DeepSeek正式發布並開源全新系列模型DeepSeek-V4預覽版,分為Pro和Flash兩個版本。V4-Pro在Agent能力、世界知識和推理性能上達到開源領先水平,可比肩頂級閉源模型;V4-Flash參數更小,速度更快、成本更低。兩款模型均支持百萬字(1M)超長上下文,採用創新注意力機制,大幅降低計算與顯存需求。
全新系列模型 DeepSeek-V4 的預覽版本正式上線並同步開源。
4月24日,中國人工智能公司DeepSeek再度向開源社區投下重磅,其全新系列模型DeepSeek-V4預覽版正式發布並同步開源,在Agent能力、世界知識與推理性能三大維度宣稱達到國內及開源領域領先水平。
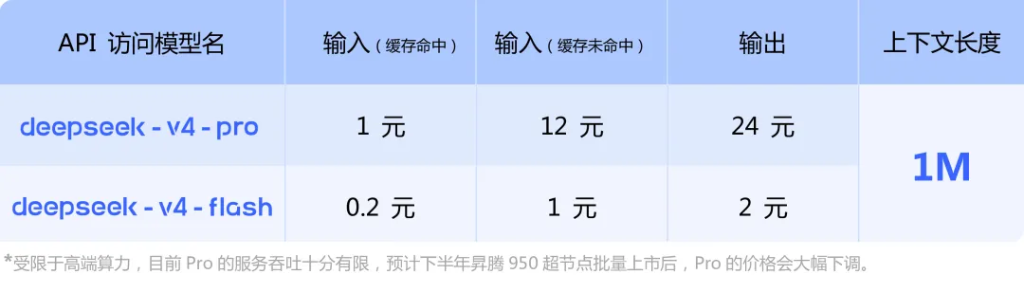
DeepSeek-V4分為Pro與Flash兩個版本,均支持百萬(1M)token超長上下文,兩個版本均大幅降低了對計算和顯存的需求。

API服務同步上線,開發者將model參數修改為deepseek-v4-pro或deepseek-v4-flash即可調用,接口兼容OpenAI ChatCompletions與Anthropic兩套標準。
DeepSeek同時披露,受限於高端算力供給,Pro版本當前服務吞吐十分有限,預計下半年隨華為昇騰950超節點批量上市後,Pro版本價格將大幅下調。
值得注意的是,昇騰CANN將在16點直播DeepSeek V4在昇騰平台的首發。
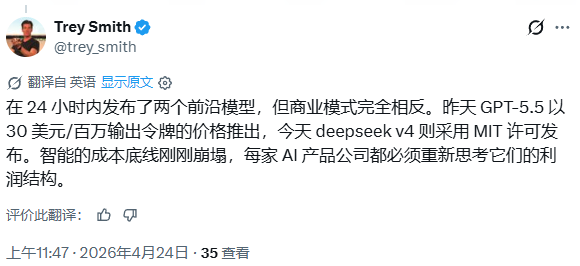
此次發布與OpenAI前一天推出GPT-5.5幾乎同步落地,兩款產品定價策略截然對立。有網友指出:
