有媒體援引知情人士透露的消息報道稱,「AI芯片超級霸主」英偉達(NVDA.US)的最強勁競爭對手之一——人工智能芯片供應商Cerebras Systems Inc.正在商討進行一輪大約10億美元的新孖展,以支持這家AI芯片初創公司與英偉達之間的長期競爭態勢,並且力爭大幅強化該公司AI算力集羣相比於英偉達AI GPU集羣的性價比與能效比。
這位知情人士表示,這一輪孖展將在投資前將這家初創公司的估值定在220億美元,意味着較去年9月進行孖展時的估值大幅擴張170%。因為討論尚屬私下,該人士要求不具名。該知情人士還表示,這家AI芯片初創公司仍計劃積極推進在美股的首次公開募股(IPO)。
在首席執行官安德魯·費爾德曼(Andrew Feldman)的帶領之下,Cerebras Systems 正積極尋求挑戰英偉達在人工智能芯片領域的高達90%市場份額的絕對市場主導地位,因此這輪孖展也勢必將為尋求挑戰全球最頂級人工智能算力基礎設施供應商英偉達主導地位的這家AI芯片公司帶來新的一輪資金支持。
向英偉達下戰書的Cerebras Systems是何方神聖?
Cerebras Systems 有着無比宏大的「人工智能雄心壯志」。首席執行官安德魯·費爾德曼稱,其公司算力硬件運行人工智能大模型的實際效率是英偉達系統的數倍。除了提供實體算力集羣,他領導的這家AI芯片明星初創公司還積極向Facebook母公司Meta Platforms Inc.、有着「藍色巨人」稱號的美國老牌科技公司IBM以及有着「歐洲OpenAI」稱號的Mistral AI等大型客戶們提供遠程人工智能計算服務。
該公司的最新估值較9月的投資輪大幅上升,當時Cerebras Systems 的估值僅僅約為81億美元。在那之後不久,英偉達與AI芯片初創公司,同時也是Cerebras Systems競爭對手之一的Groq簽署了一項重要許可協議,並收購了該AI芯片公司的大部分芯片設計人才,這也大舉提振了投資者們對於人工智能芯片領域的看漲熱情。
英偉達前不久與AI芯片初創公司Groq達成的200億美元非獨家授權合作協議,將其AI推理技術授權給英偉達,並且在交易完成後Groq創始人及核心研發團隊將加入英偉達,可謂共同凸顯出隨着「全球AI推理大浪潮」全面來襲,疊加谷歌TPU AI算力集羣帶來的越來越大競爭壓力,英偉達力爭通過「多架構AI算力+鞏固CUDA生態+引進更多AI芯片設計人才」來維持其在AI芯片領域高達90%市場份額的絕對主導權,並且英偉達欲以Groq+以色列AI初創公司AI21 Labs連下關鍵兩子鎖住AI全棧話語權。
與被英偉達「拿下」之前的Groq類似,Cerebras Systems 被視為英偉達在AI芯片領域最強勁的競爭對手之一,尤其是在AI推理(inference)這一快速增長的細分藍海市場。Cerebras 的技術路線與英偉達AI GPU算力體系以及谷歌TPU(AI ASIC技術路線)都截然不同,它採用 「晶圓級引擎」(Wafer‑Scale Engine, WSE) 架構,將整個AI模型放在單個超大芯片上,從而極大提升了推理性能和內存帶寬,在單位推理量上實現更高的能效比,並且避免了GPU集羣之間的數據拆分和高速通信開銷這一重大瓶頸。
不同於英偉達、博通與AMD等芯片巨頭聚焦於尺寸較小的高性能芯片,再通過台積電獨家的chiplet先進封裝進行芯片集成封裝整合,Cerebras Systems製造了一個能夠覆蓋整個硅晶圓的超級大型芯片。Semianalysis等半導體研究機構的分析指出,這樣的晶圓級架構在處理大型語言模型推理任務時可以實現比傳統AI GPU/AI ASIC更強勁的性能密度和能效比例。
另一家同樣有志成為英偉達最強競爭對手之一的初創公司Etched據知人士透露,在一輪新的孖展中籌集了大約5億美元,使得估值來到約50億美元。
