作者 | 程茜
編輯 | 雲鵬
智東西3月6日報道,今日凌晨,阿里雲發布最新推理模型QwQ-32B,性能媲美DeepSeek-R1,在消費級顯卡上也能實現本地部署。
要知道其參數量為32B,DeepSeek-R1參數量達到了671B,相差將近20倍。
在數學推理、編程能力上,QwQ-32B的表現與DeepSeek-R1相當,強於o1-mini及相同尺寸的R1蒸餾模型。通用能力測評效果上,QwQ-32B的得分均超越DeepSeek-R1。
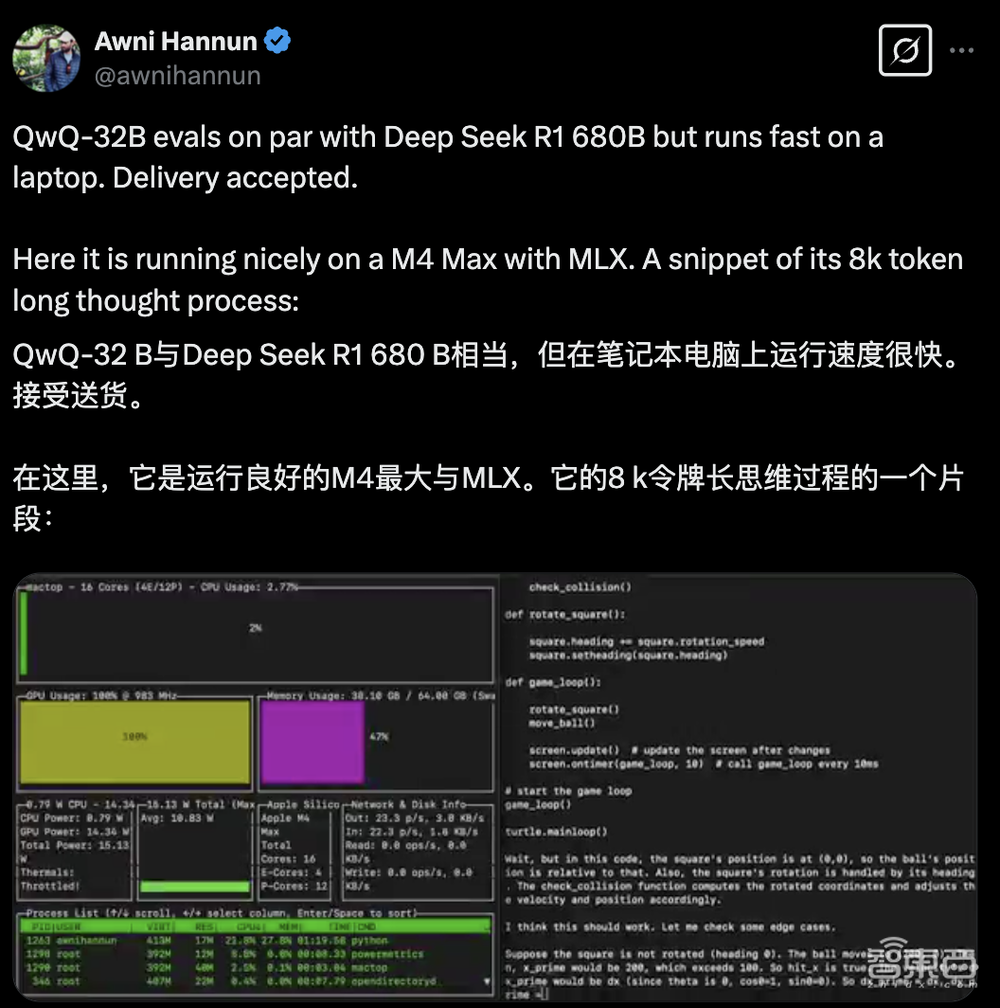
