今天凌晨,阿里巴巴開源了兩款Qwen3系列新模型,Qwen3-Embedding和Qwen3-Reranker。
這兩個模型是專為文本表徵、檢索與排序任務設計,基於 Qwen3基礎模型訓練,充分繼承了Qwen 3在多語言文本理解方面的優勢,支持119種語言。
根據測試數據顯示,在多語言文本表徵基準測試中,Qwen3 Embedding的性能非常出色。其中,8B參數以70.58的高分排名第一,超越了衆多商業API服務,例如,谷歌的Gemini-Embedding。
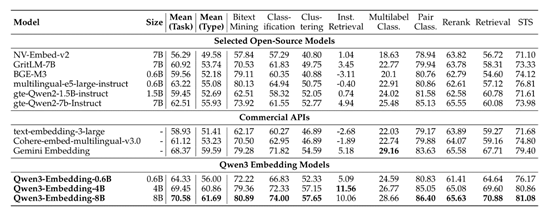
在排序任務中,Qwen3 Reranker 系列模型同樣展現了強大的能力。在基本相關性檢索任務中,8B模型在多語言檢索任務中取得了69.02的高分,在中文檢索任務中得分達到 77.45,在英文檢索任務中得分達到 69.76,顯著優於其他基線模型。
開源地址:https://huggingface.co/collections/Qwen/qwen3-embedding-6841b2055b99c44d9a4c371f
https://huggingface.co/collections/Qwen/qwen3-reranker-6841b22d0192d7ade9cdefea
文本表徵和排序是自然語言處理與信息檢索中的核心任務,主要用於網絡搜索、問答系統、推薦系統等多個領域。高質量的文本表徵能夠使模型精準捕捉文本間的語義關係,而有效的排序機制則確保最相關的結果能夠優先呈現給用戶。
但如何在大規模數據上訓練出既具備泛化能力又能精準檢索、排序的模型很困難,而新版Qwen3大幅度領先其他模型。
在模型架構方面,這兩款模型採用了基於Qwen3基礎模型的密集版本,並提供了三種不同參數規模的模型配置,分別是0.6B、4B和8B參數,以滿足不同場景下的性能與效率需求。
對於文本嵌入模型,研究人員採用了因果注意力機制的大模型,並在輸入序列的末尾添加了[EOS]標記,從而從最後一層的隱藏狀態中提取文本的語義表徵。這種設計不僅增強了模型對文本語義的理解能力,還使得模型能夠根據不同的任務需求進行靈活調整。
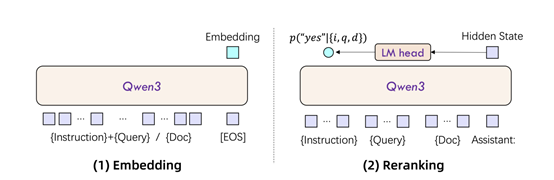
此外,為了使模型能夠更好地遵循指令,在下游任務中表現出色,研究人員將指令與查詢文本拼接為單一輸入上下文,而文檔保持不變。這種設計使得模型能夠更好地理解和處理複雜的語義任務,提升了模型在多語言和跨語言任務中的表現。
對於排序模型,採用了單塔結構,將文本對(如用戶查詢與候選文檔)作為輸入,並通過大模型的對話模板將相似性評估任務轉化為二分類問題。模型能根據輸入的指令、查詢和文檔,判斷文檔是否符合查詢要求,並輸出相關性得分。這種設計使得模型能夠更加精準地評估文本對之間的相關性,從而在排序任務中取得更好的效果。
在訓練範式方面,該系列模型採用了創新的多階段訓練方法,包括大規模無監督預訓練、高質量數據的監督微調以及模型融合策略。
在無監督預訓練階段,研究人員利用Qwen3基礎模型的文本生成能力,合成大規模的弱監督訓練數據。這些數據涵蓋了多種任務類型、語言和領域,為模型提供了廣泛的學習素材。
這種合成數據的方法不僅提高了數據的可控性,還能夠在低資源語言和領域中生成高質量的數據,突破了傳統方法依賴社區論壇或開源數據篩選獲取弱監督文本對的侷限性,實現了大規模弱監督數據的高效生成。

在監督微調階段,研究人員選擇了高質量的小規模標註數據進行訓練,進一步提升模型的性能。這一階段的訓練數據不僅包括開源的標註數據集,例如,MS MARCO、NQ、HotpotQA等,還篩選了部分合成數據。通過簡單的餘弦相似度計算,從合成數據中篩選出高質量的數據對,進一步提升模型的性能。這種策略不僅提高了模型的泛化能力,還在多種基準測試中取得了優異的成績。
最後,在模型融合階段,研究人員採用了基於球面線性插值的模型融合技術。通過合併微調過程中保存的多個模型檢查點,模型能夠在不同數據分佈上表現出更好的性能。這一策略顯著提升了模型的穩定性和一致性,增強了模型的魯棒性和泛化能力。
除了上述技術創新點,這兩個模型在訓練數據合成方面也進行了精心設計。為了生成高質量的合成數據,研究人員採用了精心設計的提示策略。在文本檢索任務中,模型通過多語言預訓練語料庫生成數據,並為每個文檔分配特定的角色,以模擬潛在用戶對該文檔的查詢。

此外,提示中還包含了多種維度,如查詢類型關鍵詞、事實性、總結性、判斷性、查詢長度、難度和語言等,確保了合成數據的高質量和多樣性。通過這種方式生成的合成數據,不僅在數量上滿足了大規模預訓練的需求,在質量上也能夠有效地提升模型的性能。