
新智元報道
編輯:英智
【新智元導讀】大模型之戰烽火正酣,谷歌Gemini 2.5 Pro卻強勢逆襲!Gemini Flash預訓練負責人親自揭祕,深挖Gemini預訓練的關鍵技術,看谷歌如何在模型大小、算力、數據和推理成本間找到最優解。
谷歌憑藉Gemini 2.5 Pro在激烈的大模型競爭中一舉翻盤。
近日,Geimini Flash預訓練負責人Vlad Feinberg在普林斯頓大學分享了相關內容。
他深入分析了Gemini預訓練的方法、挑戰以及方向,如何在模型大小、算力、數據和推理成本間取得平衡。

PPT鏈接:https://vladfeinberg.com/assets/2025-04-24-princeton-talk.pdf
經典擴展定律
模型訓練中,計算資源的合理利用至關重要。
假設有計算資源(C)1000塊H100芯片,運行30天,如何訓練出最佳的LLM呢?
這就涉及到模型參數量(N)和訓練token數量(D)。
對於Transformer,計算量C和N、D之間存在一個近似公式:C≈6×N×D。

MLP是模型的重要組成部分,不同操作的浮點運算量和參數量有所不同。
比如
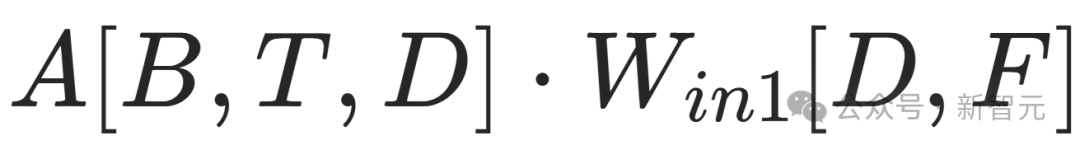
這個操作,訓練時的浮點運算量是6BTDF,參數量為DF。
把MLP的多個操作加起來,總訓練浮點運算量約為18BTDF,參數數量達到3DF。
注意力機制的計算更為複雜。將注意力機制相關操作的計算量相加,約為12BTSNH=12BT²NH,參數量為4DNH。
將MLP和注意力機制的計算量合併,就能了解整個模型訓練時的計算量情況。

