今天上午,英偉達創始人CEO黃仁勳在COMPUTEX 2025開講。這場演講的核心信息可以概括為:英偉達正在從AI淘金熱的「賣鏟子」角色,全面升級為新工業革命中「智能工廠」的設計師與關鍵基石提供者。
黃仁勳的演講要點及關鍵發布呈現在幾點:
1.計算的終極形態:「人工智能工廠」——生產「智能token」的基礎設施革命
黃仁勳將現代數據中心比作「人工智能工廠」,這是對計算基礎設施本質的全新定義。他認為,如同第一次工業革命需要電力基礎設施,信息時代需要互聯網,智能時代則需要「智能基礎設施」。AI工作負載的特性(需要大規模並行和東西向通信)使得整個數據中心必須作為一個統一的計算單元運作。
發布:
Blackwell/GB200/GB300系統: 這些是AI工廠的核心生產線。黃仁勳宣佈基於Blackwell的GB300系統將於今年Q3全面投產,推理性能提升1.5倍,HBM內存和網絡帶寬也大幅增加。他通過生動的圖示和視頻,展現了GB200系統如何通過NVLink骨幹網(帶寬130 TB/s,超越整個互聯網峯值流量)將72個GPU整合成一個巨大的虛擬GPU,實現「極端的摩爾定律」式性能飛躍(6年4000倍)。
2.智能的普適應用:AI智能體——企業和個人的數字勞動力
AI已從感知、生成能力進化到具備推理、使用工具、協同工作的「自主智能」,即AI智能體。這些智能體將成為「數字勞工」,極大地緩解全球勞動力短缺,變革各行各業的工作方式。
發布:
RTX Pro 企業級與 Omniverse 服務器: 專為在企業環境中運行AI智能體而設計。這些服務器兼容傳統x86應用和虛擬機,但更重要的是,它們提供了強大的計算能力(搭載RTX Pro 6000s GPU和CX8網絡芯片,800 Gbps帶寬),可以運行文本、圖形乃至視頻模態的AI代理。這標誌着AI智能體開始進入傳統的企業IT架構核心。
NVIDIA AI數據平台 / IQ / Nemo: 為智能體提供理解和利用企業非結構化數據的能力。IQ(查詢系統)提供快速語義搜索,Nemo Retriever/IQ藍圖開源。這是AI智能體「理解」世界的基石。
AIOps: 新的軟件層,幫助企業IT部門管理、部署、微調AI代理,將其視為「數字勞動力」進行運營。
3.智能的實體化:物理AI與機器人——數字孿生驅動的再工業化
下一波AI浪潮將是「物理AI」,能夠理解現實世界的物理規律,並進入物理載體——機器人中。機器人需要通過在遵守物理定律的虛擬世界(數字孿生)中學習來掌握技能。
發布:
Newton 物理引擎: 與DeepMind、迪士尼合作開發的、可用於高保真模擬機器人行為的物理引擎。將於7月開源,支持GPU加速和微分學習。這是構建機器人訓練場的關鍵軟件。
Isaac Groot 平台: 英偉達為通用機器人打造的端到端平台,包括:
Jetson Thor: 全新的機器人處理器,提供強大的嵌入式計算能力。
NVIDIA ISAAC OS: 機器人的運行時操作系統。
Isaac Groot N1.5模型創建方式: 已開源, enabling 開發者基於此構建機器人AI模型。
Groot Dreams: 基於Cosmos模型,利用AI放大少量人類示範數據,大規模生成合成訓練數據,解決機器人訓練數據難題,實現「Real-to-Real」學習。
Omniverse與數字孿生: 再次強調Omniverse作為構建數字孿生的平台,並展示了合作伙伴利用數字孿生進行工廠規劃、生產線優化、機器人訓練的案例。指出數字孿生是驅動全球5萬億美元新工廠建設和再工業化的核心工具。
4.生態的擴展與開放:NVLink Fusion——賦能定製化AI基礎設施
認識到AI基礎設施的多樣性需求,英偉達正變得更加開放,允許夥伴構建半定製的AI系統,同時仍受益於英偉達的核心技術。
發布:
NVLink Fusion: 允許合作伙伴將自己的CPU或ASIC(通過NVLink芯片間接口和芯片組)集成到英偉達的NVLink互聯架構中,與英偉達GPU協同工作,構建靈活的AI基礎設施。這標誌着英偉達在關鍵互聯技術層面的戰略性開放。
廣泛的合作伙伴生態: 展示了與衆多芯片設計公司(LCHIP, Astera Labs, Marvell, 聯發科, 富士通, 高通, Cadence, Synopsys)、系統製造商(富士康, 緯創, 廣達, 戴爾, 華碩, 技嘉, 惠與, 超微等)和軟件/服務提供商(VAST, Dell, Hitachi, IBM, NetApp, CrowdStrike, DataIQ, DataRobots, DataStacks, Elastic, Nutanix, Red Hat, Trend Micro等)的深度合作,共同構建從硬件到軟件的全棧生態。
面向開發者的新硬件:
DGX Spark: 面向個人AI開發者的桌面級AI超級計算機(千萬億次浮點運算,128GB HBM),已全面投產。
DGX Workstation: 更大型的個人工作站,可運行萬億參數模型。
黃仁勳明確指出,AI已經催生了一個全新的萬億美元級基礎設施產業——「人工智能工廠」,英偉達正致力於提供從底層芯片(Blackwell/GB300)、高速互聯(NVLink)、系統平台(DGX系列、RTX Pro)、軟件棧(CUDA庫、IQ、AIOps、Isaac平台、Omniverse)到生態系統協作的全方位解決方案。智能體將成為數字世界的基石,而物理AI和數字孿生將驅動實體經濟的智能化再造。通過NVLink Fusion等策略,英偉達在鞏固核心優勢的同時,擁抱生態開放,賦能全球夥伴共同參與這場計算革命。
=以下是Web3天空之城圖文全文版=

