周三,中概AI算力股拉升,金山雲一度升逾12%,萬國數據升逾6%,世紀互聯升逾5%。今天,小米開源首個為推理而生的大模型「Xiaomi MiMo」。
今天,小米開源首個為推理(Reasoning)而生的大模型「Xiaomi MiMo」,聯動預訓練到後訓練,全面提升推理能力。
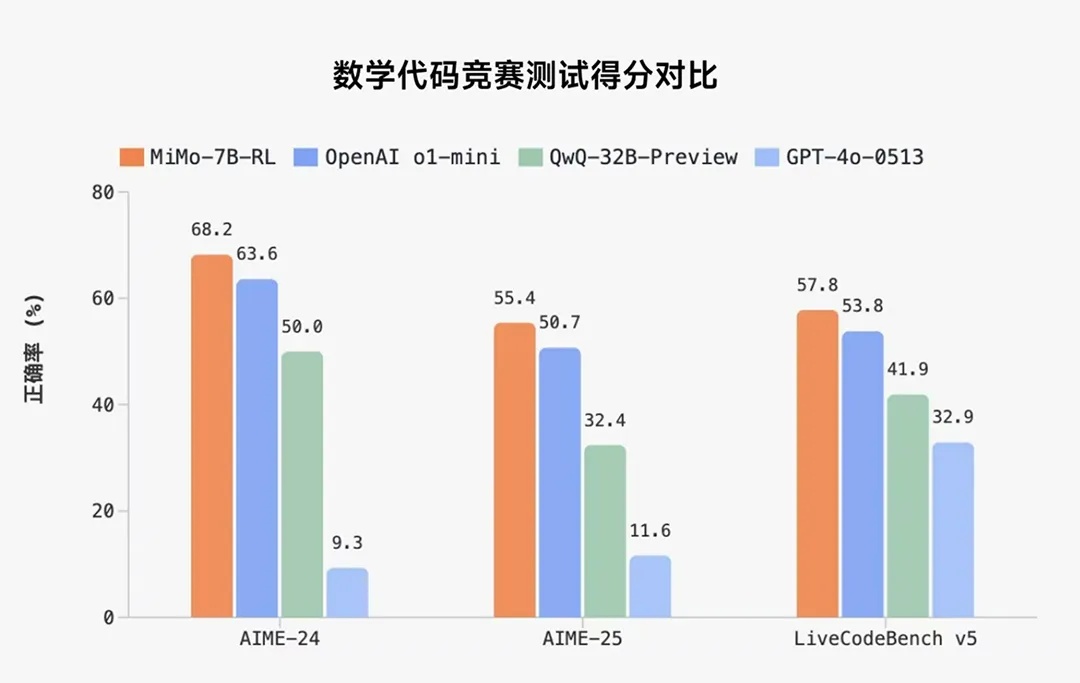
在數學推理(AIME 24-25)和 代碼競賽(LiveCodeBench v5)公開測評集上,MiMo 僅用 7B 的參數規模,超越了 OpenAI 的閉源推理模型 o1-mini 和阿里 Qwen 更大規模的開源推理模型 QwQ-32B-Preview。
強化學習潛力超越經典開源32B模型
隨着DeepSeek-R1引發業界強化學習(RL)共創潮,DeepSeek-R1-Distill-7B和Qwen2.5-32B已成為廣泛使用的強化學習起步模型。