GPT-5.5昨日以每百萬輸出token 30美元的定價上線,DeepSeek V4今日以MIT許可證開源發布,AI智能的成本底線啱啱崩塌,每一家AI產品公司都不得不重新審視自己的利潤結構。
網友Enrico亦評價稱DeepSeek V4"真的令人印象深刻,快速、智能",不過他認為輸出價格為每百萬token 3.48美元,"並不便宜",但表示LocalAI將推動該模型面向更廣泛用戶群體普及。

DeepSeek-V4-Pro:性能比肩頂級閉源模型
DeepSeek-V4-Pro是本次發布的旗艦版本,官方將其定位為性能比肩頂級閉源模型。
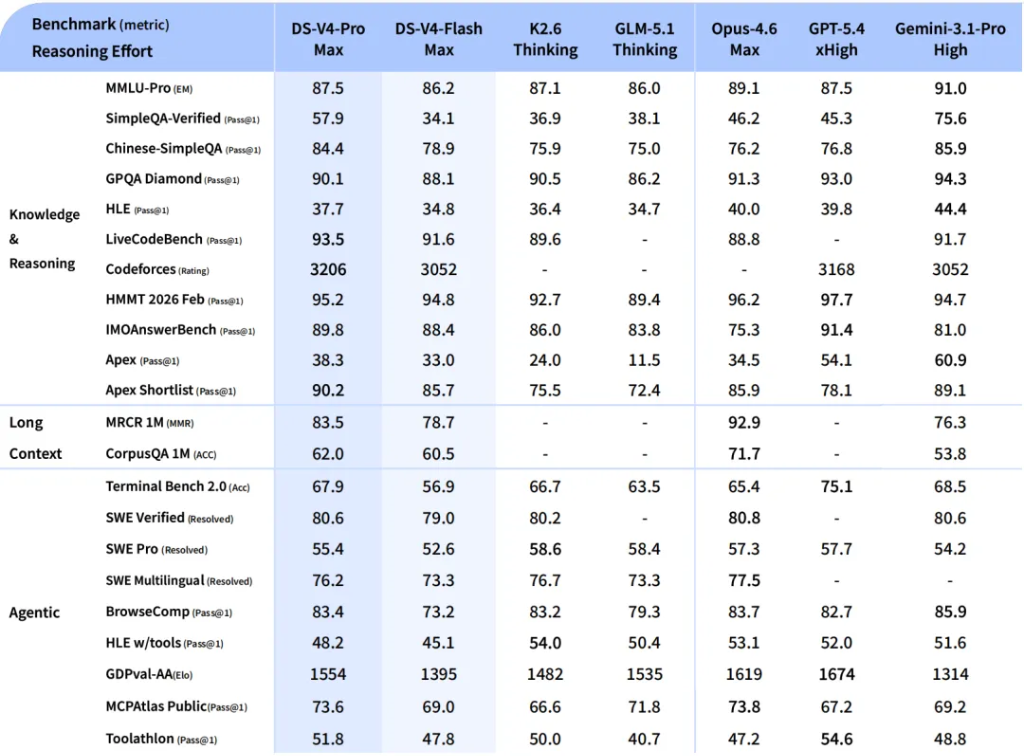
在推理性能方面,V4-Pro在數學、STEM及競賽型代碼評測中宣稱超越當前所有已公開評測的開源模型,並取得比肩世界頂級閉源模型的成績。
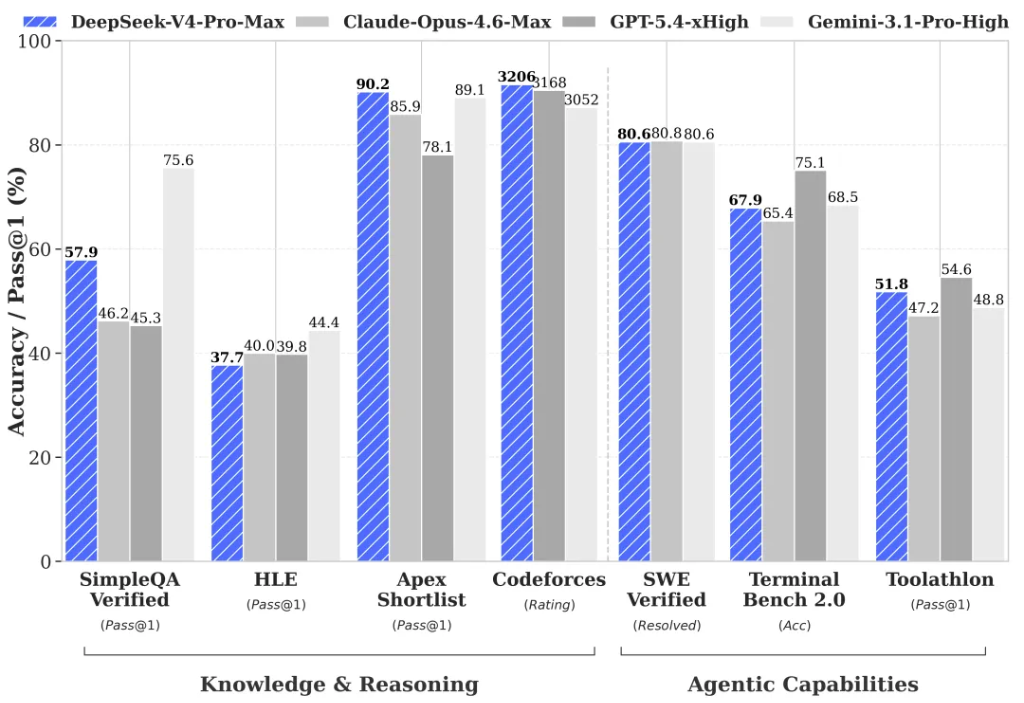
世界知識評測方面,V4-Pro大幅領先其他開源模型,僅稍遜於Google的Gemini-Pro-3.1。
Agent 能力大幅提高。相比前代模型,DeepSeek-V4-Pro 的Agent能力顯著增強。在Agentic Coding評測中,V4-Pro已達到當前開源模型最佳水平,並在其他Agent相關評測中同樣表現優異。
目前DeepSeek-V4已成為公司內部員工使用的Agentic Coding模型,據評測反饋使用體驗優於Sonnet 4.5,交付質量接近Opus 4.6非思考模式,但仍與Opus 4.6思考模式存在一定差距。
DeepSeek-V4 發布同時,也公布了其詳細的技術報告。

DeepSeek-V4-Flash:更快捷高效的經濟之選
V4-Flash定位為更快捷、經濟的輕量化選項。