很高興來到這裏。我的父母也在觀衆席中,他們在那裏。
英偉達在這裏已經超過30年了。這裏是我們許多珍貴合作伙伴和親愛朋友的家。多年來,你們見證了英偉達的成長,也見證了我們完成了許多激動人心的成就,並一路與我合作。
今天,我們將討論我們在行業中所處的位置、我們將要去的地方,並宣佈一些新產品,令人激動和令人驚喜的產品,這些產品將為我們打開新的市場,創造新的市場、新的增長。我們將討論偉大的合作伙伴,以及我們將如何共同發展這個生態系統。
衆所周知,我們正處於計算機生態系統的中心,這是世界上最重要的行業之一。因此,當需要創造新的市場時,我們必須從這裏開始創造,這是理所當然的,位於計算機生態系統的中心。而且我為你們準備了一些驚喜,一些你們可能猜不到的事情。
當然,我保證我會談論人工智能和機器人技術。
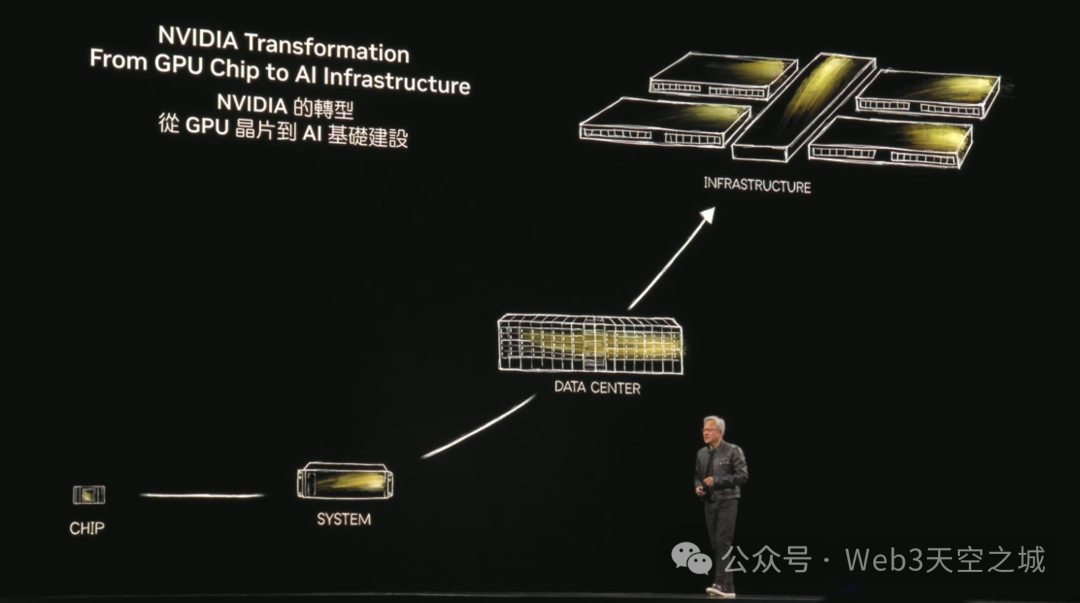
英偉達的故事是計算機產業的重塑。事實上,英偉達的故事也是我們公司的重塑。正如我所說,我已經來了30年了,你們中的許多人都經歷過我的多次主題演講,你們中的一些人,全部都經歷過。回顧這次對話,以及我們過去30年所談論的內容,變化是如此巨大。
我們最初是一家芯片公司,目標是創建一個全新的計算平台。在2006年,我們推出了CUDA,它徹底改變了計算的方式。
10年後的2016年,我們意識到一種新的計算方法已經到來。這種新的計算方法需要對技術堆棧的每一層進行徹底的改造。處理器是全新的,軟件堆棧是全新的,因此,系統也必然是全新的。
所以我們發明了一個新的系統。一個在我2006年在GTC大會上宣佈它的那天,沒有人理解我在說什麼,也沒有人給我下采購訂單的系統,叫做DGX-1。
DGX-1,我將第一台捐贈給了一個叫做OpenAI的非營利性公司,它開啓了人工智能革命。
幾年後,我們意識到,事實上,這種新的軟件開發方式,現在被稱為人工智能,與傳統的軟件運行方式不同。許多應用程序都在大型數據中心的少量處理器上運行,我們稱之為超大規模。這種新型應用程序需要多個處理器協同工作,為數百萬人的查詢提供服務。並且該數據中心的架構將從根本上不同。我們意識到有兩種類型的網絡。
一條用於南北向流量,因為仍然需要控制存儲,仍然需要擁有一個控制平面,仍然需要連接到外部。
但是最重要的網絡將會是東西向流量,計算機互相通信,試圖解決一個問題。我們認識到在高性能計算的東西向流量方面,最優秀的網絡公司進行大規模分佈式處理。
一家對我們公司非常重要且與我們息息相關的公司,一家名為Mellanox的公司,我們在5年前,即2019年收購了他們。
我們將整個數據中心轉換成一個計算單元。之前聽我說過,現代計算機就是一個完整的數據中心。數據中心是一個計算單元,不再僅僅是一台PC,不再僅僅是一台服務器,整個數據中心都在運行一個作業,而操作系統將會改變。
英偉達的數據中心發展歷程現在已廣為人知。在過去的三年裏,已經看到了我們正在塑造的一些理念,以及我們如何開始以不同的視角看待我們的公司。
歷史上沒有任何一家公司,尤其是沒有任何一家科技公司,會一次性公布長達五年的發展路線圖。沒有人會告訴你接下來會發生什麼,他們對此祕而不宣,極其保密。
然而,我們意識到英偉達不再僅僅是一家科技公司。事實上,我們是一家至關重要的基礎設施公司。如果不了解我將要做什麼,又如何規劃你的基礎設施、你的場地、你的外殼、你的電力、你所有的必要孖展,遍佈全世界?如果不了解我將要做什麼,又怎麼可能做到這一切呢?
於是,我們相當詳細地描述了我們公司的發展藍圖,詳細到世界上每個人都可以開始建造數據中心。
我們現在意識到,我們是一家人工智能基礎設施公司,一家在全球都至關重要的基礎設施公司。每個地區、每個行業、每家公司都將建設這些基礎設施。
那麼,這些基礎設施是什麼呢?事實上,這些基礎設施與第一次工業革命非常相似。當人們意識到,通用電氣、西屋電氣、西門子公司意識到,有一種名為電的新型技術,並且需要在世界各地建設新的基礎設施。這些基礎設施成為了社會基礎設施的重要組成部分,如今,這種基礎設施被稱為電力。
若干年後,就在我們這一代,我們意識到出現了一種新型的基礎設施,而且這種新的基礎設施非常概念化,難以理解。這種基礎設施被稱為信息。這種信息基礎設施,第一次被描述時,沒有人能理解,但我們現在意識到它就是互聯網,互聯網無處不在,並且所有事物都與它相連。
現在出現了一種新的基礎設施,這種新的基礎設施建立在前兩種基礎設施之上,而這種新的基礎設施是一種智能基礎設施。我知道現在,當我們說存在智能基礎設施時,這毫無意義。
我向你們保證,10年後,你們回首往事,就會意識到人工智能已經融入到一切事物之中。事實上,我們需要人工智能無處不在。而且每個地區、每個行業、每個國家、每個公司,都需要人工智能。
人工智能現在是基礎設施的一部分。而這種基礎設施,就像互聯網,就像電力一樣,需要工廠。這些工廠本質上就是我們今天所建造的東西。它們不是過去的那些數據中心。一個價值 1 萬億美元的產業,提供信息和存儲,支持我們所有的企業資源計劃(ERP)系統和員工。這是一個數據中心。一個過去的數據中心。
從某種意義上說,這與它類似,因為它來自同一個行業。它來自我們所有人。但它將演變成完全不同的東西。完全獨立於世界的數據中心。這些人工智能數據中心,如果你願意這麼稱呼它們,實際上被不恰當地描述了。它們實際上是人工智能工廠。
你向它輸入能量,它就會產出極具價值的東西。這些東西被稱為token。到了企業開始談論上個季度他們生產了多少token的地步。以及上個月他們生產了多少token。很快,我們將討論我們每小時生產多少token。正如每個工廠所做的那樣。
因此,世界已經發生了根本性的變化。從我們公司成立的那天起,我就在試圖弄清楚1993年我們的機會有多大。我得出的結論是,英偉達的商機是巨大的。3億美元。我們要發財了。3億美元的芯片產業。
針對一個價值約一萬億美元的數據中心機遇。發展到如今,一個人工智能工廠,一個價值將以數萬億美元計的人工智能基礎設施產業。這就是我們正在從事的令人興奮的未來。
現在,從根本上說,我們所做的一切都建立在幾項重要的技術之上。當然,我經常談論加速計算。我經常談論人工智能。使英偉達真正特別的是這些能力的融合。尤其重要的是算法、庫,我們稱之為 CUDAX 庫的東西。我們一直在談論庫。事實上,我們是世界上唯一一家不停談論庫的科技公司。這背後的原因是圖書館是我們一切工作的核心。圖書館是這一切的起點。
今天我將向大家展示一些新的圖書館。但在此之前,讓我先預覽一下我今天要講的內容。您即將看到的一切都與模擬、科學和人工智能相關。這裏展示的都不是藝術。一切都是模擬。只是恰好很美。讓我們來看一下。

我現在正站在實時的計算機圖形前。這不是視頻,這是計算機圖形。它由GeForce生成。這是全新的GeForce 5060,RTX 5060。這是華碩的產品。我的好朋友約翰尼在前排。這是微星的產品。我們將這款令人難以置信的GPU縮小並放到了這裏。這有道理嗎?

這太不可思議了,這就是微星搭載5060顯卡的新款筆記本電腦。英偉達GeForce為世界帶來了CUDA,現在你所看到的,是每一個像素都經過了光線追蹤。
我們是如何做到模擬光子,並以這種分辨率提供這種幀率的?原因在於人工智能。我們只渲染十分之一的像素。所以你看到的每個像素中,只有十分之一是實際計算出來的,剩下的九個,由人工智能推測,而且效果堪稱完美,它完美地猜中了。這項技術叫做DLSS,神經渲染。我們花費了許多年才開發出來,從我們開始研究人工智能的那一刻起,就已經開始了,所以這已經是一個10年的旅程。人工智能徹底革新了計算機圖形學的進步,GeForce將人工智能帶到了世界,現在人工智能又回來革新了GeForce,真的是非常驚人。
GeForce RTX 50系列啱啱完成了其有史以來最成功的發布,這是我們歷史上最快的發布,而且PC遊戲現在已經有30年曆史了,這說明了GeForce有多麼令人難以置信。

核心在於,一切都始於CUDA。通過使CUDA儘可能地高性能、儘可能地普及,從而使安裝基礎遍佈全球,應用程序就能很容易地找到CUDA GPU。安裝基礎越大,就越多的開發者希望創建庫。庫越多,越能完成令人驚歎的事情,應用程序越好,用戶受益越多,他們就會購買更多的計算機。計算機越多,CUDA就越多,這種反饋路徑至關重要。
然而,加速計算並非通用計算。通用計算編寫軟件,每個人都用Python或C++編寫,然後進行編譯,通用計算的方法論始終一致:編寫應用程序,編譯應用程序,在CPU上運行它。然而,這種方法從根本上不適用於加速計算,因為如果可以這樣做,它就會被稱為CPU。如果不直接改變CPU,以便你可以編寫軟件、編譯軟件、並在CPU上運行它,那還有什麼意義呢?你需要做一些不同的事情,這個事實實際上相當合理。其原因在於,如此多的人致力於通用計算,數萬億美元的創新投入,怎麼可能僅僅因為芯片內部的幾個小部件,計算機突然就變得快50倍、快100倍呢?這毫無道理。
因此,我們應用的邏輯是,如果你對應用程序有更深入的理解,你就可以加速它。如果你創建一種更適合加速、以接近光速運行99%運行時的架構,即使它只佔代碼的5%,你也可以加速應用程序,這相當令人驚訝。大多數應用程序中,代碼的一小部分消耗了大部分的運行時。我們觀察到了這一點,因此我們逐個攻克不同的領域。
我剛纔向你展示了計算機圖形。我們還有數值計算庫,這是數值計算庫。是最普及的數值計算庫。
Arial和Shona。Arial是世界首個用於5G和6G的GPU加速無線電信號處理方案。一旦我們將其軟件定義化,就可以在其上疊加人工智能。這樣我們就能將人工智能引入5G和6G。
Parabricks用於基因組學分析。Monai用於醫學影像。Earth 2用於天氣預測。cuQuantum用於量子經典計算機架構和計算機系統。
Megatron。這一整行,這一整列包含我們所有的深度學習以及所有用於深度學習訓練和推理的必要庫。這徹底改變了計算。而這一切都始於這些庫。不僅僅是CUDA,還有CUDNN。在CUDNN之上,有Megatron。Megatron,然後是Tensor RTLM。然後最近,用於大型AI工廠的全新操作系統,Dynamo。
CUDF用於像Spark和SQL這樣的數據幀。結構化數據也可以被加速。cuML,經典機器學習。Warp,一個框架,一個用於描述 CUDA 內核的 Pythonic 框架。非常成功。
cuopt,數學運算,優化。例如旅行商問題。能夠優化高度約束、大量變量類型的問題,例如供應鏈優化。這是一個了不起的成功。我對 Qopt 非常興奮。
cuDSS 和 cuDSparse,用於稀疏結構模擬器。它們用於 CAE 和 CAD 流體動力學。有限元分析,對於EDA和CAE行業來說極其重要。
然後,當然還有粗culitho。它是計算光刻領域最重要的庫之一。光掩模製造很容易花費一個月的時間。而且光掩模製造過程需要極高的計算強度。現在有了culitho,我們可以將計算速度提高50倍、70倍。因此,這將為未來將人工智能應用於光刻技術奠定基礎,打開世界。我們在這裏擁有優秀的合作伙伴。台積電正在廣泛使用culitho。阿斯麥、新思科技,都是與我們在culitho方面合作的卓越夥伴。
正是這些庫本身使得我們能夠在一個又一個的應用領域、科學領域和物理領域中加速應用,同時也為我們開拓了市場。我們關注特定的區域和市場,認為這些區域對於轉型到新型計算方式而言非常重要。如果通用計算經過這麼多年已經走到了盡頭,為什麼它沒有在每一個行業都走到盡頭呢?