在相同RL訓練數據情況下,MiMo-7B 的數學&代碼領域的強化學習潛力顯著領先。
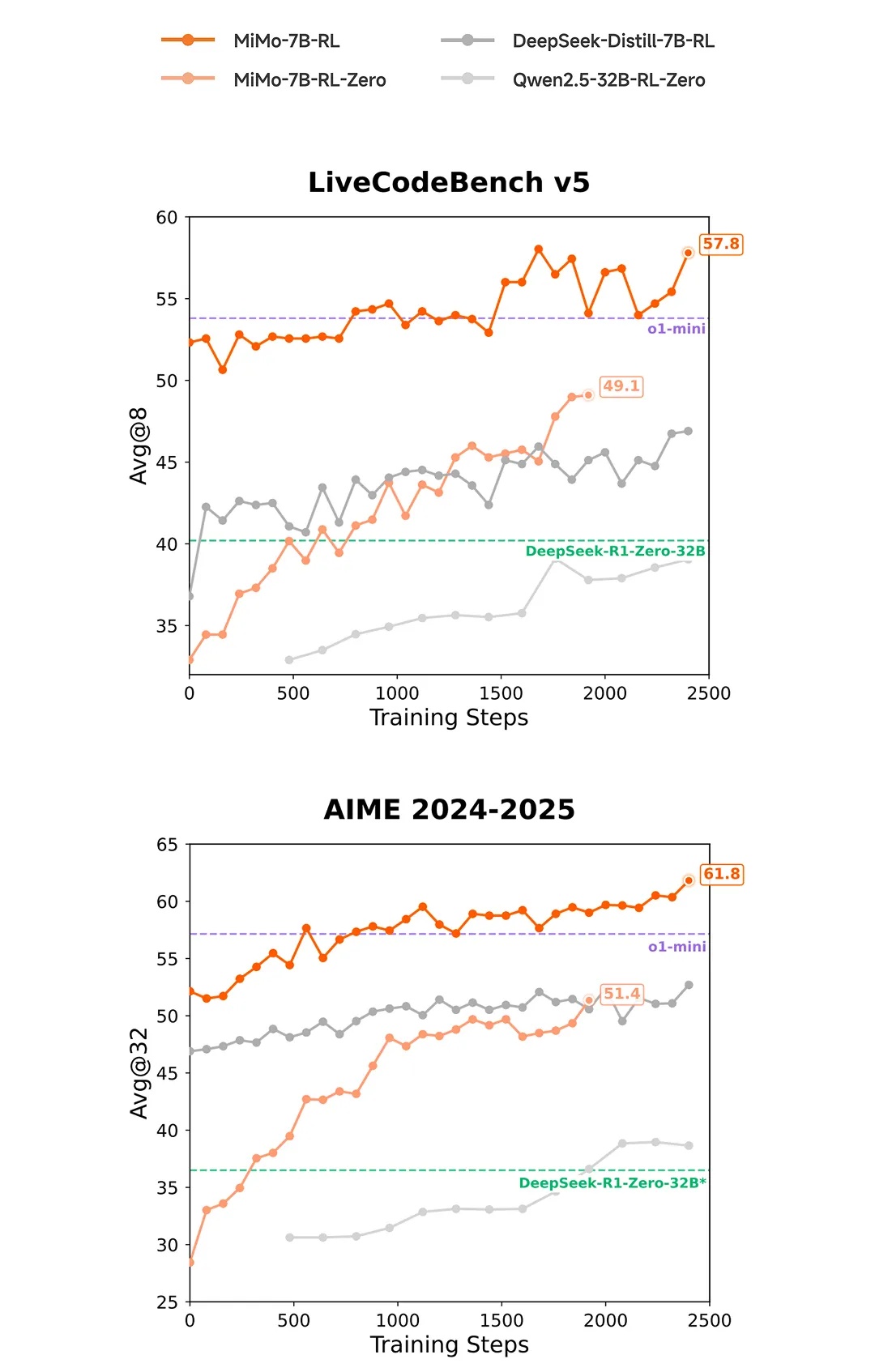
預訓練+後訓練,聯動提升推理能力
MiMo推理能力的提升,由預訓練和後訓練階段中數據和算法等多層面的創新聯合驅動,包括:
預訓練:核心是讓模型見過更多推理模式
數據:着重挖掘富推理語料,併合成約200B tokens推理數據。
訓練:進行了三階段訓練,逐步提升訓練難度,總訓練25T tokens。

後訓練:核心是高效穩定的強化學習算法和框架
算法:提出 Test Difficulty Driven Reward 來緩解困難算法問題中的獎勵稀疏問題,並引入 Easy Data Re-Sampling 策略,以穩定 RL 訓練。
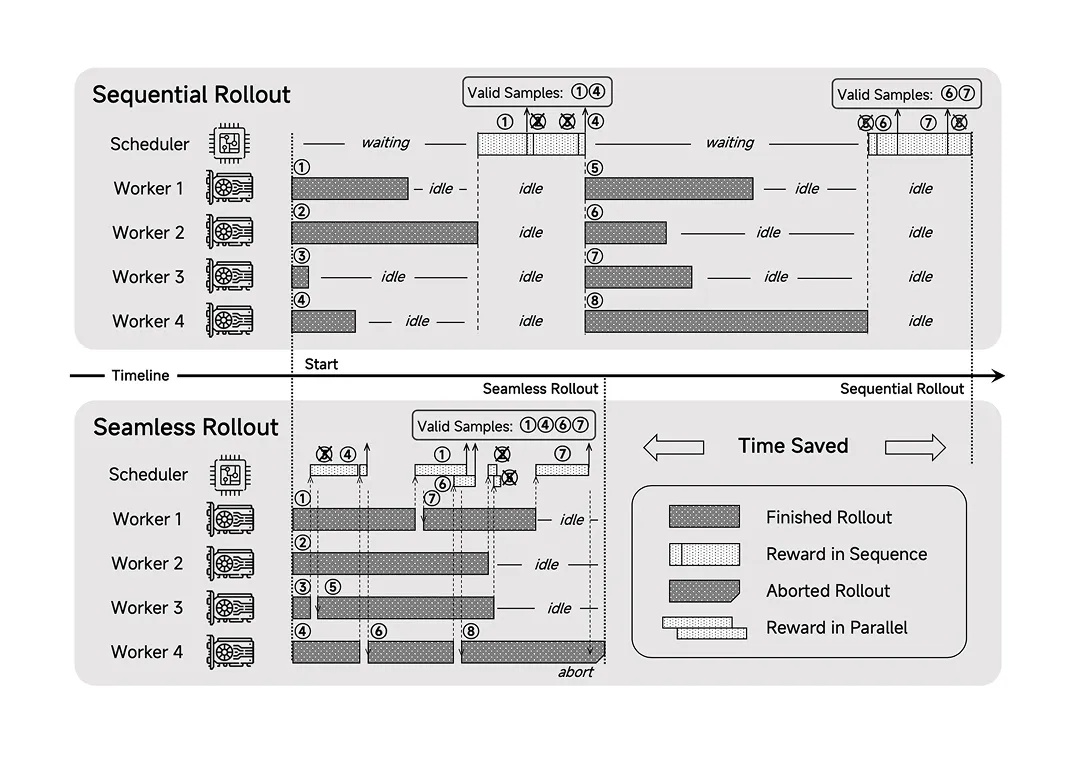
框架:設計了Seamless Rollout系統,使得RL訓練加速2.29倍,驗證加速1.96倍。