多年來,領先的人工智能公司一直堅稱,只有擁有龐大計算資源的公司才能推動前沿研究,這強化了這樣一種觀點:除非你擁有數十億美元的基礎設施投入,否則「不可能趕上」。但 DeepSeek 的成功卻講述了一個不同的故事:新穎的理念可以帶來效率上的突破,從而加速人工智能的發展;規模更小但更專注的團隊可以挑戰行業巨頭,甚至創造公平的競爭環境。
我們認為,DeepSeek 的效率突破預示着AI 應用需求的激增。如果 AI 要繼續發展,就必須降低總體擁有成本 (TCO) ——通過擴大替代硬件的覆蓋範圍、最大限度地提高現有系統的效率以及加速軟件創新。否則,未來 AI 的效益將面臨瓶頸——要麼是硬件短缺,要麼是開發者難以有效利用現有的各種硬件。
過去 25 年來,我一直致力於為世界釋放計算能力。我創立並領導了LLVM的開發,LLVM 是一項編譯器技術,它為 CPU 在編譯器技術的新應用領域打開了大門。如今,LLVM 已成為 C++、Rust、Swift 等性能導向型編程語言的基礎。它支持幾乎所有 iOS 和 Android 應用,以及 Google 和 Meta 等主要互聯網服務的基礎設施。
這項工作為我在蘋果領導的幾項關鍵創新鋪平了道路,包括創建OpenCL(一個早期的加速器框架,現已被整個行業廣泛採用)、使用LLVM重建蘋果的CPU和GPU軟件堆棧,以及開發Swift編程語言。這些經歷強化了我對共享基礎設施的力量、軟硬件協同設計的重要性,以及直觀、開發者友好的工具如何釋放先進硬件的全部潛力的信念。
2017 年,我開始着迷於 AI 的潛力,並加入 Google,領導 TPU 平台的軟件開發。當時,硬件已經準備就緒,但軟件尚未投入使用。在接下來的兩年半時間裏,通過團隊的共同努力,我們在 Google Cloud 上推出了 TPU,並將其擴展到每秒百億億次浮點運算 (ExaFLOPS),並構建了一個研究平台,促成了Attention Is All You Need和BERT等突破性成果。
然而,這段旅程也揭示了人工智能軟件更深層次的問題。儘管 TPU 取得了成功,但它們仍然僅與 PyTorch 等人工智能框架半兼容——谷歌憑藉巨大的經濟和研究資源克服了這個問題。一個常見的客戶問題是:「TPU 能開箱即用地運行任意人工智能模型嗎?」真相是?不能——因為我們沒有 CUDA,而 CUDA 是人工智能開發的事實標準。
我並非迴避解決行業重大問題的人:我最近的工作是創建下一代技術,以適應硬件和加速器的新時代。這包括 MLIR 編譯器框架(目前已被整個行業廣泛採用的 AI 編譯器),以及我們團隊在過去 3 年中構建的一些特別的東西——但我們稍後會在合適的時機分享更多相關信息。
由於我的背景和在業界的人脈,我經常被問及計算的未來。如今,無數團隊正在硬件領域進行創新(部分原因是NVIDIA 市值飆升),而許多軟件團隊正在採用 MLIR 來支持新的架構。與此同時,高層領導們也在質疑,為什麼儘管投入了大量資金,AI 軟件問題仍然懸而未決。挑戰並非缺乏動力或資源。那麼,為什麼這個行業會感到停滯不前呢?
我不認為我們陷入了困境。但我們確實面臨着一些棘手的基礎性問題。
為了向前發展,我們需要更好地理解行業底層動態。計算是一個技術含量極高的領域,發展迅速,充斥着各種術語、代號和新聞稿,旨在讓每一款新產品都聽起來具有革命性。許多人試圖撥開迷霧,只見樹木不見森林,但要真正理解我們的發展方向,我們需要探究其根源——那些將一切聯繫在一起的基本構件。
首先,我們將以一種簡單易懂的方式回答這些關鍵問題:
CUDA 到底是什麼?
CUDA 為何如此成功
️CUDA 真的好嗎?
為什麼其他硬件製造商難以提供可比的 AI 軟件?
為什麼 Triton、OneAPI 或 OpenCL 等現有技術還沒有解決這個問題?
作為一個行業,我們該如何向前發展?
我希望本文能夠激發有意義的討論,並提升人們對這些複雜問題的理解。人工智能的快速發展——例如 DeepSeek 最近的突破——提醒我們,軟件和算法創新仍然是推動行業發展的動力。對底層硬件的深入理解繼續帶來 「10 倍」 的突破。
人工智能正以前所未有的速度發展,但仍有諸多潛力有待挖掘。讓我們攜手突破,挑戰固有認知,推動行業發展。讓我們一起深入探索!