Kaplan定律
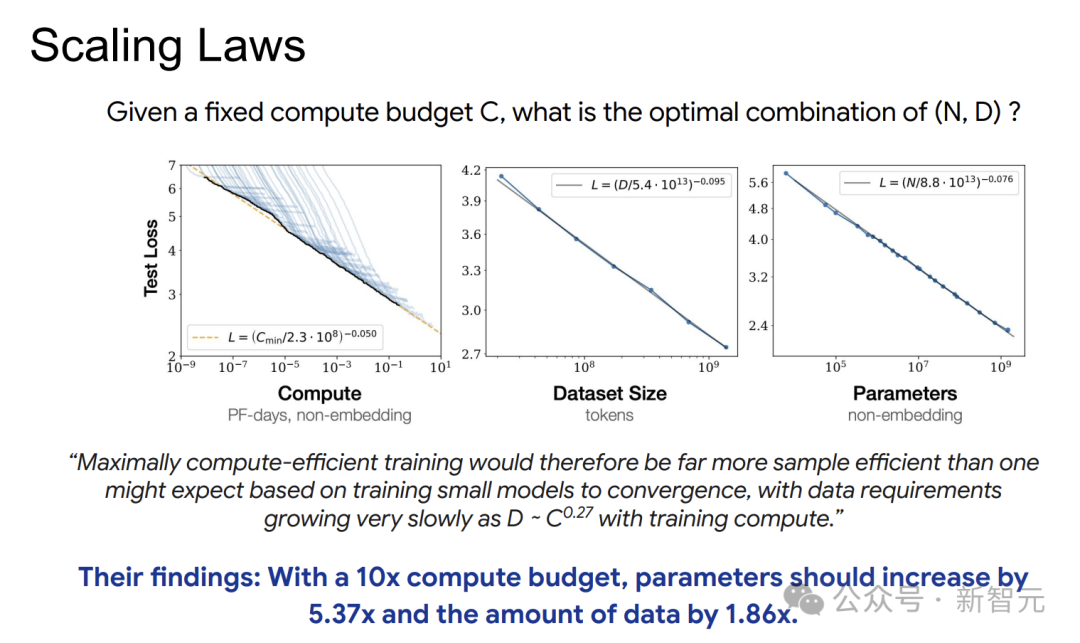
2020年,Kaplan等人的研究揭示了模型性能與數據量、模型規模和計算量之間的關係。
自迴歸Transformer模型中,小模型可以用來預測大模型的性能。
模型性能與算力、參數量、數據量之間存在冪律關係。當計算預算增加10倍時,模型參數量應增加5.37倍,數據量增加1.86倍。
這一結論在當時引起了廣泛關注,點燃了企業的「軍備競賽」。
Chinchilla(龍貓)
然而,2022年,DeepMind對Kaplan的觀點提出了質疑。

Kaplan的研究在每個模型規模下僅運行一次訓練,並用中間損失來估計不同token訓練步數下的損失。
Chinchilla論文指出,基於單次訓練的中間loss點來推斷存在缺陷,通過適當的學習率衰減可以獲得更好的損失值,只有最終的損失值纔是最優的。
論文采用IsoFlops方法,固定浮點運算量預算,同時改變模型規模和訓練token數量。
固定總算力C
訓練多個不同參數N的模型,對應不同數據量D(C≈6×N×D)
找到loss最低的模型N_opt(C)和D_opt(C)
重複以上步驟,得到不同算力下的最優(N,D)點,並擬合
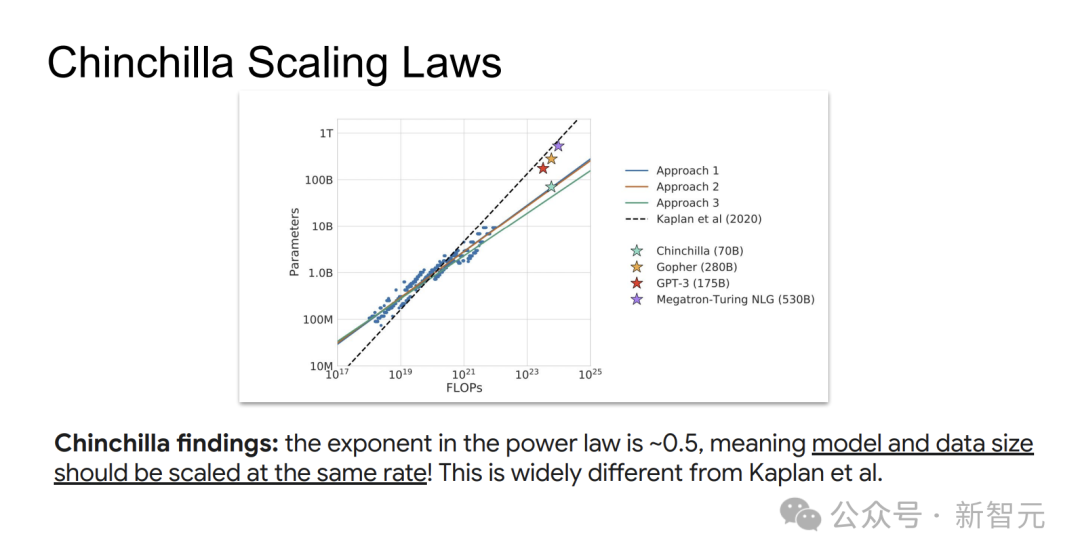
研究發現,模型參數N和數據量D應以大致相同的速率(冪律指數約為0.5)隨算力C增長,這與Kaplan等的結論大相徑庭。
這意味着,按Kaplan定律訓練的模型,可能存在訓練不足的情況,數據太少,會增加模型後續部署和使用的成本。
