DeepSeek和清華的研究者提出了一種新方法——自我原則點評調優(SPCT),用於推動通用獎勵建模在推理階段實現有效的可擴展性,最終構建出DeepSeek-GRM系列模型。同時引入了元獎勵模型(meta RM),進一步提升推理擴展性能。
DeepSeek R2,果然近了。
最近,DeepSeek和清華的研究者發表的這篇論文,探討了獎勵模型的推理時Scaling方法。

現在,強化學習(RL)已廣泛應用於LLM的大規模後訓練階段。
通過RL激勵LLMs的推理能力表明,採用合適的學習方法,就有望實現有效的推理時可擴展性。
然而,RL面臨的一個關鍵挑戰,就是在可驗證問題或人工規則之外的多種領域中,為LLMs獲得準確的獎勵信號。
是否有可能通過增加推理計算資源,來提升通用查詢場景下獎勵建模(RM)的能力,即通用RM在推理階段的可擴展性呢?
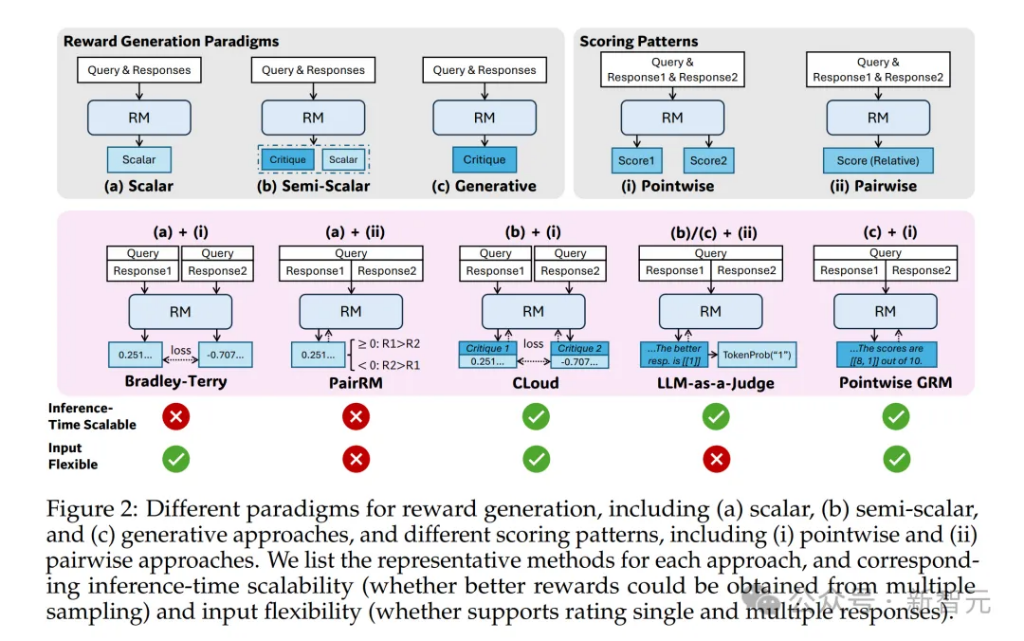
DeepSeek和清華的研究者發現,在RM方法上採用點式生成式獎勵建模(Pointwise Generative Reward Modeling, GRM),就能提升模型對不同輸入類型的靈活適應能力,並具備推理階段可擴展的潛力。
為此,他們提出一種自我原則點評調優(Self-Principled Critique Tuning, SPCT)的學習方法。
通過在線RL訓練促進GRM生成具備可擴展獎勵能力的行為,即能夠自適應生成評判原則並準確生成點評內容,從而得到DeepSeek-GRM模型。