最重要的行業之一,當然是電信業。正如世界上的雲數據中心現在已經變成了軟件定義的一樣,電信也應該變成軟件定義的,這是理所當然的。因此,我們花了大約6年的時間來完善和優化一個完全加速的無線接入網(RAN)堆棧,它能實現驚人的性能。對於每兆瓦的數據速率,或每瓦的數據速率,我們現在與最先進的專用集成電路(ASIC)處於同一水平。
一旦我們能夠做到這一點,一旦我們能夠達到那種性能和功能水平,那麼之後我們就可以在上面疊加人工智能(AI)。我們在這裏有很棒的合作伙伴,如軟銀、T-Mobile、印尼電信和沃達豐正在進行試驗。諾基亞、三星、京瓷正在與我們合作進行全棧開發。富士通和思科正在進行系統方面的合作。因此,現在我們有能力引入基於5G的人工智能,或者基於6G的人工智能,以及基於計算的人工智能的理念。

我們正在利用量子計算來實現這一點。量子計算仍處於含噪聲中等規模量子 (NISQ) 狀態。然而,我們已經可以開始進行許多非常有用的應用。因此我們對此感到興奮,我們正在開發一個量子經典,或者量子GPU計算平台,我們稱之為CUDA-Q,並與世界各地出色的公司合作。GPU可以用於預處理和後處理、糾錯以及控制。我預測在未來,所有超級計算機都將擁有量子加速器,所有計算機都將連接量子QPU。因此,一台超級計算機將是由QPU、GPU和一些CPU組成的系統。這將是現代計算機的表徵。因此,我們與該領域的許多優秀公司合作。
人工智能方面,12年前,我們從感知開始,即能夠理解模式、識別語音、識別圖像的人工智能模型。那是開端。過去5年,我們一直在談論生成式人工智能,即人工智能不僅能理解,還能生成的能力。因此,它可以從文本生成文本,比如ChatGPT中一直在使用的那樣;文本到圖像,文本到視頻,視頻到文本;圖像到文本,幾乎任何事物到任何事物。這纔是人工智能真正令人驚歎之處,我們已經發現了一個通用的函數逼近器,一個通用的翻譯器。它可以從任何事物翻譯到任何其他事物。

只要我們能簡單地對其進行標記化,表示信息的比特,那麼我們就已經達到了一個真正重要的人工智能水平。
生成式人工智能賦予了我們一次性人工智能。你給它一段文本,它就給你一段文本作為回報。那是兩年前,我們首次接觸了聊天機器人GPT。那是重大的、令人驚歎的突破。你給它一段文本,它會回給你一段文本。它預測下一個詞,預測下一段。
然而,智能遠不止是你從大量數據中所學到的東西。智能包括推理能力,包括解決你以前從未見過的問題的能力,包括將問題逐步分解的能力,包括應用一些規則和定理來解決你從未見過的問題,包括模擬多種選擇並權衡其優劣的能力。
你可能聽說過其中的一些技術:思維鏈,將其逐步分解;思維樹,提出大量可能的路徑。所有這些技術都在引領人工智能具備推理能力。
現在,令人驚奇的是,一旦你擁有推理能力,並且擁有感知能力,也就是說,比如,多模態讀取PDF,你就可以進行搜索,可以使用工具,你就擁有了自主智能。
這種自主智能所做的事情,正是我剛纔描述的我們所有人都在做的事情。我們被賦予一個目標,我們將其逐步分解。我們推理要做什麼,以及做這件事的最佳方式是什麼。我們考慮其後果,然後開始執行計劃。該計劃可能包括做一些研究,可能包括做一些工作,使用一些工具。它可能包括聯繫另一個人工智能代理,以便與之協作。
代理型人工智能基本上就是理解、思考和行動。嗯,理解、思考和行動是機器人學的循環。代理型人工智能基本上是數字形式的機器人。這些將在未來幾年變得非常重要。我們正在看到這個領域取得巨大的進展。

除此之外的下一個浪潮是物理人工智能,能夠理解世界的人工智能。他們理解慣性、摩擦、因果關係等事物。例如,如果我滾動一個球,球滾到車下,根據球的速度,它可能滾到了車的另一邊,但球並沒有消失,客體永久性。你或許能夠推斷出,如果你面前有一張桌子,而你必須到另一邊去,最好的方法不是直接穿過去。最好的方法可能是繞過它或從它下面過去。能夠推理這些物理事物對於下一代人工智能至關重要。我們稱之為物理人工智能。
因此,在這個特定的例子中,你看到我們只是提示人工智能,它就生成視頻來訓練自動駕駛汽車在不同的場景中行駛。稍後我會向你展示更多相關內容。
那是一隻狗。它可以說,「給我生成一隻狗」。「給我生成一隻帶鳥的,帶人的」。它一開始生成了左邊的圖像。

在那之後的階段,我們將採用推理系統、生成系統、物理人工智能,而這種級別的能力將會進入我們稱之為機器人的物理載體中。 如果你能想象提示人工智能生成一個視頻來伸手拿起一個瓶子,當然你也可以想象告訴一個機器人伸手拿起那個瓶子。 今天的人工智能有能力做到這些事情。 這就是我們在不久的將來要實現的目標。
我們為實現這一目標而構建的計算機,其屬性與之前的計算機截然不同。 名為Hopper的革命性計算機大約在3年前問世,它徹底改變了我們所認知的人工智能。 它可能成為了世界上最流行、最廣為人知的計算機。
在過去的幾年裏,我們一直在研發一種新的計算機,以便我們能夠實現推理時間擴展,或者說,能夠以難以置信的速度進行思考。 因為當你思考的時候,你會產生大量的tokens(標記),你會產生大量的想法,並且在你給出答案之前,在你的大腦中進行迭代。 所以,過去的一次性人工智能現在將變成思考型人工智能、推理型人工智能、推理時間擴展型人工智能。 而這將需要更多的計算量。

因此,我們創建了一個名為Grace Blackwell的新系統。Grace Blackwell具有多種功能:它具有向上擴展的能力,意味着將一台計算機變成一台巨型計算機;向外擴展是指將一台計算機與多台計算機連接起來,並讓多台不同的計算機完成工作。 擴展很容易,向上擴展極其困難。 構建超越半導體物理極限的更大型計算機,難如登天。 而這正是格蕾絲·布萊克威爾所做的。 格蕾絲·布萊克威爾幾乎打破了一切。
在座的各位,你們中的許多人正在與我們合作構建格蕾絲·布萊克威爾系統。 我很高興地說,我們已經全面投產。 雖然基於HGX的布萊克威爾系統自去年年底以來一直在全面生產,並且自2月起已上市,但我們現在才啱啱將所有格蕾絲·布萊克威爾系統上線。 它們每天都在各地陸續上線,已經在CoreWeave上可用好幾周了,已經有很多雲服務提供商(CSPs)在使用它。 現在你開始看到它從各個地方湧現出來,每個人都開始發推文說Grace Blackwell正在全面投產。
在今年第三季度,正如我承諾的,我們將像有節奏一樣,每年都提高我們平台的性能。 今年,在第三季度,我們將升級到Grace Blackwell GB300。
GB300 將沿用相同的架構、相同的物理尺寸和相同的電氣機械結構,但內部的芯片已經升級,使用了一種新的 Blackwell 芯片。

現在,它的推理性能提高了 1.5 倍,HBM 內存增加了 1.5 倍,網絡吞吐量提高了 2 倍,因此整體系統性能更高。
讓我們看看 Grace Blackwell 內部是什麼。Grace Blackwell 從計算節點開始。這是其中一個計算節點。這是上一代產品 B200 的樣子,這是 B300 的樣子。請注意正中間,現在是 100% 液冷,但除此之外,從外部來看,它是一樣的。你可以把它插入到相同的系統和相同的機箱中。

這是 Grace Blackwell GB300 系統,它的推理性能提高了 1.5 倍。訓練性能大致相同,但推理性能提高了 1.5 倍。現在,這個特殊的系統算力達到了 40 Petaflops,大約相當於 2018 年 Sierra 超級計算機的性能。
Sierra 超級計算機擁有 18000 個 Volta 架構的 GPU。這裏的這一個節點就取代了整個超級計算機。6 年內性能提升了 4000 倍。這就是極端的摩爾定律。記住,人工智能公司 NVIDIA 已經實現了大約每 10 年計算能力提升一百萬倍,而且我們仍然在沿着這條軌道前進。
但是實現這一目標的方法不僅僅是提高芯片的速度。芯片的速度和尺寸都有其極限。在 Blackwell 的案例中,甚至將兩個芯片連接在一起,使其成為可能。台積電與我們合作,發明了一種名為COOS-L的全新COOS工藝,使我們能夠製造這些巨型芯片。
但即便如此,我們仍然想要比這更大的芯片。因此,我們必須創造出所謂的NVLink,這是世界上最快的交換機,速率是每秒7.2太字節。9個這樣的交換機安裝到那個機架中。

這9個交換機通過這個奇蹟般的裝置連接起來。這就是NVLink骨幹網,兩英里的電纜,5000根結構化的電纜,全部同軸,其阻抗已匹配。它將所有72個GPU連接到NVLink交換網絡中的其他72個GPU。NVLink骨幹網的帶寬為每秒130兆兆字節。
簡單來說,整個互聯網的峯值流量為每秒900兆兆比特,除以8,它的流量超過了整個互聯網的流量。
一個NVLink主幹網連接着9個NVLink交換機,這樣每個GPU都可以完全同時地與其他GPU通信。這就是GB200的奇蹟。
由於SerDes的驅動距離有限制,這是SerDes所能達到的最遠距離,它從芯片到交換機,再到主幹網,到任何其他交換機,任何其他芯片,全部是電信號。因此,這個限制迫使我們將所有東西都放在一個機架中。
現在一個機架是120千瓦,這就是所有東西都必須進行液冷的原因。我們現在有能力將GPU從一個主板上分離出來,本質上是分佈在一個完整的機架上。那麼整個機架就是一塊主板,這就是奇蹟,完全解耦。
現在GPU的性能非常驚人,內存容量非常驚人,網絡帶寬非常驚人,現在我們真的可以大規模擴展這些系統。一旦我們向上擴展,我們就可以將它們向外擴展到大型系統中。
英偉達幾乎所有產品都非常龐大,原因在於我們不是在構建數據中心和服務器,我們正在建造人工智能工廠。這是CoreWeave,這是Oracle Cloud。每個機架的功率密度非常高,他們必須將它們分隔得更遠,以便功率密度可以分散。但實際上,歸根結底,我們不是在建造數據中心,我們正在建造人工智能工廠

