
編輯:KingHZ
自迴歸模型,首次生成2048×2048分辨率圖像!來自Meta、西北大學、新加坡國立大學等機構的研究人員,專門為多模態大語言模型(MLLMs)設計的TokenShuffle,顯著減少了計算中的視覺Token數量,提升效率並支持高分辨率圖像合成。
自迴歸模型的新突破:首次生成2048×2048分辨率圖像!
來自Meta、西北大學、新加坡國立大學等機構的研究人員,提出了TokenShuffle,為多模態大語言模型(MLLMs)設計的即插即用操作,顯著減少了計算中的視覺token數量,提高效率並促進高分辨率圖像合成。

圖1:採用新技術的27億參數自迴歸模型生成的高分辨率圖像
除了實現超高分辨率圖像生成外,生成質量也非常出色。
基於27億參數的Llama模型,新方法顯著超越同類自迴歸模型,甚至優於強擴散模型:
在GenEval基準測試中,獲得0.62的綜合得分,
在GenAI-Bench上,取得0.77的VQAScore,創造了新的技術標杆。
此外,大規模人類評估,也驗證了該方法的有效性。

與傳統方法逐個學習和生成每個視覺token不同,新方法在局部窗口內按順序處理和生成一組token,如圖2所示。
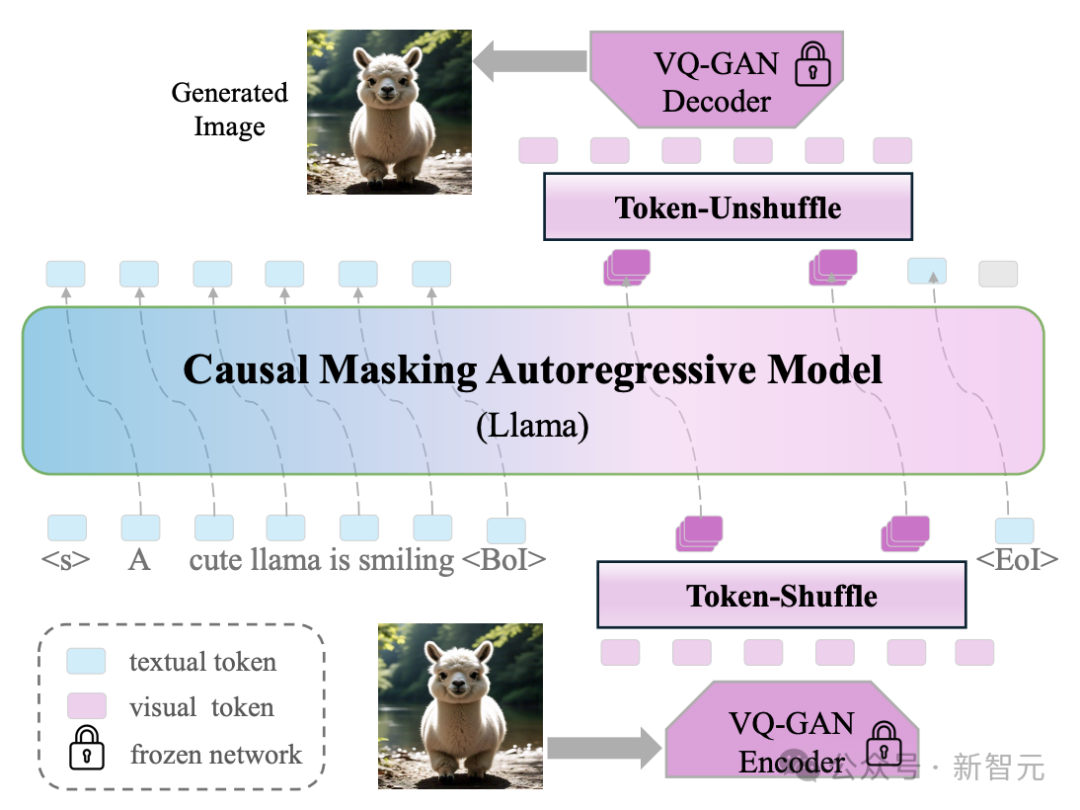
圖2:Token-Shuffle流程
Token-Shuffle包括:
token-shuffle操作,用於在Transformer輸入階段合併局部空間內的視覺token,
以及token-unshuffle操作,用於在推理階段還原視覺token。
該方法顯著減少了計算中所需的視覺token數量,同時保持了高質量的生成效果。
而且,Token-Shuffle展現的效能與效率,揭示了其在賦能多模態大語言模型(MLLMs)實現高分辨率、高保真圖像生成方面的巨大潛力,為超越基於擴散的方法開闢了新路徑。
GPT-4o沒說的祕密:自迴歸圖像生成
在語言生成領域,自迴歸(Autoregression)模型稱霸多日。
在圖像合成,自迴歸的應用雖日益增多,但普遍被認為遜色於擴散模型。
這一侷限主要源於AR模型需要處理大量圖像token,嚴重製約了訓練/推理效率以及圖像分辨率。
比如,基於自迴歸技術的GPT-4o生圖,讓OpenAI的GPU都「融化」了。
但遺憾的是,OpenAI並沒有公開背後的技術原理。

