投資人Brad Gerstner認為英偉達會是第一個市值超過十萬億美元的公司。
近期,英偉達(NVDA.US)投資「出手」頻繁,先是宣佈50億美元投資英特爾,隨後斥資至多1000億美元投資OpenAI,而受此前OpenAI與甲骨文的合作,市場均在股價層面給予了積極反饋。
但市場也出現了質疑聲音——稱英偉達、OpenAI與甲骨文存在「收入循環」,財務數字「操作」大於實際營收。
9月25日,在播客BG2最新一期節目中,BG2主播、Altimeter Capital創始人Brad Gerstner,Altimeter Capital合夥人Clark Tang與英偉達CEO黃仁勳展開了一次對話。黃仁勳在對話中回應了當下市場的關心的問題。
黃仁勳認為,投資OpenAI實際上是一個很好的機會,並認為OpenAI將是下一家數萬億美元級別的Hyperscaler。
此外,黃仁勳也特別解釋了為什麼ASIC芯片並不完全和英偉達GPU是競爭關係——因為英偉達是AI基礎設施提供商,其提供的能力範圍已經不僅僅是硬件和軟件層面,也包括其不斷迭代的速度、規模優勢帶來的可靠性,以及整體能源效率等綜合因素。
因此,黃仁勳認為英偉達目前的護城河比三年前「更寬「,而Brad Gerstner甚至認為,英偉達將是史上第一家達到十萬億美元的公司。
以下為「明亮公司」編譯的訪談正文(有刪節):

Brad Gerstner:Jensen,再次歡迎你。你的紅色眼鏡很好看,真的很適合你。距離上次上播客,已過去一年多。你們如今超過40%的收入來自推理(inference),而且推理正因為chain of reasoning鏈式推理而要起飛了。
黃仁勳:大多數人還沒真正內化這一點,這其實就是一場工業革命。
投資OpenAI不是合作的前提,是因為有機會能投
Brad Gerstner:說真的,從那次之後,感覺你我每天都像在驗證那期播客。在AI的時間尺度上,這一年像過了一百年。我最近重看了那期,很多觀點讓我印象深刻。
最打動我的是你當時拍着桌子說——當時大家覺得預訓練進入低潮(pre-training),很多人說預訓練要完蛋了,硬件建設過度。那是大約一年半前。你說推理不會只是一百倍、一千倍。會是十億倍。這把我們帶到今天。你剛宣佈了一項巨大合作,我們應該從這裏聊起。
黃仁勳:我想正式說下,我認為我們現在有三條Scaling Law。第一是預訓練的Scaling Law。第二是後訓練(post-training)的Scaling Law。後訓練基本上就是讓AI練習一種技能,直到做對,它會嘗試很多不同方法。要做到這一點,就必須進行推理(inference)。所以訓練與推理如今以強化學習的方式整合在一起,非常複雜,這就是後訓練。
第三是推理(inference)。過去的推理是「一次出手」,而我們現在理解的新推理,是「先思考再作答」。先想,再回答,想得越久,答案質量越高。思考過程中你會檢索、查證事實、學到東西,再繼續思考、繼續學習,最後輸出答案,而不是上來就生成。所以思考、後訓練、預訓練,如今我們有三條Scaling Law,而不是一條。
Brad Gerstner:這些你去年就提過,但你今年說推理會提升十億倍,並由此帶來更高水平智能」的信心更高嗎?
黃仁勳:我今年更有把握。原因是看看如今的智能體系統。AI不再是單一語言模型,而是由多個語言模型組成的系統,它們併發運行。有的在用工具,有的在做檢索,事情非常多,而且是多模態。看看生成的視頻,簡直令人難以置信。
Brad Gerstner:這也引到本周的關鍵時刻,大家都在談你們與OpenAI的重磅合作Stargate。你們將成為首選合作伙伴,並在一段時間內向公司投資1000億美元。他們會建10個「gig「(Gigawatt,吉瓦)。如果這10個「gig」都用英偉達,那對你們的收入貢獻可能高達4000億美元。幫我們理解一下這個合作,對你意味着什麼?以及為何這項投資是合理的?
黃仁勳:我先回答後一個問題,再回到我的敘述。我認為OpenAI很可能成為下一家數萬億美元級的hyperscale公司。
就像Meta是hyperscale,Google也是,他們會同時擁有C端與企業服務。他們非常可能成為下一家多數萬億美元級的hyperscale公司。如果是這樣,能在他們達到那個規模之前投資進去,是我們能想象到的最聰明的投資之一。你必須投資你熟悉的東西,恰好我們熟悉這個領域。所以這筆錢的回報會非常出色。
我們很樂意投資,但不是必須的,也不是合作的前提;是他們給了投資機會,這太好了。
我們與OpenAI在多個項目上合作。第一,Microsoft Azure的建設,我們會持續推進,這個合作進展非常順利,未來還有數年的建設;第二,OCI(Oracle Cloud Infrastructure)的建設,我想大概有5-7個GW要建。我們與OCI、OpenAI、軟銀一道推進。這些項目都已簽約,正在實施,工作量很大。第三是CoreWeave。所有與CoreWeave相關的……我還在講OpenAI,對,一切都在OpenAI語境裏。
所以問題是,這個新夥伴關係是什麼?它是幫助OpenAI首次自建AI基礎設施。也就是我們直接與OpenAI在芯片、軟件、系統、AI工廠層面協作,幫助他們成為一家完全自運營的hyperscale公司。這會持續相當一段時間,是對他們現有建設的補充。
他們正經歷兩個指數曲線:第一個指數是客戶數量在指數級增長,因為AI在變好、用例在變好,幾乎每個應用現在都連到OpenAI,所以他們正經歷使用指數;
第二個指數是計算量的指數增長。每個使用場景的算力在暴漲。過去是一鍵式推理,現在要先思考再回答。這兩個指數疊加,大幅抬升了計算需求。我們會推進所有這些建設。因而這個新合作是對既有所有合作的「增量」,去支撐這股驚人的指數增長。
Brad Gerstner:你剛說到一個很有意思的點,你認為他們極大概率會成為數萬億美元公司,是很好的投資;同時你們還在幫助他們自建數據中心。過去他們把數據中心外包給微軟,現在他們要自建「全棧工廠」,就像Elon和X那樣,對吧?
