昨夜晚間,思科推出了一款新型路由 ASIC,旨在通過將現有數據中心整合到單個統一的計算集羣中來幫助比特倉運營商克服功率和容量限制。
新發布的8223是一款 51.2 Tbps 路由器,搭載其自主研發的 Silicon One P200 ASIC。思科表示,結合 800 Gbps 相干光器件,該平台可支持高達 1,000 公里的傳輸距離。在連接足夠多的路由器後,該架構理論上可實現每秒 3 EB 的總帶寬,這足以連接當今最大的 AI 訓練集羣。
事實上,這樣的網絡將能夠支持包含數百萬個 GPU 的多站點部署,但正如您所料,實現這種級別的帶寬並不便宜,需要數千個路由器才能使其全部工作。對於不需要那麼快連接的客戶,思科表示,路由器可以使用較小的雙層網絡支持高達 13 Pbps 的帶寬。
高速、跨規模數據中心網絡的想法已經引起了包括微軟和阿里巴巴在內的幾家大型雲提供商的關注,思科告訴我們,他們正在評估芯片的潛在部署。
阿里雲網絡基礎設施負責人在一份聲明中表示:「這款新的路由芯片將使我們能夠擴展到核心網絡,用一組搭載 P200 的設備取代傳統的基於機箱的路由器。這一轉變將顯著增強我們 DCI 網絡的穩定性、可靠性和可擴展性。」
思科只是最新一家加入分佈式數據中心潮流的網絡供應商。今年早些時候,Nvidia 和 Broadcom 宣佈推出各自的可擴展網絡 ASIC。
與 P200 類似,博通的 Jericho4 是一款 51.2 Tbps 交換機,主要設計用於高速數據中心到數據中心架構。博通表示,該芯片可以以超過 100 Pbps 的速度連接相距最遠 100 公里的數據中心。
Nvidia 也加入了這場盛宴,在今年夏初的 Hot Chips 大會上展示了其 Spectrum-XGS 交換機。雖然關於實際硬件的細節尚不清楚,但 GPU 芯片供應商 CoreWeave 也承諾利用這項技術將其數據中心連接成一台「統一的超級計算機」。
雖然這些交換機和路由 ASIC 可以幫助數據中心運營商克服功率和容量限制,但延遲仍然是一個持續的挑戰。
我們通常認為光速是瞬時的,但實際上並非如此。在相距 1000 公里的兩個數據中心之間發送數據包,單程大約需要 5 毫秒才能到達目的地,這還沒有考慮到將信號完整傳輸到目的地所需的收發器、放大器和中繼器所產生的額外延遲。
話雖如此,谷歌 DeepMind 團隊今年早些時候發表的研究表明,通過在訓練期間壓縮模型並戰略性地安排兩個數據中心之間的通信,可以克服許多此類挑戰。
硬剛博通英偉達,爭奪AI數據中心互聯市場
廣域網和數據中心互連(DCI),正如我們在過去十年左右所熟知的那樣,在性能和速度上都遠遠不足以承擔跨多個數據中心擴展AI訓練工作負載的任務。因此,Nvidia、Broadcom以及現在的思科系統公司創建了一種名為「跨網絡擴展」(scale across network)的新型網絡。
出於多種原因,這種跨平台網絡對於 AI 工作負載的可擴展性至關重要,其重要性不亞於機架級系統內部的縱向擴展網絡,後者將 GPU 和 XPU(有時也包括 CPU)的內存連接到內存區域網絡。縱向擴展網絡構建更大的計算/內存節點,橫向擴展網絡使用以太網或 InfiniBand(以太網的使用日益增多)將數千個機架級節點連接在一起,而跨平台網絡則允許多個數據中心互連,從而組成一個巨型集羣共享工作。
