今天凌晨,微軟研究院開源了創新音頻模型VibeVoice-1.5B。
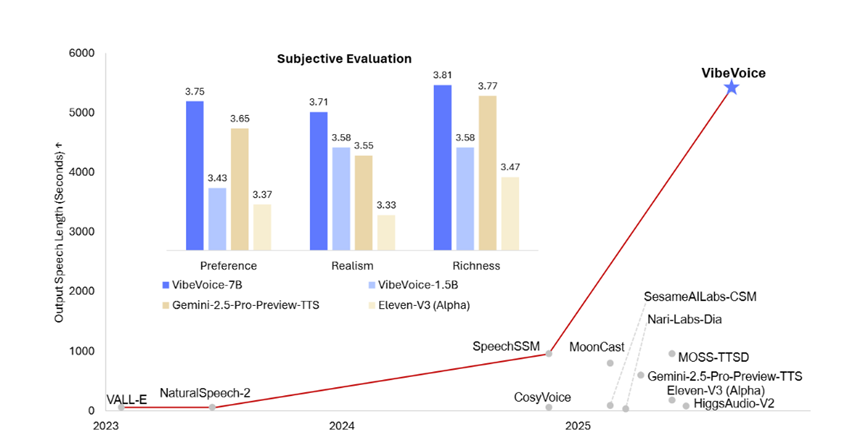
VibeVoice-1.5B開創了語音界多個重大技術突破:一次性可連續合成90分鐘超長逼真語音,之前多數模型只能合成60分鐘以內語音,並且30分鐘後會出現音色漂移、語義斷裂等難題;
最多支持4名發言人,而之前開源的SesameAILabs-CSM、HiggsAudio-V2等知名模型最多支持2人;可對24kHz原始音頻實現3200倍累計壓縮,並且壓縮效率是主流Encodec模型的80倍,同時仍能保持高保真語音效果;
以往TTS模型多依賴單一tokenizer提取特徵,非常容易出現音色與語義不匹配,微軟通過首創雙tokenizer協同架構成功解決這一難題。
VibeVoice案例
下面就為大家展示一下VibeVoice神奇的語音效果。
93分鐘超長合成語音,一共四位演講者,兩男兩女。
這個是老外教英語的音頻播客,有背景音樂、有英語到漢語的轉換,整個流程非常絲滑。如果不告訴你,能聽出來這是語音合成的嘛?
這個是「AIGC開放社區」根據demo測試的效果,主要是根據西遊記二創了一段。使用了單一女性演講。
這個是帶背景音樂的科技資訊介紹GPT-5正式發布,一共有3位演講者,兩男一女。
關於體育資訊,主要討論誰是籃球界的扛把子。一共兩位演講者,一男一女。
一段擬人化的語音效果,主要體現這個模型強大的擬人化情緒效果,一男一女兩個人。
VibeVoice架構簡單介紹
VibeVoice首創了雙語音tokenizer模塊,聲學tokenizer與語義tokenizer,兩者各有分工又相互配合,為後續的建模提供高效壓縮且語義與聲學對齊」的混合特徵。
聲學tokenizer承擔保留聲音特徵並實現極致壓縮的核心任務,其架構採用基於變分自編碼器的對稱編碼-解碼結構,這種設計既解決了傳統變分自編碼器在自迴歸建模中容易出現的方差坍縮問題,簡單說就是數據多樣性丟失,又通過層級化的下采樣實現超高壓縮率。
聲學編碼器部分包含7個階段的改進版Transformer模塊,和傳統Transformer依賴的自注意力模塊不同,該模塊採用1D深度可分離因果卷積,這種設計不僅支持流式處理,也就是一邊接收音頻一邊進行特徵提取,避免長音頻全部加載進來導致內存不夠用,還能有效捕捉音頻的時間順序關聯性;
通過6個下采樣層逐步降低數據維度,最終將24kHz採樣率的原始音頻轉化為每秒僅7.5個潛在向量的形式,實現3200倍的累計壓縮率,並且每個編碼器與解碼器組件的參數規模控制在3.4億左右,兼顧了處理效率與性能。
在訓練方面,聲學tokenizer參考DAC框架的訓練目標,引入生成器與判別器雙損失機制,生成器負責確保音頻重建質量,判別器則通過區分合成音頻與真實音頻來優化細節保真度,同時其變分自編碼器設計採用固定方差分佈策略將方差定義為預先設定的正態分佈,一種常見的數據分佈形態,而不是傳統變分自編碼器中的可學習參數,通過特定計算方式確保潛在向量始終保持足夠的多樣性,為長音頻生成的多樣性與穩定性打下基礎。