Brad Gerstner:想想Colossus的優勢,他們構建全棧,就是hyperscaler,即便自己用不完容量,也能賣給別人。同樣的,Stargate在建設海量容量,他們覺得會用掉大部分,但也能售賣出去。這聽起來很像AWS、GCP(谷歌雲)或Azure,是這意思嗎?
黃仁勳:我認為他們很可能自己用掉,就像X大多會自用。但他們希望與我們建立直接關係——直接工程協作和直接採購關係。就像Zuck、Meta與我們之間的直接關係。我們與Sundar和Google的直接關係,我們與Satya和Azure的直接夥伴關係。他們規模足夠大了,認為該建立這些直接關係了。我很樂意支持,而且Satya(微軟CEO)知道,Larry(谷歌聯合創始人)知道,大家都知道。
華爾街與英偉達之間預期背離:如何理解AI的需求規模
Brad Gerstner:這兒有件事我覺得頗為神祕。你剛提到Oracle 3000億、Colossus的建設,我們知道一些主權國家在建(AI基礎設施),hyperscaler也在建。Sam正以萬億美元的口吻來談這一切。可覆蓋你們股票的華爾街25位賣方分析師的共識卻顯示,你們從2027年開始增長放緩,預2027-2030年年化增速8%。這些人的唯一工作就是給英偉達做增長預測。顯然……
黃仁勳:我們對此很坦然。看,我們經常能輕鬆超預期。
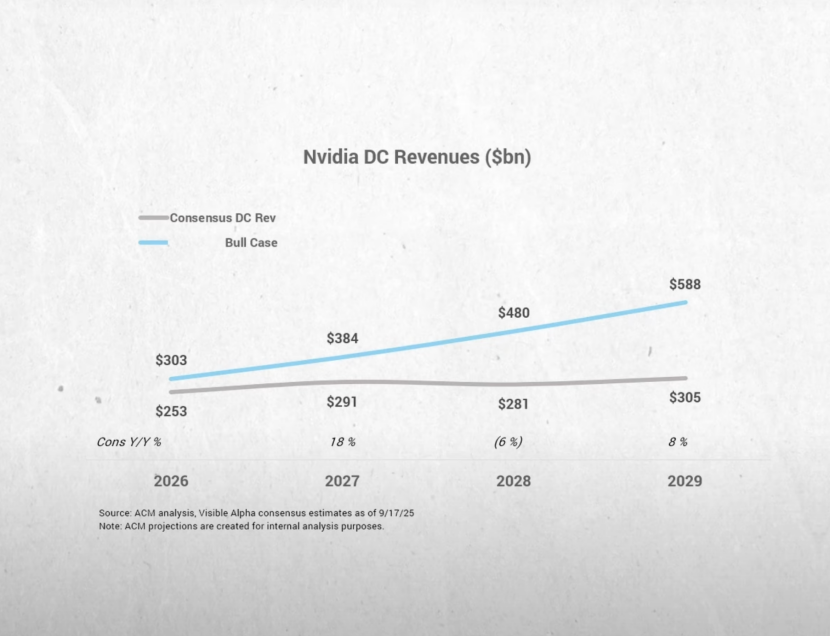
英偉達數據中心營收的增長預期(來源:BG2)
Brad Gerstner:我明白。但這仍是個有趣的「背離」。我每天都在CNBC、彭博上聽到。很多人擔心短缺會轉向過剩,他們不相信持續高增長。他們說,行,我們給姑且信你們的2026年,但2027年可能供給過剩、不再需要那麼多。但共識預測其實顯示這不會發生。我們也做了自己的預測,納入了所有這些數字。
結果是,即便進入「AI時代」兩年半,各方的信念仍然分歧巨大,Sam Altman、你、Sundar、Satya的看法,與華爾街仍然相信的相去甚遠。對此,你依舊感到從容嗎?