博通於 8 月中旬率先推出「Jericho 4」 StrataDNX 交換機/路由器芯片,在爭奪網絡市場份額的規模之爭中打響了第一槍。該芯片於當時開始提供樣品,可提供 51.2 Tb/秒的總帶寬,並配有數量和類型未知的 HBM 內存,可作為深度數據包緩衝區,幫助緩解擁塞。
為什麼 DCI 無法實現規模化
在深入探討速度和數據流之前,我們先來定義一些概念。我們還認為,重要的是要注意到 AI 工作負載在網絡上的這種規模化是不可避免的。超大規模計算平台和雲構建者一直在拼湊各種 Web 基礎設施工作負載,但這不足以滿足模型構建者日益增長的 AI 訓練任務的需求。
Rakesh Chopra在思科工作了 27 年,擔任過各種職務,於 2018 年成為思科院士,並帶頭開發了用於交換和路由的 Silicon One 商用 ASIC ,以對抗博通,並且(在當時的程度較小,現在的程度較大)對抗 Nvidia/Mellanox,他是這樣看待數據中心網絡中的劃分的:
我認為,DCI 本質上是將數據中心連接到最終用戶,這通常是通過某種傳統的廣域網來實現的。我們今天討論的,以及業內其他人在過去一個月左右討論的,是跨數據中心的橫向擴展網絡連接的概念。這指的是利用高帶寬的橫向擴展網絡橋接數據中心,使其擁有比數據中心互連更高的帶寬。
為了解決人工智能帶來的功耗和擴展挑戰,橫向擴展網絡需要多長的距離,不同的人持有不同的看法。我們的主張是,你需要在緩衝區和安全性方面做到這一點,因為你正在突破數據中心的限制。與業內其他公司不同,他們採取了我稱之為「非此即彼」的做法——一半人說他們會進行主動擁塞控制,而我會使用傳統交換機將數據中心連接在一起,而其他人則說不需要高級擁塞控制,只需在數據中心之間放置一個深度緩衝路由器即可。
我們的觀點是,兩者實際上都需要,因為高級擁塞控制算法無法解決的一個問題是預先確定網絡路徑的問題。由於人工智能工作負載是確定性的,因此故障情況會導致被動擁塞控制,這種控制必須啓動,並在所需的距離上進行深度緩衝。
「所以,有趣的是,這種跨越規模的概念幾乎是 Silicon One 的涅槃時刻,多年來你我都在談論這個問題,它涉及將這兩個脫節的世界連接在一起——你必須獲得以交換效率進行路由的能力。」

既然如此,那麼問題來了:為什麼不乾脆建一個像曼哈頓那麼大的數據中心——比如紐約的那個,但考慮到美國的延遲問題,它也可能建在堪薩斯州的那個——然後採用超級以太網設備,在一個網絡上部署 1000 萬個 XPU?超大規模計算公司為了數據分析也這麼做,在一個數據中心裏部署 5 萬或 10 萬個 CPU,然後使用容器系統打包應用程序模塊,並將它們以任意規模部署到這個原始計算平台上。對嗎?
是的,但區別在於,推動超大規模業務發展的 Web 基礎設施及其相關數據分析每機架功耗為 15 千瓦,近年來可能已達到每機架 30 千瓦。而英偉達的機架式 GPU 基礎設施每機架功耗約為 140 千瓦,預計在 2020 年前達到每機架 1 兆瓦。因此,在一個地方為 1000 萬個 XPU 供電存在問題,因為將所有電力輸送到那裏——即使是使用燃燒天然氣的發電機——也是一個大問題。
電價也是如此,全球各地的電價差異很大。以下是美國每千瓦時電價:
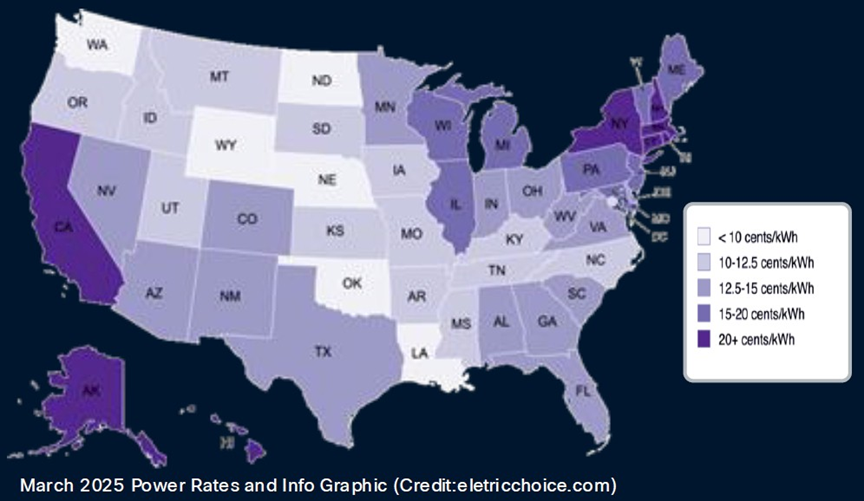
大型數據中心就像非洲大草原上的大型動物:它們追尋水源,也追尋食物。在這種情況下,食物指的是電力,而不是草或肉。因此,超大規模數據中心和雲平台一直在不斷擴張,而考慮到其功率密度和對任何特定數據中心的絕對消耗,人工智能數據中心也必然會這樣做。