值得注意的是,Cerebras Systems 在很大程度上依賴總部位於阿布扎比的人工智能公司G42的業務,這一深度合作關係已引起美國外國投資委員會(Committee on Foreign Investment in the US)的審查,可能導致IPO進程持續受阻。
AI推理大浪潮全面來襲,Cerebras Systems欲緊抓這股大勢
從最近的市場動態來看,Cerebras Systems 確實正在利用 AI 推理這股大浪潮積極佈局,並通過孖展與推動 IPO 來增強自身競爭力,爭取不斷蠶食英偉達的高達90%這一無比龐大市場份額。Cerebras 的持續孖展進程與IPO推進共同反映出該AI芯片初創公司希望借 AI 推理浪潮擴大市場影響、增強競爭力、挑戰英偉達的意圖。
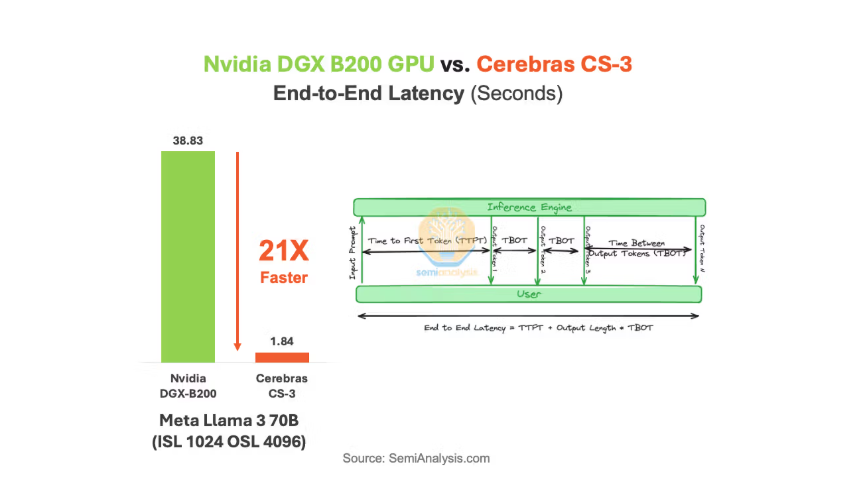
Cerebras 最新的 CS‑3 系統(搭載 WSE‑3 芯片) 在多個公開對比中,被報告在大型語言模型推理場景下可以達到遠高於英偉達最新GPU體系——Blackwell架構AI GPU的性能。根據Cerebras自己的對比數據,CS‑3 在運行如 Llama 3 70B 推理任務時比Blackwell架構的 B200 AI GPU 系統快約21倍,同時總體成本和能耗更低(包括硬件與電力消耗成本);第三方分析也指出,一些高參數的推理基準任務中,Cerebras 的輸出吞吐量(tokens/sec)多倍於傳統GPU,有報道提到在某些模型推理中速度可以達到比GPU快20倍或更多。
在大規模推理領域, 特別是處理大型LLMs時,Cerebras 的WSE‑基架構在性價比(成本/性能比) 與 能效比(能耗/推理輸出比) 上可謂全面顯示出相較於英偉達 GPU算力集羣的顯著優勢。這些優勢主要來源於其晶圓級單片設計、極高帶寬和推理吞吐能力。但這種優勢更顯著於特定推理場景,而非覆蓋所有AI計算任務,在通用計算任務部署、AI訓練算子以及CUDA生態兼容性方面,英偉達仍具備很大優勢。
英偉達AI GPU幾乎壟斷的AI訓練側需要更加強大的AI算力集羣通用性以及整個算力體系的快速迭代能力,而AI推理側則在前沿AI技術規模化落地後更看重單位token成本、延遲與能效。谷歌明確把Ironwood定位為「為AI推理時代而生」的TPU代際,並強調性能/能效/算力集羣性價比與可擴展性。
當AI推理算力體系成為全球科技企業長期現金成本中心,客戶們更願意在雲上選擇更划算更具性價比的AI ASIC加速器。有媒體曾報道OpenAI通過谷歌雲平台Google Cloud大規模租用TPU(谷歌TPU屬於AI ASIC技術路線),核心動機之一就是降低AI推理成本——這是來自TPU競爭壓力上升的最典型案例。
根據Semianalysis測算數據,谷歌最新的TPU v7 (Ironwood) 展現出了驚人的代際跨越,TPU v7的BF16算力高達4614 TFLOPS,而上一代被廣泛使用的TPU v5p僅為459 TFLOPS,這堪稱是整整一個數量級的提升。此外,TPU v7顯存直接對標英偉達Blackwell架構的 B200,針對特定AI應用場景,架構上更具性價比與能效比優勢的AI ASIC可以更容易地喫下主流推理端算力負載,比如TPU甚至能提供比英偉達Blackwell高出1.4倍的每美元性能。
當前超大規模AI推理需求正呈現每六個月翻一番的極速增長趨勢,因此在AI推理大浪潮席捲而來以及谷歌TPU帶來的愈發強大競爭壓力的算力需求背景下,英偉達通過Groq拿到推理芯片思路與頂尖人才、並通過AI21補軟件與模型側能力,屬於典型的「硬件技術路線多元化 + AI應用生態端到端綁定」防守/反擊。
英偉達與AI芯片初創公司Groq的交易本質是非獨佔推理類AI芯片技術授權 + 吸納Groq創始人/CEO Jonathan Ross等高管與部分核心工程團隊,一些半導體行業分析師也強調Groq的獨家芯片技術專注推理並用片上SRAM等方式降低數據搬運瓶頸,可謂直指推理階段的成本/延遲痛點。