黃仁勳:我也不認為這不一致。首先,我們這些「建設者」應該為「機會」而建。我們是建設者。讓我給你三個思考點,有助於你對英偉達的未來更放心。
第一點,是物理定律層面的、最關鍵的一點,通用計算已到盡頭,未來屬於加速計算與AI計算。這是第一點。
你可以這樣想:全球有多少萬億美元的計算基礎設施要被更新換代。所以首先你得認識到通用計算的終結。沒人反對這一點。摩爾定律已死,人們常這麼說。那麼這意味着什麼?通用計算會轉向加速計算。我們與Intel的合作就是在承認通用計算需要與加速計算融合,為他們創造新機會。通用計算正遷移到加速計算與AI。
第二點,AI的首要用例其實已無處不在——在搜索、在推薦引擎等等。基礎的hyperscale計算基礎設施過去由CPU執行推薦,如今要由GPU執行AI。你把傳統計算換成加速計算與AI;你把hyperscale計算從CPU換到加速計算與AI。這是第二點。僅僅滿足Meta、Google、字節跳動、Amazon,把它們傳統的hyperscale方式搬到AI,就是數千億美元的市場。
所以,哪怕先不談AI創造新機會,僅僅是AI改變了舊做法到新做法。然後再談未來。是的,到目前為止我其實只談了「平凡」的事。舊方式不對了。你不會再用煤油燈,而要用電。這就夠了。
然後是更不可思議的,當你走向AI、走向加速計算,會出現什麼新應用?就是我們在談的所有AI相關,機會巨大。怎麼理解?簡單想想,過去電機替代了體力勞動;現在我們有AI——我稱之為AI超級計算機、AI工廠——它們會生成tokens來增強人類智能。而人類智能佔全球GDP的55%-65%……我們就算50萬億美元吧,這50萬億將被某種東西增強。
回到個人層面,假如我僱一位工資10萬美元的員工,再給TA配一個1萬美元的AI,如果這個AI讓那位員工產能翻倍、三倍?我會不會做。一定會做。我現在就在給公司裏每個人配,沒錯,每位協作智能體(co-agents)、每位軟件工程師、每位芯片設計師都已有AI與其協作智能體,覆蓋率100%。
結果是我們做的芯片更好,數量在增長,推進速度更快。公司因此增長更快、招聘更多、生產率更高、營收更高。利潤更高。現在把英偉達的故事套到全球GDP上,很可能發生的是,這50萬億會被……我們取個數,10萬億美元所增強。而這10萬億需要跑在一台機器上。
AI與過去IT的不同在於,過去軟件是事先寫好,跑在CPU上,不怎麼自己「動」。未來,AI要生成tokens,而機器要生成這些tokens、它「在思考」,所以軟件一直在運行;過去是一次性編寫,現在是持續編寫、持續思考。要讓AI思考,就需要工廠。假設這10萬億token的毛利率是50%,其中5萬億需要工廠、需要AI基礎設施。
所以如果你告訴我全球每年的資本開支大概是5萬億美元,我會說這個數看起來說得通。這大概就是未來的輪廓——從通用計算到加速計算;把所有hyperscale都換成AI;然後用AI去增強人類智能,覆蓋全球經濟。
Clark Tang:以今天而言,我們估算年市場規模大約4000億美元,所以TAM從現在到目標是四到五倍的提升。
黃仁勳:沒錯。昨晚(北京時間9月24日)阿里巴巴的吳泳銘(Eddie Wu)說,從現在到20年代末,他們要把數據中心電力(消耗)提升十倍。對吧?你剛纔說四倍?這就對上了。他們要把電力提升十倍,而我們的收入與電力幾乎是正相關。(注:吳泳銘表示,對比2022年GenAI元年,到2032年阿里雲全球數據中心能耗規模將提升10倍)他還說token生成量每幾個月就翻倍。
這意味着什麼?單位能耗性能(perf per watt)必須指數級提升。這就是為什麼英偉達要瘋狂推進單位能耗性能提升,而單位能耗收入(revenue per watt)基本就是收入。
Brad Gerstner:在這個未來裏,有個假設從歷史角度看我覺得很迷人。兩千年裏,全球GDP基本不增長。然後工業革命來了,GDP加速;接着數字革命,GDP又加速。你現在的意思和Scott Bessent(美國現任財長)說的一樣——他認為明年全球GDP增長會到4%。你其實是在說全球GDP增速將加快,因為我們正在給世界提供「數十億同事」來為我們工作。而如果GDP是在既定勞動與資本下的產出,那麼它必須……
黃仁勳:一定會增長。看看AI正在發生的事,AI的技術形態、可用性,諸如大語言模型與AI智能體,都在推動一個新的「智能體行業」。這點毫無疑問。OpenAI就是歷史上收入增長最快的公司,他們在指數級增長。所以AI本身是個高速增長的行業,因為AI需要背後的工廠與基礎設施,這個行業在增長,我的行業也在增長;而因為我的行業在增長,在我們之下的行業也在增長——能源在增長、電力與廠房在增長。這簡直是能源產業的復興。核能、燃氣輪機……看看我們生態之下的那些基礎設施公司,他們做得很棒,大家都在增長。
Brad Gerstne:這些數字讓大家都在談是否會「供給過剩」或「泡沫」。Zuckerberg上周在一個播客說了,可能會有短期的「氣阱」(Airpocket),Meta可能會多花個100億美元之類的。但他說,這不重要。對他業務的未來而言太關鍵了,這是必須承擔的風險。但從博弈角度看,這有點像「囚徒困境」。
黃仁勳:開心的囚徒。
Brad Gerstner:再捋一遍。今天我們估算到2026年,會有1000億美元的AI收入,不含Meta,也不含跑推薦引擎的GPU還有搜索等其他工作負載,我們就先算1000億。
黃仁勳:但hyperscale行業本身到底有多大?這個行業現在的基數是多少?
Brad Gerstner:以萬億美元計。
黃仁勳:對。這個行業會先部署AI,不是從零起步,你得從這裏開始。
Brad Gerstner:不過懷疑者會說,我們必須從2026年的1000億,長到2030年至少1萬億的AI收入。你剛纔還談到5萬億。從全球GDP的自下而上推演看,你能看到從1000億到1萬億在未來五年實現嗎?
