導讀:去GPU化的浪潮,已經攔不住了!OpenAI嫌英偉達太慢,Anthropic砸1486億投奔TPU,老黃被迫200億天價收購「叛徒」自救。如今,算力軍備賽正式進入能效為王的新時代:誰先卡住「每焦耳每微秒」的極限,誰或許就是下一個十年的霸主。
再過兩周,黃仁勳將站上GTC 2026的舞台。
他提前放了話:「我們準備了幾款世界上前所未見的全新芯片。」
底氣來自一份炸裂的成績單——
英偉達2026財年年收入2159億美元,淨利潤翻倍,數據中心業務三年翻了13倍。
在財報電話會上,CFO直接甩出一個數字:客戶已經部署了9吉瓦的Blackwell基礎設施!

但詭異的一幕出現了。
財報發布當晚,英偉達盤後一度升逾4%。隨後股價悄然轉跌,次日直接低開低走,收跌5.46%,一夜蒸發數千億美元市值。
華爾街不是看不懂數字,是看懂了趨勢。
前有Anthropic甩出210億美元訂單,全面採購基於谷歌TPU的算力系統;後有Meta跟谷歌簽下數十億美元芯片大單,大規模租用TPU訓練模型。
為了給編程帶來接近實時的響應體驗,OpenAI更是歷史上首次將主力級產品GPT-5.3-Codex-Spark,部署在了更低延遲與更低能耗的非GPU芯片Cerebras上。
英偉達最大的幾個客戶,正在集體分散籌碼。
")
根據摩根大通的產能報告,谷歌計劃在2027年部署600至700萬顆TPU,大部分供給Anthropic、OpenAI、Meta和蘋果等外部客戶。
高盛投資研究部的模型顯示,全球AI服務器中非GPU芯片出貨佔比,將從2024年的36%升至2027年的45%。
類似的,IDC也預測,到2028年,中國非GPU服務器市場規模佔比將逼近50%。
GPU的致命短板
一個更深層的轉折正在發生:AI的競爭焦點,正從單純的算力規模,轉向對能效比與延遲的極致追求。
過去拼誰卡多、誰集羣大。
現在拼的是,同樣花一塊錢,誰能吐出更多Token。
「每美元產生的Token數」正在取代峯值算力,成為衡量芯片商業價值的核心指標。
究其原因在於,GPU的架構決定了,每次計算時數據都要在外部顯存和計算單元之間來回搬運。
路徑長、次數多,能耗就高、延遲就大。堆更多卡解決不了這個問題。
路透社爆料,OpenAI已多次表達對英偉達芯片的「不滿」——響應速度沒達預期,在代碼生成產品Codex上感受尤為明顯。
壓力迫使英偉達這條「巨龍」尋求改變。
圖靈獎得主David Patterson教授在最新研究中指出,大模型每次token生成都繞不開數據搬運,而搬運能耗遠高於計算本身。
未來的核心命題是「讓數據離計算更近」。
為此,他給出了三個AI芯片的演進方向:近內存處理、3D堆疊、低延遲互連。
實際上,這些都指向同一件事——用架構創新降低數據搬運的能耗和延遲。
換句話說就是,誰能用更低的能耗、更低的延遲跑通下一代模型,誰就能在未來十年的算力牌桌上佔得先機。
谷歌TPU殺向商用市場
一直以來,谷歌TPU專供自家大模型訓練和推理,外人用不到。
去年開始,谷歌把TPU推向了商用。
訂單隨即湧入。
博通CEO透露,Anthropic下了210億美元的大單;Meta簽下數十億美元TPU租賃協議;潛在客戶還包括蘋果和已與SpaceX合併的xAI。
原因不難理解。大模型進入規模化落地階段,算力需求爆發、成本壓力加劇,單一依賴GPU的瓶頸越來越明顯。而谷歌TPU的性能,已經具備與頂級GPU分庭抗禮的實力。
2025年推出的第七代TPU,是谷歌迄今為止性能最高、可擴展性最強的AI芯片——
單芯片峯值算力4614 TFLOPS(FP8精度),最大集羣9216顆芯片、總算力達42.5 EFLOPS。
劃重點:TPU v7在同等算力輸出下功耗僅為英偉達B200的40%至50%。
不僅如此,谷歌自研的光電路交換機(OCS)技術,還讓萬卡級集羣實現近乎線性的加速比。相比之下,傳統GPU集羣規模越大,通信損耗越嚴重;而TPU集羣基本不喫這個虧。