GPT-4o生成的第一視角機器人打字圖
這次,來自Meta等機構的研究者,發現在多模態大語言模型(MLLMs)中,視覺詞表存在維度冗餘:視覺編碼器輸出的低維視覺特徵,被直接映射到高維語言詞表空間。
研究者提出了一種簡單而新穎的Transformer圖像token壓縮方法:Token-Shuffle。
他們設計了兩項關鍵操作:
token混洗(token-shuffle):沿通道維度合併空間局部token,用來減少輸入token數;
token解混(token-unshuffle):在Transformer塊後解構推斷token,用來恢復輸出空間結構。
在輸入準備階段,通過一個MLP模塊將空間上相鄰的token進行融合,形成一個壓縮後的token,同時保留局部的關鍵信息。
對於打亂窗口大小為s的情況,token數量會按s的平方減少,從而大幅降低Transformer的運算量。
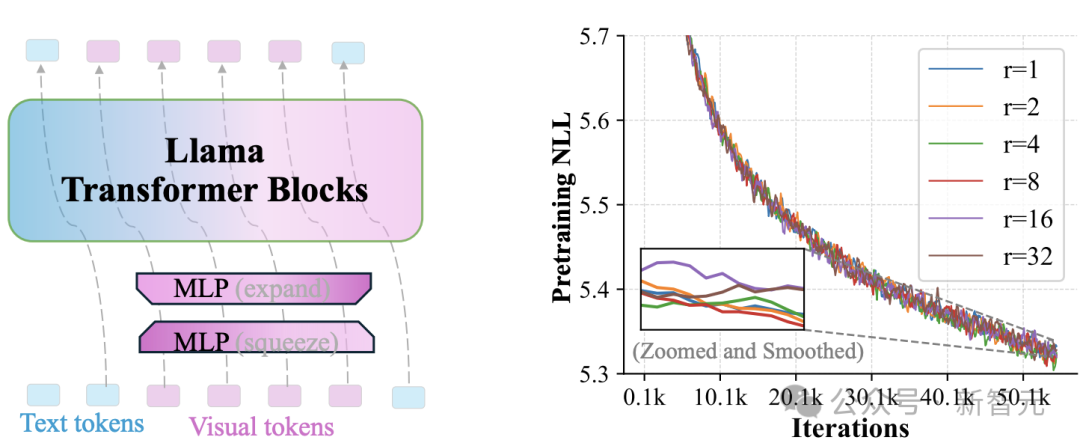
圖3:視覺詞彙維度冗餘的示意圖。左側:通過兩個MLP操作將視覺token的秩降低r倍。右側:不同r值下的預訓練損失(對數刻度困惑度)
在經過Transformer層處理後,token-unshuffle操作重新還原出原本的空間排列過程。這一階段同樣藉助了輕量級的MLP模塊。
本質上,新方法在訓練和推理過程中並未真正減少序列長度,而是在Transformer計算過程中,有效減少了token數量,從而加速計算。
圖4直觀地展示了新方法在效率上的提升。
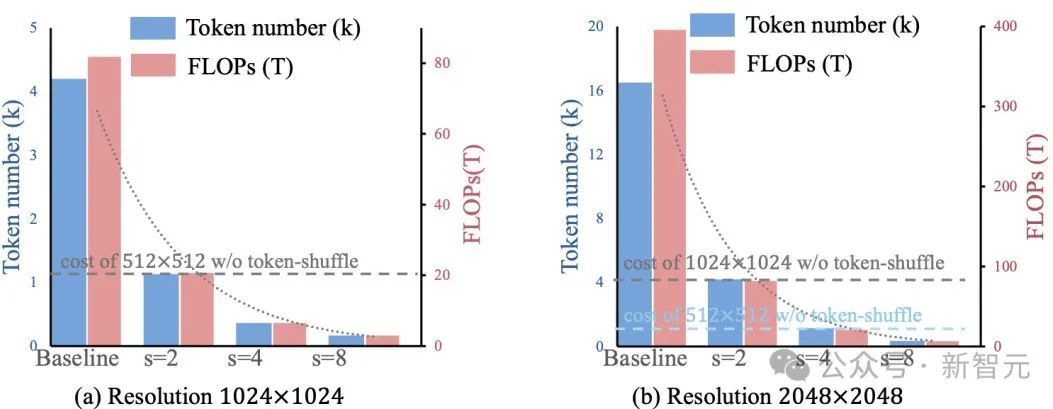
圖4:Token-Shuffle能夠實現計算效率的二次提升
通過在Transformer計算期間壓縮token序列,Token-Shuffle實現了高效的高分辨率圖像生成,包括支持2048×2048分辨率的圖像。
重要的是,這種方法無需對Transformer架構本身進行修改,也不引入輔助損失函數或需要額外預訓練的編碼器。
此外,該方法還集成了一個針對自迴歸生成專門調整的無分類器引導(Classifier-Free Guidance,CFG)調度器。
不同於傳統的固定引導強度,新的CFG調度器在推理過程中逐步調整引導力度,減少早期token生成的僞影問題,並進一步提升文本與圖像的對齊效果。
研究者探索了幾種CFG調度策略,相關結果展示在圖5中。
根據視覺質量和人類評估的反饋,默認採用「半線性」(half-linear)調度器,以獲得更好的生成效果。