黃仁勳:能,而且我會說我們其實已經到了。因為Hyperscalers已經把CPU遷到AI,他們的整個收入基座如今都由AI驅動。
Brad Gerstner:是的。
黃仁勳:沒有AI就沒有TikTok,對吧?沒有AI就沒有YouTube Shorts。Meta做的為你定製、個性化的內容,沒有AI就做不到。以前那些事情,靠人類事先創作、提供幾個選項,再由推薦引擎挑選。現在是AI生成無限多的選項。
Brad Gerstner:這些轉變已經發生:我們從CPU遷到GPU,主要是為了那些推薦引擎。
黃仁勳:對。Zuck會告訴你,我在SIGGRAPH時他也說過,他們其實到得有點晚。Meta用GPU也就一年半、兩年的事。搜索上用GPU更是嶄新的、啱啱開始的。
Brad Gerstner:所以論證是,到2030年我們有1萬億AI收入的概率幾乎確定,因為我們幾乎已經達到了。
接着我們只談「增量」。不管你做自下而上還是自上而下,我剛聽了你按全球GDP佔比的自上而下的分析。那你覺得,未來三到五年內,出現「供給過剩(glut)」的概率有多大?
黃仁勳:在我們把所有通用計算徹底轉換為加速計算與AI之前,我認為出現過剩的概率極低。
Brad Gerstner:會花幾年?
黃仁勳:直到所有推薦引擎都基於AI,直到所有內容生成都基於AI。因為面向消費者的內容生成很大程度就是推薦系統之上的,所以所有這些都會轉向AI生成。直到傳統意義上的hyperscale全部遷到AI,從購物到電商等一切都遷過去。
Brad Gerstner:但所有這些新建項目,我們談的是「萬億級」,總是提前投資。那如果你們看到了放緩或過剩,是不是還「不得不」把錢投進去?還是說,一旦看到放緩跡象,再隨時收縮?
黃仁勳:實際上正相反,因為我們在供給鏈的末端,我們按需響應。現在,所有VC都會告訴你——你們也知道——全球短缺的是「計算」,不是GPU的數量短缺。只要給我訂單,我就造。過去兩年我們把整個供應鏈都打通了,從晶圓啓動、到封裝、到HBM內存等等,我們都加足了馬力。需要翻倍,我們就翻倍,供應鏈已備好。我們現在等的是需求信號。當雲服務商、hyperscaler和客戶做年度計劃給我們預測時,我們就響應,並按那個預測去建。
問題是,他們每次給我們的預測都會錯,因為預測都偏低。於是我們總處於「緊急追趕」模式,已經持續了好幾年,每一輪預測都比上一年顯著上調。
Brad Gerstner:但還不夠。比如去年,Satya看起來稍微收斂了一點,有人說他像房間裏那個「更穩重的成年人」,壓一壓預期。但幾周前他又說,我們今年也建了兩個「gig」,未來還會加速。你是否看到那些傳統hyperscalers——相較於Core Weave或Elon的X,或者相較於StarGate——此前略慢一些的,現在都在加倍投入,而且……
黃仁勳:因為第二條指數來了。我們已經有一條指數在增長,AI的應用和滲透率指數級增長。第二條指數是「推理與思考」,這就是我們一年前討論的。我當時說,一旦你把AI從「一次性出手、記憶並泛化」推進到「推理、檢索與用工具」,AI就在思考,它會用更多算力。
Clark Tang:回到你剛纔的點,hyperscale客戶無論如何都需要把內部工作負載從通用計算遷到加速計算,他們會穿越周期持續建設。我想部分hyperscalers的負載結構不同,不確定消化速度,現在大家都認定自己嚴重低配了。
黃仁勳:我最喜歡的應用之一就是傳統的數據處理,即結構化與非結構化數據處理。很快我們會宣佈一個關於「加速數據處理」的重大計劃。
數據處理佔據了當今世界絕大多數CPU,它仍然完全跑在CPU上。去Databricks,大多是CPU;去Snowflake,大多是CPU;Oracle的SQL處理,大多是CPU。
大家都在用CPU做SQL/結構化數據。未來,這一切都會遷到AI數據。這是一個極其龐大的市場,我們會推進過去。但你需要英偉達的全部能力——加速層與領域專用的「配方」。數據處理層的「配方」需要我們去構建,但它要來了。
「循環營收」質疑:投資機會不綁定任何條件
Brad Gerstner:還有一個質疑點。昨天我打開CNBC,他們說的是「過剩、泡沫」。換到彭博,是「循環交易與循環營收(round-tripping、circular revenues)」。給在家觀看的觀衆解釋下,這指公司之間締結看似交易、實則缺乏真實經濟實質的安排,人為抬高營收。
換言之,增長不是來自真實的客戶需求,而是財務數字上。所以當你們、微軟或亞馬遜投資那些同時也是你們大客戶的公司時,比如你們投資OpenAI,而OpenAI又購買數百億美元的芯片。
請提醒我們、也提醒大家:當彭博等媒體分析師拿「循環營收」大做文章時,他們到底誤解了什麼?