他們提出了DeepSeek-GRM-27B,它是基於Gemma-2-27B經過SPCT後訓練的。
可以發現,SPCT顯著提高了GRM的質量和可擴展性,在多個綜合RM基準測試中優於現有方法和模型。
研究者還比較了DeepSeek-GRM-27B與671B的更大模型的推理時間擴展性能,發現它在模型大小上的訓練時間擴展性能更好。
另外,他們還引入一個元獎勵模型(meta RM)來引導投票過程,以提升擴展性能。
總體來說,研究者的三個貢獻如下。
1.提出了一種新方法——自我原則點評調優(SPCT),用於推動通用獎勵建模在推理階段實現有效的可擴展性,最終構建出DeepSeek-GRM系列模型。同時引入了元獎勵模型(meta RM),進一步提升推理擴展性能。
2.SPCT顯著提升了GRM在獎勵質量和推理擴展性能方面的表現,超過了現有方法及多個強勁的公開模型。
3.將SPCT的訓練流程應用於更大規模的LLM,並發現相比於訓練階段擴大模型參數量,推理階段的擴展策略在性能上更具優勢。
SPCT
受到初步實驗結果的啓發,研究者為點式生成式獎勵模型(pointwise GRM)開發了一種新穎的方法,使其能夠學習生成具有適應性和高質量的原則,以有效指導點評內容的生成。
這一方法被稱為自我原則點評調優(Self-Principled Critique Tuning,SPCT)。
