快科技1月16日消息,今日,阿里雲通義開源全新的數學推理過程獎勵模型Qwen2.5-Math-PRM,72B及7B尺寸模型性能均大幅超越同類開源過程獎勵模型。
據了解,在識別推理錯誤步驟能力上,Qwen2.5-Math-PRM以7B的小尺寸超越了GPT-4o。同時,通義團隊還開源了首個步驟級的評估標準 ProcessBench,此項評估標準填補了大模型推理過程錯誤評估的空白。
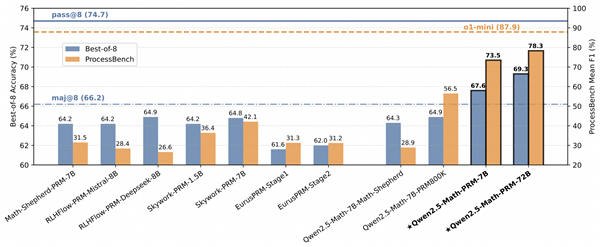
與此同時,為更好衡量模型識別數學推理中錯誤步驟的能力,通義團隊還提出了全新的評估標準ProcessBench。該基準由3400個數學問題測試案例組成,其中還包含奧賽難度的題目,每個案例都有人類專家標註的逐步推理過程,可綜合全面評估模型識別錯誤步驟能力。這一評估標準也已開源。
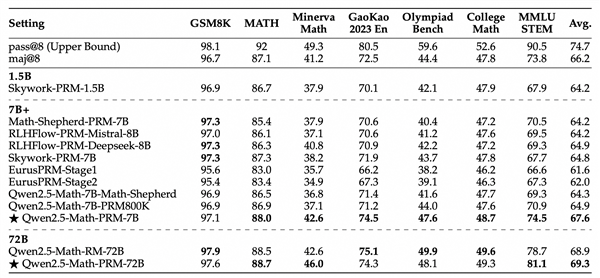
此外,在ProcessBench上對錯誤步驟的識別能力的評估中,72B及7B尺寸的Qwen2.5-Math-PRM均顯示出顯著的優勢,7B版本的PRM模型不但超越同尺寸開源PRM模型,甚至超越了閉源GPT-4o-0806。這證明了過程獎勵模型(PRM)能夠顯著提高推理的可靠性,為未來開發推理過程監督技術開闢了新的途徑。