這是XAI Colossus工廠,這是星門 (Stargate),4百萬平方英尺,1吉瓦。因此,請想象一下這座工廠,這座1吉瓦的工廠可能需要大約600億到800億美元的投資。在這600億到800億美元中,電子設備和計算部分,也就是這些系統,就佔了400億到500億美元。所以,這些都是巨大的工廠投資。
人們建造工廠的原因是因為你知道答案,買得越多,生產得越多,這就是工廠所做的事情。
這項技術非常複雜,實際上,僅僅在這裏看看,你仍然無法充分領略我們的所有合作伙伴以及在座的所有公司所完成的卓越工作。所以我們為您製作了一部影片。
(影片文字:Blackwell 是一項工程奇蹟。它始於台積電的一塊空白硅晶圓。數百個芯片處理和紫外光刻步驟在 12 英寸晶圓上逐層構建起 2000 億個晶體管。晶圓被劃片成一個個 Blackwell 芯片,經過測試和分類,分離出合格的芯片以繼續後續流程。
台積電、Spill 和 Amcor 完成芯片-晶圓-基板(chip-on wafer on substrate)工藝,將 32 個 Blackwell 芯片和 128 個 HBM 堆棧連接到定製的硅中介層晶圓上。 金屬互連走線直接蝕刻到其中,將 Blackwell GPU 和 HBM 堆棧連接到每個系統和封裝單元中,將所有部件鎖定到位。
然後對組件進行烘烤、模塑和固化,從而製造出 Blackwell B200 超級芯片。 在 KYEC,每個 Blackwell 都在 125 攝氏度的烤箱中進行應力測試,並在其極限下運行幾個小時。
回到富士康,機器人日夜不停地工作,將 10000 多個組件拾取並放置到 Grace Blackwell PCB 上。 與此同時,其他組件正在全球各地的工廠中準備。 來自 Cooler Master、AVC、Aorus 和 Delta 的定製液體冷卻銅塊將芯片保持在最佳溫度。
在另一家富士康工廠,ConnectX 7 SuperNIC 正在構建中,以實現橫向擴展通信,而 Bluefield 3DPU 則用於卸載和加速網絡、存儲和安全任務。 所有這些部件彙集在一起,被仔細地集成到GB200計算托盤中。
NVLink是英偉達發明的突破性高速互聯技術,用於連接多個GPU並擴展成一個巨大的虛擬GPU。 NVLink交換機托盤由NVLink交換機芯片構建,提供每秒14.4太字節的全互連帶寬。
NVLink主幹網絡形成一個定製的、盲插式背板,集成了5000根銅纜,可提供每秒130太字節的全互連帶寬。 這將所有72個Blackwell芯片,或144個GPU裸晶,連接成一個巨大的GPU。
來自世界各地的零部件陸續運達。 從富士康、緯創、廣達、戴爾、華碩、技嘉、慧與、超微和其他合作伙伴處運來,由熟練的技術人員組裝成機架規模的AI超級計算機。 總計120萬個組件,2英里的銅纜,130萬億個晶體管,重達1800公斤。
從蝕刻到晶圓上的第一個晶體管到固定Blackwell機架的最後一顆螺栓,每一步都承載着合作伙伴的奉獻、精確和工藝。 Blackwell不僅僅是一個技術奇蹟,更證明了科技生態系統的奇蹟。為此共同取得的成就感到無比自豪。)

因此,今天我們宣佈,富士康、英偉達、台積電,我們將在這裏為人工智能基礎設施和人工智能生態系統建造第一台巨型人工智能超級計算機。
謝謝。有誰需要一台人工智能計算機嗎?有聽衆席上的任何人工智能研究人員嗎?每一位學生、每一位研究人員、每一位科學家、每一家初創公司、每一家大型成熟公司,台積電本身已經進行了大量的人工智能和科學研究。富士康在機器人技術方面也做了大量的工作。我知道聽衆席上還有許多其他的公司,稍後會提到,你們也在進行機器人技術研究和人工智能研究。因此,擁有世界一流的人工智能基礎設施確實非常重要。

所有這些都是為了我們能夠構建一個非常大的芯片。NVLink 和 Blackwell,這一代的技術,使我們能夠創造出這些令人難以置信的系統。這是來自和碩、廣達電腦、緯創和緯穎的系統。這是來自富士康、技嘉和華碩的系統。可以看到它的正面和背面。它的整個目標是利用這些 Blackwell 芯片,可以看到它們有多大,並將它們變成一個巨大的芯片。當然,實現這一目標的能力是由 NVLink 提供的。但這低估了系統架構的複雜性,以及將它們連接在一起的豐富的軟件生態系統。由 150 家公司共同構建的整個生態系統。這種架構以及技術、軟件和產業中的整個生態系統,是三年工作的成果。這是一項大規模的工業投資。
現在,我們希望讓任何想構建數據中心的人都能做到。它可以是大量的英偉達GB200或300,以及英偉達的加速計算系統。也可以是其他公司的產品。
所以今天,我們要宣佈一件非常特別的事情。我們要宣佈英偉達 NVLink Fusion。NVLink Fusion 旨在讓可以構建半定製的 AI 基礎設施。不僅僅是半定製芯片,因為那已經是過去式了。需要構建 AI 基礎設施。而且每個人的 AI 基礎設施都可能略有不同。有些人可能擁有更多的 CPU,有些人可能擁有更多的英偉達 GPU,還有些人可能擁有某種半定製的 ASIC。而那些系統構建起來極其困難。並且它們都缺少一個至關重要的要素。這個至關重要的要素叫做NVLink。NVLink可以擴展這些半定製系統,並構建真正強大的計算機。所以今天,我們宣佈推出NVLink Fusion。NVLink Fusion的工作方式大致如下。這是英偉達平台。100%英偉達。
您擁有英偉達CPU、英偉達GPU、NVLink交換機,來自英偉達的網絡,名為Spectrum X或InfiniBand,網卡,網絡互連,交換機。整個系統,整個基礎設施都是端到端構建的。

現在,當然,您可以隨意混合搭配。而且今天我們使您甚至可以在計算層面上進行混合搭配。這將是您使用定製專用集成電路(ASIC)所做的事情。我們有很多優秀的合作伙伴,他們正在與我們合作,以集成您特殊的TPU或您特殊的ASIC,您特殊的加速器。
而且它不一定是轉換器加速器。它可以是您想集成到大型縱向擴展系統中的任何類型的加速器。我們創建了一個NVLink芯片模塊,它基本上是一個緊挨着您的芯片的交換機。將會有IP可用於集成到您的半定製ASIC中。
然後,一旦您完成了這些,它就可以直接安裝到計算板中,並且可以安裝到AI超級計算機的生態系統中。
現在,也許您想要的是使用您自己的CPU。您已經構建自己的CPU一段時間了,也許您的CPU已經建立了一個非常龐大的生態系統,並且您希望將NVIDIA整合到您的生態系統中。現在,我們使您能夠做到這一點。您可以通過構建自定義CPU來實現這一點。
我們為您提供NVLink芯片間接口,以便集成到您的專用集成電路(ASIC)中。我們使用NVLink芯片組進行連接,現在它可以連接並直接毗鄰Blackwell芯片和我們的下一代Rubin芯片。再次強調,它完全適合這個生態系統。
這項令人難以置信的工作成果現在變得靈活和開放,供所有人集成。因此,您的人工智能基礎設施可以包含一些NVIDIA組件,還有很多您的自有組件,很多CPU,很多ASIC,也許還有很多NVIDIA GPU。
因此,在任何情況下,您都可以受益於使用NVLink基礎設施和NVLink生態系統,並且它與Spectrum X完美連接。所有這些都具有工業強度,並且受益於已經使其成為可能的龐大工業合作伙伴生態系統。這就是NVLink Fusion。

我們有一些很棒的合作伙伴,如LCHIP、Astera Labs、Marvell,以及聯發科,他們將與我們合作,與ASIC或半定製客戶、超大規模企業,以及希望構建這些東西的CPU供應商合作,他們將成為他們的半定製ASIC供應商。
我們還有富士通和高通,他們正在構建帶有NVLink的CPU,以集成到我們的生態系統中。
Cadence和Synopsys,我們與他們合作將我們的IP轉移給他們,以便他們可以與所有人合作,並將該IP提供給所有芯片。
所以這個生態系統非常棒。但這恰恰突顯了NVLink Fusion生態系統的優勢。一旦與他們合作,將立即融入整個更大的NVIDIA生態系統,從而擴展到這些AI超級計算機中。

現在來談談一些新的產品類別。已經展示了幾款不同的計算機。然而,為了服務於世界上的絕大多數人,仍然缺少一些計算機。所以將要談談它們。
在此之前,想通報一下,我們稱之為DGX Spark的這款新計算機已經全面投產。DGX Spark即將就緒,不久即可上市,可能就在幾周內。
我們有非常棒的合作伙伴與我們合作,如戴爾、HPI、華碩、微星、技嘉、聯想。他們是與我們合作的傑出夥伴。這就是DGX Spark。這實際上是一台量產機型。這是我們的版本。然而,我們的合作伙伴正在構建許多不同的版本。
這是為原生 AI 開發者設計的。如果是一名開發者、一名學生、一名研究人員,而且不想總是打開雲端,並進行準備工作,然後在完成後再進行清理,那麼就會希望擁有自己的,基本上是自己的 AI 雲就坐在旁邊,並且它始終開啓,始終等待着。它允許進行原型設計、早期開發,這就是它令人驚歎的地方。這就是 DGX Spark。這是一個千萬億次浮點運算和128千兆字節。

在2016年,當我交付DGX One時,這只是擋板,我無法抬起一整台電腦,它重達300磅。這是DGX One,這是一個千萬億次浮點運算和128千兆字節。當然,這是128千兆字節的HBM內存。這是128千兆字節的LPDDR5X。實際上,性能非常相似。但最重要的是,能做的工作,可以在這裏做的工作與在這裏能做的工作相同。這在僅僅大約10年的時間裏,是一項了不起的成就。
這是DGX Spark,適合任何想要擁有自己的人工智能超級計算機的人。我會讓所有的合作伙伴自己定價,但可以肯定的是,每個人都能在聖誕節擁有一台。

