作者 | ZeR0
編輯 | 漠影
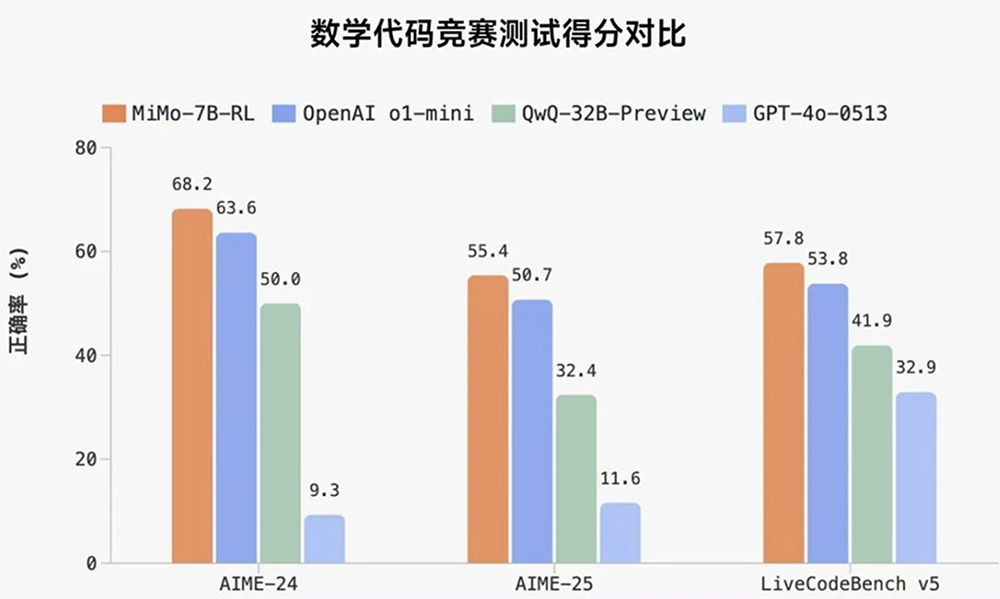
智東西4月30日報道,今日,小米開源其首個推理大模型Xiaomi MiMo。其中經強化學習訓練形成的MiMo-7B-RL,在數學推理(AIME 24-25)和代碼競賽(LiveCodeBench v5)公開測評集上,僅用7B參數量,得分超過了OpenAI的閉源推理模型o1-mini和阿里Qwen開源推理模型QwQ-32B-Preview。
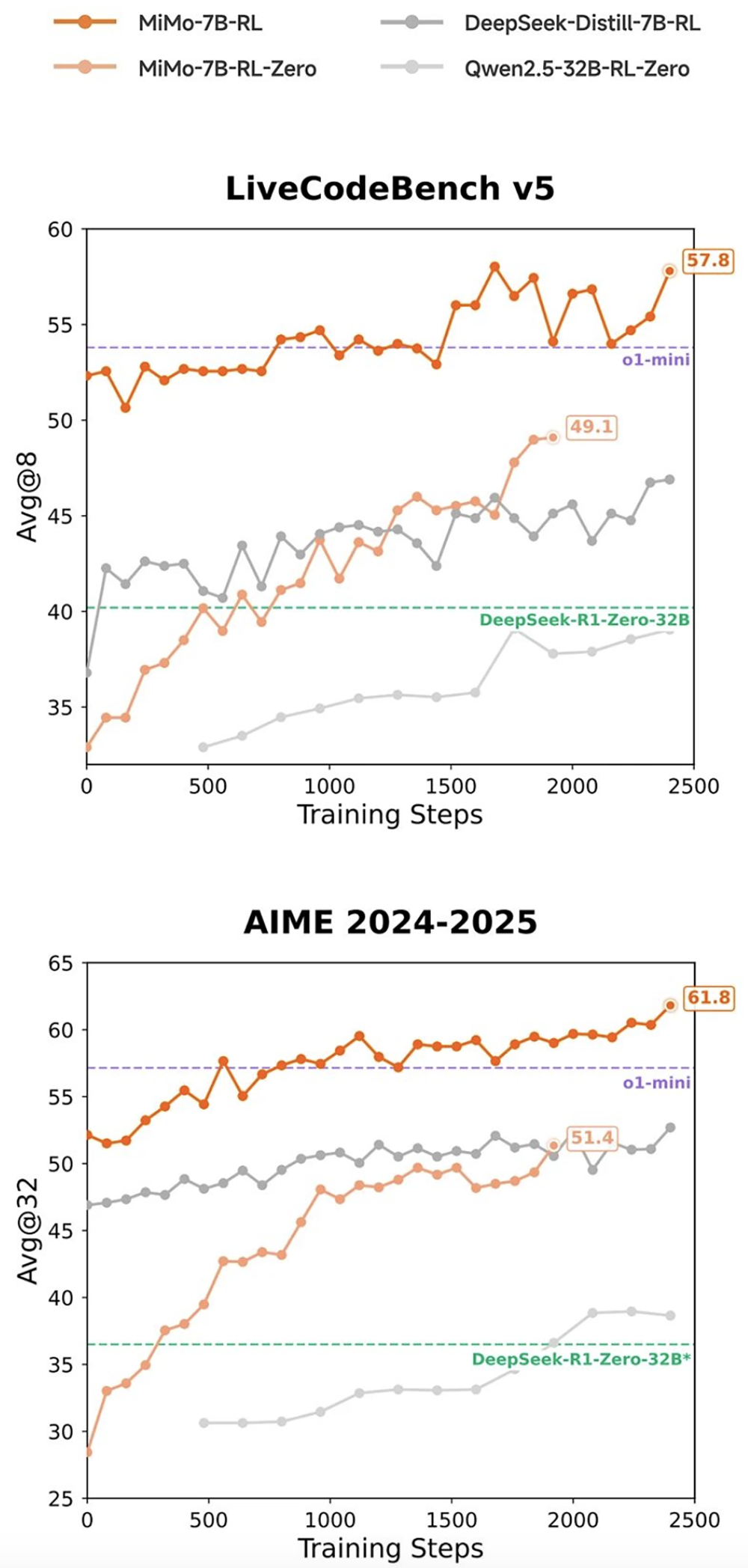
在相同強化學習訓練數據情況下,MiMo-7B-RL在數學和代碼推理任務上均表現出色,分數超過DeepSeek-R1-Distill-7B和Qwen2.5-32B。
MiMo是新成立不久的小米大模型Core團隊的初步嘗試,4款MiMo-7B模型(基礎模型、SFT模型、基於基礎模型訓練的強化學習模型、基於SFT模型訓練的強化學習模型)均開源至Hugging Face。代碼庫採用Apache2.0許可證授權。