黃仁勳:建10GW的(數據中心)規模大概就是4000億美元左右吧。那4000億要主要由他們的offtake(消納能力/下游需求)來支撐,它在指數增長。
(支出)這得由他們自有資本、股權孖展和可獲得的債務來支持,這是三種工具。能融到多少股權與債務,取決於他們對未來收入的把握程度。精明的投資人與授信人會綜合權衡這些因素。這是他們公司的事,不是我的。
我們當然要和他們緊密合作,以確保我們的建設能支持他們持續增長,但收入端與投資端無關。投資機會不是綁定任何條件的,是一個純投資機會。正如前面說的,這家公司很可能成為下一家多萬億美元級的hyperscale公司。誰不想持有它的股權?我唯一的遺憾是,他們早年就邀請我們投資,當時我們太「窮」了,投得不夠,真該把所有錢都投進去。
Brad Gerstner:而現實是,如果你們不把本職工作做到位,比如Vera Rubin最終不成好芯片,他們也可以去買別家的。對吧?他們沒有義務必須用你們的芯片。正如你說的,你們看待這件事是機會性的股權投資。
黃仁勳:我們投了xAI、投了CoreWeave,這都是很棒的投資。
Brad Gerstne:回到「循環營收」的討論,還有一個根本點是,你們把一切都擺在台面上,告訴大家你們在做什麼。而其背後的經濟實質是什麼?並不是雙方互相倒騰營收。我們看到有用戶每月為ChatGPT付費,有15億月活在用這個產品。你剛說世界上每家企業要麼擁抱這一切,要麼被淘汰。每個主權國家都把這視為其國防與經濟安全的「生死攸關」,就像核能一樣。
黃仁勳:問問看,有哪一個人、公司、國家會說「智能」對我們是可選項?沒有。這就是基礎。關鍵在於「智能的自動化」。
摩爾定律已死,現在需要極致的軟硬件協同設計
Brad Gerstner:需求問題我問得夠多了,我們聊系統設計。我接下來會把話題遞給Clark。2024年你們切換到了年度發布節奏,對吧?
Hopper之後,2025年的Grace Blackwell是一次巨大升級,需要數據中心進行重大改造。26年下半年會有Vera Rubin,27年有Rubin Ultra,28年有Feynman。年度發布節奏進行得如何?為什麼要改為年度發布?英偉達內部的AI是否讓你們能落實年度發布?
黃仁勳:是的,答案是肯定的。沒有它,英偉達的速度、節奏和規模都會受限。現在沒有AI,根本不可能建出我們如今的產品。為什麼這麼做?記得Eddie(吳泳銘)在財報或大會上說過、Satya說過、Sam也說過……token生成速率在指數級上升,用戶使用在指數級上升。我記得OpenAI說周活躍用戶有8億左右,對吧?從ChatGPT推出才兩年。
Brad Gerstner:而且這些用戶的每次使用都在生成更多token,因為他們在使用「推理時思考」(inference-time reasoning)。
黃仁勳:沒錯。所以第一點是:在兩個指數疊加的情況下,除非我們以不可思議的速度提升性能,否則token生成成本會持續上升。
因為摩爾定律已死,晶體管的單位成本每年幾乎不變,電力也大致不變。在這兩條「定律」約束下,除非我們發明新技術降成本,否則即便給對方打個幾個百分點的折扣,也無法抵消兩個指數增長的壓力。因此我們必須每年以跟上這個指數的節奏去提升性能。
比如從Kepler(注:2012年4月發布)一路到Hopper(注:2022年3月發布),大概實現了100000的提升。那是英偉達 AI旅程的開端,十年十萬倍。Hopper到Blackwell,因為NVLink等,我們在一年內實現了30×的系統級提升;接下來Rubin還會再來一波「x」(數倍),Feynman再一波「×」……
之所以能做到,是因為晶體管本身幫不上太多忙了。摩爾定律基本只剩密度在漲,性能沒有相應提升。所以我們必須把問題在系統層面完全拆開,所有芯片同步升級,軟件棧與系統同步升級,這是極致的「協同設計(co-design)」。
以前沒人做到這個層級。我們同時改變CPU、重塑CPU,與GPU、網絡芯片、NVLink縱向擴展、Spectrum-X橫向擴展。當然還要去構建更大的系統,在多個AI工廠之間做跨域互聯。並且以年度節奏推進。所以我們自身也在技術上形成了「指數疊指數」。這讓客戶能持續拉低token成本,同時通過預訓練、後訓練與「思考」讓token更聰明。AI變聰明,使用就更多,使用更多就指數增長。
Brad Gerstner:極致的協同設計是什麼?
黃仁勳:極致協同設計,意味着你要同時優化模型、算法、系統與芯片。
當摩爾定律還能推動時,只要讓CPU更快,一切都會更快。那是在「盒子裏」創新,只需把那顆芯片做快。但如果芯片不再變快,你怎麼辦?就要跳出原有框架來創新。
英偉達改變了行業,因為我們做了兩件事——發明了CUDA、發明了GPU,並把大規模協同設計的理念落地。
這就是為什麼我們覆蓋這麼多行業。我們在構建大量庫與協同設計。第一,全棧的極致不僅在軟件與GPU,還延伸到數據中心層面的交換與網絡,以及它們內部的所有軟件:交換機、網絡接口、縱向擴展與橫向擴展,跨全部層面優化。其結果就是Blackwell對Hopper的30×提升。摩爾定律根本做不到,這是極致協同設計的成果。