CUDA究竟是什麼
似乎在過去一年裏,每個人都開始談論 CUDA:它是深度學習的支柱,是新型硬件難以與之競爭的原因,也是英偉達護城河與市值飆升的核心。
DeepSeek 的出現讓我們有了驚人的發現:它的突破是通過 「繞過」 CUDA、直接進入 PTX 層實現的…… 但這究竟意味着什麼呢?似乎每個人都想打破這種技術鎖定,但在制定計劃之前,我們必須先了解自己面臨的挑戰。
CUDA 在人工智能領域的主導地位不可否認,但大多數人並不完全理解 CUDA 究竟是什麼。有人認為它是一種編程語言,有人稱它是一個框架。許多人認為它只是 「英偉達用來讓 GPU 運行更快的東西」。這些說法並非完全錯誤,也有很多傑出人士試圖解釋它,但沒有一種能完全涵蓋 「CUDA 平台」 的全貌。
CUDA 並非單一事物,它是一個龐大的分層平台,是一系列技術、軟件庫和底層優化的集合,共同構成了一個大規模的並行計算生態系統。它包括:
一種底層並行編程模型,開發者可以用類似 C++ 的語法利用 GPU 的原始計算能力。
一套複雜的庫和框架,這些中間件支持人工智能等關鍵垂直應用場景(例如用於 PyTorch 和 TensorFlow 的 cuDNN 庫 )。
像 TensorRT-LLM 和 Triton 這樣的高級解決方案,它們能在不需要開發者深入了解 CUDA 的情況下,支持人工智能工作負載(例如大語言模型服務)。
而這只是冰山一角。
在本章節中,我們將深入剖析 CUDA 平台的關鍵層級,探究其發展歷程,並解釋它為何對如今的人工智能計算如此重要。這為我們系列文章的下一部分內容奠定了基礎,屆時我們將深入探討 CUDA 如此成功的原因。提示:這與其說是技術本身的原因,不如說和市場激勵因素有很大關係。
讓我們開始吧!
CUDA 發展之路:從圖形處理到通用計算
在 GPU 成為人工智能和科學計算的強大引擎之前,它們只是圖形處理器,是專門用於渲染圖像的處理器。早期的 GPU 將圖像渲染功能硬編碼在硅芯片中,這意味着渲染的每個步驟(變換、光照、光柵化)都是固定的。雖然這些芯片在圖形處理方面效率很高,但缺乏靈活性,無法用於其他類型的計算。
2001 年,英偉達推出 GeForce3,這一切發生了改變。GeForce3 是第一款帶有可編程着色器的 GPU,這在計算領域是一次重大變革:
在此之前:固定功能的 GPU 只能應用預定義的效果。
在此之後:開發者可以編寫自己的着色器程序,解鎖了可編程圖形管線。
這一進步伴隨着 Shader Model 1.0 的推出,開發者可以編寫在 GPU 上執行的小程序,用於頂點和像素處理。英偉達預見到了未來的發展方向:GPU 不僅可以提升圖形性能,還能成為可編程的並行計算引擎。
與此同時,研究人員很快就提出了疑問:「如果 GPU 能運行用於圖形處理的小程序,那我們能否將其用於非圖形任務呢?」
斯坦福大學的 BrookGPU 項目是早期對此進行的重要嘗試之一。Brook 引入了一種編程模型,使 CPU 能夠將計算任務卸載到 GPU 上,這一關鍵理念為 CUDA 的誕生奠定了基礎。
這一舉措具有戰略意義且極具變革性。英偉達沒有把計算當作一項附帶實驗,而是將其列為首要任務,將 CUDA 深度融入其硬件、軟件和開發者生態系統中。
CUDA 並行編程模型
2006 年,英偉達推出 CUDA(統一計算設備架構),這是首個面向 GPU 的通用編程平台。CUDA 編程模型由兩部分組成:「CUDA 編程語言」 和 「英偉達驅動程序」。
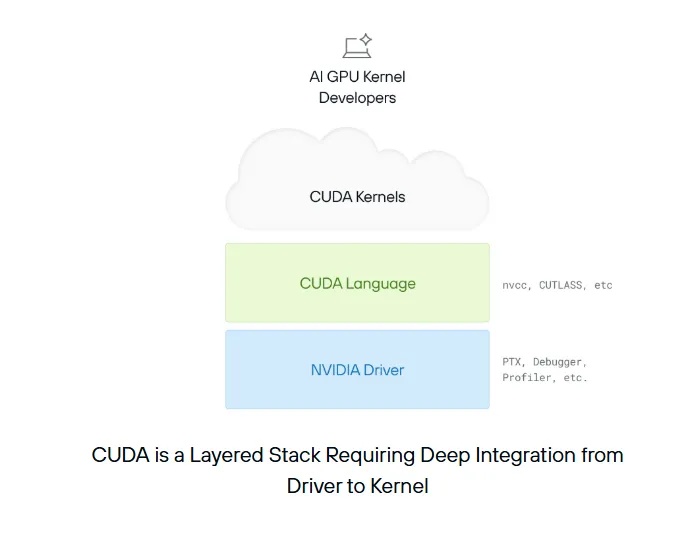
CUDA 是一個分層堆棧,需要從驅動程序到內核的深度集成
