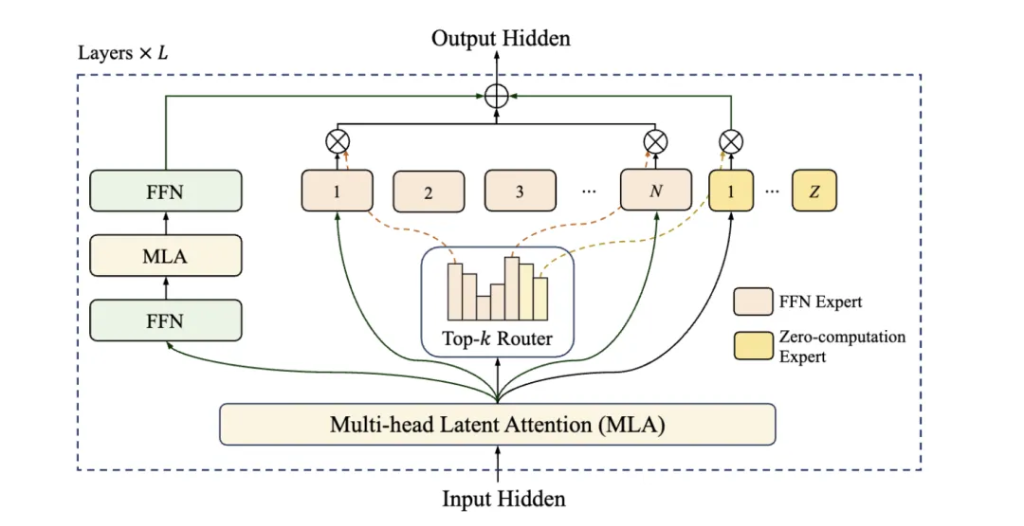
LongCat-Flash最具創新性的設計之一是 「零計算」專家機制 (Zero-computation Experts)
模型可以智能地判斷輸入內容中不同部分的重要性,並將計算量較小的任務(例如常見的詞語、標點符號)分配給一個特殊的「零計算」專家。
該專家不進行實際的複雜運算,直接返回輸入,從而極大地節省了算力。
得益於此,模型在處理每個詞元(token)時,僅需動態激活186億至313億的參數(平均約270億),實現了性能與效率的完美平衡。
在大規模MoE模型中,不同「專家」模塊之間的通信延遲往往是性能瓶頸。
為此龍貓大模型引入了快捷連接混合專家模型 (Shortcut-connected MoE, ScMoE)
ScMoE架構通過引入一個快捷連接,有效地擴大了計算和通信的重疊窗口,顯著提升了訓練和推理的吞吐量,讓模型的響應速度更快。
為了讓模型不僅能「聊天」,更能成為能解決複雜任務的「智能代理」,LongCat-Flash經歷了一個精心設計的 為Agent而生的多階段訓練流程。
該流程包括大規模預訓練、針對性地提升推理和代碼能力的中期訓練,以及專注於對話和工具使用能力的後訓練。
這種設計使其在執行需要調用工具、與環境交互的複雜任務時表現出色。
一個有趣且值得關注的細節是,在官方的技術報告中,強調了LongCat-Flash是在一個包含數萬個加速器(tens of thousands of accelerators)的大規模集群上完成訓練的。
這個用詞非常嚴謹。
在當前AI領域,雖然大家通常會立刻聯想到NVIDIA的GPU,但「加速器」是一個更廣泛的概念,它可以包括Google的TPU、華為的升騰(Ascend)或其他專為AI計算設計的芯片。
