
文|劉俊宏
編|王一粟
「AI大模型讓我們看到自動駕駛,比任何時候都接近於落地。」
在中國汽車智駕能力競爭愈發激烈的今天,小鵬汽車自動駕駛副總裁李力耘找到了智駕通往自動駕駛的大門。
針對去年車企們熱衷的端到端的智駕訓練模式,李力耘認為智駕模型還能做得更大,要突破過去端到端模型的「一畝三分地」。
端到端的模型做智駕的好處,李力耘解釋說,「用端到端的模型做自動駕駛,我覺得無非兩個重要的點:一是保持信息的無損。另一個是降低整個車輛的延時,讓自動駕駛的功能更加敏捷、高效和擬人。」
但直接學習人類行為的端到端,其上限只是接近人類。在大量的數據和訓練中,智駕逐漸形成類似於人類日常駕駛的能力和習慣。但真正遇到極端場景時,智駕廠商幾乎拿不到這部分數據。一方面是因為場景發生的頻次非常少,另一方面是人類自己都反應不過來,根本就沒有「可以參考的答案」。
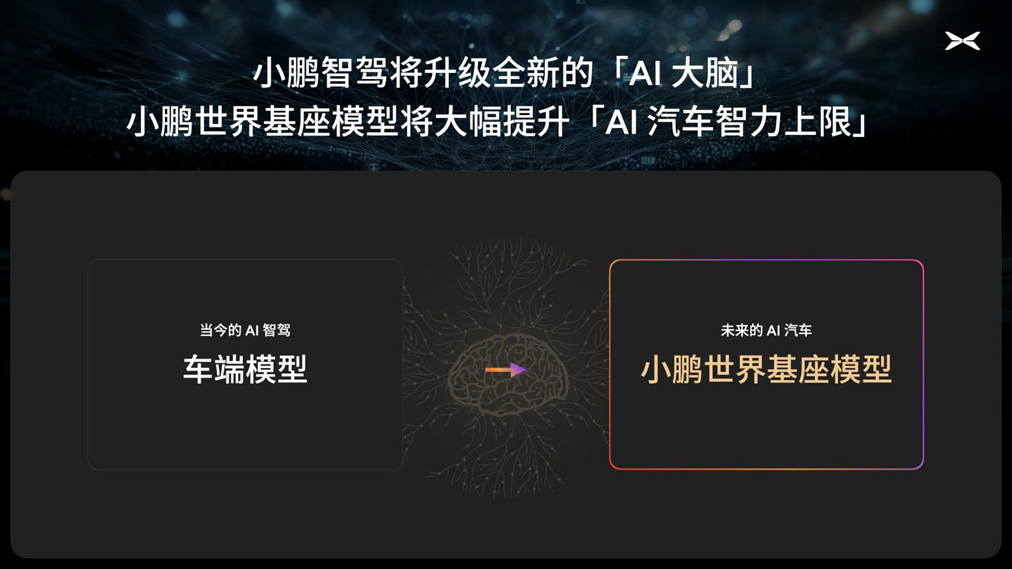
如何讓端到端智駕變得更強?小鵬給出的答案是用雲端大模型蒸餾並輔以強化學習的方式,跳出之前車端思路做智駕模型的「一畝三分地」。
事實上,過往的自動駕駛其實並沒有真正用到「大模型」。參考去年雲端模型的進化,AI成長的基本邏輯,遵循Scaling Law的「規模越大,能力越大」。
「基於當前主流的車端芯片,車端模型的尺寸一般在1億到5億之間。最近非常受到業界關注的VLA模型,參數規模一般在20億左右。這是因為自動駕駛的模型其實是一個非常複雜的,既需要兼顧視覺,也需要兼顧推理,最後還需要有動作輸出的一個大模型。但是雲端大模型可以真正突破這樣的限制,整個參數量可以達到主流車端模型的35倍以上。」李力耘介紹道。
為了搭建雲端足夠強的大模型,本次小鵬首次披露了正在研發的720億參數的超大規模自動駕駛大模型,即「小鵬世界基座模型」。
未來,小鵬將通過雲端蒸餾小模型的方式將基模部署到車端,給「AI汽車」配備全新的大腦。
針對算力優化,小鵬從2024年開始搭建AI基礎設施(AI Infra),當前已建立起萬卡規模的智能算力集羣,是目前國內汽車行業最大的自動駕駛算力集羣。
如今,小鵬的算力儲備達到10EFLOPS,集羣利用率常年高達90%以上,高峯時期的運行效率甚至達到98%。
「我們為什麼要投入巨大的資源去做雲端的基座模型呢?如果我們只侷限在車端算力的一畝三分地,我們模型大小是受限的,能真正消化的數據也是受限的。只有超越車端芯片算力的限制,真正用更大的模型、更海量的數據,去大道至簡地把駕駛這件事做好,我們才能真正實現車端的智能。」李力耘介紹說。
如何讓車端模型擁有云端大模型的能力?李力耘借用了去年雲端模型的兩個最重要的進化,「一個是知識的蒸餾,另一個是強化學習」。
Deepseek在數字世界證明了蒸餾和強化學習能夠大幅增強大模型的能力,小鵬現在在具身物理世界嘗試執行和落地。
其中,知識的蒸餾是先讓雲端大模型擁有深度思考(CoT思維鏈)的能力,然後再將這些能力蒸餾到車端模型上。在雲端訓練中,大模型形成對每一個場景會做出一系列符合邏輯,但又可能超越訓練數據本身的思維鏈條。然後再將這些思維通過訓練數據轉化為操作,並以一個合適的頻率操縱自動駕駛。