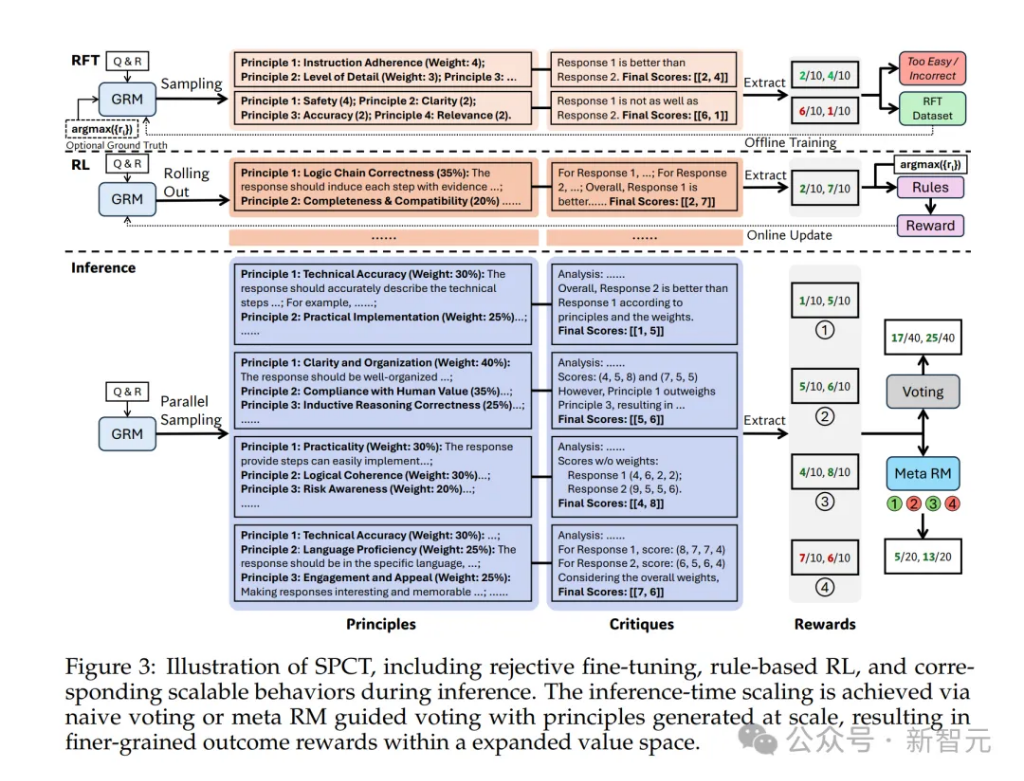
如圖3所示,SPCT包括兩個階段。
1.拒絕式微調(rejective fine-tuning)作為冷啓動階段
2.基於規則的在線強化學習(rule-based online RL),通過提升生成的原則和點評內容來強化通用獎勵的生成過程。
另外,SPCT還可以促進GRM在推理階段的可擴展行為。
將「原則」從理解轉向生成
研究者發現,適當的原則可以在一定標準下引導獎勵生成,這對於生成高質量獎勵至關重要。
然而,在大規模通用獎勵建模中,如何有效生成這些原則仍是一個挑戰。
為此,他們提出將「原則」從一種理解過程解耦出來,轉變為獎勵生成的一部分,也就是說,不再將原則視為預處理步驟,而是納入獎勵生成流程中。
形式化地說,當原則是預定義時,原則可用於引導獎勵生成。
研究者讓GRM自行生成原則,並基於這些原則生成點評內容,形式化表達如下:
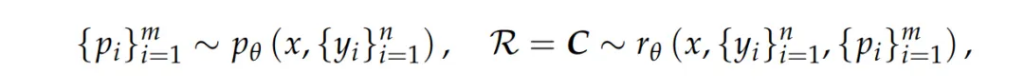
其中,p_θ是用於生成原則的函數,由參數θ表示,且與獎勵生成函數r_θ共享同一個模型架構。
這一轉變使原則能夠根據輸入問題及其回答內容進行動態生成,從而使獎勵生成過程更加自適應。
此外,通過對GRM進行後訓練,可進一步提升所生成原則與對應點評內容的質量與細緻程度。
當GRM能夠在大規模條件下生成多樣化、高質量的原則時,其輸出的獎勵將更加合理且具備更高的細粒度,而這一能力正是推理階段可擴展性的關鍵所在。