我還有另一台電腦想展示。如果那還不夠,並且仍然想要擁有自己的個人電腦,這位是珍妮·保羅女士。如果那台對你來說不夠大,這裏還有一台。這又是另一台台式機,將由戴爾、惠普、華碩、技嘉、微星、聯想提供。它將從Box、Lambda等卓越的工作站公司提供。這將是你自己的個人DGX超級計算機,能讓你從一個牆壁插座中獲得你能獲得的最高性能。你可以把它放在你的灶底1裏,但只能勉強放得下。如果把這個放在灶底1裏,然後有人啓動微波爐,我認為那就是極限了。
這就是極限,這就是你能從牆上插座獲得的極限。這是一個DGX工作站。它的編程模型和我展示的那些巨型系統的編程模型是相同的。這就是令人驚歎的地方。單一架構,它擁有足夠的能力和性能來運行一個萬億參數的AI模型。記住,Llama是Llama 70B。一個萬億參數的模型在這台機器上將會運行得非常出色。這就是DGX工作站。

這些系統都是AI原生的,是為新一代軟件而構建的計算機。它不必與 x86 兼容,不必運行傳統的 IT 軟件,不必運行虛擬機監控程序,不必運行 Windows。這些計算機是為現代人工智能原生應用程序設計的。當然,這些人工智能應用程序可以是可以通過傳統和經典應用程序調用的 API。但是,為了將人工智能帶入一個新世界,而這個新世界是企業 IT,我們必須回到我們的根源,並且必須重新發明計算並將人工智能帶入傳統的企業計算中。
現在,我們所知的企業計算,實際上是三個層次,不僅僅是計算層,而是計算、存儲和網絡。始終是計算、存儲和網絡。正如人工智能已經改變了一切,可以推斷,人工智能也必然改變了企業IT的計算、存儲和網絡。那麼,這個底層必須被徹底改造,而我們正在進行改造。

我將展示一些新產品,這些產品將為我們開啓、解鎖企業IT。它必須與傳統的IT行業協同工作,並且必須增加一種新的能力。對於企業而言,這種新的能力就是代理式人工智能。
基本上就是數字營銷活動經理、數字研究員、數字軟件工程師、數字客服、數字芯片設計師、數字供應鏈經理,以及過去所做所有工作的數字化人工智能版本。
代理式人工智能具有推理、使用工具以及與其他人工智能協同工作的能力。在很多方面,這些都是數字勞工,是數字僱員。
世界正面臨勞動力短缺,工人短缺。預計到2030年,勞動力短缺將達到約3000萬到5000萬,這實際上限制了世界經濟的增長能力。因此,現在我們有了這些可以協同工作的數字代理。英偉達(NVIDIA)現在有100%的軟件工程師都配備了數字代理,以便它們能夠幫助、協助開發更好的代碼,提高生產力。
在未來,將會看到一層代理人工智能,人工智能代理。過去我們有人力資源部管理人力勞動者,未來信息技術部門將成為數字勞動者的人力資源部。因此,必須為當今的IT產業、當今的IT從業者創造必要的工具,使他們能夠管理、改進、評估在其公司內部工作的一整個AI代理家族。這就是我們想要構建的願景。
但首先,我們必須重新發明計算。企業IT運行在x86架構上,運行傳統的軟件,例如來自VMware、IBM Red Hat或Nutanix的虛擬機管理程序。它運行着大量的經典應用程序。我們需要擁有能夠執行相同操作的計算機,同時還要增加一種稱為代理人工智能的新功能。

這是全新的 RTX Pro 企業級和 Omniverse 服務器。這台服務器可以運行所有程序,當然,它有 x86 架構,可以運行所有經典的虛擬機管理程序。它在這些虛擬機管理程序中運行 Kubernetes。因此,IT 部門想要管理網絡、集群以及編排工作負載的方式,與之前的工作方式完全相同。它甚至能夠將 Citrix 和其他虛擬桌面流式傳輸到 PC。今天世界上運行的任何東西都應該能在這裏運行。Omniverse 在這裏運行得非常完美。除此之外,這還是企業級人工智能代理的計算機。這些人工智能代理可能僅是文本形式,也可能是計算機圖形。像是小 TJ,來到你面前,像是小玩具 Jensen 來拜訪你,幫助你工作。因此,這些人工智能代理可以是文本形式,可以是圖形形式,也可以是視頻形式。
所有這些工作負載都可以在此係統上運行。無論何種模態,我們所知的世界上每一個模型、每一個應用程序都應該運行於此,即使是 Crysis 也能在這裏運行。

連接這8個GPU(Blackwell,新的Blackwell RTX,RTX Pro 6000s)的是這塊新的主板。這塊新的主板實際上是一個交換網絡。
CX8是一個新的芯片類別,首先它是一個交換機,其次它是一個網絡芯片,也是世界上最先進的網絡芯片。CX8現在已進入批量生產階段。在CX8中,可以插入GPU。CX8都在後面,PCI Express 連接在此處,CX8 在它們之間進行通信。而且網絡帶寬非常高,達到每秒800千兆位。這是插入到這裏的收發器。因此,每個GPU都有它們自己的網絡接口。現在,所有GPU都在東西向流量上與其他所有GPU進行通信,性能驚人。
這是 RTX Pro。在人工智能工廠的世界中,思考性能的方式是吞吐量,即每秒處理的token數。你的工廠產出越多,你生產的token就越多。因此,吞吐量衡量的是每秒處理的token數。
然而,每個AI模型都不一樣,有些AI模型需要更多的推理。因此,你需要每個用戶的性能非常高,每個用戶的每秒token數必須很高。工廠要麼喜歡高吞吐量,要麼喜歡低延遲,但它不喜歡兩者兼得。
因此,挑戰在於如何創建一個操作系統,使我們能夠在擁有高吞吐量的同時,擁有非常低的延遲,即交互性,每用戶每秒令牌數。
這張圖表告訴您一些關於計算機整體性能,以及工廠整體計算機性能的信息。這些不同的顏色代表了您必須配置我們所有GPU的不同方式,才能實現這種性能。有時您需要流水線並行,有時您需要專家並行,有時您希望進行批處理,有時您希望進行推測性解碼,有時您不希望。因此,所有這些不同類型的算法必須根據工作負載分別且不同地應用。
帕累託曲線(即外圍區域)的總體區域代表您工廠的能力。請注意,Hopper(世界上最著名的計算機,Hopper H100,HGX,225000美元的Hopper)就在那裏。
您剛纔看到的Blackwell企業級服務器,其性能是現有服務器的1.7倍。
Llama70B與DeepSeek R1相比,後者性能是前者的4倍。 這得益於DeepSeek R1的優化,它確實是世界人工智能產業的一份禮物。 其中計算機科學的突破非常顯著,為美國和世界各地的研究人員開啓了大量的優質研究。 無論在哪裏,DeepSeek R1都對人們如何看待人工智能、推理以及推理型人工智能產生了影響。 他們為行業和世界做出了巨大貢獻。 DeepSeek R1的性能是當前最先進的H100的4倍,這使其更具現實意義。

如果您正在構建企業人工智能,我們現在為您提供一台出色的服務器,一個出色的系統。 它是一台可以運行任何程序的計算機,一台具有驚人性能的計算機,無論是x86還是AI程序都能運行。 我們的RTX Pro服務器正在行業內所有合作伙伴處批量生產,這很可能是有史以來規模最大的上市系統。
計算平台和存儲平台是不同的。 人們查詢的是像SQL這樣的結構化數據庫,但AI想要查詢非結構化數據。 它們需要語義和意義,所以我們需要創建一個新型的存儲平台,這就是英偉達AI數據平台。
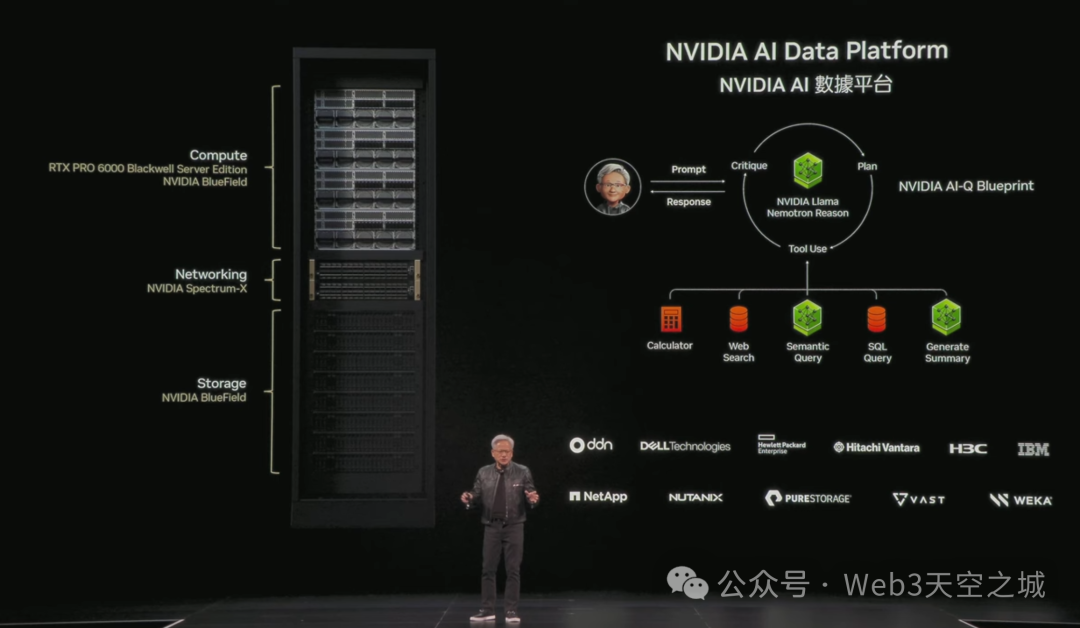
在最頂層,就像SQL服務器、SQL軟件以及存儲供應商提供的文件存儲軟件一樣,存在一個非常複雜的軟件層,它與存儲相關聯。 大多數存儲公司本質上都是軟件公司,而那個軟件層極其複雜。 因此,在新型存儲系統之上,將是一個我們稱之為IQ的新型查詢系統,英偉達AI IQ,或者IQ。 它是最先進的,非常出色,並且正在與存儲行業的幾乎所有人合作。
未來的存儲不再是位於一排存儲設備之上的CPU,而將會是位於存儲機架頂端的GPU。 這樣做的原因是,你需要系統嵌入並找到非結構化數據、原始數據中的意義。 你必須進行索引、搜索和排序。 因此,這個過程是計算密集型的。 所以未來大多數存儲服務器的前端都會有一個計算節點,即GPU計算節點。