和聲學tokenizer聚焦聲音特徵不同,語義tokenizer的核心目標是提取與文本語義對齊的特徵,解決傳統單一tokenizer容易出現的音色與語義脫節問題,比如悲傷的文本用歡快的語調合成。它的架構與聲學tokenizer的編碼器部分完全對應,同樣包含7個階段的改進版Transformer模塊與1D深度可分離因果卷積,但關鍵區別在於去掉了變分自編碼器組件,因為語義特徵需要具備確定性,以確保文本與語音的語義一致。
在訓練方式上,語義tokenizer沒有采用音頻重建目標,而是以自動語音識別為代理任務:訓練過程中,編碼器輸出的語義特徵會輸入到一個臨時的Transformer解碼器中,這個解碼器的任務是根據語義特徵預測對應的文本內容,通過這種方式強制語義特徵與文本語義深度綁定;等訓練完成後,用於預測文本的Transformer解碼器會被捨棄,只保留編碼器作為語義特徵提取器,這樣做既實現了語義與文本的對齊,又通過移除多餘模塊將語義tokenizer的推理速度提升40%,避免給長音頻處理增加額外的計算負擔。
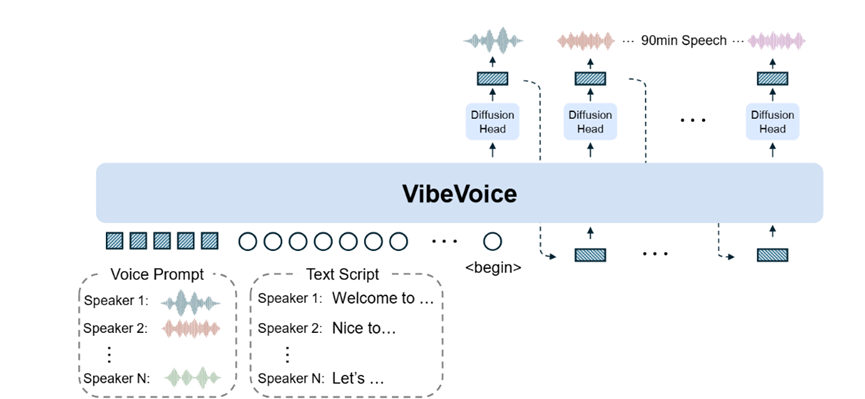
作為架構的上下文理解與決策核心,VibeVoice選用預訓練的Qwen2.5大語言模型作為序列建模主體,核心作用是解析複雜的用戶輸入包括多個說話人的語音提示、文本腳本以及角色分配,並生成能夠引導後續擴散生成的上下文隱藏狀態。
為了適配多說話人長音頻場景,VibeVoice對大語言模型的輸入形式進行了針對性設計:輸入序列採用「角色標識-語音特徵-文本腳本」交錯拼接的格式,具體表現為[說話人1:語音特徵1,說話人2:語音特徵2,……,說話人N:語音特徵N]與[說話人1:文本腳本1,說話人2:文本腳本2,……,說話人N:文本腳本N]的組合,其中語音特徵是語音提示經聲學tokenizer編碼後的潛在向量,文本腳本是對應角色的文本內容經過分詞處理後轉化為嵌入向量,而說話人k作為角色標識標籤,能讓大語言模型精準關聯「某段文本應該由哪個說話人的音色生成」,從而實現多說話人的自然輪替。
在模型訓練與優化方面,VibeVoice採用課程學習策略將大語言模型的輸入序列長度從初始的4096個token逐步增加到65536個token,對應24千赫茲採樣率下90分鐘的音頻長度,避免模型因為一開始就處理超長序列而出現訓練失敗。
為了提升訓練效率,預訓練完成的聲學tokenizer與語義tokenizer參數在整個訓練過程中保持不變,只更新大語言模型與後續擴散頭的參數,這樣做使訓練周期縮短50%,還能確保特徵提取模塊的穩定性。
值得一提的是,VibeVoice-1.5B只是試水,未來微軟還會開源一個更大參數的語音模型。