相比 DeepSeek-V4-Pro,DeepSeek-V4-Flash 在世界知識儲備方面稍遜一籌,但展現出了接近的推理能力。
由於模型參數與激活規模更小,其API服務在速度與成本上具備明顯優勢。
在Agent評測中,V4-Flash在簡單任務上與V4-Pro表現相當,但高難度任務上仍有差距。
這一定位使V4-Flash更適合對延遲和成本敏感、任務複雜度適中的企業級應用場景。
結構創新和超高上下文效率
DeepSeek-V4在底層架構上引入了一種全新注意力機制。
在token維度進行壓縮,並結合自研DSA稀疏注意力技術(DeepSeek Sparse Attention),官方稱其實現了全球領先的長上下文能力,同時相比傳統方法大幅降低了對計算資源和顯存的需求。
這一架構創新的直接產物是:1M上下文窗口將成為DeepSeek所有官方服務的標配。
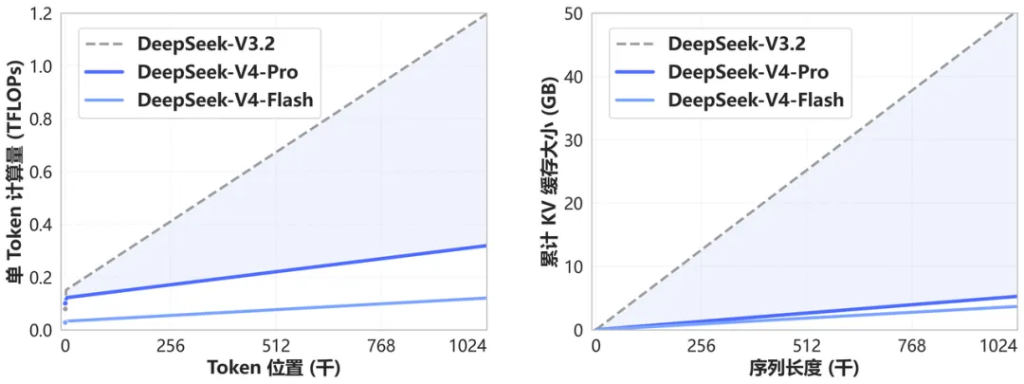
對於需要處理長文檔、長對話或複雜多步驟任務的企業用戶而言,這一能力的普及具有實質性意義。
在降低算力消耗的同時擴展上下文窗口,亦有助於進一步壓低推理成本,強化DeepSeek在性價比維度的競爭優勢。
Agent生態適配同步推進
DeepSeek表示,V4系列針對Claude Code、OpenClaw、OpenCode、CodeBuddy等主流Agent產品進行了專項適配與優化,在代碼任務及文檔生成任務上均有性能提升。
API層面,兩款模型最大上下文長度均為1M,同時支持非思考模式與思考模式。
思考模式支持通過reasoning_effort參數設定推理強度,可選high或max檔位。DeepSeek建議,針對複雜Agent場景應啓用思考模式並將強度設為max。