但更重要的是,即使沒有這些功率限制,跨網絡擴展也是必要的,因為如此大的房間,你只能通過可擴展的方式互連。相比一次性構建所有數據中心,構建八個數據中心並隨着時間的推移(以及空間)擴展它們的 AI 處理能力更容易——也許也只有在技術和經濟上纔可行。就像計算插槽正在轉向芯片組以提高良率和降低成本一樣,數據中心正在被分解成多個部分並互連。這一切變得多麼複雜啊。正如我們之前指出的那樣,數據中心看起來就像芯片插槽。那麼,跨網絡擴展就像是放大版的 Infinity Fabric。事實證明,它非常大。
Chopra 向我們介紹了 GPU 集羣的規模,以及數據中心內部和跨數據中心的各種網絡,最終突破了數據中心 50,000 個 GPU 的門檻。以下是 OpenAI GPT 模型的演變歷程,展現了模型構建者們正在努力應對的計算能力的指數級增長:
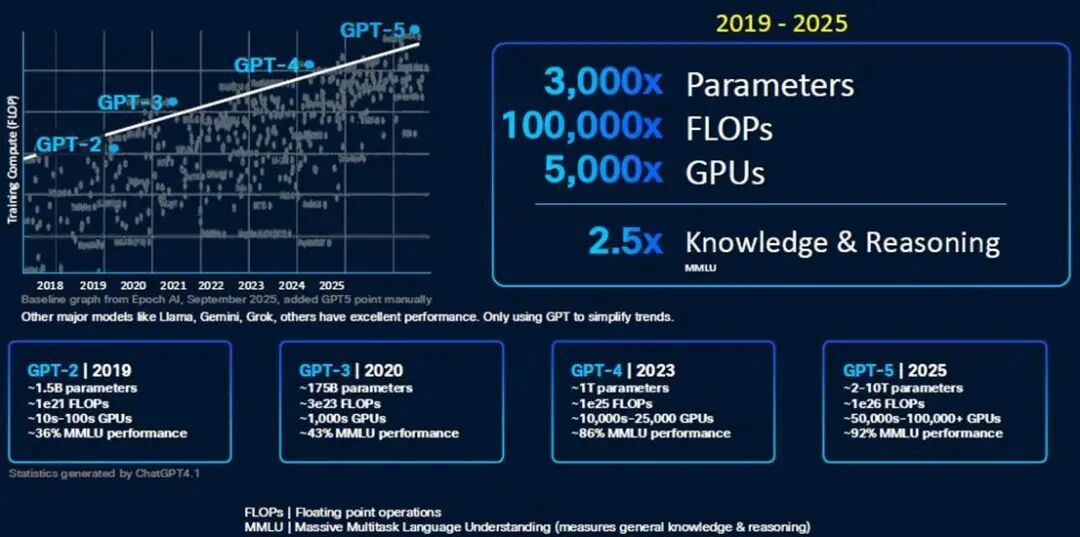
顯然,一個20瓦的大腦能夠在曾經用於評估AI模型的大規模多任務語言理解(MMLU)基準測試中獲得A級評價,這已經相當令人印象深刻了。但暫且不論這一點,我們只需要想想GPT-6,無論它是什麼——或許是20萬個GPU和1×10^ 27百億億次浮點運算的性能——就能明白多數據中心集羣的重要性。
GPT-5 模型開始打破數據中心的壁壘,其他人肯定也在這樣做。
看看前端網絡用於連接計算和存儲的帶寬,與用於網絡規模的舊式 WAN/DCI 相比,大約高出 7 倍。在機架級系統中,用於連接 (0)100 個 GPU 的擴展帶寬是 WAN 的 504 倍。(XPU 之間的共享內存需要巨大的帶寬成本。)即使是用於連接機架級節點的擴展帶寬,也比 WAN/DCI 互連高出 56 倍。
在低端網絡規模方面,需要將大約 20 個數據中心的 100 萬個 XPU 連接在一起,這需要大約 14 倍於 WAN/DCI 網絡的帶寬,約為 914 Tb/秒。如果進行計算,Chopra 表示思科可以使用其新款 Dark Pyramid P200 ASIC 構建的橫向擴展網絡可提供約 12.8 Pb/秒的帶寬。(圖表四捨五入為 13 Tb/秒。)
要聚合近 1 PB/秒的 WAN/DCI 互連,需要數十個模塊化路由器機箱中的數百個平面(或主幹/主幹網絡中類似數量的設備);這需要大約 2,000 個端口暴露給數據中心。Chopra 表示,整個網絡的規模需要數千個平面,這些平面使用模塊化機箱中的 51.2 Tb/秒 ASIC,以 800 Gb/秒的速度運行 16,000 個端口,從而達到 12.8 PB/秒的總帶寬。但是,你不可能構建一個如此大的模塊化交換機,並讓它看起來像一個大型交換機。
這實際上只能通過葉/脊網絡來實現,具體來說,需要 512 個葉節點,每個葉節點有 64 個端口,以 800 Gb/秒的速率運行,並由 256 個脊節點互連,才能達到 13.1 Pb/秒的速率。(這是全雙工路由,因此實際帶寬是該速率的兩倍,並且僅測量一個方向。)
如果您想要構建一個三層聚合/骨幹/葉子網絡,那麼使用 P200 設備,您可以在整個網絡中實現 3,355 PB/秒的聚合帶寬。因此,如果您願意支付額外的兩跳費用,這裏有足夠的帶寬空間。(在 P300、P400 或 P500 路由器芯片推出更高的基數和帶寬之前,數據中心運營商可能別無選擇,只能這樣做。)