基於規則的強化學習
為了同時優化GRM中的原則與點評內容的生成,研究者提出了SPCT方法,它結合了拒絕式微調(rejective fine-tuning)與基於規則的強化學習(rule-based RL)。
其中,拒絕式微調作為冷啓動階段。
拒絕式微調(Rejective Fine-Tuning,冷啓動)
這一階段的核心思想是讓GRM適應不同輸入類型,並以正確的格式生成原則與點評內容。
與以往工作混合使用單個、成對和多個回答的RM數據並使用不同格式不同,研究者採用了點式GRM(pointwise GRM),以在相同格式下靈活地對任意數量的回答進行獎勵生成。
在數據構建方面,除了通用指令數據外,研究者還從具有不同回答數量的RM數據中採樣預訓練GRM在給定查詢與回答下的軌跡。
對於每個查詢及其對應的回答,研究者執行了N_RFT次採樣。
他們統一了拒絕策略:若模型預測的獎勵與真實獎勵不一致(錯誤),或該組查詢與回答在所有N_RFT次採樣中全部預測正確(太簡單),則拒絕該軌跡。
形式化地,令r_i表示第i個回答y_i對查詢x的真實獎勵,預測得到的點式獎勵
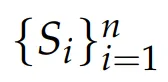
被認為是正確的,當且僅當:
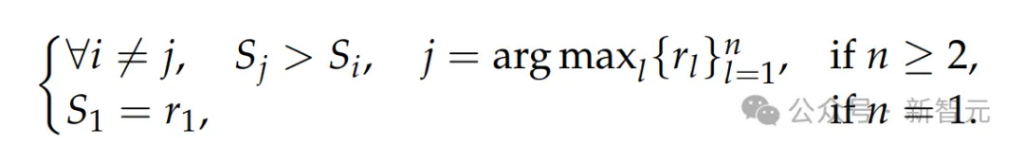
該條件保證真實獎勵中只有一個最大值。