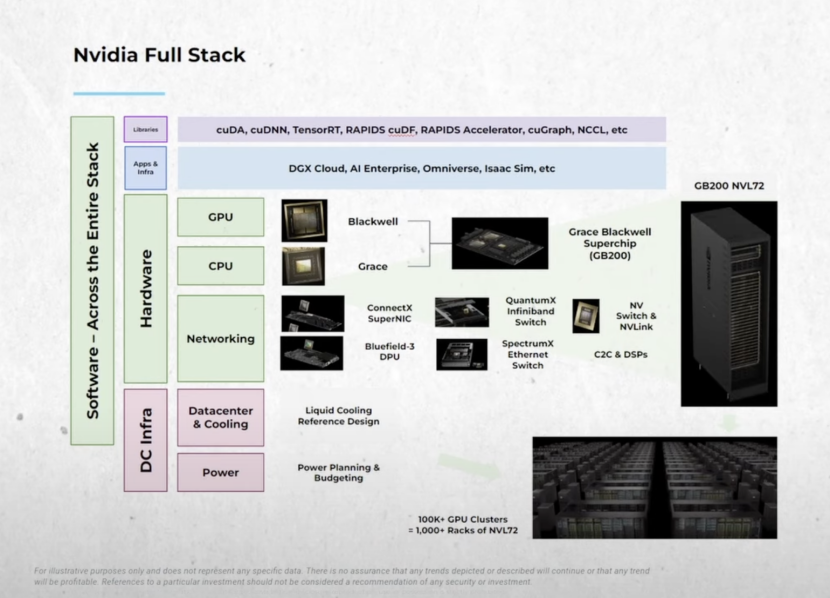
英偉達全部技術棧(來源:BG2)
Brad Gerstner:這些都源自極致協同設計。
黃仁勳:是的,這就是為什麼我們要做網絡、做交換、做縱向/橫向/跨域擴展,做CPU、做GPU、做NIC。也是為什麼英偉達的軟件如此豐富。我們在開源軟件上的貢獻提交量,全球能比的沒幾家。而且這還只是AI領域。別忘了我們在計算機圖形、數字生物學、自動駕駛等。我們產出的軟件規模極其可觀,這讓我們能做深度且極致的協同設計。
Brad Gerstner:我從你一位競爭對手那裏聽說,你們這麼做能降低token生成成本。但與此同時,你們的年度發布節奏讓競爭者幾乎很難跟上。因為你們給供應鏈三年的可見性,供應鏈鎖定更深,心裏有底該供到什麼規模。
黃仁勳:你不妨這樣想:要讓我們一年做幾千億美元級的AI基礎設施建設想想我們在一年前就必須提前預備多少產能。我們說的是數千億美元級的晶圓啓動量、DRAM採購量。這個規模,幾乎沒有公司能承接。
英偉達的護城河為什麼更寬了:如何看ASIC的競爭力
Brad Gerstner:你們今天的護城河比三年前更寬了嗎?
黃仁勳:是的。
首先,競爭者比以往更多,但難度也比以往更大。因為晶圓成本在上升。除非你在極致規模上做協同設計,否則你交不出那個「數倍」級的增長,這是第一點。所以,除非你一年同時做6-8顆芯片,否則不行。重點不是做一顆ASIC,而是構建一座AI工廠系統。這座系統裏有很多芯片,它們都協同設計。它們共同交付我們幾乎固定節奏能拿到的那個「10×」。
所以第一,協同設計必須極致。第二,規模必須極致。當你的客戶部署1個GW,那就是四五十萬顆GPU,要讓50萬顆GPU協同工作,這就是個奇蹟。
所以客戶是在承擔巨大的風險來購買這些。你得想,有哪個客戶會在一個架構上下500億美元的採購訂單?一個全新的、未經大規模驗證的架構?
你再興奮、大家再為你喝彩,當你啱啱展示第一個硅片的時候,會有誰給你500億美元的訂單?你又為何敢在一顆啱啱流片的芯片上啓動500億美元的晶圓?但對英偉達來說,我們敢,因為我們的架構高度成熟與積累的信用。其二,我們客戶的規模極其驚人。再者,我們供應鏈的規模也極其驚人。誰會替一家企業去提前啓動這些、預構建這麼多,除非他們確信英偉達能把它交付到底?對吧?他們相信我們能交付到全球所有客戶手裏,願意一次性啓動數千億美元的供應。
這就是「規模」的故事。
Clark Tang:順着這個點,全球一個最大的爭論是「GPU vs ASIC」,比如Google的TPU、Amazon的Trainium。Arm到OpenAI、Anthropic在傳出自研……你去年說過我們構建的是「系統」,不是「芯片」,而你們在堆棧的每一層都驅動性能提升。你還說過這些項目裏很多可能永遠到不了生產規模,事實上…大多數都到不了。在TPU看似成功的前提下,你今天如何看這片正在演進的版圖?
黃仁勳:Google的優勢在「前瞻」。
記得他們在一切開始之前就做了TPU v1。這跟創業沒區別。你應當在市場尚未做大之前去創業,而不是等市場漲到萬億級再來。所有VC都懂一個謬誤:市場很大,只要拿到幾個百分點就能做成大公司。這是錯的。你該在一個很小的領域拿到「幾乎全部份額」,這就是英偉達當年做的,也是TPU當年做的。
所以今天那些做ASIC的人的挑戰在於:市場看起來很「肥」,但別忘了,這個「肥市場」已經從一顆叫GPU的芯片,演化為我剛描述的「AI工廠」。
你們剛看到我宣佈了CPX(注:Rubin CPX GPU,英偉達專為長語境推理設計的芯片),這是一顆用於「上下文處理與擴散式視頻生成」的芯片,是很專門但很重要的數據中心負載。我剛纔也暗示,也許會有「AI數據處理」處理器。因為你需要「長期記憶」和「短期記憶」。KVCache的處理非常重,AI記憶是大事。你希望你的AI有好記憶。圍繞整個系統處理KVCache非常複雜,也許它也需要一顆專屬處理器。
你可以看到,英偉達今天的視角,是俯瞰全體AI基礎設施——這些了不起的公司要如何讓多元且變動的工作負載流經系統?看看Transformers,這個架構在快速演化。若非CUDA如此好用、易於迭代,他們要如何進行如此海量的實驗,來決定採用哪種Transformer變體、哪類注意力算法?如何去做「解耦/重構(disaggregate)」?CUDA之所以能幫你做這一切,是因為它「高度可編程」。
所以看我們的業務,你得回到三五年前那些ASIC項目啓動之時,那會兒的行業「可愛而簡單」,只有GPU。一兩年後,它已巨大且複雜;再過兩年,它的規模會非常之大。所以,作為後來者要殺入一個巨量市場,這仗很難打。
Clark Tang:即便那些客戶在ASIC上成功了,他們的算力機隊裏也應該有個「優化配比」,對吧?我覺得投資人喜歡非黑即白,但其實即便ASIC成功了,也要有個平衡。會有很多不同的芯片或部件加入英偉達的加速計算生態,以適配新生的負載。
