阿里巴巴近期在AI領域展現出的「日更級」開源節奏和多項大模型技術突破,標誌着中國AI產業正在以一種全新的姿態參與全球競爭。這不僅僅是一項技術層面的突破,更是一場關於技術主權、生態重構和全球化競爭的戰略博弈。從技術參數到開源策略,從商業邏輯到產業應用,中國企業正在改寫全球AI版圖。
近一周,中國AI的速度與激情正在上演。
阿里巴巴一口氣連發四個開源模型,包括Qwen3系列Qwen3-235B-A22B-Instruct基礎模型、Qwen3-Coder、Qwen3-235B-A22B推理模型和通義萬相Wan2.2。「開源」、「登頂」等關鍵詞頻頻出現,「日更級」的節奏更是令世界瞠目結舌。
7月22日,阿里開源Qwen3-235B-A22B-Instruct,性能獲得基礎模型領域冠軍,成為 「全球最智能的非思考基礎模型」。
7月23日,阿里開源AI編程模型Qwen3-Coder,代碼能力及Agent調用能力超越GPT4.1、Claude4等頂尖閉源模型,登頂全球最大開源社區HuggingFace模型總榜冠軍。
7月25日,阿里開源千問3推理模型性能比肩頂級閉源模型Gemini2.5 pro,斬獲推理模型的全球開源冠軍。
7月28日,阿里開源視頻生成模型通義萬相Wan2.2,共開源文生視頻、圖生視頻和統一視頻生成三款模型。
密集的技術迭代和突破,阿里用實際成果打破了「閉源模型是高性能代名詞」的固有認知,重新定義開源模型的天花板。
技能突破:性能與開源的雙重飛躍
短短四天時間,阿里三款開源模型Qwen3-235B-A22B-Instruct基礎模型、Qwen3-Coder、Qwen3-235B-A22B推理模型,分別在基礎模型、編程模型、推理模型等主流領域登上全球開源冠軍寶座。