谷歌TPU崛起還有更為直接的例證:在TPU上訓練的Gemini 3,在多個權威基準測試中位居榜首,為業界頂尖模型之一。
回到成本賬上。
TPU憑藉AI專用架構帶來的2-4倍能效優勢,將大模型推理的綜合成本相比GPU拉低50%以上。而這正是Anthropic、Meta們用訂單投票的根本邏輯。
當下,大多數大模型企業已經在用TPU+GPU的組合來緩解成本壓力。
去年11月,半導體研究機構SemiAnalysis對比大模型公司的採購成本後發現:與OpenAI相比,同時使用TPU與GPU的Anthropic,在與英偉達談判時擁有更強的議價權。
手裏有TPU,就多了一張跟老黃討價還價的牌。未來頭部AI公司大概率都會走「多芯片並行」路線。

性能跨越式提升,頂尖大模型規模化驗證,頭部公司主動佈局——TPU已從算力產業的補充路線,升級為主流路線。
英偉達一家獨大的格局,正在被改寫。
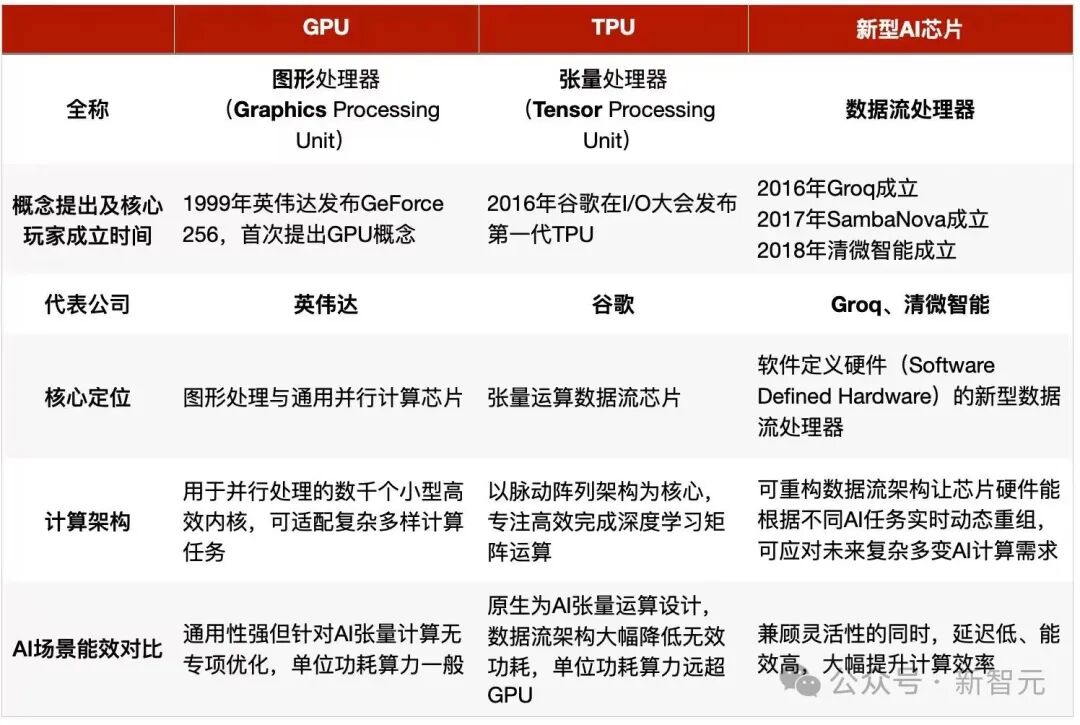
十年磨一劍
「TPU之父」要造下一代AI芯片
2025年底,英偉達斥資200億美元,拿下AI芯片創企Groq的核心技術和團隊。
這是英偉達史上最大的一筆交易,溢價近三倍。
Groq創始人Jonathan Ross,被稱為「TPU之父」,谷歌TPU的核心設計者之一。離開谷歌後,他創立Groq的目標很明確:做一顆超越谷歌TPU的芯片。
兩者的差異在架構。
谷歌TPU走的是「固定架構+集羣擴展」路線。
其中,芯片內部搭載固定計算單元,依託二維數據流運算;芯片間通過3D Torus拓撲實現高效互聯。架構穩定,但靈活性有限。