CUDA 語言源自 C++,並進行了擴展,以直接暴露 GPU 的底層特性,例如 「GPU 線程」 和內存等概念。程序員可以使用該語言定義 「CUDA 內核」,這是一種在 GPU 上運行的獨立計算任務。下面是一個非常簡單的示例:

CUDA 內核允許程序員定義自定義計算,這些計算可以訪問本地資源(如內存),並將 GPU 用作高速並行計算單元。這種語言會被翻譯成 「PTX」,PTX 是一種彙編語言,是英偉達 GPU 支持的最低級接口。
但是程序究竟如何在 GPU 上執行代碼呢?這就要用到英偉達驅動程序了。它充當 CPU 和 GPU 之間的橋樑,負責處理內存分配、數據傳輸和內核執行。以下是一個簡單示例:

請注意,這些操作都非常底層,充滿了繁雜的細節(如指針和 「幻數(magic numbers)」)。如果出現錯誤,通常會以難以理解的程序崩潰形式提示。此外,CUDA 還暴露了許多英偉達硬件特有的細節,例如 「warp 中的線程數」(這裏暫不深入探討)。
儘管存在這些挑戰,但這些組件讓整整一代硬核程序員能夠利用 GPU 強大的計算能力來解決數值問題。例如,2012 年 AlexNET 點燃了現代深度學習的火種。它之所以能夠實現,得益於用於卷積、激活、池化和歸一化等人工智能操作的自定義 CUDA 內核,以及 GPU 提供的強大算力。
雖然大多數人聽到 「CUDA」 時,通常想到的是 CUDA 語言和驅動程序,但這遠不是 CUDA 的全部,它們只是其中的一部分。隨着時間的推移,CUDA 平台不斷發展,涵蓋的內容越來越多,而最初的首字母縮寫詞(CUDA)已經無法準確描述其全部意義。
高級 CUDA 庫:讓 GPU 編程更易上手
CUDA 編程模型為通用 GPU 計算打開了大門,功能強大,但它帶來了兩個挑戰:
CUDA 使用難度較大。
更糟糕的是,CUDA 在性能可移植性方面表現不佳。
為第 N 代 GPU 編寫的大多數內核在第 N + 1 代 GPU 上仍能 「繼續運行」,但性能往往較差,遠達不到第 N + 1 代 GPU 的峯值性能,儘管 GPU 的優勢就在於高性能。這使得 CUDA 成為專業工程師的有力工具,但對大多數開發者來說,學習門檻較高。這也意味着每次新一代 GPU 推出時(例如現在新出現的 Blackwell 架構),都需要對代碼進行大量重寫。
隨着英偉達的發展,它希望 GPU 對那些在各自領域是專家,但並非 GPU 專家的人也有用。英偉達解決這一問題的方法是開始構建豐富而複雜的閉源高級庫,這些庫抽象掉了 CUDA 的底層細節,其中包括:
cuDNN(2014 年推出)—— 加速深度學習(例如卷積、激活函數運算)。
cuBLAS—— 優化的線性代數例程。
cuFFT—— 在 GPU 上進行快速傅里葉變換(FFT)。
以及許多其他庫。
有了這些庫,開發者無需編寫自定義 GPU 代碼就能利用 CUDA 的強大功能,英偉達則承擔了為每一代硬件重寫這些庫的工作。這對英偉達來說是一項巨大的投資,但最終取得了成效。
cuDNN 庫在這一過程中尤為重要,它為谷歌的 TensorFlow(2015 年推出)和 Meta 的 PyTorch(2016 年推出)鋪平了道路,推動了深度學習框架的興起。雖然此前也有一些人工智能框架,但這些是首批真正實現規模化應用的框架。現代人工智能框架中包含數千個 CUDA 內核,每個內核都極難編寫。隨着人工智能研究的爆發式增長,英偉達積極擴展這些庫,以涵蓋重要的新應用場景。

CUDA 上的 PyTorch 建立在多層依賴關係之上
英偉達對這些強大的 GPU 庫的投入,使得全球開發者能夠專注於構建像 PyTorch 這樣的高級人工智能框架,以及像 HuggingFace 這樣的開發者生態系統。他們的下一步是打造開箱即用的完整解決方案,讓開發者完全無需了解 CUDA 編程模型。
全面的垂直解決方案助力AI和GenAI快速發展