Brad Gerstner:換句話說,Google也是你們的大客戶。
黃仁勳:Google是我們的大GPU客戶。Google很特殊,我們必須給予尊重。TPU已經迭代到v7了,對吧?這對他們也是極大挑戰。他們做的事情極難。
所以我想先理順一下芯片的分類。一類是「架構型」芯片:x86CPU、ArmCPU、英偉達GPU,屬於架構級,有豐富的IP與生態,技術很複雜,由架構的擁有者構建。
另一個是ASIC,我曾就職於發明ASIC概念的公司LSI Logic。你也知道,LSI早已不在。原因在於,當市場規模不太大時,ASIC很棒,找一家代工/設計服務公司幫你封裝整合併代工生產,他們會收你50-60個點的毛利。
但當ASIC面向的市場變大後,會出現一種新方式叫COT(Customer-Owned Tooling,客戶自有工具),誰會這麼做?比如Apple的手機芯片,量級太大,他們絕不會去付給別人50-60%的毛利做ASIC,他們會自己掌握工具。
所以,當TPU變為一門大生意時,它也會走向COT,這毫無疑問。話說回來,ASIC有它的位置——視頻轉碼器的市場永遠不會太大;智能網卡(Smart NIC)的市場也不會太大。
所以當你看到一家ASIC公司有十來個甚至十五個ASIC項目時,我並不驚訝,因為可能其中五個是Smart NIC、四個是轉碼器。它們都是AI芯片嗎?當然不是。如果有人做一顆為某個特定推薦系統定製的處理器,做成ASIC,當然也可以。但你會用ASIC來做那顆「基礎計算引擎」嗎?要知道AI的工作負載變化極快。有低延遲負載,有高吞吐負載;有聊天token生成,有「思考」負載,有AI視頻生成負載,現在你在談的是……
Clark Tang:算力機羣的 「主力骨幹」。
黃仁勳:這纔是英偉達的定位。
Brad Gerstner:再通俗點講,就像「象棋vs跳棋」。那些今天做ASIC的人,不管是Trainium還是別的某些加速器,本質是在造一顆「更大機器中的一個部件」。
而你們造的是一個「非常複雜的系統、平台、工廠」,現在你們又開始做一定程度上的「開放」。你提到了CPX GPU,在某種意義上,你們在把工作負載「拆分」到最適合它的硬件切片上。
黃仁勳:沒錯。我們發布了一個叫「Dynamo」的東西——解耦後AI負載編排(disaggregated orchestration),而且開源了它,因為未來的AI工廠就是解耦的。
Brad Gerstner:你們還發布了NVLink Fusion,甚至對競爭對手開放,包括你們啱啱投資的Intel,這就是讓他們也能接入你們正在建的工廠——沒人瘋狂到要獨自建完整工廠。但如果他們有足夠好的產品、足夠有吸引力,終端客戶說我們想用這個替代某個Arm GPU,或者替代你們的某個推理加速器等,他們就可以插進來。
黃仁勳:我們非常樂意把這些接上。NV Fusion是個很棒的主意,我們也很高興與Intel合作——它把Intel的生態帶進來,全球大多數企業工作負載仍跑在Intel上。它融合了Intel生態與英偉達的AI生態與加速計算。我們也會與Arm做同樣的融合。之後還會與更多人做。這為雙方都打開了機會,是雙贏、非常大的雙贏。我會成為他們的大客戶,他們也會把我們帶到更大的市場機會前。
Brad Gerstner:與此緊密相關的,是你提出一個讓人震驚的觀點:就算競爭者造的ASIC芯片今天已經更便宜,甚至就算他們把價格降到零,也依然會買英偉達的系統。因為一個系統的總運營成本——電力、數據中心、土地等——以及「智能產出」,選擇你們仍然更划算,即使對方的芯片白送。
黃仁勳:因為單是土地、電力、廠房等設施就要150億美元。
Brad Gerstner:我們試着做過這背後的數學題。對很多不熟悉的人來說,這聽起來不合邏輯,你把競品芯片定價為零,考慮到你們芯片並不便宜,怎麼可能還是更划算?
黃仁勳:有兩種看法。一是從營收角度。大家都受「電力」約束。假設你拿到了新增2GW的電力,那你希望2GW能被轉化為營收。如果你的「token單位能耗(token per watt)」是別人的兩倍,因為你做了深度且極致的協同設計,你的單位能耗性能更好,那你的客戶就能從他們的數據中心產出兩倍營收。誰不想要兩倍營收?而就算有人給他們15%的折扣——比如我們75%的毛利,別人50%-65%的毛利——這點差距也絕不可能彌補Blackwell與Hopper之間30×的差距。

過去10年大模型單位能效提升了10萬倍(來源:BG2)
就算我們把Hopper和別人的ASIC看作同級,Blackwell也有30×的空間。所以在同一個GW上,你要放棄30×的營收。這代價太大了。就算對方白送芯片,你也只有2GW的電力可用,你的機會成本高得離譜——你永遠會選擇「單位能耗」最強的那套系統。
Brad Gerstner:我從一家hyperscaler的CFO那裏聽說過,鑑於你們芯片帶來的性能提升,特別是以單位能耗(token/gigawatt)和「電力供給」為硬約束,他們不得不升級到新的周期。展望Rubin、Rubin Ultra、Feynman,這條曲線會延續嗎?