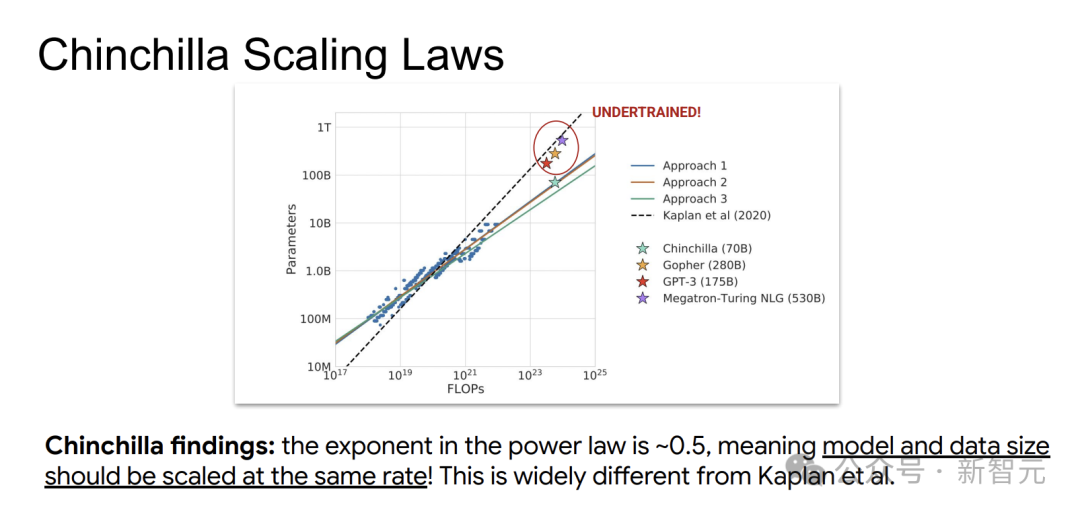
為了進一步優化模型訓練,研究人員嘗試了多種方法。通過不同的計算場景和擬合方式,得到了更精確的係數。
混合專家(MoE)模型的擴展定律展現出了獨特的優勢。與傳統模型相比,在相同的活躍參數數量和固定100B token的情況下,MoE 64E模型的性能更優。
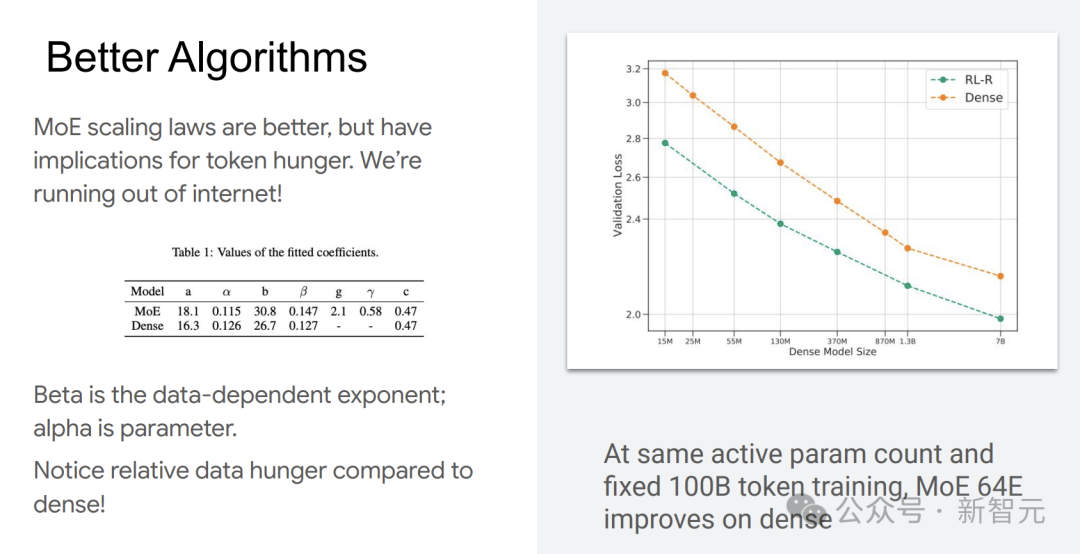
然而,MoE模型對token數據的需求量較大,互聯網上的可用數據逐漸難以滿足其需求,這成為了發展瓶頸。
為了解決數據不足的問題,研究人員將目光投向了更多的數據來源。多模態數據,如音頻、視覺、3D 模型、視頻等,為模型訓練提供了豐富的信息。
合成數據也受到了關注。實際應用中,需要在生成質量與篩選成本之間找到平衡。
實時場景的模型選擇
在谷歌的許多應用場景中,如免費的Gemini聊天機器人、AIO、AIM、Vertex AI(用於模型微調、部署)以及AI Studio(提供生成式API)等,推理效率至關重要。
這些應用需要快速給出準確的響應,對模型的推理速度和效率要求極高。
就拿實時應用來說,Astra和Mariner都需要快速響應。
以一個網絡交互智能體為例,假設上下文128k,但每次增量只有8k token,解碼需要128 token來生成一個動作,並且動作之間的延遲不超過1秒,其中250毫秒還得用於框架搭建、負載均衡等操作。
用Llama3-70B模型和v5e芯片做實驗,發現單芯片處理8k token需5.7秒。為了達到0.5秒的API延遲限制,需要搭建4×4 v5e並行。