人工智能的熱潮遠遠超出了研究實驗室的範疇,如今它無處不在。從圖像生成到聊天機器人,從科學發現到代碼助手,生成式人工智能(GenAI)在各個行業蓬勃發展,為該領域帶來了大量新應用和開發者。
與此同時,出現了一批新的人工智能開發者,他們有着截然不同的需求。在早期,深度學習需要精通 CUDA、高性能計算(HPC)和底層 GPU 編程的專業工程師。如今,一種新型開發者(通常稱為人工智能工程師)在構建和部署人工智能模型時,無需接觸底層 GPU 代碼。
為了滿足這一需求,英偉達不僅提供庫,還推出了交鑰匙解決方案,將底層的一切細節都抽象掉。這些框架無需開發者深入了解 CUDA,就能讓人工智能開發者輕鬆優化和部署模型。
Triton Serving—— 一種高性能的人工智能模型服務系統,使團隊能夠在多個 GPU 和 CPU 上高效運行推理。
TensorRT—— 一種深度學習推理優化器,可自動調整模型,使其在英偉達硬件上高效運行。
TensorRT-LLM—— 一種更專業的解決方案,專為大規模大語言模型(LLM)推理而構建。
以及許多(衆多)其他工具。

NVIDIA 驅動程序和 TensorRT-LLM 之間存在多個層
這些工具完全屏蔽了 CUDA 的底層複雜性,讓人工智能工程師能夠專注於人工智能模型和應用,而無需關注硬件細節。這些系統提供了強大的支持,推動了人工智能應用的橫向擴展。
整體的 「CUDA 平台」
CUDA 常被視為一種編程模型、一組庫,甚至僅僅是 「英偉達 GPU 運行人工智能所依賴的東西」。但實際上,CUDA 遠不止如此。它是一個統一的品牌,是一個真正龐大的軟件集合,也是一個經過高度優化的生態系統,所有這些都與英偉達的硬件深度集成。因此,「CUDA」 這個術語含義模糊,我們更傾向於使用 「CUDA 平台」 這一表述,以明確我們所談論的更像是 Java 生態系統,甚至是一個操作系統,而不僅僅是一種編程語言和運行時庫。

CUDA 的複雜性不斷擴大:涵蓋驅動程序、語言、庫和框架的多層生態系統
從核心來看,CUDA 平台包括:
龐大的代碼庫:經過數十年優化的 GPU 軟件,涵蓋從矩陣運算到人工智能推理的所有領域。
廣泛的工具和庫生態系統:從用於深度學習的 cuDNN 庫到用於推理的 TensorRT,CUDA 涵蓋了大量的工作負載。
針對硬件優化的性能:每次 CUDA 發布都會針對英偉達最新的 GPU 架構進行深度優化,確保實現頂級效率。
專有且不透明:當開發者與 CUDA 的庫 API 交互時,底層發生的很多操作都是閉源的,並且與英偉達的生態系統緊密相連。
CUDA 是一套強大且龐大的技術體系,是整個現代 GPU 計算的軟件平台基礎,其應用甚至超越了人工智能領域。
CUDA平台的演進史,實為一部軟硬件協同進化的史詩——從可編程着色器的萌芽到萬億級AI生態的崛起,英偉達用二十年時間構築起層層嵌套的技術護城河。這座由數億行優化代碼堆砌的巴別塔,既成就了深度學習革命的算力基石,也暴露出行業深陷路徑依賴的隱憂。DeepSeek繞過CUDA直抵PTX層的突破,猶如刺破雲層的閃電,揭示了一個關鍵真相:當硬件創新進入深水區,軟件棧的範式革命可能比晶體管密度更具顛覆性。
當前AI競賽的本質,早已超越單純算力的軍備較量,演變為生態系統重構權的爭奪。正如LLVM曾打破編譯器的壟斷格局,MLIR等新一代基礎設施正悄然重塑計算範式。行業的真正瓶頸不在於芯片的物理極限,而在於如何構建開放、可移植的創新土壤——這要求我們以更底層的思維解構CUDA神話,在編譯器、中間件與開發者體驗的交叉點上尋找突破口。歷史的經驗反覆印證:每一次計算民主化的浪潮,終將由那些敢於跳出既有框架、用算法效率對沖硬件鴻溝的顛覆者引領。此刻,我們正站在算力平權時代的門檻上,答案或許就藏在軟件與硬件的縫隙之間。