黃仁勳:我們現在一年做六七顆芯片,每一顆都是系統的一部分。系統軟件無處不在。要實現Blackwell的30×,需要跨這六七顆芯片的聯調與優化。想象一下,我每年都這麼做,砰、砰、砰地連發。如果你在這鍋「芯片大雜燴」裏只做一顆ASIC,而我們卻在整鍋裏到處優化,這就是個很難的問題。
Brad Gerstner:這讓我回到開頭的護城河問題。我們做投資許久了,在整個生態投資,也投了你的競爭對手,比如Google、博通。
但當我從第一性原理出發,你們改為以年為單位的發布節奏、跟供應鏈共研、規模遠超所有人預期,這對資產負債表與研發有雙重規模要求,你們通過收購與自研推進了NVFusion、CPX等。因此,你們的護城河在拓寬,至少在「構建工廠或打造系統」這件事上是如此。
但有趣的是,你們的估值倍數比那些人都低。我認為部分源自「大數定律」——一家4.5萬億美元的公司不可能再變更大了。但一年半前我也問過你,如果市場會把AI負載提升10×或5×,我們也知道Capex的走勢。在你看來,結合剛纔談到的優勢下,營收「不大幅更高」的概率有多大?
黃仁勳:我這樣回答,我們的機會遠大於市場共識。
Brad Gerstner:我認為英偉達很可能成為第一家10萬億美元的公司。我在這行待得夠久了。十年前,大家還說世上不可能有1萬億美元公司。現在我們有十家。今天的世界更大了,對吧?
黃仁勳:世界變大了。而且人們誤解我們在做什麼。大家記得我們是「芯片公司」——沒錯,我們造芯片,造的是全球最驚人的芯片。但英偉達實際上是一家AI基礎設施公司。
我們是你的「AI基礎設施合作伙伴」。我們與OpenAI的夥伴關係就是最好證明。我們是他們的AI基礎設施夥伴。我們以很多方式與客戶合作。我們不要求任何人買我們的一切。我們不要求你買整機櫃,你可以買一顆芯片、一個部件、我們的網絡,或僅僅買我們的CPU。也有人只買我們的GPU,配別家的CPU和網絡。我們基本上是按你喜歡的方式賣。我的唯一請求是,買點兒我們的東西就行。
Brad Gerstner:你說過,不只是更好的模型,還要有「世界級建造者」。你說,也許全國最強的建設者是Elon Musk。我們聊過Colossus One,他在那裏把二十幾萬顆H100/H200組成一個「相干」的大集羣。現在他在做Colossus Two,可能是50萬顆GPU、相當於幾百萬H100的「等效」相干集羣。
黃仁勳:如果他先於所有人做到1GW,我不驚訝。
Brad Gerstner:既能做軟件與模型,又懂如何打造這些集羣的「建造者」有什麼優勢?
黃仁勳:這些AI超級計算機極其複雜。技術複雜,採購複雜(孖展),拿地、拿電力與廠房複雜,建設複雜、點亮複雜。這恐怕是人類史上最複雜的系統工程之一。Elon的優勢在於:在他腦子裏,這些系統是一體協同的,所有相互依賴關係都在他一個人腦中,包括孖展。是的,而且……
Brad Gerstner:他自己就是個「大GPT」、一台「大超算」。
黃仁勳:對,終極「GPU」。他有很強的緊迫感,他非常想把它建出來。當「意志」與「能力」相遇時,不可思議的事會發生。
主權AI:AI正在成為每個國家的基礎設施
Brad Gerstner:你深度參與的另一塊是主權AI……回看30年前,你大概難以想象如今你經常出入白宮。總統說你與英偉達對美國國家安全至關重要。面對這些,先給我個背景——若不是各國把這件事視為「生死攸關」,至少不亞於我們在1940年代看待「核」,你也不會出現在那些地方。如今如果沒有一個由政府出資的「曼哈頓計劃」,那它也由英偉達、OpenAI、Meta、Google來出資。
黃仁勳:沒有人需要原子彈,但人人都需要AI。這就是巨大的不同。AI是現代軟件。這是我一開始就說的:從通用計算到加速計算,從人寫代碼到AI寫代碼,這個根基不能忘,我們已經重塑了計算。它需要被普及,這就是所有國家都意識到必須進入AI世界的原因,因為每個國家都必須在計算中保持現代化。不會有人說:你知道嗎,我昨天還用計算機,明天我就靠木棍和火種了。所以每個人都得繼續向前,只是計算被現代化了而已。
第二,為了參與AI,你必須把自己的歷史、文化、價值觀寫進AI。隨着AI越來越聰明,核心AI學這些的速度很快,不必從零開始。所以我認為每個國家都需要一定的主權能力。我建議大家都用OpenAI、用Gemini、用Grok、用Anthropic……用各類開放模型。但他們也應該投入資源去學習如何「構建」AI,這不僅是為了語言模型,也是為了工業模型、製造模型、國家安全模型。他們要培養一整套「自己的智能」。因此,每個國家都應具備主權能力。
Brad Gerstner:這是否也是你在全球聽到與看到的?
黃仁勳:是的。他們都會成為OpenAI、Anthropic、Grok、Gemini的客戶,但同時也需要建設自己的基礎設施。這就是英偉達在做的大想法——我們在構建「基礎設施」。就像每個國家需要能源基礎設施、通信與互聯網基礎設施,現在每個國家都需要AI基礎設施。