圖5:不同CFG調度器的比較,CFG尺度從1單調增加到7.5
右側結果顯示,相較於在所有視覺token上使用固定7.5的CFG值,採用CFG調度器能夠同時提升圖像的美學質量和文本對齊效果。

不同無分類器引導(CFG)尺度下的生成圖像示例
自迴歸的歷史性突破
該方法通過與文本提示聯合訓練,無需額外預訓練文本編碼器,就能讓MLLMs在下一個token預測框架下,支持超高分辨率圖像合成,同時保持高效訓練推理。
這是自迴歸模型首次實現2048×2048分辨率的文生圖。
在GenAI基準測試中,27億參數Llama模型在困難提示下取得0.77綜合得分,較AR模型LlamaGen提升0.18,超越擴散模型LDM達0.15。
大規模人工評估也證實新方法在文本對齊度、視覺缺陷率和美學質量上的全面優勢。
在MLLMs高效生成高分辨率圖像領域,Token-Shuffle有望成為基準設計方案。
消融實驗等更多內容和細節,參閱原論文。

模型訓練:3步曲
實驗使用2.7B Llama模型,維度為3072,由20個自迴歸Transformer模塊組成。
模型的預訓練被分為3個階段,從低分辨率到高分辨率圖像生成。
首先,研究者使用512×512分辨率的圖像進行訓練,在此階段不使用Token-Shuffle操作,因為此時視覺token的數量並不大。在這一階段,他們訓練了約50億個token,使用4K的序列長度、512的全局批量大小和總共211K步。
接下來,研究者將圖像分辨率提升到1024×1024,並引入Token-Shuffle操作,減少視覺token數量,提高計算效率。在這一階段,他們將訓練token數量擴展到2TB。
最後,研究者使用之前訓練的checkpoint,將分辨率進一步提升至2048×2048,訓練約300億個token,初始學習率設為4e−5。
他們引入了z-loss,用於穩定高分辨率圖像生成的訓練。
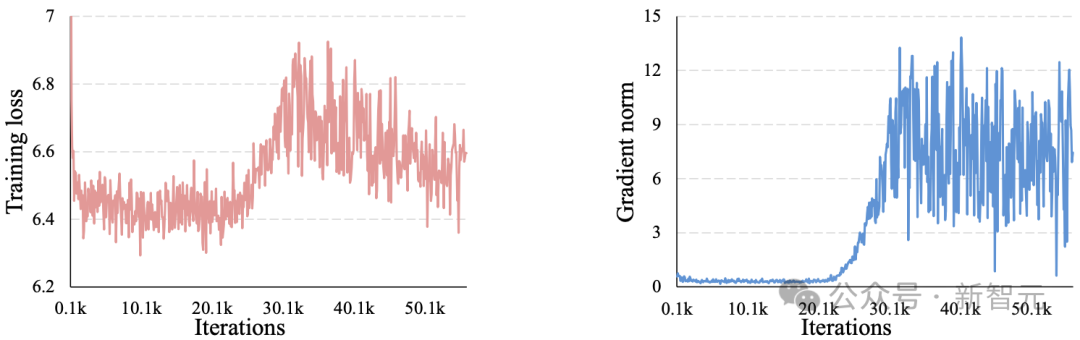