開源地址:https://huggingface.co/XiaomiMiMo
小米大模型Core團隊已公開MiMo的26頁技術報告。

技術報告地址:https://github.com/XiaomiMiMo/MiMo/blob/main/MiMo-7B-Technical-Report.pdf
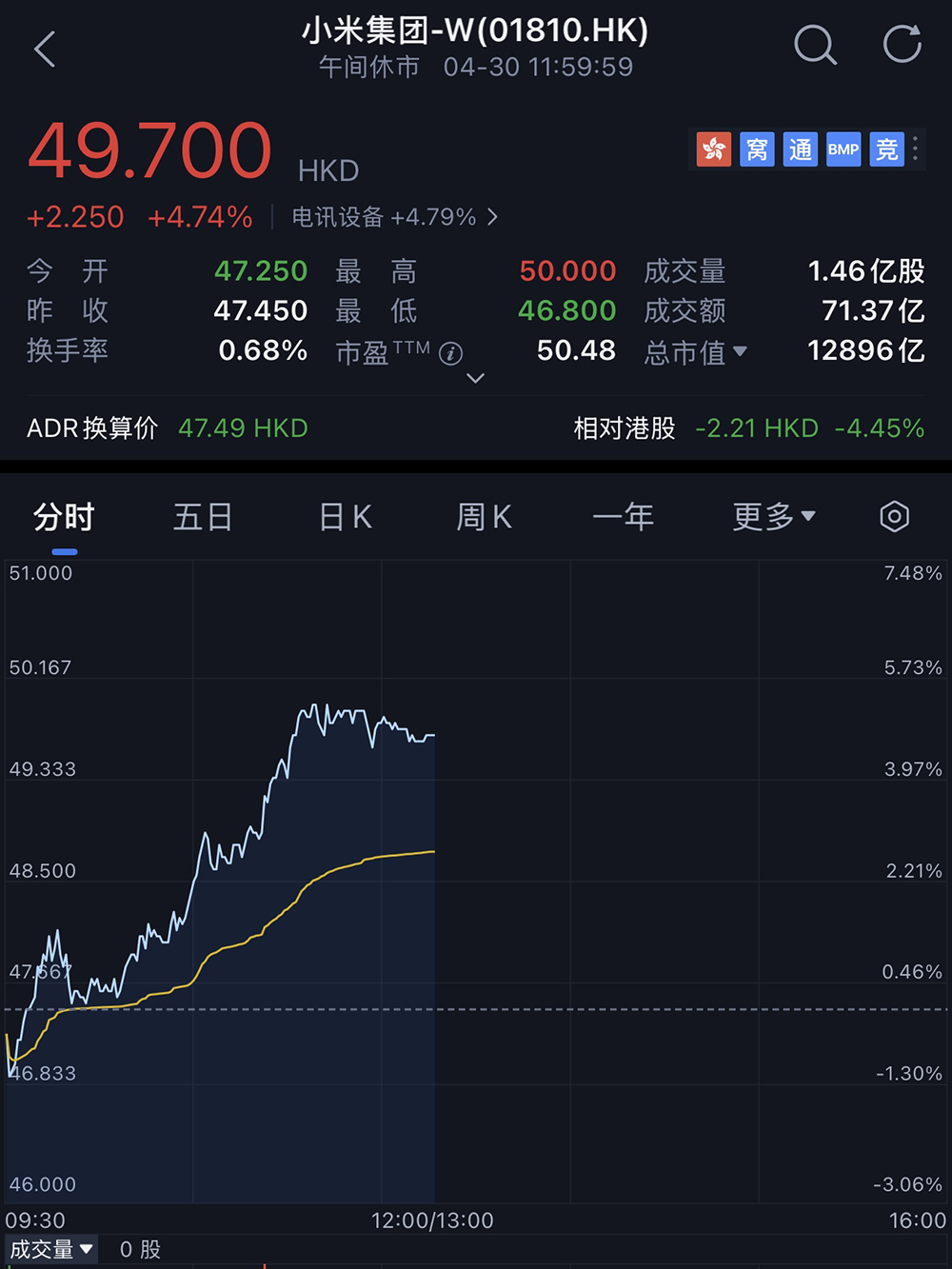
受此消息提振,截至午間休市,小米集團今日股價上漲4.74%,總市值1.29萬億港元(約合人民幣1.21萬億元)。
一、預訓練+後訓練,聯動提升推理能力
MiMo系列模型從零開始訓練,其推理能力的提升由預訓練和後訓練階段中數據和算法等多層面的創新聯合驅動,包括:
預訓練:核心是讓模型見過更多推理模式
數據:着重挖掘富推理語料,併合成約200B tokens推理數據。

