來源:源達
投資要點
全球首款通用性AI Agent——Manus
中國創業公司Monica於2025年3月6日發布全球第一款通用型AI Agent——Manus,其在GAIA 的基準測試中取得了新的SOTA表現, 超越Open AI同級產品。Manus採用Multiple Agent架構, 可將複雜任務拆分為規劃、執行、驗證等子模塊,運行在獨立的虛擬機中。目前,Manus已提供多種處理現實世界任務的案例,包括個性化旅行規劃、深度股票分析、保險政策比較、供應商採購、財務報告分析、專業數據整理、教育內容創建等。該產品體現國內 Al Agent 產品強大的通用性和複雜任務執行能力。此外,官方計劃在今年開源Manus的推理部分,國內廠商有望內化Manus的通用任務執行能力,從而進一步推動AI應用的落地。
DeepSeek算法創新催動AI平權
DeepSeek R1版本模型在訓練方法上的核心創新點在於通過極簡的規則化獎勵設計(準確性獎勵和格式獎勵)來替代複雜的傳統的微調(SFT以及RLHF),從而實現高效的推理能力優化,以及節約大量的算力成本。該方法在後續產品的迭代中得到了延續,3月25日,DeepSeek 宣佈V3 模型已完成小版本升級,該版本借鑑了DeepSeek-R1 模型訓練過程中所使用的強化學習技術,在推理類任務上的表現水平大幅提高,在數學、代碼類相關評測集上取得了超過 GPT-4.5 的得分成績。DeepSeek-R1的算法創新使得模型在極少標註數據條件下顯著地提升模型推理能力,AI 產業鏈價值鏈分配或向中小廠商傾斜。此外,在醫療、金融合規等垂直領域,僅需少量領域規則即可微調模型,無需海量標註數據,相關應用側公司有望受益。
投資建議
建議關注AI應用側的投資機會:1) AI語音: 科大訊飛;2) 金融IT:恒生電子;3)醫療IT:衛寧健康;4)AI視頻/圖像創作:萬興科技。
風險提示
AI 技術發展不及預期;AI應用滲透不及預期;競爭格局惡化。
一、國內創業公司發布全球首款通用型AI Agent
1.全球首款通用型AI Agent——Manus
中國的創業公司Monica於2025 年 3 月 6 日發布全球第一款通用型AI Agent , 據團隊介紹,「Manus是全球第一款通用Agent產品,可以解決各類複雜多變的任務。無論用戶需要深入的市場調研、繁瑣的文件批量處理、個性化的旅行規劃還是專業的數據分析,Manus都能通過獨立思考和系統規劃,在自己的虛擬環境中靈活調用各類工具——編寫並執行代碼、智能瀏覽網頁、操作各類網頁應用——為用戶直接交付完整的任務成果,而非僅僅提供建議或答案。」
|
圖1:Manus 初始運行界面 |
圖2:Manus執行結果界面 |
 |
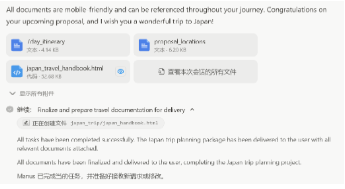 |
|
資料來源:Manus官網,源達信息證券研究所 |
資料來源:Manus官網,源達信息證券研究所 |
根據官網資料,Manus在GAIA(General Artificial Intelligence Assistant benchmark)的基準測試中, 在所有三個難度級別上都取得了新的SOTA(state of the art)表現, 超越Open AI同級產品。
圖3:Manus GAIA基準測試