原文圖11:在2048×2048分辨率下訓練時的平均損失(左)和梯度範數(右)。在大約20K次迭代後出現訓練不穩定現象
在不同階段,研究者對所有模型進行了微調,學習率為4e−6,使用1500張精選的高美學質量圖像進行展示。
默認情況下,除非另有說明,可視化和評估是基於1024×1024分辨率和2大小的token-shuffle窗口的微調結果。
量化評估:又快又好
表1中的結果突顯了Token-Shuffle的強大性能。
與其他自迴歸模型相比,新方法在「基本」(basic)提示上整體得分超越LlamaGen 0.14分,在「高難度」(hard)提示上超越0.18分。
與擴散基準相比,新方法在「高難度」提示上超越DALL-E 3 0.7分。
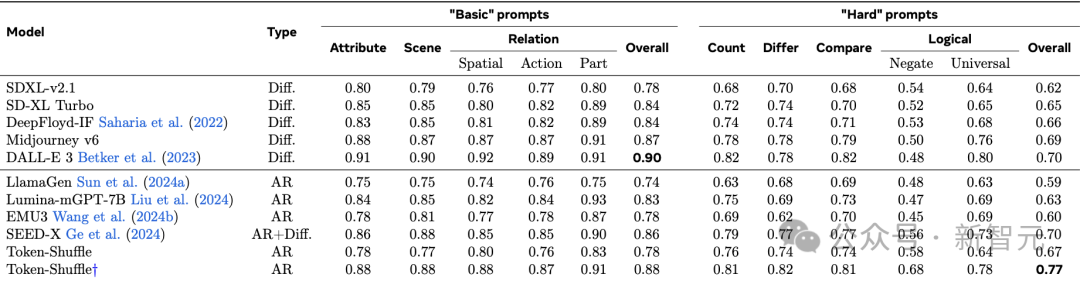
表1:在GenAI-Bench上的圖像生成VQAScore評估。「†」表示圖像是通過Llama3重寫提示生成的,保證訓練與推理的一致性
除了表1中報告的VQAScore結果外,研究者還進行了額外的自動評估GenEval,並在表2中報告了詳細的評估結果。
實驗結果表明,除了高分辨率外,Token-Shuffle作為一個純自迴歸模型,能夠呈現出令人滿意的生成質量。
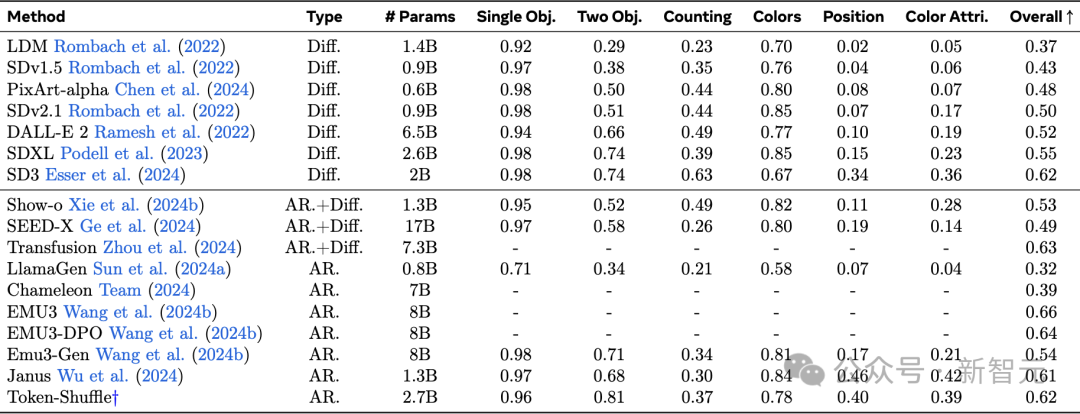
表2:在GenEval基準測試上的評估。
人類評估
儘管自動化評估指標提供了無偏的評估,但最近的研究所指出它們可能並不能完全捕捉到人類偏好。
為此,研究者還在GenAI-Bench提示集上進行了大規模的人類評估,將新模型Token-Shuffle與LlamaGen、LuminamGPT和LDM進行了比較,分別代表了自迴歸模型、MLLM和擴散模型。
在人類評估中,重點關注三個關鍵指標:
文本對齊,評估圖像與文本提示的匹配準確度;
視覺缺陷,檢查邏輯一致性,避免出現不完整的身體或多餘的肢體等問題;
視覺外觀,評估圖像的美學質量。