Qwen3-235B非思考模式基礎模型的「天花板」突破,僅需4張H20顯卡即可部署2350億參數模型,顯存佔用僅為同類模型1/3,推理速度提升1.8倍,在GPQA、AIME25、Arena-Hard等任務中更是一舉擊敗Claude4(Non-thinking)等閉源模型,這種「非思考模式」的優化,可能為需要高速推理的場景,如實時對話、自動化處理等提供更高效的解決方案。
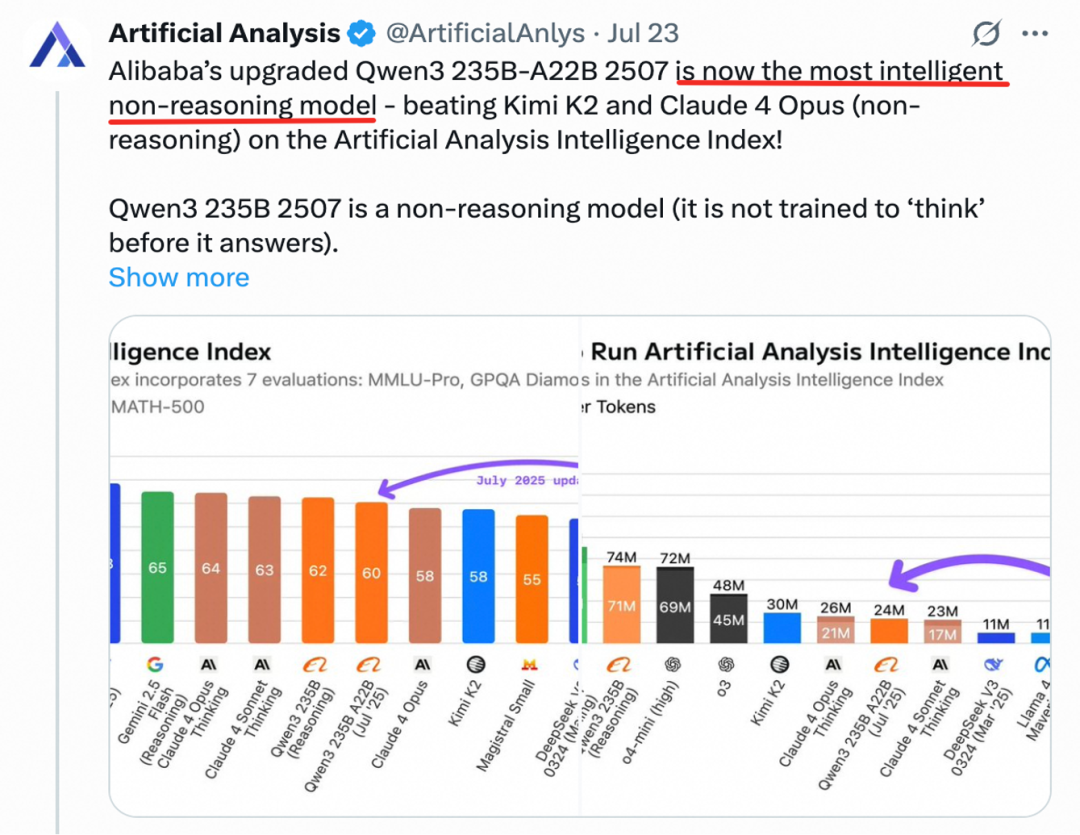
△圖:AI研究機構Artificial Analysis:「千問3是全球最智能的非思考基礎模型」
同樣,推理與視頻生成的「全能型」佈局,阿里AI正在加速覆蓋從文本到多模態的全鏈路能力。Qwen3-235B-A22B推理模型和通義萬相Wan2.2的開源,它可以支持處理256K上下文超長文本,解決複雜推理任務的能力顯著提升,在知識、邏輯推理、數學、編程、人類偏好對齊、創意寫作、多語言能力等任務中表現可比肩Gemini-2.5 Pro、o4-mini等頂級閉源模型。
通義萬相Wan2.2此次共開源文生視頻(Wan2.2-T2V-A14B)、圖生視頻(Wan2.2-I2V-A14B)和統一視頻生成(Wan2.2-TI2V-5B)三款模型,其中文生視頻模型和圖生視頻模型均為業界首個使用MoE架構的視頻生成模型,總參數量為27B,激活參數14B,均由高噪聲專家模型和低噪專家模型組成,分別負責視頻的整體佈局和細節完善,在同參數規模下,可節省約50%的計算資源消耗,有效解決視頻生成處理Token過長導致的計算資源消耗大問題,同時在複雜運動生成、人物交互、美學表達、複雜運動等維度上也取得了顯著提升。尤其文生視頻、圖生視頻的開源,有望加速AIGC在影視、廣告等行業的落地。
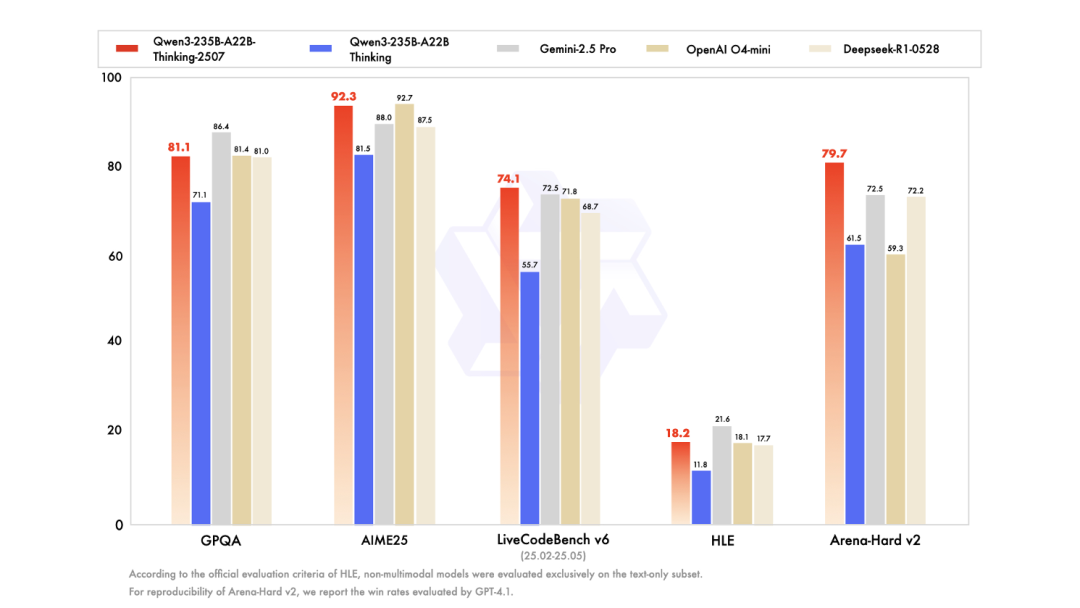

△圖:通義萬相圖