然而,正如以往研究所指出的,預訓練的GRM在有限採樣次數下,往往難以為部分查詢及其回答生成正確的獎勵。
因此,研究者引入了提示式採樣(hinted sampling):將
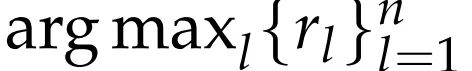
作為提示,附加到GRM的提示語中,以期提高預測獎勵與真實獎勵的一致性。
可以發現,與之前的研究不同,提示採樣的軌跡在某些情況下會捷徑式簡化點評生成,特別是在推理任務中。
這表明:在線強化學習對於GRM仍是必要的,並具有潛在優勢。
基於規則的強化學習
在SPCT的第二階段,研究者使用基於規則的在線強化學習對GRM進一步微調。
具體而言,我們採用了GRPO的原始設定,並使用基於規則的結果獎勵(rule-based outcome rewards)。
在rollout過程中,GRM根據輸入查詢與回答生成原則與點評,然後提取預測獎勵並通過準確性規則與真實獎勵進行對比。
與DeepSeek-AI不同的是,研究者不再使用格式獎勵,而是採用更高的KL懲罰係數,以確保輸出格式正確並避免產生嚴重偏差。
形式化地,對於第i個輸出o_i(給定查詢x和回答
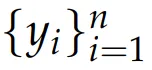
),其獎勵定義為
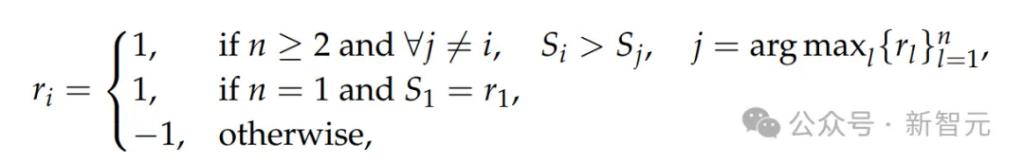
其中,點式獎勵
是從o_i中提取的。
該獎勵函數鼓勵GRM通過在線優化生成的原則與點評內容,正確地區分最優回答,從而提升推理階段的可擴展性。