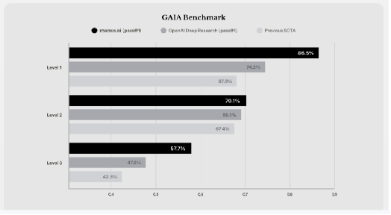
資料來源:Manus官網,源達信息證券研究所
GAIA為FAIR、Meta、HuggingFace等於2023年發布的通用人工智能助手基準測試,提出了系列需要推理、多模態處理、網頁瀏覽和工具使用等基本能力的現實世界問題。對於人類來說,這些問題在概念上很簡單,但對大多數先進的人工智能來說卻具有挑戰性:測試中人類受訪者正確率達92%,而配備插件的GPT-4僅獲得15%。GAIA可以根據解決問題所需的步驟數量和所需的不同工具數量分為三個難度級別:
1)Level 1:問題通常不需要工具,或最多使用一個工具,不超過5步;
2)Level 2:問題通常涉及更多步驟,大約在5到 10步之間,且需要結合不同的工具;
3)Level 3:問題是為接近完美的通用助手設計的,需要執行任意長度的操作序列,使用任意數量的工具,並訪問一般世界。
此外,Manus 支持文本、文檔、壓縮包等多種類型的輸入。在指令發出後,Manus 能夠在虛擬機內自行配置和使用終端、編輯器、瀏覽器等工具,完全自主地實現複雜任務的拆解、規劃與異步執行。在執行期間,頁面左側顯示有系統當前的運行狀態,右側則顯示正在訪問的頁面或整體進度。由於 Manus 是在雲中異步工作的,一方面用戶可以同時運行多個 Manus 會話,並行執行不同任務;同時用戶也可以在任務執行過程中關閉計算機,Manus 將在後台繼續運行,並且會在任務完成後發送通知。此外,Manus 也支持任務執行過程中的實時交互。
圖4:Manus 系統運行情況
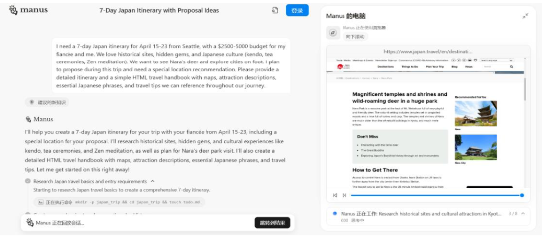
資料來源:Manus官網,源達信息證券研究所
在實際使用當中,目前Manus已提供多種處理現實世界任務的案例,包括個性化旅行規劃(整合旅行信息、為用戶創建定製旅行手冊)、深度股票分析(全面股票洞察)、保險政策比較(創建保險政策比較表)、供應商採購(找到最適合用戶需求的供應商)、財務報告分析(研究和數據分析捕捉市場對特定公司的情緒變化)、專業數據整理(創業公司列表整理)、教育內容創建(為中學教師創建視頻演示材料)等。
目前,該產品還在內測之中,用戶可在登入後申請加入內測。
圖5:Manus 涵蓋的應用場景
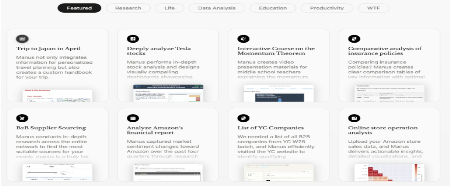
資料來源:Manus官網,源達信息證券研究所
- Manus 性能對比領先於Operator
Manus目前採用Multiple Agent架構,將複雜任務拆分為規劃、執行、驗證等子模塊,運行在獨立的虛擬機中,通過規劃代理、執行代理、驗證代理的分工協作機制來大幅提升對複雜任務的處理效率,並通過並行計算縮短響應時間。
在Multiple Agent的架構中,每個代理可能基於獨立的語言模型或強化學習模型,彼此通過API或消息隊列通信。同時每個任務也都在沙盒中運行,避免干擾其他任務,支持雲端擴展。每個獨立模型都能模仿人類處理任務的流程,比如先思考和規劃,理解複雜指令並拆解為可執行的步驟,再調用合適的工具。