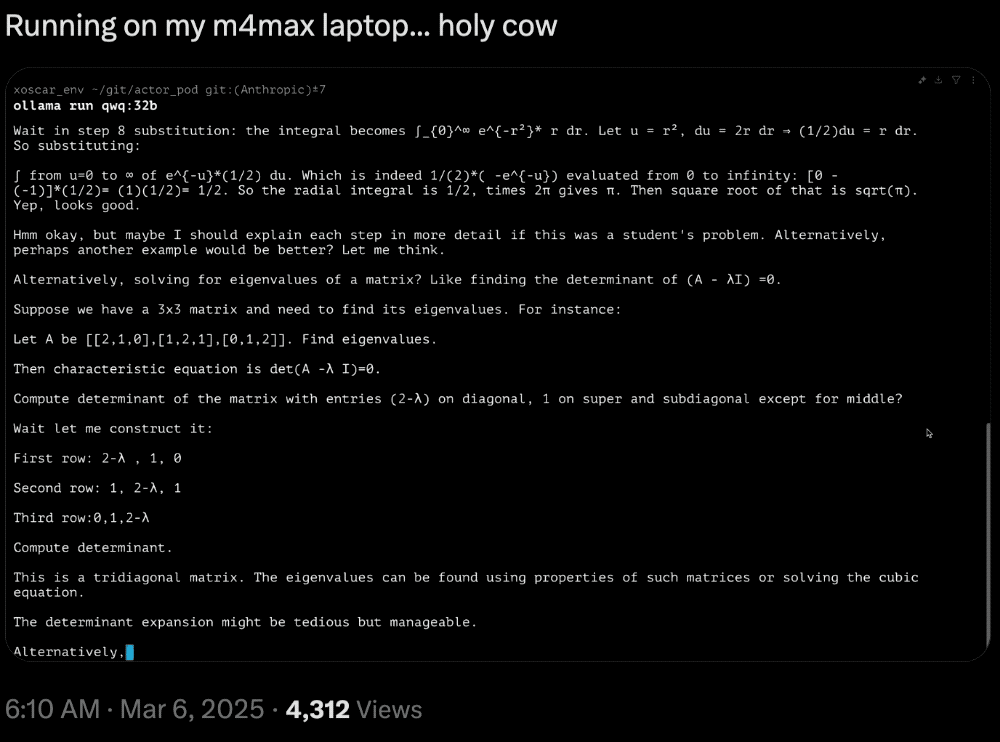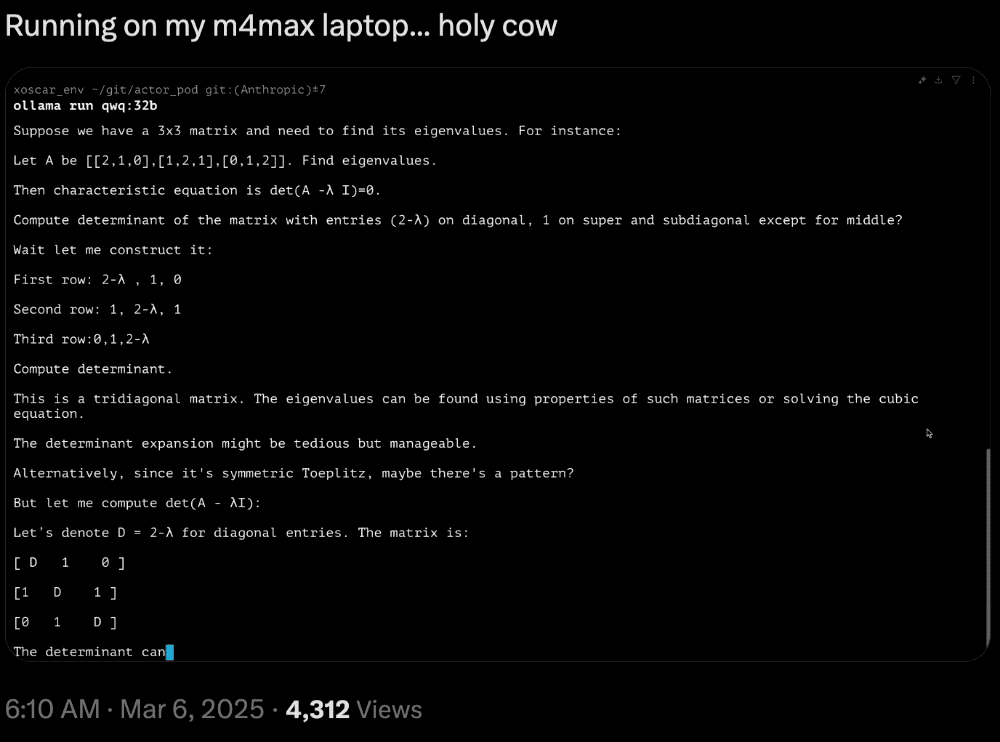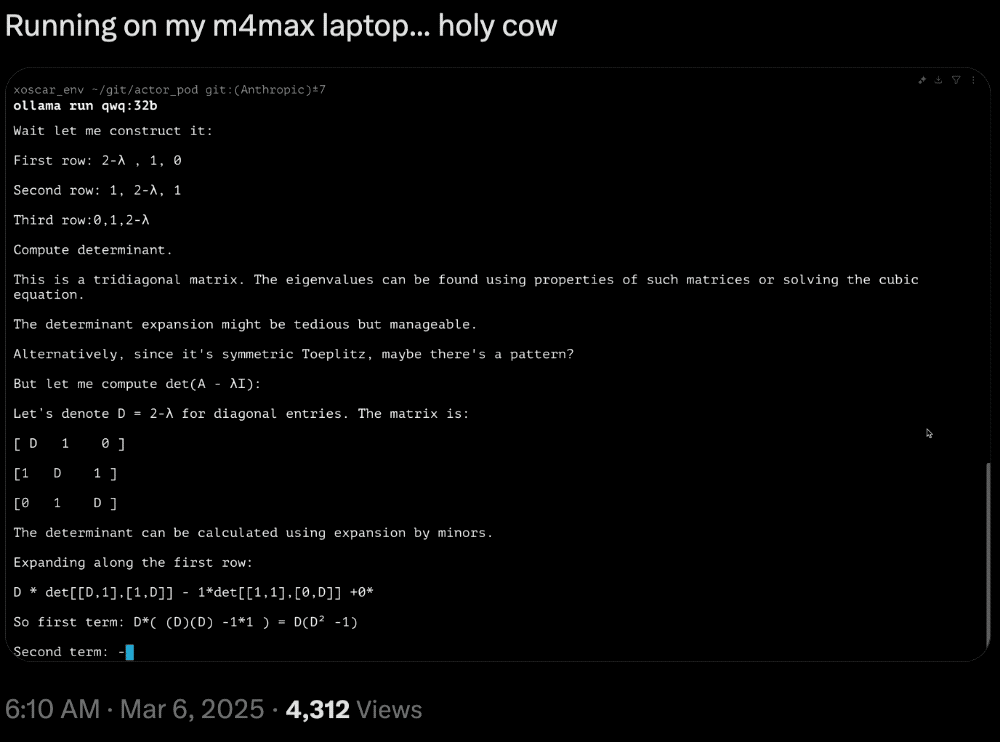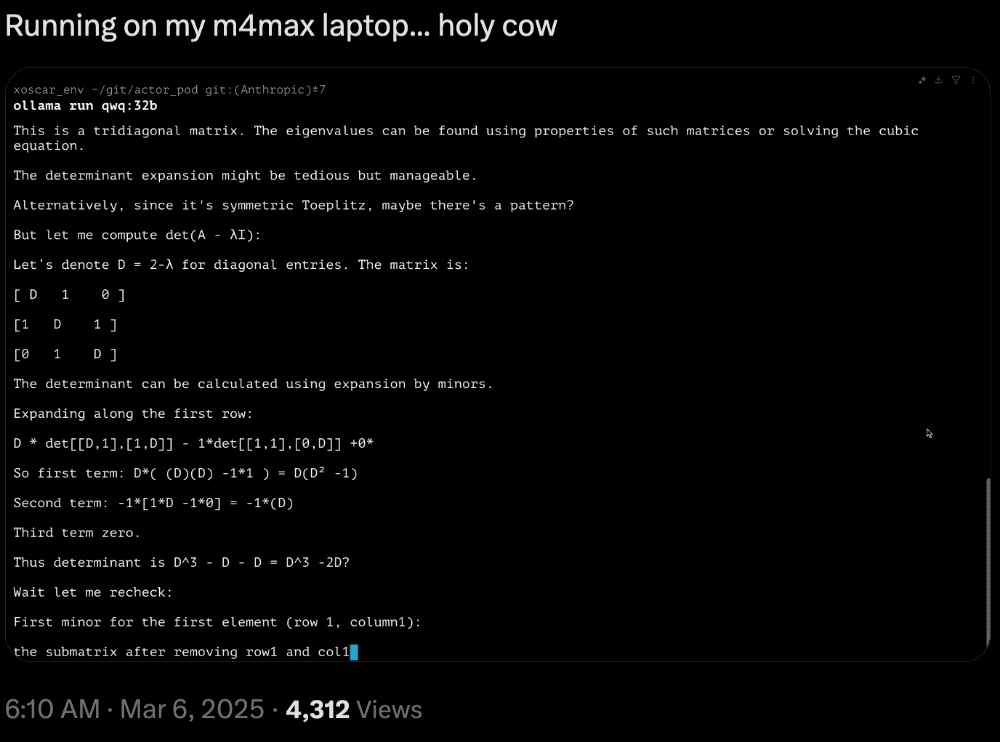
蘋果的機器學習科學家Awni Hannun(吳恩達學生)發文展示了QwQ-32B在配備MLX(專門為蘋果芯片設計的開源框架)的M4 Max芯片電腦上的運行速度很快。
該模型在Hugging Face和ModelScope上以Apache 2.0許可證下的開源。這意味着它可用於商業和研究用途,因此企業可以立即使用它來為他們的產品和應用程序提供動力(即使是他們向客戶收費使用的產品和應用程序)。