此外,這種獎勵信號可無縫對接任何偏好數據集與標註的LLM回答。
SPCT的推理時Scaling
為了進一步提升DeepSeek-GRM在生成通用獎勵上的性能,研究團隊探索瞭如何利用更多的推理計算,通過基於採樣的策略來實現有效的推理時擴展。
通過生成獎勵進行投票
逐點GRM(pointwise GRMs)投票過程被定義為將獎勵求和:
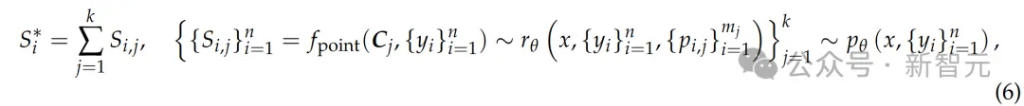
因為S_(i,j)通常被設定在一個小的離散範圍內(比如{1,...,10}),所以投票過程實際上將獎勵空間擴大了k倍,讓GRM能生成大量原則(principles),從而提升最終獎勵的質量和細膩度。
直觀來說,如果把每個原則看作一種判斷視角的代表,那麼更多的原則就能更準確地反映真實分佈,從而帶來擴展的有效性。
值得一提的是,為了避免位置偏差並增加多樣性,研究人員在採樣前會對回答進行隨機打亂。
元獎勵模型引導投票
DeepSeek-GRM的投票過程需要多次採樣,但由於隨機性或模型本身的侷限性,生成的某些原則和評論可能會出現偏見或者質量不高。
因此,研究團隊訓練了一個元獎勵模型(meta RM)來引導投票過程。
這個meta RM是一個逐點標量模型,訓練目標是判斷DeepSeek-GRM生成的原則和評論是否正確。