與Manus 有相似功能的Agent 是Open AI 於25年1月份發布的Operator, 該產品是一款由 Open AI 推出的 AI 瀏覽器智能體,由計算機使用代理(Computer-Using Agent,)驅動,結合了 GPT-4o 的視覺能力以及強化學習下的高級推理,能夠識別網頁並自動實現與網頁的交互,且具備一定的推理能力,可以在遇到問題時自我糾正,可以在無法解決時將控制權交換給用戶。
|
圖6:Operator運行界面 |
圖7: Operator 應用場景 |
 |
 |
|
資料來源:Open AI官網,源達信息證券研究所 |
資料來源:Open AI官網,源達信息證券研究所 |
在性能測試中,Manus 與Operator均可以構建出虛擬環境和資源進行CUA一些列動作執行。
Manus能夠在雲端獨立完成任務,無需人工干預,直接交付完整的任務成果,同時由多種模型支持,具備強大的工具調用能力,可靈活編寫代碼、智能瀏覽網頁和操作各類應用,不僅僅侷限於單一任務,而是能夠跨領域、跨任務地提供解決方案。
而Operator主要運行在瀏覽器中, 無法調用終端、文件系統等資源交付最終結果。
表1:Manus 與Operator 性能對比
|
Manus |
Operator |
|
|
技術架構 |
Multiple Agent |
Computer-Using Agent |
|
是否能創建雲上虛擬機 |
是 |
是 |
|
是否支持瀏覽器外的操作 |
是 |
否 |
|
推理能力 |
強 |
較弱 |
|
魯棒性 |
強 |
較弱 |
資料來源:Manus,Open AI, 國金證券研究所,源達信息證券研究所
3.Manus計劃開源模型推理部分,進一步推動AI 應用落地
3月11日,Manus平台宣佈將與阿里通義千問團隊正式達成戰略合作。雙方將基於通義千問系列開源模型,在國產模型和算力平台上實現Manus的全部功能。目前兩家技術團隊已展開緊密協作,致力於為中國用戶打造更具創造力的通用智能體產品,Manus產品使用了不同的基於阿里千問大模型(Qwen)的微調模型。
此外,官方將計劃在今年開源Manus中的部分模型,特別是Manus的推理部分。國內廠商有望內化Manus的通用任務執行能力,推出在多個領域具有泛化應用效果的模型,有望進一步推動AI應用的落地。
二、Deepseek 通過算法優化實現 AI 平權
1.Deepseek R1 版本實現重要算法創新
AI 傳統的訓練方法包括預訓練(Pre-Training)以及微調(Fine-Tuning),主要過程可以簡化為:隨機模型 → 預訓練(爬取數據)→ 預訓練模型 → 微調(領域數據)→ 微調模型 → 提示/上下文學習 → 實際應用。
具體來看,從一個隨機初始化的大語言模型(Random Model)開始,模型參數未經訓練,接着使用大規模、多樣化的爬取數據進行無監督學習。這些數據通常包含網頁文本、書籍、代碼等。通過預測下一個詞或掩碼詞等任務,學習通用語言表示,得到一個預訓練模型,具備通用語言理解能力。接着通過在監督微調(SFT)加入大量的思維鏈(COT)範例,用例證和複雜的如過程獎勵模型(PRM)之類的複雜神經網絡獎勵模型,來讓模型學會用思維鏈思考,使其適應具體任務。
圖8:AI模型的訓練方法
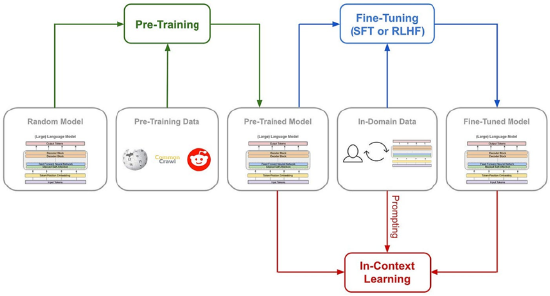
資料來源:騰訊科技公衆號,源達信息證券研究所