這是基於我們創建的模型。 我接下來要展示的幾乎所有內容都始於優秀的AI模型。 我們創建AI模型,並在開源AI模型的後訓練中投入大量的精力和技術。 我們使用對您完全透明的數據對這些AI模型進行後訓練。 這些數據是安全可靠的,可以完全放心地使用和訓練,我們會將該列表提供給您查看。
它是完全透明的,我們會向您提供數據。我們對模型進行後訓練,後訓練模型性能非常出色。
它目前可供下載,是開源的推理模型。LamaNemotron推理模型是世界上最好的,它的下載量非常巨大。
我們也用一大堆其他AI模型將其包圍,以便您可以進行IQ,即檢索部分。它比市面上現有的快15倍,查詢結果好50%。這些模型都是可用的,都可以提供給您,IQ藍圖是開源的。
我們與存儲行業合作,將這些模型集成到他們的存儲堆棧、他們的AI平台中。這是一個廣闊的領域,這就是它的樣子。
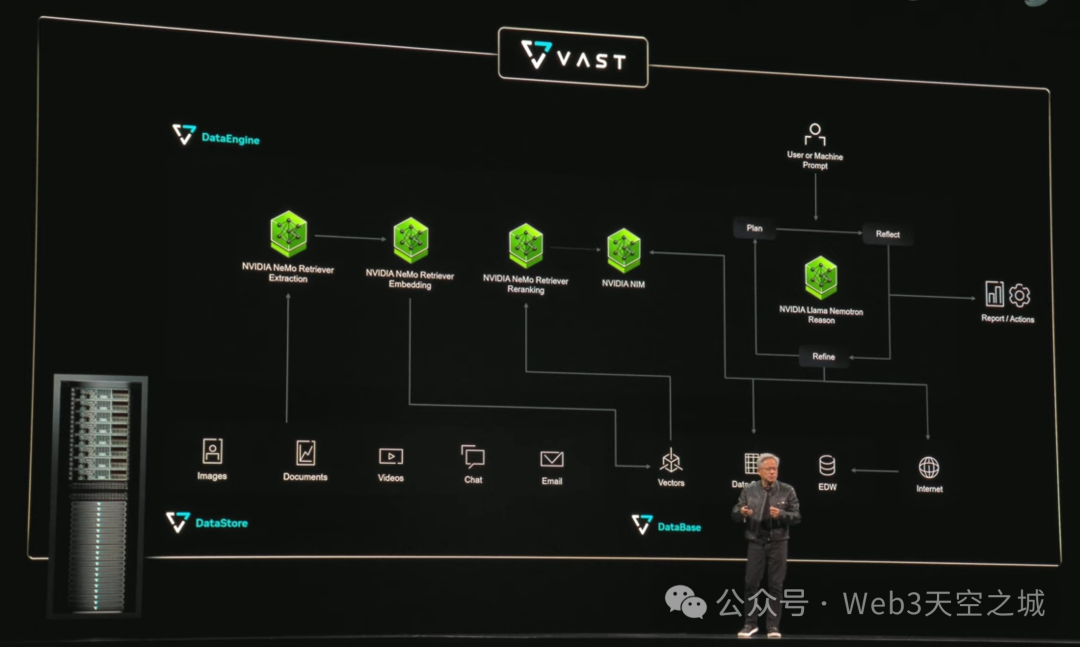
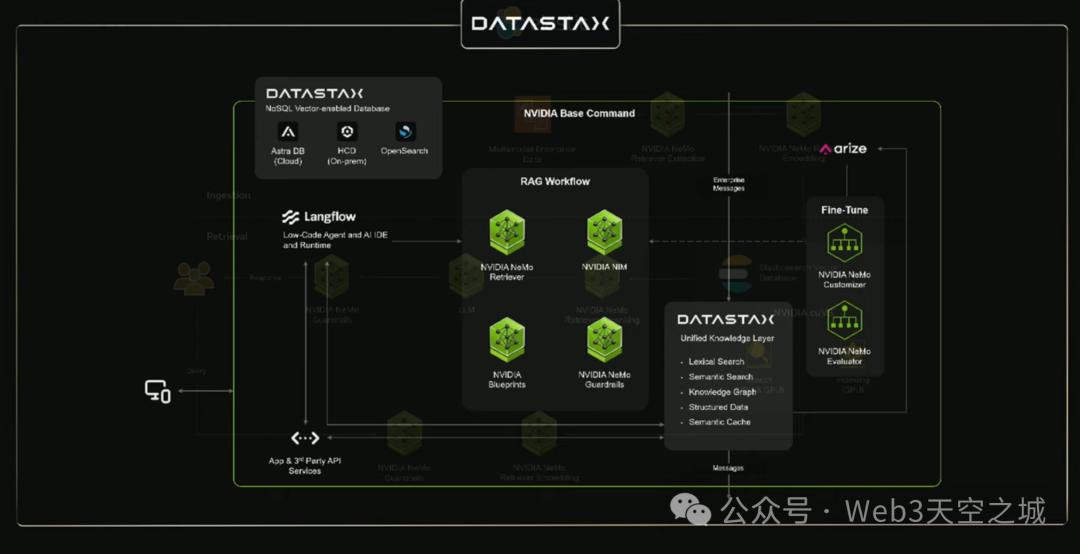
我不打算深入探討,我只是想讓大家感受一下集成到他們平台中的人工智能模型的質感。讓我們看看VAST都做了些什麼。主動式人工智能改變了企業利用數據進行決策的方式。
僅僅三天時間,VAST就利用NVIDIA IQ藍圖及其加速人工智能數據平台構建了一個銷售研究人工智能代理。利用Nemo Retriever,該平台持續提取、嵌入和索引數據,以實現快速的語義搜索。
首先,該代理起草一個概要,然後接入CRM系統、多模態知識庫和內部工具。最後,它使用Lama Nemotron將該概要轉化為一個循序漸進的銷售計劃。
過去需要幾天才能完成的銷售計劃,現在可以通過一個人工智能提示開始,並在幾分鐘內完成計劃。藉助VAST加速的人工智能數據平台,各組織可以為每位員工創建專門的代理。
這就是VAST。戴爾擁有卓越的人工智能平台,是世界領先的存儲供應商之一。日立擁有卓越的人工智能平台,人工智能數據平台。IBM正在與NVIDIA Nemo合作構建人工智能數據平台。NetApp正在構建人工智能平台。
正如您所見,所有這些都對您開放。如果您正在構建一個具有語義查詢人工智能前端的人工智能平台,那麼NVIDIA Nemo是世界上最好的。這樣,您就擁有了企業計算能力和企業存儲能力。
下一部分是一個名為AIOps的新的軟件層。正如供應鏈有他們的運營,人力資源有他們的運營一樣,未來,IT也將有AIOps。他們將管理數據,微調模型,評估模型,為模型設定護欄,保障模型的安全。
我們擁有大量必要的庫和模型,可以集成到AIOps生態系統中。我們有優秀的合作伙伴來幫助我們做到這一點,並將其推向市場。CrowdStrike正在與我們合作。DataIQ正在與我們合作。DataRobots正在與我們合作。
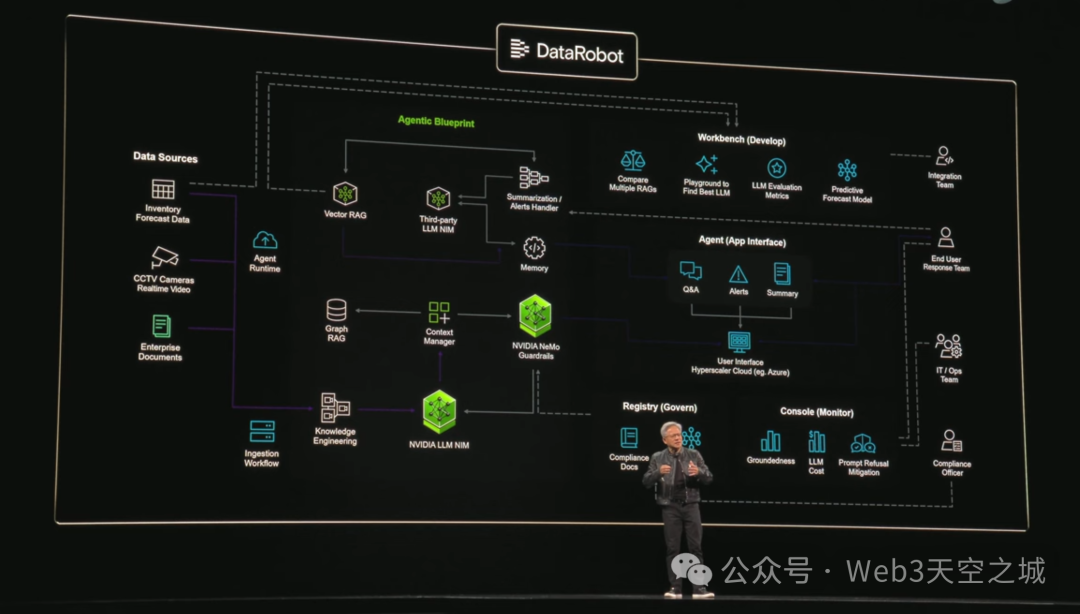
正如你所見,這些都是人工智能運營,為企業中的主體人工智能創建微調模型和部署模型。 你可以看到NVIDIA的庫和模型集成在其中。
DataRobots之後,這裏是DataStacks。 這是Elastic。 據說他們被下載了4000億次。 這是Nutanix。 這是紅帽。 這是趨勢科技。 。
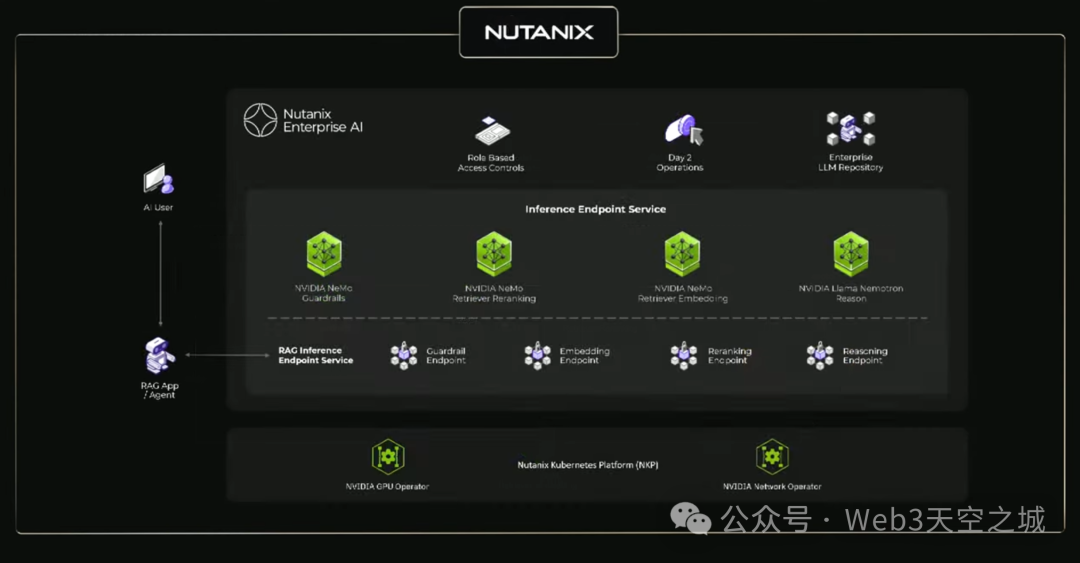
這就是我們將為全球企業IT帶來為您的所有工作添加人工智能能力的方式。 您不會把企業IT組織中的所有東西都拆掉,因為公司必須運轉。 但我們可以把人工智能添加進去。 現在我們有了具備企業級就緒狀態的系統,以及令人難以置信的生態系統合作伙伴。
傑夫·克拉克,偉大的傑夫·克拉克。 他長期以來一直是我們的合作伙伴。 還有傑夫·克拉克。 因此,我們的生態系統合作伙伴,戴爾和其他公司,將把這個平台,這些平台,帶給全球的企業IT領域。
讓我們來談談機器人。 智能體人工智能,類智能體人工智能,人工智能智能體,有很多不同的說法,智能體本質上是數字機器人。 原因是機器人能夠感知、理解和規劃。 而這基本上就是智能體所做的事情。
但我們也希望建造實體機器人。 這些實體機器人,首先,需要具備學習成為機器人的能力。 在現實世界中高效地學習成為機器人的能力是不可能實現的。 你必須創建一個虛擬世界,讓機器人在其中學習如何成為一個優秀的機器人。 那個虛擬世界必須遵守物理定律。
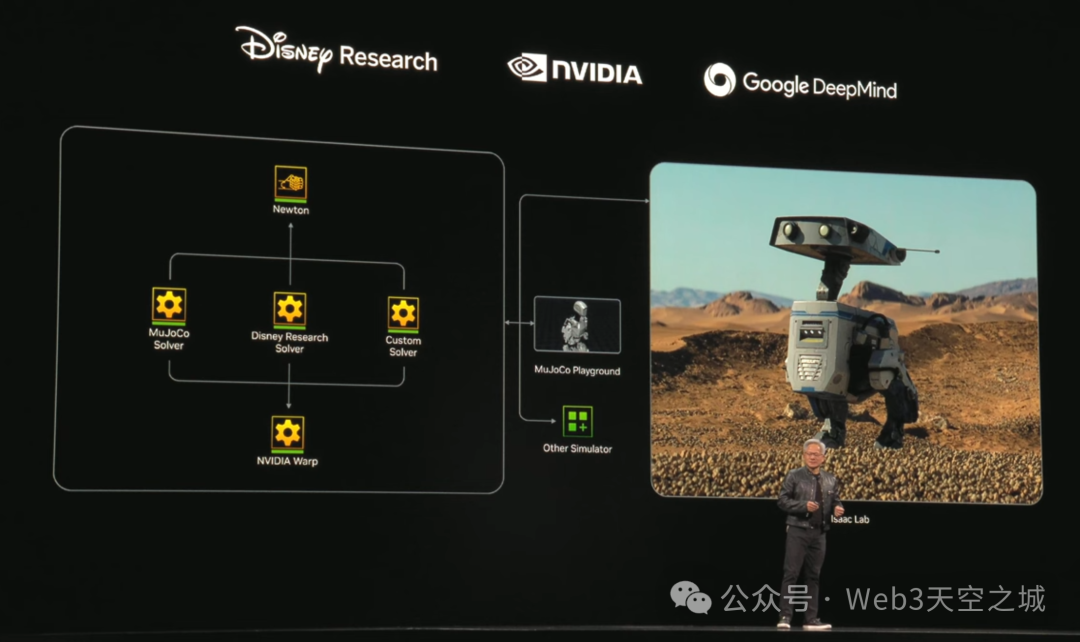
大多數物理引擎都無法高保真地處理剛體和柔體模擬。 因此,我們與 DeepMind、谷歌 DeepMind 和迪士尼研究院合作,共同構建了 Newton,世界上最先進的物理引擎。 它將於7月開源,它的功能令人難以置信。 它完全通過GPU加速。 它是可微的,因此你可以從經驗中學習。 它的保真度極高,它是超實時的。
因此我們可以使用那個牛頓引擎,並且它已集成到Mujoco中。 它已集成到NVIDIA的Isaac Sim中。 所以無論你使用什麼仿真環境和框架。 因此,通過它,我們可以讓這些機器人栩栩如生。