引導投票的實現很簡單:meta RM為k個採樣獎勵輸出元獎勵(meta rewards),然後從這些獎勵中選出前k_meta(k_meta ≤ k)個高質量的獎勵進行最終投票,從而過濾掉低質量樣本。
獎勵模型結果
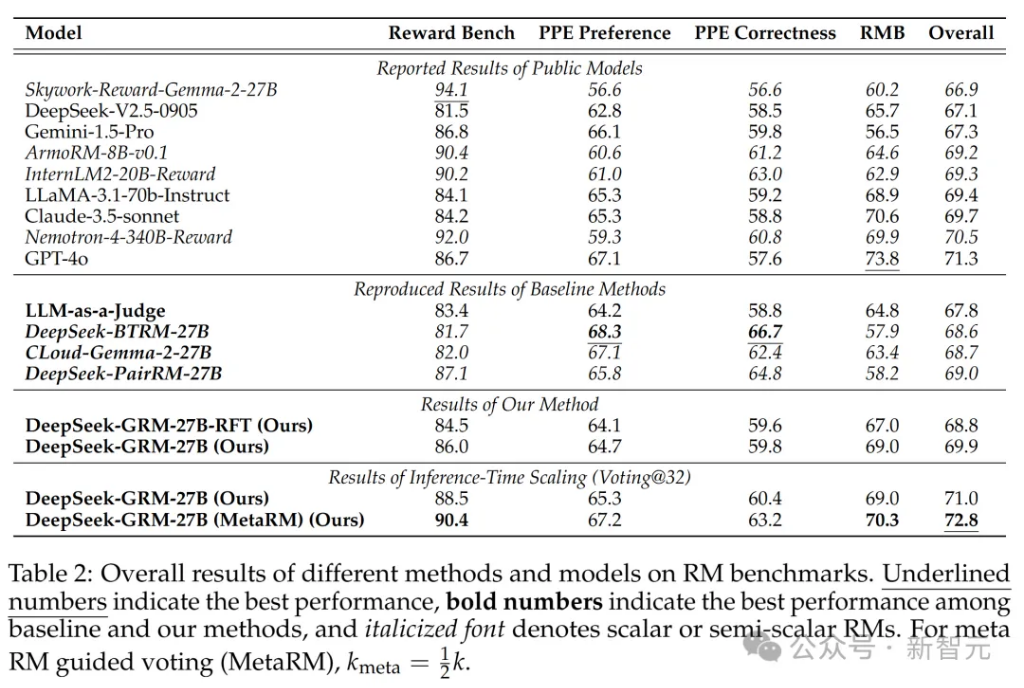
不同方法和模型在RM基準測試上的總體結果如表2所示。
結果顯示,DeepSeek-GRM-27B在整體性能上超過了基線方法,並且與一些強大的公開RM(如Nemotron-4-340B-Reward和GPT-4o)表現相當。
如果通過推理時擴展(inference-time scaling),DeepSeek-GRM-27B還能進一步提升,達到最佳整體結果。
推理時擴展性
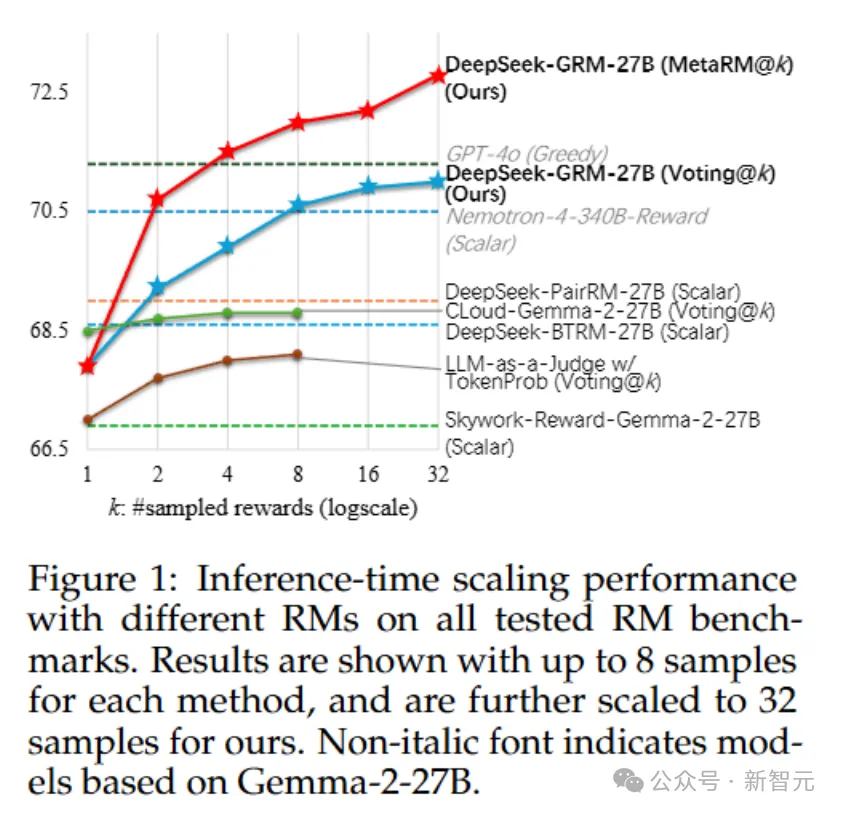
不同方法的推理時擴展結果如表3所示,整體趨勢見圖1。
研究人員發現,在最多8個樣本的情況下,DeepSeek-GRM-27B的性能提升最高,超越了貪婪解碼和採樣結果。
隨着推理計算量增加(最多32個樣本),DeepSeek-GRM-27B展現出進一步提升性能的潛力。meta RM也在每個基準測試中證明了其過濾低質量軌跡的有效性。
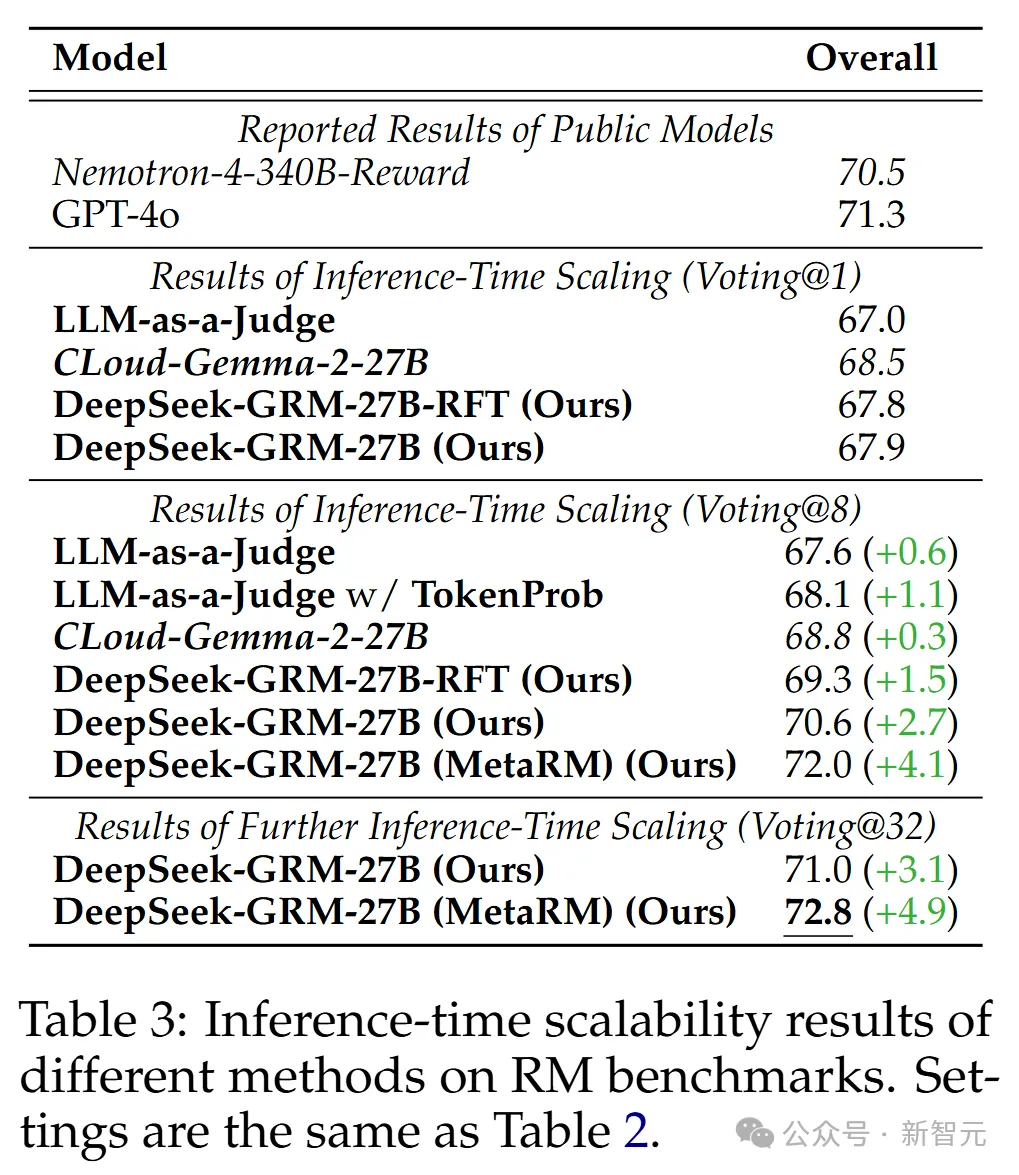
總之,SPCT提升了GRM的推理時擴展性,而meta RM進一步增強了整體擴展性能。
消融研究
表4展示了所提SPCT不同組件的消融研究結果。