Qwen3-Coder編程模型更是直接帶來了AI編程能力的顛覆性競爭,首次將混合專家(MoE)架構引入編程模型,激活參數達35B,支持256K token上下文擴展至1M。在多語言SWE-bench、Mind2Web、Aider-Polyglot等模型Agent能力評估中,Qwen3-Coder超越GPT4.1、Claude4等頂級閉源模型,可幫助程序員實現「一句話生成3D物理模擬代碼」、「5分鐘搭建品牌官網」,大幅降低編程門檻。這一突破直接衝擊了閉源模型與開源模型在編程領域的分工邊界,成為全球開發者社區的「爆款」。

Qwen3-Coder編程模型發布之後,迅速登頂全球最大AI開源社區HuggingFace模型總榜冠軍,在全球AI圈掀起熱潮。推特創始人傑克·多爾西(Jack Dorsey)、爆火Agent應用Perplexity CEO 阿拉溫德·斯里尼瓦斯(Aravind Srinivas)、著名風投公司a16z合夥人馬克·馬斯克羅(Marco Mascorro)等硅谷大咖們紛紛盛讚編程模型Qwen3-Coder,HuggingFace CEO克萊門特·德朗格(Clement Delangue)更是連轉帶發12條推文,向全球開發者力薦這一最好的編程模型。
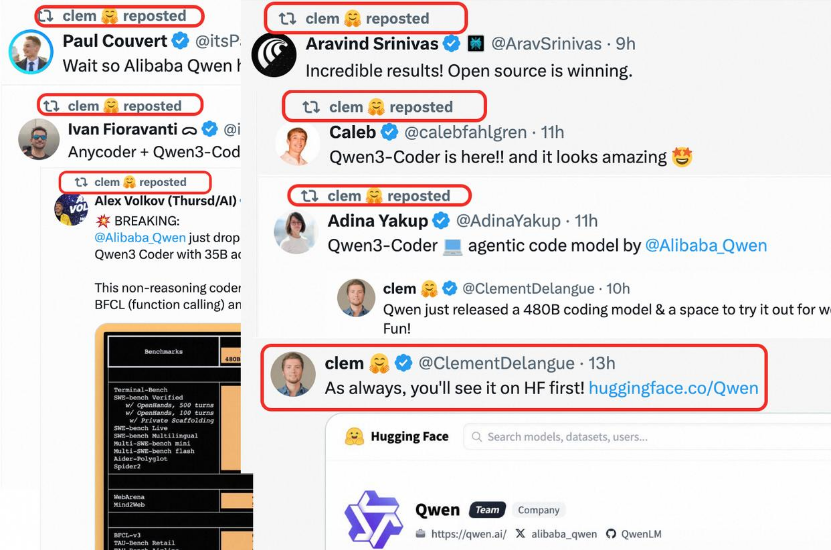
△圖:HuggingFace CEO Clement Delangue連發12條推文盛讚Qwen3-Coder
開源生態:從「技術普惠」到「生態鎖定」
阿里AI編程模型發布之後,一位硅谷工程師把月付200美元的Claude Code一鍵卸載,只因為GitHub上「突然出現中國開源的AI編程模型「,不僅性能追平GPT-4,還把上下文拉到100萬Token。
模型不僅「性價比高」,而且「還聽勸」,Qwen團隊也被AI圈譽為開發者們的「有求必應」、「開源懂帝」,「開發者需要什麼,千問團隊就開源什麼。」例如此前Qwen3-235B非思考模型的推出,正式Qwen團隊接受了開發者的建議,Qwen團隊曾在X平台上寫道:「經過與社區溝通和深思熟慮,我們決定停止使用混合思考模式,相反,我們將分別訓練Instruct和Thinking模型,以獲得最佳質量。 」