圖9:SFT微調示例

資料來源:源達信息證券研究所
圖10:RLHF微調示例
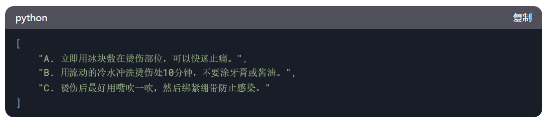
資料來源:源達信息證券研究所
DeepSeek-R1-Zero訓練方法降低計算資源消耗。DeepSeek-R1-Zero在訓練方法上的核心創新點在於通過極簡的規則化獎勵設計(準確性獎勵和格式獎勵)來替代複雜的傳統的微調(SFT以及RLHF),從而實現高效的推理能力優化。
規則化獎勵設計具體包括:
- 準確性獎勵:準確性獎勵模型評估響應是否正確。對了就加分,錯了扣分。評價方法也很簡單:例如,在具有確定性結果的數學問題中,模型需要以指定格式(如<answer>和</answer>間)提供最終答案;對於編程問題,可以使用編譯器根據預定義的測試用例生成反饋。
- 格式獎勵:格式獎勵模型強制要求模型將其思考過程置於<think>和</think>標籤(該標籤為思考的開閉過程)之間。沒這麼做就扣分,做了就加分。
同時讓模型在GRPO(Group Relative Policy Optimization)的規則下自我採樣+比較,自我提升。即通過組內樣本的排序(如「組1 > 組2」)比較來計算策略梯度,有效降低了訓練的不穩定性,同時提高了學習效率。該訓練方法首先可以使訓練效率的提升,所需訓練時間更短,其次是省去了SFT和複雜的獎懲模型,從而降低計算資源消耗。
表2:不同訓練路徑對比
|
方法 |
獎勵來源 |
數據需求 |
|
傳統RLHF |
人類偏好模型 |
大量人工標註 |
|
監督微調SFT |
標註輸入-輸出對 |
高質量標註 |
|
R1-Zero |
規則(答案/格式校驗) |
無人工標註 |
資料來源:DeepSeek, 源達信息證券研究所
表3: DeepSeek-R1-Zero算力節省原因
|
環節 |
傳統RLHF |
DeepSeek-R1-Zero |
算力節省原因 |
|
獎勵計算 |
訓練RM(需GPU計算) |
規則匹配(CPU正則表達式) |
省去神經網絡前向傳播和反向傳播 |
|
RL算法 |
PPO(多步優化,高方差) |
單步策略梯度(如REINFORCE) |
簡化策略更新,減少交互次數 |
|
數據需求 |
大規模人類標註數據 |
自動生成+規則驗證 |
零標註成本,數據生成算力可忽略 |
|
調試成本 |
需調參RM和PPO超參數 |
規則邏輯透明,調試簡單 |
減少實驗迭代次數 |
資料來源:DeepSeek, 源達信息證券研究所
此外,DeepSeek-R1-Zero訓練方法可以快速提高模型的推理能力。根據DeepSeek的研究論文,大模型在訓練學習的過程中,響應長度會出現突然的顯著增長後又回落,這些「跳躍點」可能暗示模型推理解題策略的質變,即模型推理能力的顯著提升。
如下圖所示:
圖11: DeepSeek-R1-Zero 在訓練過程中出現跳躍點
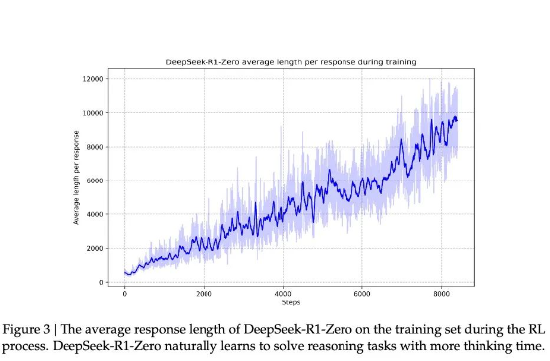
資料來源:Deepseek,源達信息證券研究所
Deepseek R1-Zero在數學界享有盛譽的AIME競賽中從最初的15.6%正確率一路攀升至71.0%的準確率。AIME的題目需要深度的數學直覺和創造性思維,而不是機械性的公式應用。