實時應用中,小模型反而更有優勢,如Gemini Flash/Flash-lite。
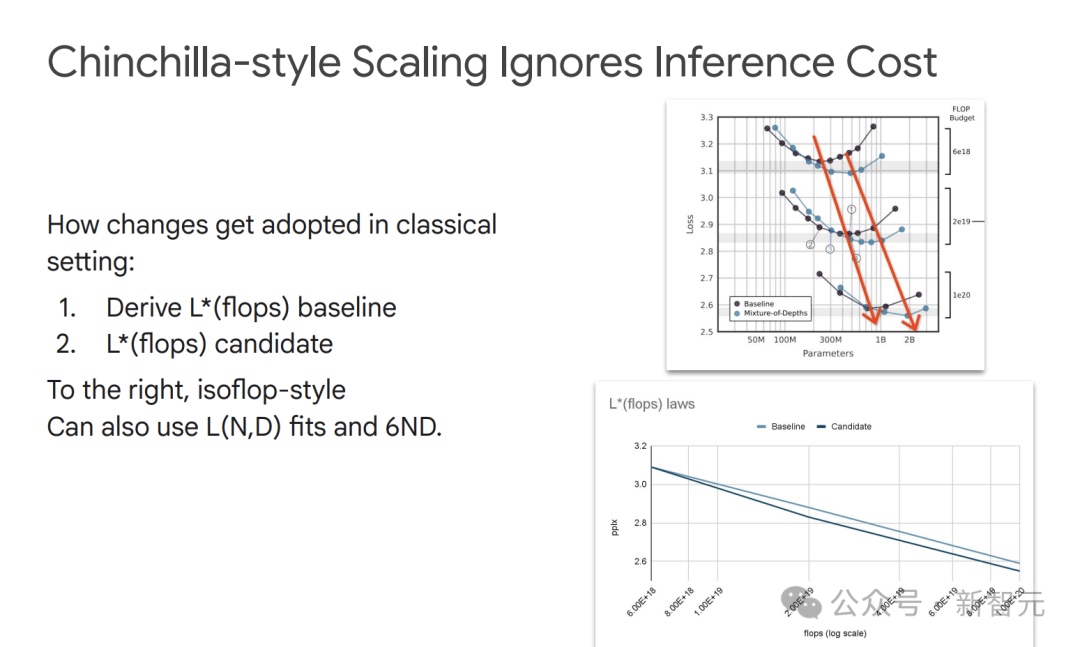
Chinchilla的擴展方法雖然在模型訓練的計算優化上有效,但它忽略了推理成本。
在實際應用中,需要綜合考慮訓練和推理的成本,找到更合適的模型和數據配置。
推理優化擴展定律
《超越Chinchilla最優:在語言模型擴展定律中考慮推理因素》這篇論文提出了新的推理優化Scaling Laws。
核心思想是,不僅最小化訓練loss,而是要綜合考慮訓練和推理的總計算量,為模型優化提供了新的方向。

按照這些公式,在相同計算量下,與Chinchilla最優策略相比,應該訓練更小的模型,並使用更多的數據,因為推理所需的計算量更少。
當然,這也存在新的挑戰。
計算資源的非同質性:實際應用中計算資源存在差異,用於推理優化的芯片各不相同,給推理優化帶來了困難。
推理量D_inf難以預測:技術進步提高資源利用效率,反而會增加對該資源的需求(傑文斯悖論)。模型質量提升可能會擴大市場,進而影響推理時的token數量D_inf。
擬合效果不佳:不同數據集下,相關參數的擬合效果存在差異。不同token與參數比例的數據子集,擬合得到的 α、β等參數不同,和Chinchilla的擬合結果也有較大差異。
針對這些問題,研究人員採用在數據約束下建模的方法。研究引入新維度,即有意區分數據,提出新的損失函數和數據規模公式,這樣訓練出來的模型更小,對數據重複的魯棒性更強。
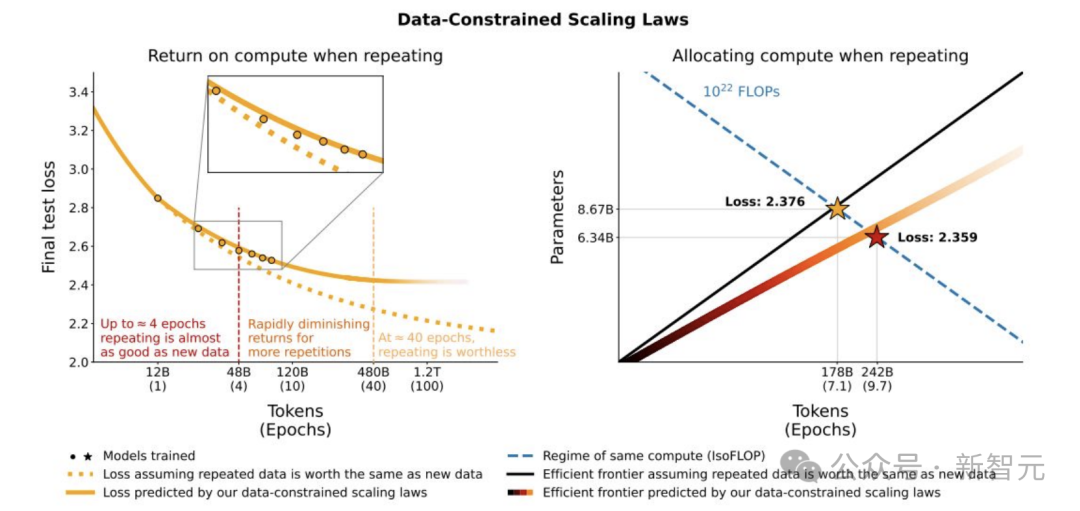