Hugging Face地址:huggingface.co/Qwen/QwQ-32B
魔搭社區地址:https://modelscope.cn/models/Qwen/QwQ-32B
體驗地址:https://huggingface.co/spaces/Qwen/QwQ-32B-Demo
一、網友讚不絕口:推理速度「非常快」、「o1-mini級別本地模型」
具體來看QwQ-32B在一系列基準測試中的得分。
QwQ-32B與DeepSeek-R1-Distilled-Qwen-32B、DeepSeek-R1-Distilled-Llama-70B、o1-mini以及DeepSeek-R1進行了對比。
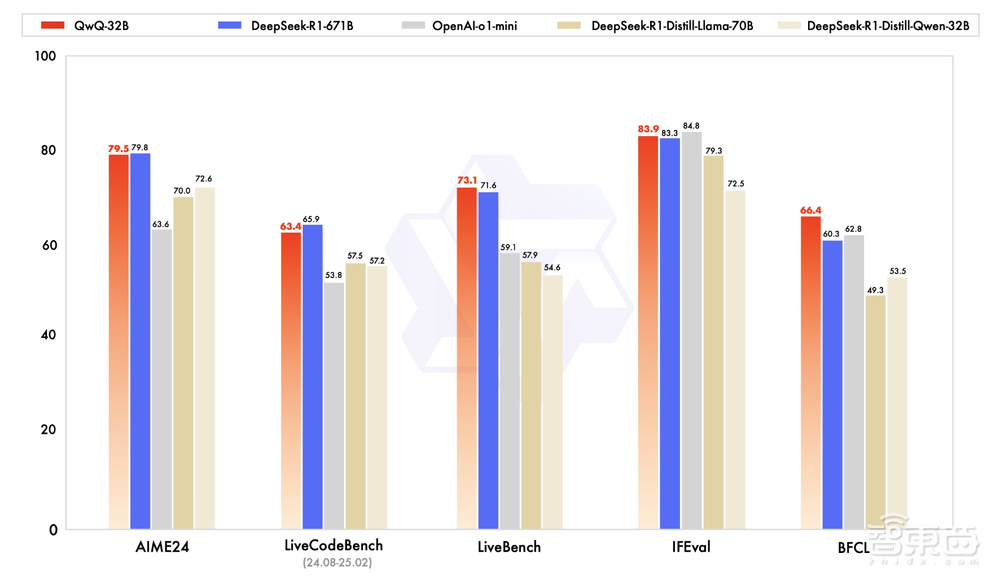
在測試數學能力的AIME24評測集上,以及評估代碼能力的LiveCodeBench中,QwQ-32B表現與DeepSeek-R1相當,強於o1-mini及相同尺寸的R1蒸餾模型。
在由Meta首席科學家楊立昆領銜的「最難LLMs評測榜」LiveBench、谷歌等提出的指令遵循能力IFEval評測集、由加州大學伯克利分校等提出的評估準確調用函數或工具方面的BFCL測試中,QwQ-32B得分超越DeepSeek- R1。