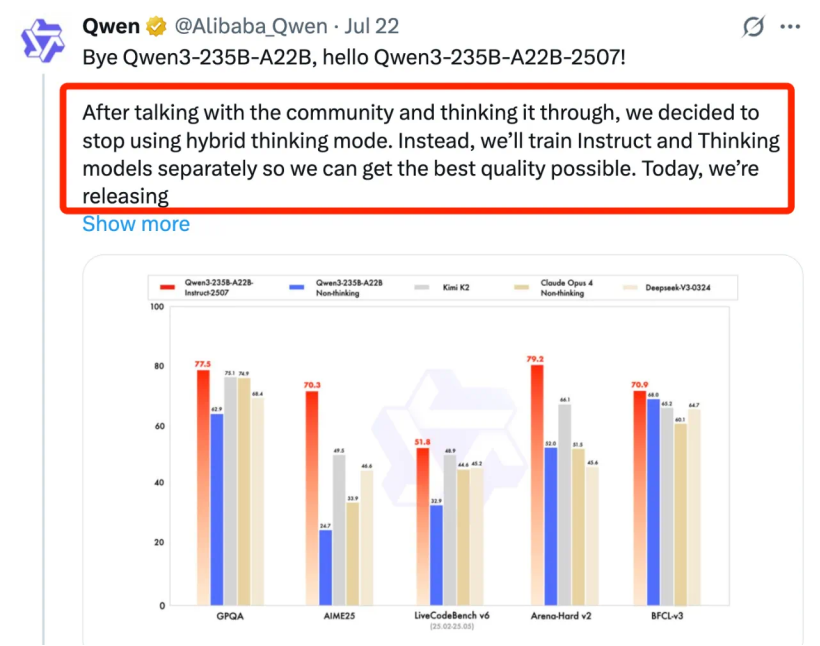
大規模參數模型的開源,降低了開發者和中小企業的使用成本,吸引更多的參與者加入。生態參與者們無需再支付高昂的授權費,即可使用頂級模型。
對於阿里而言,開源不僅僅是「技術共享」,而是通過開源模型構建技術標準,通過雲計算及企業服務實現商業化。這種「以開放換生態、以生態鎖雲端」的策略,既推動技術普惠,又促進了技術商業化價值的轉化。
通過魔搭社區、全球開源社區HuggingFace雙平台及全鏈路生態支持,阿里構建起一個跨語言、跨場景、跨行業的全球開發者生態。一方面,全球開源社區可以吸引更多的國際開發者一起貢獻代碼、優化模型;另一方面魔搭社區提供模型體驗、微調、部署服務,促進更多場景化落地,最終形成從模型開源、生態繁榮到技術反哺的良性循環。
同時,開源模型的廣泛使用也帶來技術的加速迭代。不久前,李飛飛團隊曾基於Qwen開源模型訓練出s1-32B,性能媲美頂尖推理模型;取得了與 OpenAI 的 o1 和 DeepSeek 的 R1 等尖端推理模型數學及編碼能力相當的效果,甚至在競賽數學問題上的表現比 o1-preview 高出 27%。同樣,在開源紅利下,杭州創業團隊開發的PolyGlot同傳工具,端到端延遲僅420ms,遠超傳統70B模型。這種「開放協作」模式,正在卷積形成中國AI的全球影響力。
從追趕到定義規則 中國企業重塑全球AI競爭格局
短短一周,阿里AI重新點燃了中國科技公司的AI敘事浪潮,技術迭代的寬度和深度直追當下全球最頂級的AI玩家。