官方選擇使用這個詞彙,而沒有明確指出是「GPU」,這為硬件的具體來源留下了一定的想象空間,也體現了其在技術陳述上的精確性。
無論具體是哪種硬件,在如此龐大的集群上,於短短30天內完成超過20萬億詞元的訓練量,都足以證明其背後基礎設施的強大與工程優化的卓越。
LongCat-Flash的工程優化成果最終體現在了用戶可感知的性能和成本上:
極高的推理速度 :推理速度超過100詞元/秒(TPS)。
極低的運營成本 :每處理一百萬輸出詞元的成本僅為0.7美元。
強大的綜合能力 :支持128k的長文本上下文,並在代碼、推理和工具調用等多個方面展現出與業界領先模型相媲美的競爭力。
為了更直觀地展示 LongCat-Flash 的實力,我們來看一下它與業界其他頂尖模型的詳細評估對比。
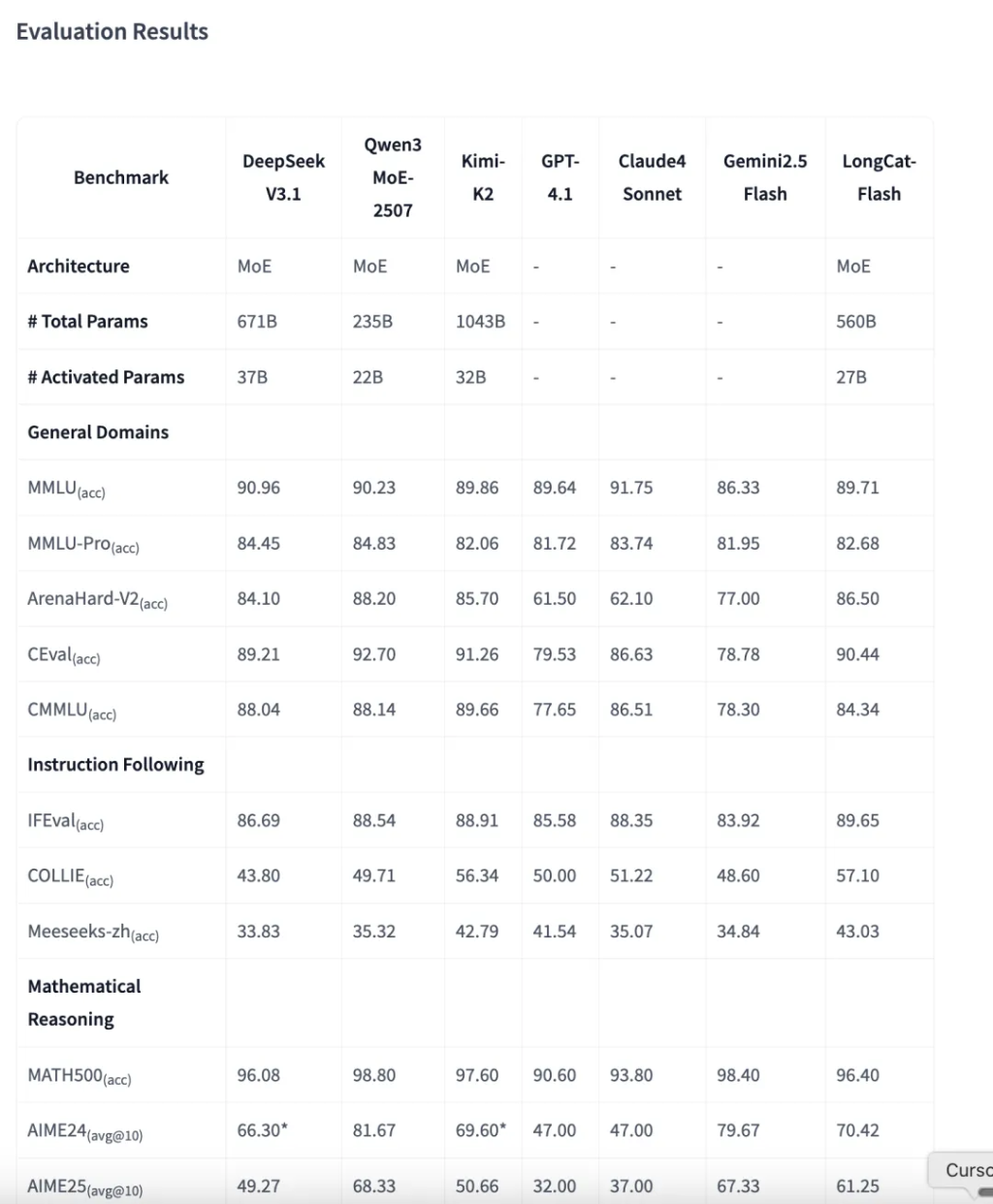
美團的 LongCat-Flash 模型在各項基準測試中展現出了非常強勁且極具競爭力的性能。
它不僅在多個方面與業界頂尖的開源模型(如 DeepSeek V3.1, Qwen3)旗鼓相當,甚至在某些特定能力上實現了超越。
通用領域能力 (General Domains) 在衡量模型通用知識和推理能力的測試中,LongCat-Flash 表現穩定且出色。
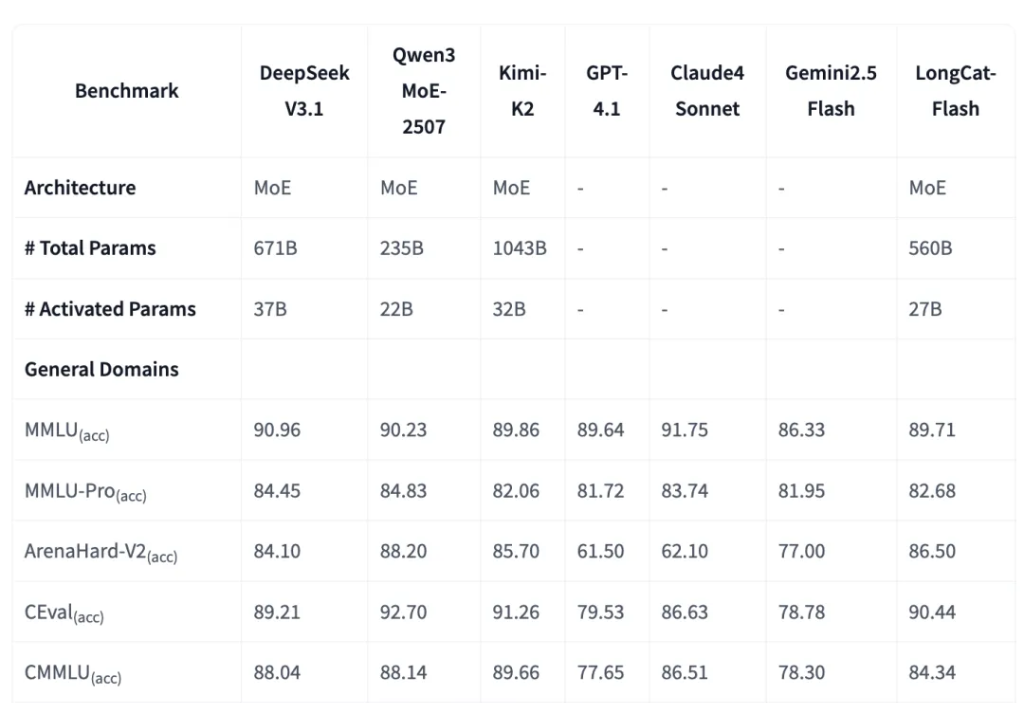
MMLU / MMLU-Pro :
這是衡量模型綜合知識水平的核心指標。
LongCat-Flash 的得分(89.71 / 82.68)與 DeepSeek V3.1、Qwen3 MoE 和 Kimi-K2 處於同一梯隊,證明了其紮實的基礎知識和推理能力。