存在視覺缺陷與結構錯誤的生成圖像示例(紅色圓圈標記處)
圖6展示了結果,新模型在所有評估方面始終優於基於自迴歸的模型LlamaGen和LuminamGPT。
這表明,即使在大幅減少token數量以提高效率的情況下,Token-Shuffle也能有效地保留美學細節,並且能夠緊密遵循文本引導,前提是進行了充分的訓練。
在生成結果(無論是視覺外觀還是文本對齊)上,研究者展示了基於自迴歸的多模態大語言模型(AR-based MLLMs)能夠與擴散模型相媲美或更勝一籌。
然而,研究者觀察到,Token-Shuffle在視覺缺陷方面略遜於LDM。
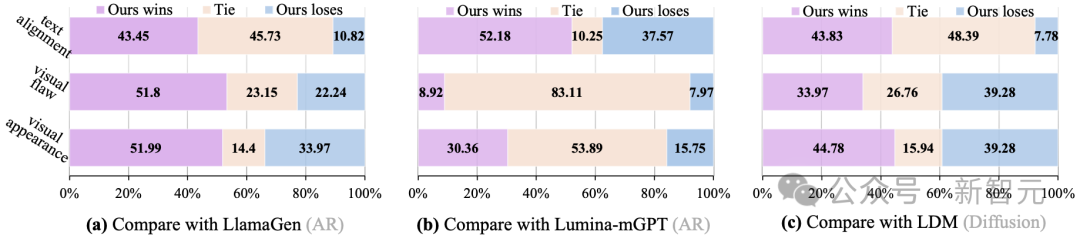
圖6:人類評估結果|在文本對齊、視覺缺陷和視覺外觀方面等方面,比較了Token-Shuffle與無文本的自迴歸模型LlamaGen、帶文本的自迴歸模型Lumina-mGPT以及基於擴散的模型LDM的表現
可視化示例
研究者將Token-Shuffle與其他模型進行了視覺效果對比,包括兩種基於擴散的模型LDM和Pixart-LCM,以及一種自迴歸模型LlamaGen。
圖7展示了可視化例子。
雖然所有模型的生成效果都不錯,但Token-Shuffle在文本對齊方面表現得更加出色。
與自迴歸模型LlamaGen相比,Token-Shuffle在相同推理開銷下實現了更高的分辨率,帶來了更好的視覺質量和文本對齊效果。
與擴散模型相比,自迴歸模型Token-Shuffle在生成性能上表現出競爭力,同時還能支持高分辨率輸出。

圖7:與其他開源的基於擴散模型和基於自迴歸模型的視覺效果對比
一作簡介
馬旭(Xu Ma)

他是美國東北大學工程學院的博士研究生。
在此之前,他在美國德克薩斯大學北部分校計算機科學與工程系工作了兩年。
在南京林業大學信息科學與技術學院, 他獲得了學士和碩士學位。
他的研究興趣包括:模型效率、多模態大語言模型(LLM)、生成式人工智能(Generative AI)。
在博士學習期間,他獲得了一些獎項,包括ICME'20最佳學生論文獎、SEC'19最佳論文獎、NeurIPS'22傑出審稿人獎和CVPR'23傑出審稿人獎。