一方面,阿里始終保持敏捷的研發速度,研發的模型覆蓋「全尺寸」、「全模態」、「多場景」,順應AI在不同時期的不同特點,快速迭代,滿足開發者和應用企業的需求;另一方面,阿里始終將開源作為AI發展的重要理念,幾乎所有模型均是第一時間研發成功,就第一時間對外開源,讓全球開發者和企業最快最好地用上最先進的模型,真正踐行了「技術民主」的開源本質。

過去十六年,阿里長期堅定地投入雲計算和AI技術,發展成為全球少數具備全棧AI能力的企業,成為目前中國唯一同時在基礎設施和模型研發上具備全球一流能力的平台。從分佈式計算、自研芯片、大模型到行業應用,全棧AI的垂直整合將AI能力快速落地產業鏈的核心環節,促進技術迭代和生態發展。
這種「開源平權」與「全棧整合」的結合,可能為中國乃至全球AI產業開闢了一條不同於閉源路線的路徑。通過多快好省的訓練,「性能+成本」的雙重碾壓,中國的開源模型從本質上動搖了閉源模型的定價權,引發了AI從閉源主導到開源主導的新一輪變革,而中國企業在這一變革中的主動出擊,或將重塑全球AI技術的競爭格局。
7月28日消息,全球知名的大模型API三方聚合平台OpenRouter公布了最新一期排行榜,來自中國的DeepSeek和阿里通義千問躋身全球前五。其中,來自阿里的通義千問以10.4%的市場份額,超越OpenAI的4.7%,位列第四。
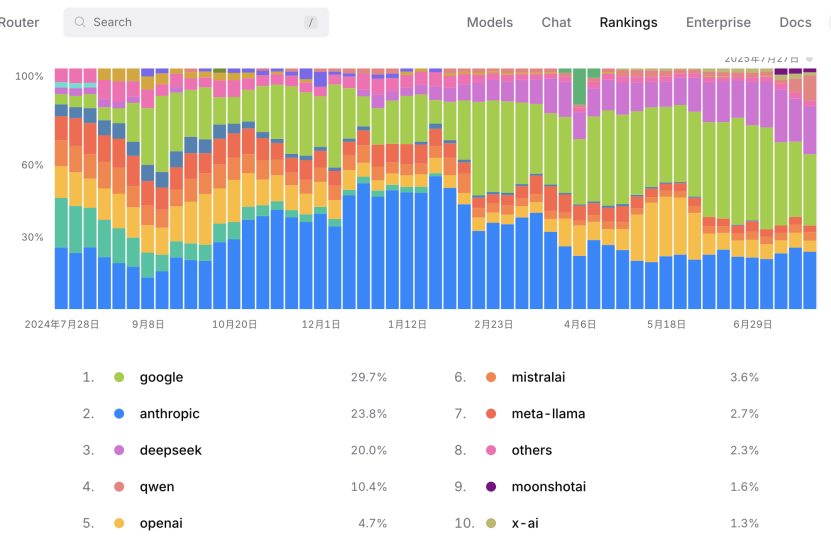
目前,阿里千問在全球主要模型社區的下載量已經突破4億,衍生模型突破14萬個,超越Meta的Llama系列成為全球第一的開源模型家族,千問也是全球開發者和企業使用最廣泛的大模型,已有30多萬中國企業和機構接入通義大模型,如中國一汽、聯想、國家天文台等,覆蓋金融、製造、科研等領域。未來三年,阿里將投入3800億持續雲和AI基礎設施建設,將開源作為長期戰略。
阿里AI加速佈局的背後,是一場關於未來的技術戰役。隨着AI技術從「工具」進化為「基礎設施」, 這場戰役的勝負,將決定中國在AI時代的全球地位。