黑暗金字塔——是美元上的那個嗎?還是埋在阿拉斯加的那個?——ASIC 在其 64 個端口上擁有 51.2 Tb/秒的總帶寬。P200 擁有 64 個端口,運行速度為 800 Gb/秒,並配備兩層 HBM3 內存堆棧,總計 16 GB 的深度數據包緩衝區。該芯片每秒可處理超過 200 億個數據包,每秒可進行超過 4300 億次路由查找。
P200 ASIC 適用於希望構建跨路由器規模的客戶,但思科也在銷售自己的產品,目前他們正在提供樣品,就像 ASIC 也提供給幾家超大規模廠商一樣。「Mustang」 8223-64EF 交換機是一款 3U 交換機,採用 OSFP800 光模塊,「Titan」 8223-64E 是一款類似的交換機,採用 QSFP-DD800 光模塊。
這些路由器運行思科 IOS-XR 網絡操作系統以及開源 SONiC 網絡操作系統。Chopra 告訴The Next Platform,最終配備深度緩衝區的 Nexus 9000 交換機也將基於 P200,並且思科 NX-OS 網絡操作系統將被移植到這些設備上運行。
這些設備的出現可謂恰逢其時。不妨看看兩年前構建一個帶寬高達 51.2 Tb/秒的模塊化機箱所需的條件,而如今,只需要一塊 Dark Pyramid 芯片和一個機箱:
如果你能等上一兩年,等待下一代網絡,顯然總是值得的。然而,有時你就是等不及。這就是為什麼資金不斷湧入思科、英偉達、博通/Arista 等公司的原因。
為分佈式 AI 帶來規模化發展
思科公司今天宣佈推出8223 路由系統,該系統採用其新款Silicon One P200芯片——這是一種旨在通過大規模釋放人工智能潛力的新型網絡系統。
今年早些時候,隨着人工智能正面臨單個數據中心的極限,英偉達公司提出了「跨規模」架構的概念。「計算單元」最初指的是一台服務器,後來演變成一個機架,再後來是整個數據中心。跨規模架構使多個數據中心能夠充當單個計算單元,而思科設計的 8223 和 P200 芯片正是針對這項任務的特殊要求而設計的。
這款新芯片的全雙工吞吐量高達每秒 51.2 Tbps,為網絡性能樹立了新的標杆。新路由器有兩種型號,均為 3RU,並配備 64 個 800G 端口。
8223-64EF 使用 OSFP 光纖,而 8223-64E 使用 QSFP。雖然兩個模塊的總數據速率相同,但它們的主要區別在於尺寸、熱管理和向後兼容性。這些區別影響了它們在不同網絡環境中的適用性,例如高密度數據中心和電信應用。此外,OSFP 同時支持以太網和 Infiniband 標準,而 QSFP 主要用於以太網網絡。
單一數據中心AI基礎設施已達到極限
儘管這些路由器的容量看似超乎尋常,但人工智能正以前所未有的速度消耗着網絡流量。隨着人工智能模型的規模每年翻一番,訓練它們所需的基礎設施也隨之膨脹。這使得超大規模數據中心的規模已經超出了其縱向和橫向擴展的能力,唯一的出路就是跨規模擴展。這種跨規模遷移正在推動長距離流量的大幅增長。
思科高級副總裁 Rakesh Chopra 在會前簡報會上談到了這一點。他提到,一個跨規模網絡所需的帶寬大約是傳統廣域網互連的 14 倍,並且可能需要多達 16,000 個端口才能為大規模 AI 集羣提供每秒 13 PB 的帶寬。
如果使用老式模塊化機箱來實現這一目標,則需要數千個模塊化機箱,成本高昂、功耗高且管理複雜。而使用橫向擴展技術,只需約 2,000 個端口即可實現這一目標,這遠低於之前預估的 16,000 個端口。