引入思維鏈之後,智駕大模型展現出了極強的泛化能力。「在香港其實我們並沒有正式開放XNGP功能,但我們的用戶發現在這裏XNGP也可按照導航駕駛我們的車。說明了在真正大模型能力賦能下,通過蒸餾是可以期待自動駕駛真正具備自己的靈魂、自己的大腦的。」李力耘介紹說。
在蒸餾之後,接下來是利用強化學習來打破智駕大模型的上限,進而達到比人駕更安全的效果。在危急場景下,人類會緊張,會受到思維慣性的影響,但AI不會。針對AI強化學習,本質上就是允許AI利用一切操作,突破人類固有的認知,找到危險場景的可行解,從而最大化保障行車安全。
對於強化學習,根據小鵬世界基座模型負責人劉博士介紹,小鵬選擇從三個方面入手搭建整個獎勵機制。
首先是設計獎勵函數。小鵬在這部分使用的是最簡單的規則,例如合規、安全、舒適等,這些參數直接決定了行車體驗。這些規則的設計和出發點,來自小鵬過往智駕研發過程中積累的大量經驗。以這些規則作為大模型強化學習的開始,小鵬的智駕大模型在起步之初就打好了基礎能力。
其次是設計獎勵模型。獎勵模型的設計目的,是讓智駕模型獲得更連續、更泛化、更多維的獎勵信息。簡單來說就是告訴智駕「什麼是好的」,並以此讓智駕想辦法達成這些表現。這部分小鵬更重視智駕接管和市場的反饋數據,獎勵模型就會讓智駕儘量避免接管,或按照市場建議來改進「開車習慣」。
最後是世界模型。作為當前智駕最前沿的技術方案,行業內主要用世界模型來進行仿真,從而讓端到端智駕持續獲得泛化能力。在小鵬看來,世界模型不只是現實世界的「模擬器」。要想用好世界模型,就得將它作為智駕模型的閉環「訓練場」。世界模型要有能力根據智駕模型的動作輸入,模擬出真實的場景,並且生成其他智能體的響應,從而構建閉環的訓練網絡。
如何理解世界模型應該具有的能力?劉博士舉了這樣一個例子,假設智駕看到前面有輛車,隨後選擇了繞行。對過的車輛看見我們正在繞行,它也會稍微避開一點空間,而不是繼續保持直行。世界模型本身的運行,應該符合常識,而非「生硬死板」的模擬空間。「世界模型更像是一個生成式的想象系統,要理解這個世界以及如何去完成動作」,劉博士總結說。
「在今天真的是非常幸運,在大模型的賦能下,我們真正看到自動駕駛離我們前所未有的近。」
回想起從事自動駕駛開發的經歷,李力耘唏噓不已。一路走來,小鵬汽車經歷了硬件算力稀缺的時期,走過了不停寫規則完善智駕的艱辛,也體驗了端到端加速智駕研發的驚喜。面對自動駕駛的「高峯」,李力耘在研發中越來越有信心。
「功成不必在我,功成必定有我。我們小鵬汽車自動駕駛團隊一定會在這條路上持續深耕,一定會把真正的自動駕駛帶給大家。」
以下為小鵬AI大模型技術溝通會問答環節實錄(經光錐智能編輯整理)。受訪者為小鵬汽車自動駕駛副總裁李力耘與小鵬汽車自動駕駛產品高級總監袁婷婷。
Q:小鵬的AI模型開發與特斯拉有什麼相同與不同?世界模型與其他友商有什麼區別?