ArenaHard-V2 :
這個基準更側重於模型作為聊天助手的「體感」和處理複雜指令的能力。LongCat-Flash 在此項得分 86.50 ,超過了 DeepSeek V3.1,與 Qwen3 MoE(88.20)非常接近,這說明它的對話和推理能力非常優秀。
中文能力 (CEval / CMMLU) :
作為中文領域的權威測試,LongCat-Flash 在 CEval 上表現優異(90.44),在 CMMLU 上也保持了不錯的水平,證明其對中文語言有很好的支持。
指令遵循(Instruction Following)這是 LongCat-Flash 最突出的亮點。
技術報告中提到,模型為「Agent」能力進行了專門的多階段訓練,而評估結果也印證了這一點。
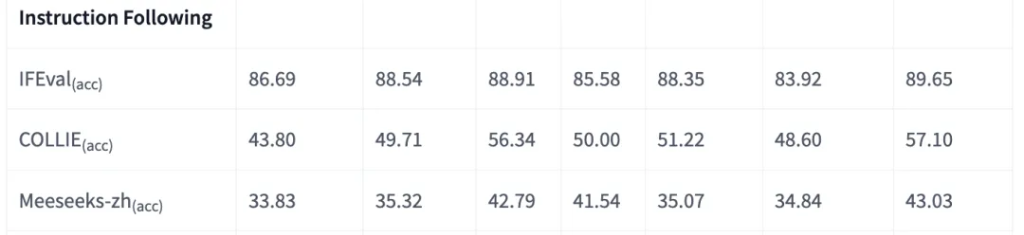
IFEval & COLLIE :
這兩個基準專門評估模型理解並執行復雜、多步驟指令的能力。
在 IFEval 上,LongCat-Flash 的得分(89.65)名列前茅,超越了 DeepSeek V3.1,與 Kimi-K2 和 Qwen3 MoE 並駕齊驅。
在 COLLIE 測試中,LongCat-Flash 取得了 57.10 的高分, 在所有參與對比的模型中排名第一 。
這強有力地證明了它在執行需要調用工具、與環境交互的複雜「智能代理」(Agent)任務方面的卓越能力。
目前,LongCat-Flash模型已經發布在Hugging Face和Githiub社區,並遵循MIT許可協議。
全球學術界和產業界的研究者、開發者都可以自由地使用和探索這個強大的模型,共同推動AI技術的發展。