對於推理token數量的處理,像Llama3模型,有研究指出其8B和70B參數的模型,在訓練到15T token後,性能仍呈對數線性提升,即D_inf可視為無窮大。
蒸餾的探索與應用
除了模型大小、數據量和推理成本,知識蒸餾為推理優化擴展帶來了新的思路。
知識蒸餾擴展定律公式:
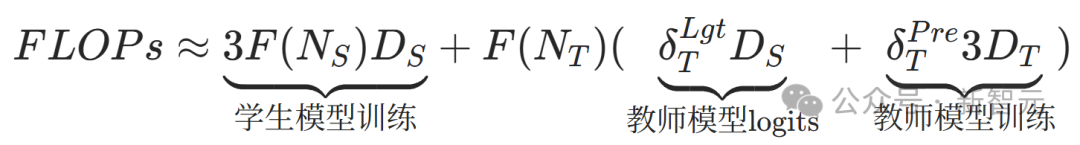
通過調整這些參數,可以優化學生模型的性能。
不過,知識蒸餾在實際應用中也有一些問題,比如趨勢影響不明顯、部分情況考慮不周全等,但可以通過權重調整等方法進行改進。
從原理上講,知識蒸餾能降低方差,更好的教師模型能減少偏差,為模型優化提供了新途徑。
谷歌Gemini預訓練技術對經典擴展定律和推理優化擴展定律都進行了深入研究。
經典擴展定律通過探索模型規模、數據量和計算量之間的關係,不斷優化模型訓練的資源配置。
推理優化擴展定律針對推理成本和效率問題,綜合考慮訓練和推理需求,提出新方法,提升模型整體性能。
同時,知識蒸餾等技術的應用也為模型的優化提供了更多的途徑。
Vlad Feinberg

Vlad Feinberg畢業於普林斯頓大學計算機科學專業,於加州大學伯克利分校RISE實驗室攻讀博士學位。
後來,Feinberg加入了一家名為Sisu的初創公司,擔任機器學習主管。他曾任職於谷歌研究院的Cerebra項目,目前在谷歌DeepMind工作。
參考資料:
https://x.com/JeffDean/status/1916541851328544883
https://x.com/FeinbergVlad/status/1915848609775685694