你能想象其中一個小傢伙,或者幾個小傢伙在房子裏到處跑嗎? 追逐你的狗? 讓他們發瘋?
你看到了發生了什麼嗎? 那不是動畫,而是一個模擬。 他在沙子和泥土中打滑。 所有這些都是模擬的。
機器人的軟件在模擬中運行,這是一種模擬而非動畫。未來,我們將採用訓練好的人工智能模型,並將其置入模擬環境中的機器人中,讓它學習如何成為一個優秀的機器人。
我們正在研究多項舉措來幫助機器人產業。我們已經在自主系統領域工作了一段時間。我們的自動駕駛汽車基本上包含三個系統:創建人工智能模型的系統(使用GB200、GB300),訓練人工智能模型的系統(使用Omniverse模擬人工智能模型),以及將人工智能模型置入自動駕駛汽車中的系統。
今年,我們將在全球範圍內推廣梅賽德斯所使用的端到端自動駕駛汽車技術棧。我們創建所有這些,並以與我們在其他任何地方工作方式完全相同的方式上市。我們創建整個技術棧,並將其開放。合作伙伴可以使用他們想使用的任何東西。他們可以使用我們的計算機,但不能使用我們的庫;他們可以使用我們的計算機、我們的庫以及我們的運行時環境。無論您想使用多少,都取決於您。
由於存在許多不同的工程團隊、不同的工程風格和不同的工程能力,我們希望確保以一種儘可能方便所有人都能夠集成英偉達技術的方式來提供我們的技術。如果您從我這裏購買所有東西,我會很高興,但請至少從我這裏購買一些東西。我們非常務實。

因此,我們正在機器人系統中做完全相同的事情,就像汽車一樣。這是我們的Isaac Groot平台。仿真環境完全相同,都是Omniverse。訓練系統也是相同的。當你完成模型後,你把它放入這個Isaac Groot平台。
Isaac Groot平台始於一台全新的計算機,名為Jetson Thor,它才啱啱開始投入生產,是一個令人難以置信的處理器。這款機器人處理器可以用於自動駕駛汽車,也可以用於人或機器人系統。
在此之上是一個我們稱之為NVIDIA ISAAC的操作系統,這是一個運行時環境,它進行所有的神經網絡處理、傳感器處理、所有管線處理,並輸出驅動結果。在其之上,是我們與一個出色的機器人團隊創建的預訓練模型,他們正在對這些模型進行預訓練。創建這一切所需的所有工具,包括模型本身,我們都會提供。

今天我們宣佈 Isaac Groot N1.5 現已開源,並向全世界開放使用。它已經被下載了6000次,來自社區的歡迎、喜愛和讚賞令人難以置信。
以上是關於模型創建方面的內容,我們公開了我們創建模型的方式。
機器人技術,或者說人工智能領域總體上最大的挑戰在於數據策略。你的數據策略必須投入大量的研究和技術。
就機器人技術而言,人類演示非常重要,就像我們向孩子們演示,或者教練向運動員演示一樣。你演示如何使用遙控操作,你向機器人示範如何執行任務,然後機器人可以從該示範中進行泛化。因為人工智能可以泛化,並且我們擁有泛化技術,可以從該演示中泛化出其他技術。
那麼,如果你想教機器人一大堆技能呢?你需要多少不同的遙控操作人員?結果表明需要很多。所以我們決定使用人工智能來放大人類示範系統。
因此,這本質上是從真實到真實,並使用人工智能來幫助我們擴展、放大人類示範過程中收集的數據量,以訓練人工智能模型。
通用機器人時代已經到來,伴隨着機電一體化、物理人工智能和嵌入式計算的突破。正當其時,因為勞動力短缺限制了全球工業增長。
機器人製造商面臨的主要挑戰是缺乏大規模的、真實的和合成的數據來訓練模型。人工示範不具備可擴展性,受限於一天中的小時數。