思科的深度緩衝區區分器
思科戰略的一個關鍵部分是深度緩衝區的使用——這一功能通常與傳統路由器相關,而非內部AI集羣青睞的淺緩衝交換機。這可以說是與Nvidia Spectrum-XGS以太網等競爭方案最顯著的架構差異點。有趣的是,深度緩衝區尚未用於AI基礎設施,因為人們認為它們實際上會減慢AI工作負載的速度。
深度緩衝區被認為對 AI 網絡有害,尤其是對於分佈式訓練工作負載,因為它們會導致高延遲和抖動,從而嚴重降低 AI 模型的性能。這一概念源於這樣一種觀點:使用深度緩衝區時,緩衝區需要反覆填充和清空,這會導致 GPU 之間的數據傳輸出現抖動。
雖然深度緩衝區可以防止擁塞(微突發)期間的數據包丟失,從而提高吞吐量,但其代價是出現了一種稱為緩衝區膨脹的現象。AI 工作負載,尤其是涉及多個 GPU 的分佈式訓練,對延遲和同步問題高度敏感。
值得稱讚的是,思科在分析師電話會議上主動解決了這個問題,並解釋瞭如何克服深度緩衝區的已知侷限性。思科的論點是,問題並非源於深度緩衝區的存在,而是擁塞導致其被填滿。Chopra 辯稱:「問題在於你們在負載平衡和避免擁塞控制方面做得不好。」
另一件需要注意的事情是,即使緩衝區正在填充和耗盡,也不會影響作業完成時間,因為AI工作負載本質上是同步的。「AI工作負載會等待網絡中最長路徑的傳輸完成,這會影響實際傳輸時間,而不是最大傳輸時間,」Chopra解釋道。
深度緩衝技術的引入為支持 AI 工作負載的長距離、跨網絡擴展帶來了更高的可靠性。丟失一個數據包就會導致數據大規模回滾到檢查點,而當 AI 訓練運行數月時,這一過程的成本非常高昂。P200 的深度緩衝功能旨在吸收訓練過程中的大量流量激增,確保性能穩定,並避免在重新處理上浪費電量。通過良好的擁塞管理,思科可以充分利用深度緩衝的優勢,避免其歷史遺留的弊端。
安全性和靈活性使 AI 結構面向未來
考慮到跨數據中心傳輸數據的重要性,8223 芯片將安全性深深嵌入其中。該系統採用後量子彈性算法進行密鑰管理,提供線速加密,這對於持續多年的 AI 訓練工作而言,具備面向未來的保障至關重要。此外,芯片中嵌入了信任根,確保從製造到部署的完整性,防止物理篡改。
此外,思科正在大力推行運營靈活性。8223 最初面向開源SONiC部署,目標客戶是超大規模數據中心和大型 AI 數據中心建設者,他們通常更傾向於開放選項。不久之後,該平台將支持 IOS XR,這將使該平台能夠服務於傳統的數據中心互連 (DCI)、核心網和骨幹網 WAN 用例,從而顯著擴展核心 AI 雲客戶以外的潛在市場。
P200 芯片還將應用於模塊化平台和分體式機箱,並將為企業數據中心的思科 Nexus 產品組合(運行 NX-OS)提供支持,確保整個 AI 生態系統採用相同的基礎技術和架構一致性。這種多層面的部署策略使思科能夠在 AI 雲領域超過 100 億美元的網絡設備潛在市場中佔據重要份額。
值得注意的是,思科和英偉達現在都提供跨規模網絡產品,思科利用深度緩衝區,而英偉達則採用淺緩衝區。儘管行業觀察人士可能會將兩者進行比較,但現實是,人工智能網絡的需求如此巨大,兩者皆有可能取得成功。思科的方法非常適合分佈式人工智能互連,因為網絡彈性至關重要。英偉達的方法更適合低延遲場景,在這些場景中,可預測的最小延遲是快速訓練周期的絕對優先事項。
人工智能已經掀起了一股浪潮,為客戶提供了多種選擇。