QwQ-32B的優勢還在於,QwQ-32B需要GPU上的24GB vRAM(英偉達H100為80GB),而運行完整的DeepSeek R1需要超過1500GB vRAM。
社交平台X上的網友已經為之瘋狂,到處充斥着「太震驚了」的言論。
機器學習愛好者Vaibhav (VB) Srivastav強調了QwQ-32B的推理速度,稱其「非常快」,可與頂級模型相媲美。

網友曬出了在M4 Max芯片的MacBook上運行的推理速度:
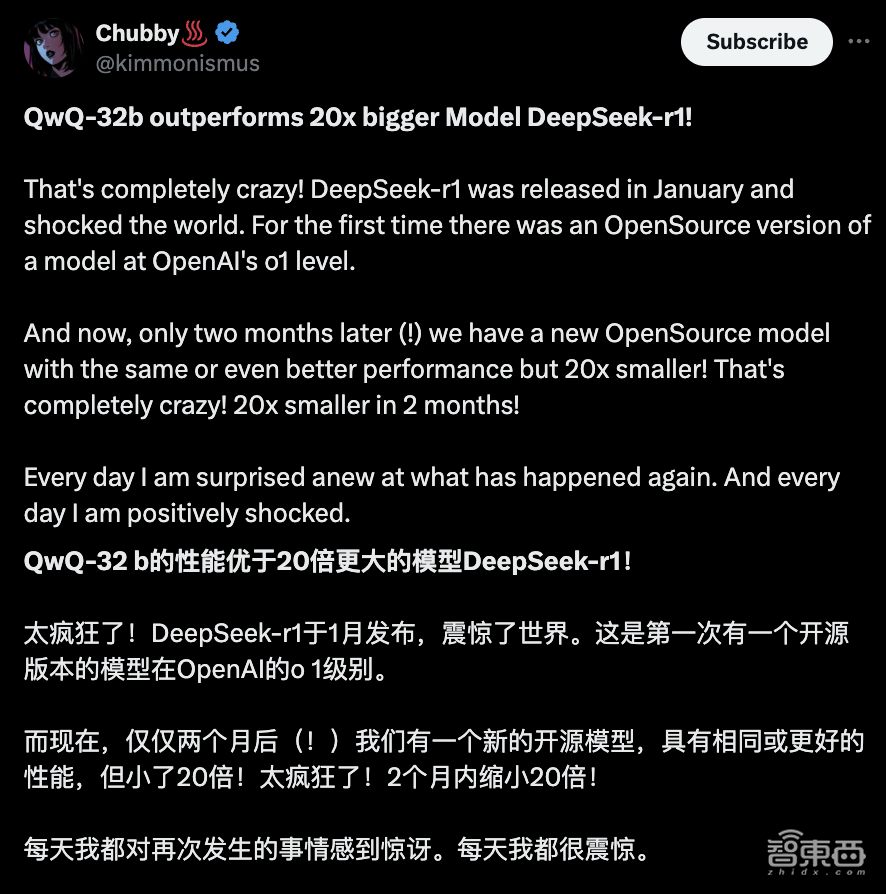
AI新聞發布者@Chubby稱QwQ-32 B太瘋狂了!