開發人員可以使用NVIDIA Cosmos物理人工智能世界基礎模型來放大數據。Groot Dreams是一個基於Cosmos的藍圖,用於大規模生成合成軌跡數據。
一種真實到真實的數據工作流程:首先,開發人員通過在單一環境中對單一任務進行遙操作記錄的人工示範來微調Cosmos。然後,他們用一張圖片和新的指令提示模型來生成夢想,或者說是未來的世界狀態。Cosmos是一個生成模型,因此開發者可以使用新的動作詞進行提示,而無需捕獲新的遙操作數據。
一旦生成了大量夢想,Cosmos會推理並評估每個夢想的質量,選擇最佳的夢想用於訓練。但這些夢想仍然只是像素。機器人從行動中學習。
Groot Dreams藍圖從2D夢想視頻中生成3D動作軌跡。然後,這被用於訓練機器人模型。Groot Dreams讓機器人能夠學習各種各樣的新動作,而只需極少的人工捕獲。
因此,一小隊人類演示者現在可以完成成千上萬人的工作。Groot Dreams讓開發者們在解決機器人數據挑戰方面更進一步。
為了實現機器人技術,你需要人工智能。但為了教導人工智能,你需要人工智能。因此,這確實是智能體時代的偉大之處,我們需要大量的合成數據生成。機器人技術,需要大量的合成數據生成。
被稱為微調的技能學習,涉及到大量的強化學習和巨大的計算量。因此,人工智能的訓練、開發和運行都需要巨大的計算量。
正如之前提到的,世界正面臨嚴重的勞動力短缺。人形機器人如此重要的原因是,它是唯一一種幾乎可以在任何棕地環境中部署的機器人。它不必是綠地環境,它可以融入我們創造的世界,完成我們為自己設定的任務。我們為自己設計了世界,現在我們可以創造一個機器人來適應這個世界,並幫助我們。
現在,人形機器人最令人驚歎之處不僅僅在於,如果它能正常運作,它將具有相當高的通用性。它很可能是唯一有可能成功的機器人。其原因在於技術需要規模效應。我們目前擁有的大多數機器人系統產量太低,這些低產量系統永遠無法達到足夠的技術規模,從而無法使飛輪運轉足夠遠、足夠快,以至於我們願意投入足夠的技術來改進它。但人形機器人很可能成為下一個數萬億美元級的產業,而且技術創新速度非常快。計算和數據中心的消耗是巨大的,但這是需要三台計算機才能實現的應用之一。一台計算機用於學習的人工智能,一台計算機是仿真引擎,人工智能可以在虛擬環境中學習如何成為機器人,然後進行部署。一切移動的物體都將是機器人。
當我們將這些機器人放入工廠時,請記住,工廠也將是機器人化的。今天的工廠非常複雜,例如達美航空的生產線,他們正在為機器人化的未來做準備。它已經是機器人和軟件定義的了,並且未來將會有機器人在其中工作。
為了讓我們創造和設計能夠像一個艦隊一樣,像一個團隊一樣運作的機器人,在一個也是機器人化的工廠中協同工作,我們必須賦予其 Omniverse(全宇宙)來學習如何協同工作。而那個數字孿生,現在有了一個機器人的數字孿生,擁有所有設備的數字孿生,擁有一個工廠的數字孿生。這些嵌套的數字孿生將成為 Omniverse 能夠實現的一部分。這是達美航空的數字孿生,這是緯創資通的數字孿生。
這些都是數字孿生,都是模擬,看起來非常漂亮。圖像看起來非常漂亮,但它們都是數字孿生。這是和碩的數字孿生,這是富士康的數字孿生,這是技嘉的數字孿生,這是澳洲航空的,這是緯創資通的。台積電正在為其下一個晶圓廠構建一個數字孿生。
全球正在規劃價值5萬億美元的工廠。未來三年內,將新建價值5萬億美元的工廠。
世界正在重塑,再工業化正在全球推進,新的工廠正在各地興建。這對我們來說是一個巨大的機遇,確保其建造得良好、經濟高效且準時。
將一切都放入數字孿生體中,是邁出的絕佳第一步,並為機器人化的未來做好準備。建造這價值5萬億美元的工廠,還不包括我們正在建造的一種新型工廠。甚至我們自己的工廠,也將其放入數字孿生體中。這是英偉達人工智能工廠的數字孿生體。高雄也是一個數字孿生體。他們將高雄製造成了一個數字孿生體。目前已經有成千上萬棟建築,數百萬英里的道路。
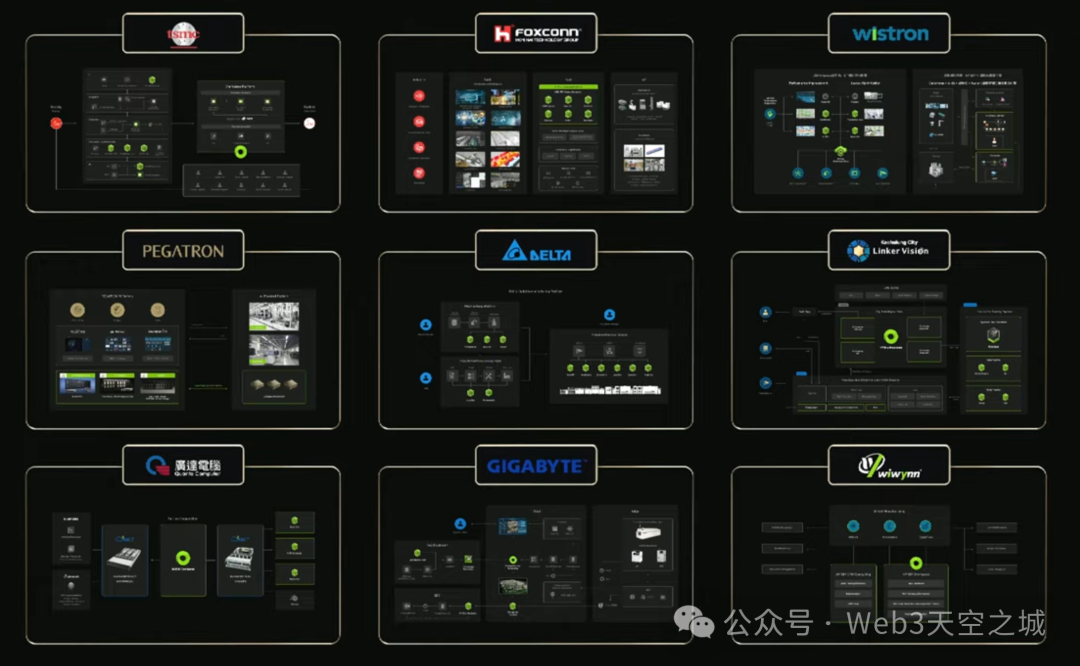
台積電、富士康、緯創、和碩、台達電子、廣達、雲達科技和技嘉正在 NVIDIA Omniverse 上為製造過程的每一步開發數字孿生體。台積電與 MED-AI 從二維 CAD 生成整個晶圓廠的 3D 佈局,並在 CUOP 上開發人工智能工具,可以模擬和優化跨多個樓層的複雜管道系統,從而節省數月時間。廣達、緯創和和碩計劃在實際建造之前,先以虛擬方式規劃新的設施和生產線,通過減少停機時間節省數百萬美元的成本。和碩模擬焊膏點膠,從而減少生產缺陷。廣達使用 Siemens Teamcenter X 與 Omniverse 來分析和規劃多步驟流程。富士康、緯創和廣達利用 Cadence Reality Digital Twin 模擬測試數據中心的電力和散熱效率。
為了開發具備人工智能的實體機器人,每家公司都將其數字孿生體用作機器人訓練場,以開發、訓練、測試和模擬機器人。無論是機械臂、自主移動機器人(AMR)、人形機器人,還是視覺人工智能代理,在執行任務或作為多元化團隊協同工作時,均可利用數字孿生體。當通過物聯網(IoT)連接到物理孿生體時,每個數字孿生體都成為一個實時交互式儀表板。和碩利用 NVIDIA Metropolis 構建人工智能代理,以幫助員工學習複雜的技術。
LinkerVision 公司和高雄市利用數字孿生體來模擬不可預測情境的影響,並構建可監控城市攝像頭流的人工智能代理,向急救人員提供即時警報。
工業人工智能時代已經到來,由科技領軍企業率先開創,由 Omniverse 驅動。
作為最先進產業的中心,人工智能和機器人技術的發源地,理應如此。這裏是世界上最大的電子產品製造區域。
人工智能和機器人技術將變革我們所做的一切。歷史上第一次,各位所做的工作已經徹底改變了每一個行業,現在它將回過頭來徹底改變各位的行業。
GeForce將人工智能帶到了世界。人工智能又回來並改變了GeForce。各位將人工智能帶到了世界,人工智能現在會反過來改變各位所做的一切。和各位一起工作非常愉快。謝謝。

我有一個新產品要發布。我們已經在太空船塢開發了一段時間。現在是我們揭曉我們有史以來建造的最大的產品之一的時候了。而它就停在外面等着我們。讓我們看看情況如何。英偉達星系(NVIDIA Constellation)。
正如各位所知,我們一直在發展。我們與各位的所有合作關係也一直在發展。我們這裏的工程師人數一直在增長。因此,我們的發展已經超出了目前辦公室的侷限。所以我打算為他們建造一個全新的英偉達辦公室。它被稱為英偉達星系(NVIDIA Constellation)。
我們也在選擇場地。我們一直在選擇場地,各個城市的市長們都對我們非常友善。我認為我們達成了一些不錯的交易。我不太確定,但黃金地段就是黃金地段。今天我非常高興地宣佈,NVIDIA Constellation 將落戶北投士林。
我們已經就租賃權的轉讓事宜與現有租賃權所有者進行了談判。然而,我了解到,為了讓市長批准該租賃,他想知道台北市民是否同意我們在這裏建造一個大型、美麗的NVIDIA Constellation。各位同意嗎?他還讓各位給他回電話。所以各位確信知道他的號碼。大家都立刻給他打電話,告訴他你認為這是個很棒的主意。
這將是英偉達星空平台。我們將要構建它。我們會盡快開始構建。我們需要辦公空間。英偉達星空平台,北投士林。非常令人興奮。
我想感謝各位多年來的合作。我們正面臨着千載難逢的機會。擺在我們面前的機遇是前所未有的。在我們共同經歷的這段時間裏,我們第一次不僅在創造下一代信息技術,我們已經這樣做了好幾次,從個人電腦到互聯網,再到雲,再到移動雲。我們已經這樣做了好幾次。
但這一次,我們不僅在創造下一代信息技術,事實上,我們正在創造一個全新的產業。

這個全新的產業將使我們面臨着巨大的機遇。
我期待與各位合作,共同構建人工智能工廠、企業智能代理、機器人。感謝各位傑出的合作伙伴,與我們共同圍繞統一架構構建生態系統。
因此,我想感謝各位今天的光臨。祝各位Computex2025愉快。謝謝。