令人驚訝的是,即使沒有使用拒絕採樣的評論數據進行冷啓動,經過在線強化學習(online RL)後,通用指令調整的GRM仍然顯著提升(66.1 → 68.7)。
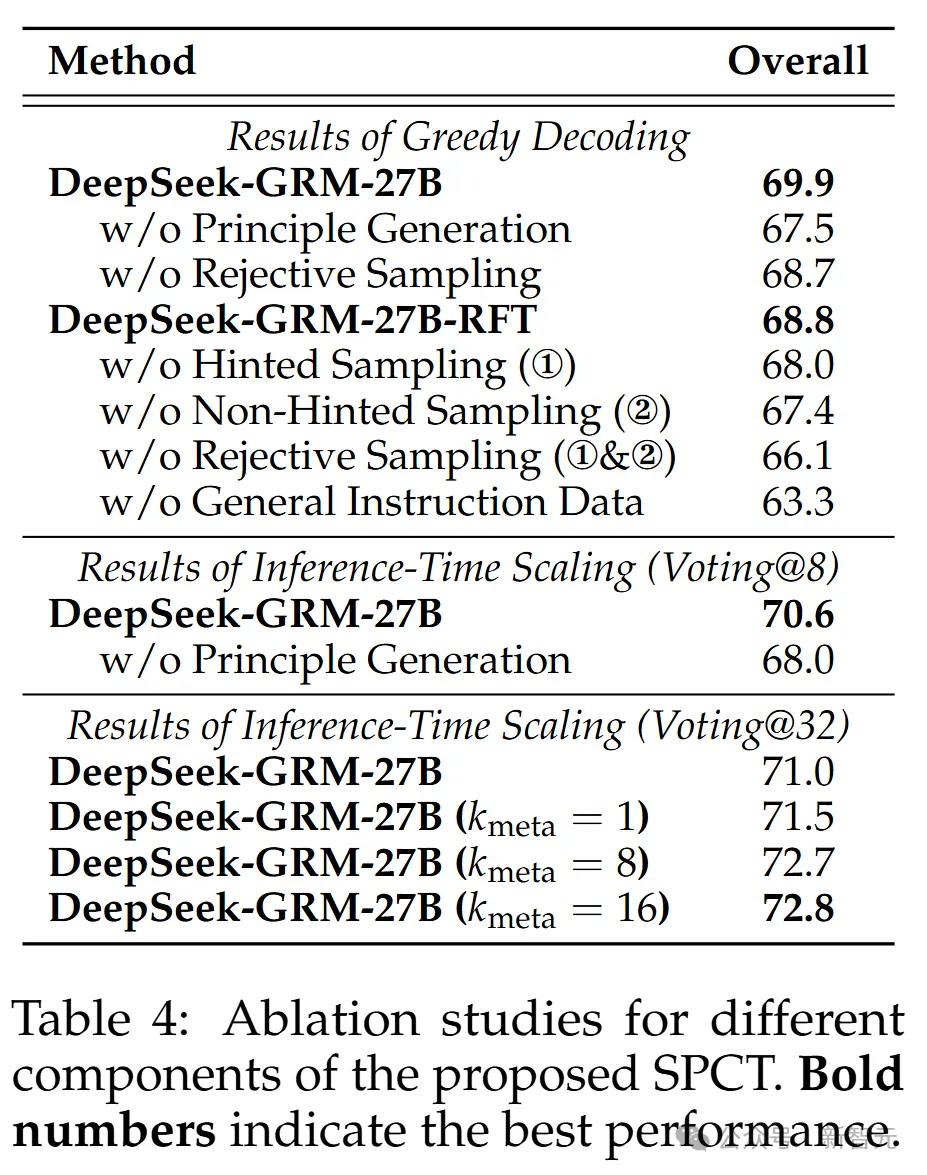
此外,非提示採樣似乎比提示採樣更重要,可能是因為提示採樣軌跡中出現了捷徑。這表明在線訓練對GRM的重要性。
與之前研究一致,研究團隊確認通用指令數據對GRM性能至關重要。他們發現,原則生成對DeepSeek-GRM-27B的貪婪解碼和推理時擴展性能都至關重要。
在推理時擴展中,meta RM指導的投票在不同k_meta下表現出魯棒性。
推理與訓練成本擴展
研究團隊進一步研究了DeepSeek-GRM-27B在不同規模LLM後訓練下的推理時和訓練時擴展性能。
模型在Reward Bench上測試,結果如圖4所示。
他們發現,使用32個樣本直接投票的DeepSeek-GRM-27B可以達到與671B MoE模型相當的性能,而meta RM指導的投票僅用8個樣本就能取得最佳結果,證明了DeepSeek-GRM-27B在推理時擴展上的有效性,優於單純擴大模型規模。
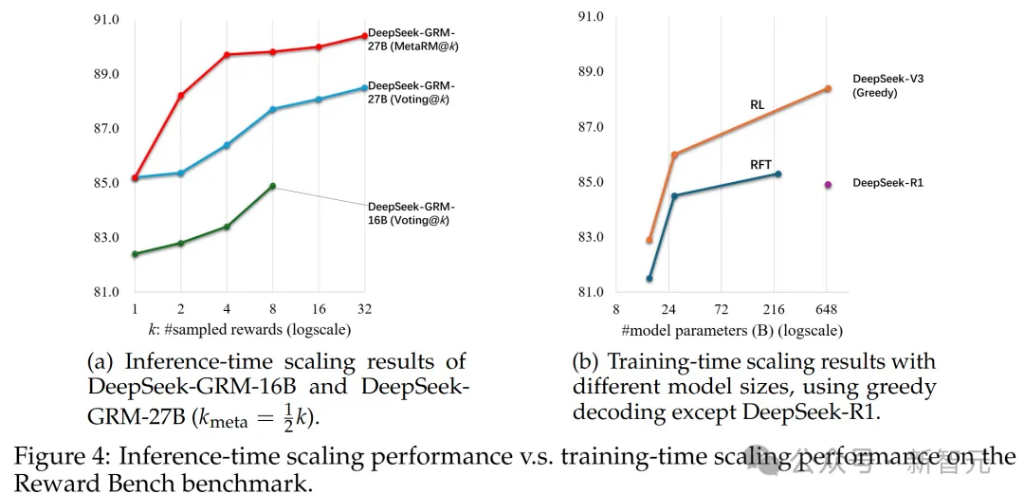
此外,他們用包含300個樣本的降採樣測試集測試了DeepSeek-R1,發現其性能甚至不如236B MoE RFT模型,這表明延長推理任務的思維鏈並不能顯著提升通用RM的性能。