Hyperbolic Labs的聯合創始人兼首席技術官Yuchen Jin發文稱:「小模型太強大了!」

有網友嘗試了QwQ-32B的編碼能力,並稱讚其是o1-mini級別的可本地部署模型。他的提示詞是」Create an amazing animation using p5js(「使用p5.js創建一個精彩的動畫」)。效果如下:

不過也有網友指出,巨大的尺寸差異意味着用戶需要大約5%的高帶寬內存來進行推理。

二、擴展強化學習,可持續提高數學、編碼能力
研究人員在冷啓動的基礎上開展了大規模強化學習。在初始階段,他們特別針對數學和編程任務進行了強化學習訓練。
與依賴傳統的獎勵模型(reward model)不同,他們通過校驗生成答案的正確性來為數學問題提供反饋,並通過代碼執行服務器評估生成的代碼是否成功通過測試用例來提供代碼的反饋。隨着訓練輪次的推進,這兩個領域中的性能均表現出持續的提升。
QwQ-32B的強化學習過程分兩個階段執行:
數學和編碼重點:使用用於數學推理的準確性驗證器和用於編碼任務的代碼執行服務器來訓練該模型。這種方法確保生成的答案在被強化之前被驗證正確性。
通用能力增強:在第二階段,模型使用通用獎勵模型和基於規則的驗證器接受獎勵訓練。這個階段改進了指令遵循、人類對齊和代理推理,而不影響其數學和編碼能力。
QwQ-32B遵循因果語言模型架構,幷包括幾個優化:
1、64個Transformer層,具有RoPE、SwiGLU、RMS Norm和Attention QKV偏置;
2、分組查詢注意力(GQA),40個attention heads用於查詢,8個attention heads用於鍵值對(key-value pairs);
3、擴展了131072個Tokens的上下文長度,允許更好地處理長序列輸入;
4、多階段訓練,包括預訓練,監督微調和RL。
憑藉其強化學習驅動的推理能力,該模型可以提供更準確、結構化和上下文感知的見解,使其可用於自動化數據分析、戰略規劃、軟件開發和智能自動化等用例具有價值。
為了獲得最佳性能,通義千問團隊建議使用以下設定:
1、強制正確輸出:確保模型以「」開頭,以防止生成空的思考內容,這會降低輸出質量。如果你使用apply_chat_template並設定add_generation_prompt=True就可以自動實現,但可能會導致響應在開始時缺少標籤。
2、採樣參數:使用Temperature=0.6和TopP=0.95而不是Greedy解碼,以避免無休止的重複;使用20到40之間的TopK來過濾掉罕見的Token出現,同時保持生成的輸出多樣性。
3、標準化輸出格式:數學問題:包括「請一步一步推理,並把你的最終答案放在\boxed{}內。」在提示;多項選擇題:將以下JSON結構添加到提示中,以標準化回答:「請在答案字段中僅顯示選擇字母,例如\「答案\」:\「C\」。
4、處於長文本輸入:對於超過32768個Token的輸入,啓用YaRN以提高模型有效捕獲長序列信息的能力。
此外,該模型支持使用vLLM(一種高吞吐量推理框架)進行部署。然而,vLLM的當前實現僅支持靜態YaRN縮放,即無論輸入長度如何,都保持固定的縮放因子。
結語:強化學習成下一代模型關鍵驅動
基於QwQ-32B,研究人員將強化學習定位為下一代AI模型的關鍵驅動力,證明可以產生高性能和有效的推理系統。
其博客中還提到,通義千問團隊計劃:進一步探索擴展RL以提高模型智能;將Agent與RL集成用於長時間推理;繼續開發為RL優化的基礎模型;通過更先進的訓練技術向通用人工智能發展。
這是通義千問團隊通過大規模強化學習以增強推理能力方面的第一步,其擴展了強化學習的巨大潛力,同時還展現出預訓練語言模型中尚未開發的可能性。