圖12: DeepSeek-R1-Zero 在AIME的表現
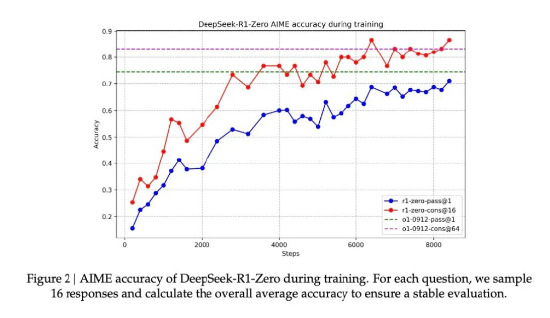
資料來源:Deepseek,源達信息證券研究所
- 創新強化學習技術助力Deepseek V3完成小版本升級
3月25日,DeepSeek 宣佈V3 模型已完成小版本升級,目前版本號 DeepSeek-V3-0324,根據官方公衆號描述,DeepSeek-V3-0324 與之前的 DeepSeek-V3 使用同樣的 base 模型,僅借鑑了DeepSeek-R1 版本模型訓練過程中所使用的強化學習技術,便大幅提高了在推理類任務上的表現水平,在數學、代碼類相關評測集上取得了超過 GPT-4.5 的得分成績。
圖13: DeepSeek-V3-0324 相對於其他模型的表現
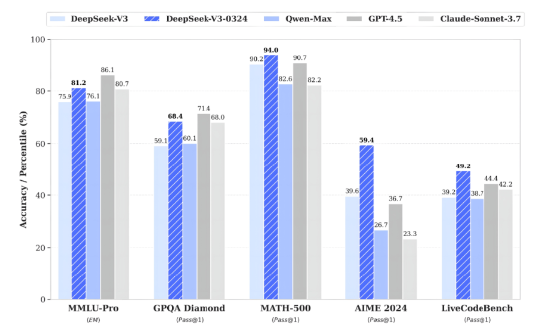
資料來源:Deepseek,源達信息證券研究所
綜上, DeepSeek-R1版本模型的算法創新使得模型在極少標註數據條件下顯著地提升模型推理能力,在數學、代碼、自然語言推理等任務上性能對齊海外模型。過往大模型遵循Scalling Law準則,頭部廠商能夠憑藉先發以及投入優勢吸引資源聚集構建自身護城河,Deepseek R1 則打破了在算力和芯片上「大力出奇跡」的既定格局,極大衝擊頭部模型廠商壁壘,AI 產業鏈價值鏈分配或向中小廠商傾斜。
三、投資建議
1.建議關注
Manus計劃在今年開源其推理部分的模型,國內廠商有望內化Manus的通用任務執行能力,推出在多個領域具有泛化應用效果的模型,有望進一步推動AI應用的落地。
以Deepseek-R1引領的 AI 技術平權使得中小廠商廣泛受益,算力資源有限的機構也可高效地訓練高性能模型。此外,在醫療、金融合規等垂直領域,僅需少量領域規則即可微調模型,無需海量標註數據,相關應用側公司有望受益。
建議關注AI應用側的投資機會:1) AI語音: 科大訊飛;2) 金融IT:恒生電子;3)醫療IT:衛寧健康;4)AI視頻/圖像創作:萬興科技。
2.行業重點公司一致盈利預測
表4:萬得一致盈利預測
|
公司 |
代碼 |
歸母淨利潤(億元) |
PE |
總市值(億元) |
||||
|
2024E |
2025E |
2026E |
2024E |
2025E |
2026E |
|||
|
科大訊飛 |
002230.SZ |
5.7 |
9.0 |
12.3 |
194.1 |
122.9 |
90.3 |
1115.4 |
|
恒生電子 |
600570.SH |
10.4 |
16.0 |
18.5 |
50.5 |
32.8 |
28.2 |
526.9 |
|
萬興科技 |
300624.SZ |
0.3 |
0.8 |
1.2 |
362.1 |
140.7 |
103.1 |
120.6 |
|
衛寧健康 |
300253.SZ |
4.4 |
5.7 |
7.3 |
54.3 |
41.7 |
32.7 |
239.5 |
資料來源:Wind一致預期(2025/4/2),源達信息證券研究所
四、風險提示
AI 技術發展不及預期;
AI應用滲透不及預期;
競爭格局惡化。
責任編輯:劉萬里 SF014