李力耘:我覺得應該是「英雄所見略同」。首先我們都是面向C端的公司,都有C端落地的產品,所以我們都有海量的數據。其次,我們都有非常高的算力儲備和AI能力。我覺得很多東西可能就不言自明瞭,如果AI能力只是為了從車端訓練小的模型的話,肯定不是一個終極方案。區別部分是小鵬的基座模型不僅僅是對世界的理解,更重要的是需要它像人一樣大小腦兼併,可快可慢,進而實現與現實世界的交互。
袁婷婷:現在可能大部分人想要用世界模型做仿真,但很顯然它不僅僅是只能做仿真。我們還在用模型來調教Agent(智能體)的反饋,和它之間的博弈以及接下來要做哪些動作。
Q:基於以往的規則,可以理解為是一種託底嗎?世界模型生成的規則是否可能與以往設定的規則產生衝突?很多人都在提基座模型、VLA,看起來好像都是語言、視覺或者說動態的、多模態的概念,這些區別到底在哪裏?
李力耘:我覺得最重要的區別是超越車端芯片算力的「一畝三分地」,我們的模型真的就是「大道至簡」。不需要考慮部署的問題,就是先通過最簡單的模型、最純粹的模型架構、最海量的優質數據,達到超越的、未曾想到的能力湧現效果。
關於語言,語言是一種表徵形式。不是說所有語言都應該以人類語言的形式表示。我們基於大語言模型加上獨特的多模態視頻編碼器的輸入,再加上我們動作解碼器的輸出,最後進行強化學習。我們的基座模型的目的,是為了做好物理世界交互。語言模型的預訓練是一個起點,讓模型有初步的推理能力,但更重要的還是讓模型體現出推理和思維能力。在雲端驗證了這些能力之後,這纔是我們值得去蒸餾的東西。
回到規則,在規則時代小鵬無疑是領先的,我們的規則積累很深。這些規則,以前可能算是一個負擔,但現在非常自豪和高興,因為這些規則正在轉化成我們的資本。我們成功完成了很多核心研發同學從規則化到AI化的轉型,尤其在強化學習的初期,規則其實算是積累好的經驗和老師,規則不斷沉澱,AI才能更高效地成長。沒有以前規則的積累,可能會不知道如何去教AI。只有規則和強化學習的積累到一定程度,我們才能實現從Reward Model(獎勵模型)到World Model(世界模型)的轉變。
袁婷婷:我認為我們的雲端的基座大模型和別人的雲端訓練至少有三處不同。
第一是我們的訓練方式。我們在去年11月份就提出,先在雲端訓練一個非常巨大的模型,再蒸餾到車端的流程。今年1月我們看到DeepSeek公開的論文顯示,他們也在用蒸餾方式時,我們感覺真的是英雄所見略同。通過這樣的方式,可以突破車端模型的能力上限,改變雲端參照車端算力來搭設模型規模的做法。
第二點是架構和性能表現不同。我們正在訓練的模型已經達到了72B的參數。更大的模型能夠支撐更大的訓練數據量,我們現在用到的是2000萬Clips,預計年底會達到2億Clips。這些領先行業數量級的訓練數據量,將轉化成模型性能上的巨大優勢。
第三點是我們的基礎能力。我們從0開始建了AI Infra,這些AI基礎設施不可能是一天忽然從0到1生成的。我們還建成了整個自動駕駛行業內首個萬卡集羣。如何把這些算力訓練的效率發揮到最大化,以及如何12小時就能訓練一版模型出來,這些都體現了我們今天領先於行業的一些特點。
Q:LLM的幻覺問題怎麼解決,需要規則兜底嗎?模型蒸餾到自研芯片上,其效率與使用常見芯片相比如何?