Groq的TSP(Tensor Streaming Processor)則是一種「軟件定義硬件」的數據流處理器。
其核心理念是,通過構建可重構的軟硬件系統,在保持可編程性的同時,達到接近ASIC的極致性能。
具體來說,芯片內部做了功能切片化微架構設計,配合軟件層的靈活配置,可根據不同任務實時調整計算邏輯和數據流路徑。
同時,依託大容量片上SRAM及靜態調度機制,顯著提升了數據訪存效率並降低搬運能耗。
美國DARPA「電子復興計劃」(ERI)高度看好「軟件定義硬件」方向,將其列為國家級戰略核心。這也是Groq被稱為「高階TPU」的原因。
數據顯示,在相同推理任務中,Groq芯片首token延遲比谷歌TPU v7降低20%至50%,每token成本降低10%至30%。
這場芯片革命,纔剛開始加速
Groq被收編,但「高階TPU」的進化沒停。
國內清微智能、海外Cerebras等公司正在高效數據流動態配置和先進集成方式上持續突破。
1. 通過3D Chiplet技術構建三維立體數據流架構。
具體來說,「計算核心+3D DRAM芯粒」的組合在垂直與水平兩個維度上形成了高效的數據流計算模式,突破了傳統二維架構的效率侷限。
三維架構可以依據計算任務的需求和數據特性,在兩個維度上靈活調度數據流,最大化縮短傳輸路徑,降低搬運過程中的延遲與能耗,從而進一步提升整體計算效率。
2. 依託算力網格技術構建靈活數據流計算範式。
傳統固定組網存在擴展性和語義適配瓶頸。而算力網格技術則可以通過靈活組網,實現Scale up與Scale out的協同。
根據AI任務特性,系統能實時下發數據流的動態配置信息,在多種互聯拓撲結構間靈活切換、精準調度。最終降低互聯延遲,充分釋放數據流架構的算力。
3. 通過前沿的晶圓級芯片技術,將數據流架構的優勢發揮到極致。
這項技術將數據流架構從芯片尺度擴展到整片晶圓。
在整張晶圓上高密度集成大量計算核心,計算核心間的互聯距離被極大縮短。帶來的結果是,互聯帶寬實現數量級提升,通信延遲大幅降低。
數據流架構的算力規模與計算效能由此被推到極致。這也是為什麼晶圓級芯片被視為數據流計算架構的理想物理載體。
以Cerebras為例。
數據顯示,Cerebras CS 3系統推理性能比英偉達旗艦DGX B200快21倍,成本與功耗均降低三分之一,在算力、成本、能效上展現出顯著的綜合優勢。
在實測中,OpenAI的Codex-Spark跑出了每秒超1000 token的生成速度,讓代碼編寫第一次有了實時交互的體驗。

GPU獨霸的時代,回不去了
谷歌TPU走出圍牆,OpenAI擁抱晶圓級芯片,英偉達天價收編Groq。
這些信號均指向同一個方向:TPU已變成巨頭們真金白銀押注的主戰場。
算力世界的單極時代,正在被多元架構終結。
決定下一代AI天花板的,不是算力堆砌的軍備競賽,而是能耗、延遲、確定性共同構成的新指標。
對國產芯片來說,這場變局既是機遇也是挑戰。 跟隨者只能分殘羹,走出自己的底層創新之路,纔有資格參與下一輪全球算力洗牌。