李力耘:確實大模型的預訓上有時候會有一些幻覺或者偶爾有一些模態坍塌。這些情況很難針對出問題的case用類似寫Loss-Function(損失函數)的方式解決。但我們通過後訓練微調和強化學習進行打磨,最終目標是讓AI不僅達到非常高的上限,而且還能對下限進行兜底。我們跟現在的車端端到端不一樣,車端的端到端模型很小,有時候有一些東西確實很難學進去。但云端大模型是有能力掌握真正的靈魂和智能的,這是我們篤定的方向。
關於第二個問題。在雲端的世界模型、仿真、實車驗證了能力之後,是可以蒸餾到車端不同芯片上的。在確認雲端的能力之後,車端的芯片決定了承載能力。我們希望用自研的芯片和軟硬一體的優化給大家帶來事半功倍的效果。
袁婷婷:我認為第二個問題關鍵就兩點。第一是用蒸餾的方法一定能提高上限。所以,我們用雲端的基座模型蒸餾到車端的方式,是遠勝於現在直接訓車端的雙Orin或以後我們自己的芯片的。無論哪個都是加碼,這是一個確定性的答案。
第二點,我們馬上要發新車了。新的芯片算力一定比現在車端的算力有數倍提高。假設自動駕駛是一個人,需要有非常聰明的大腦、有非常銳利的眼睛,來面對這個世界並做出判斷。這個過程中,最核心的部分一定是聰明的大腦。大腦越大,轉的速度越快,一定更加厲害,我覺得這也是一個很簡單的常識性問題。所以,無論是今天的雙Orin車型還是來自研芯片的車型,都遵循ScalingLaw的進化。
Q:安全對汽車來講是生命線,AI技術未來在安全中如何發揮更大的作用,在當下我們這套系統中我們有沒有一些最新的思考?會再加一些規則或什麼樣的方式再去把控底線嗎?
李力耘:我們認為安全最重要的是要有雪亮的眼睛,要有聰明的大腦,以及靈敏的身手和反應。安全作為我們最重要的一環,我們也在往這三個方向努力。
雪亮的眼睛,就是我們眼觀六路,耳聽八方,比如在傳感器的覆蓋上,我們是非常重視的。當然,更重要的是,我們認為你要有聰明的大腦,這樣才能做到很多預防性的安全。最後,身手也需要好,無論是整個車端的端到端,還是通過雲端的基座模型蒸餾出來的端到端,都是一體式的,所以會有最小的延時,使用最多的信息,以最敏捷的方法去幫我們把安全做到更好。
袁婷婷:第一,AI汽車一定是安全汽車。AI汽車一定代表了AI安全,這是確定性的,而且AI的安全在整個小鵬核心戰略裏是關鍵的,是決不會退讓的一步。
第二,從端到端走向L3、L4的過程中,AI的第一步是端到端,它是極致人類行為的模擬。人類怎麼開我就怎麼開,可以和人類開得一樣好,它顯示出了你的舒適性、體驗、靈活性都非常高。但要超越人類的時候,強化學習一定會帶來新的驚喜。這也是為什麼我們會用雲端基座模型蒸餾的方式突破雲端的上限,用強化學習既突破雲端基座的上限,也突破車端的上限。
大家都非常擔心AI的幻覺,擔心下限守不住。首先,我想說我們現在可以看到的是隨着AI介入越來越多,其實安全性的表現是越來越好的,而未來這個表現應該還會持續得更好,並且會遠遠超出人類現在駕駛行為能夠帶來的安全。所以會給大家超出預期外的安全,在更多的極限場景,如果你要達到L3、L4,就一定要在會遇到概率0.0001%的情況下也能夠發揮出更好的實力。
Q:自研基座模型的必要性?為什麼其他基座模型蒸餾的效果做不到小鵬這樣?對模型開源有什麼理解?
袁婷婷:其實大家首先需要LLM作為骨幹,做自動駕駛就需要往上疊加大量現實世界數據。物理的AI世界非常複雜,跟文本的比特世界不一樣。物理世界會遇到現實的速度、操控,人類、運動等非常不一樣的狀況。我們添加了自動駕駛數據以後,還用CoT推理鏈去一步步理解,推導出整個現實世界的脈絡和物體的運動。這些都是區別,當然我們也有一個LLM的底層骨幹網。
我認為小鵬自動駕駛也好、智能座艙也好,其實在AI開源浪潮中是受益的。無論是通義千問還是DeepSeek這些非常棒的、非常優秀的AI公司,都讓我們有所受益,我們對未來的發展也抱着開放的態度。也許有一天大家也可以看到我們的自動駕駛有一部分也可以通過開放的方式,給世界和行業一些反饋,這也是我們對未來的期待,但今天肯定還沒有到這個時候。