訓練:採用三階段數據混合策略,逐步提升訓練難度,MiMo-7B-Base在約25T tokens上進行預訓練;受DeepSeek-V3啓發,將多token預測作為額外的訓練目標,以增強模型性能並加速推理。
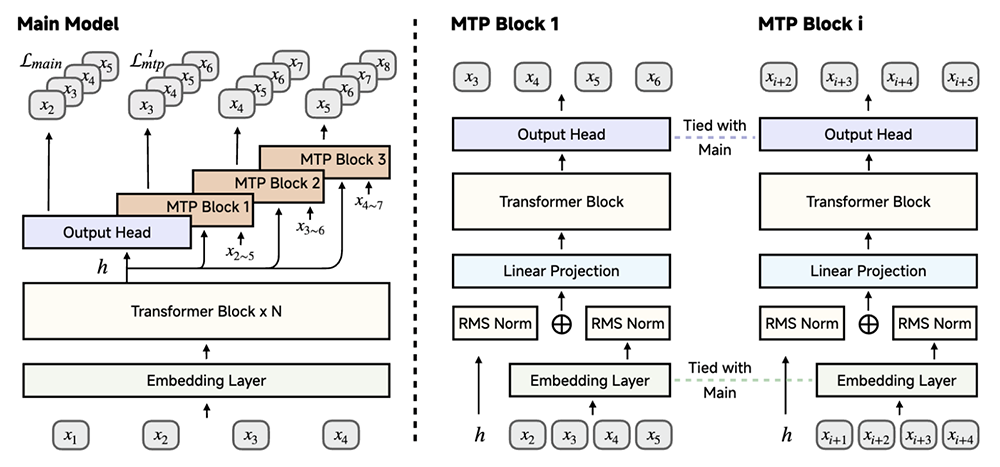
▲使用MiMo-7B實現多token預測:在預訓練期間使用單個MTP層,推理階段可使用多個MTP層以獲得額外的加速
後訓練:核心是高效穩定的強化學習算法和框架
算法:提出Test Difficulty Driven Reward來緩解困難算法問題中的獎勵稀疏問題,並引入Easy Data Re-Sampling 策略,以穩定強化學習訓練。
數據:精選了13萬道數學和代碼題作為強化學習訓練數據,可供基於規則的驗證器進行驗證。每道題都經過仔細的清理和難度評估,以確保質量。僅採用基於規則的準確率獎勵機制,以避免潛在的獎勵黑客攻擊。
框架:設計了Seamless Rollout系統,集成了連續部署、異步獎勵計算和提前終止功能,以最大限度地減少GPU空閒時間,使得強化學習訓練加速2.29倍,驗證加速1.96倍。
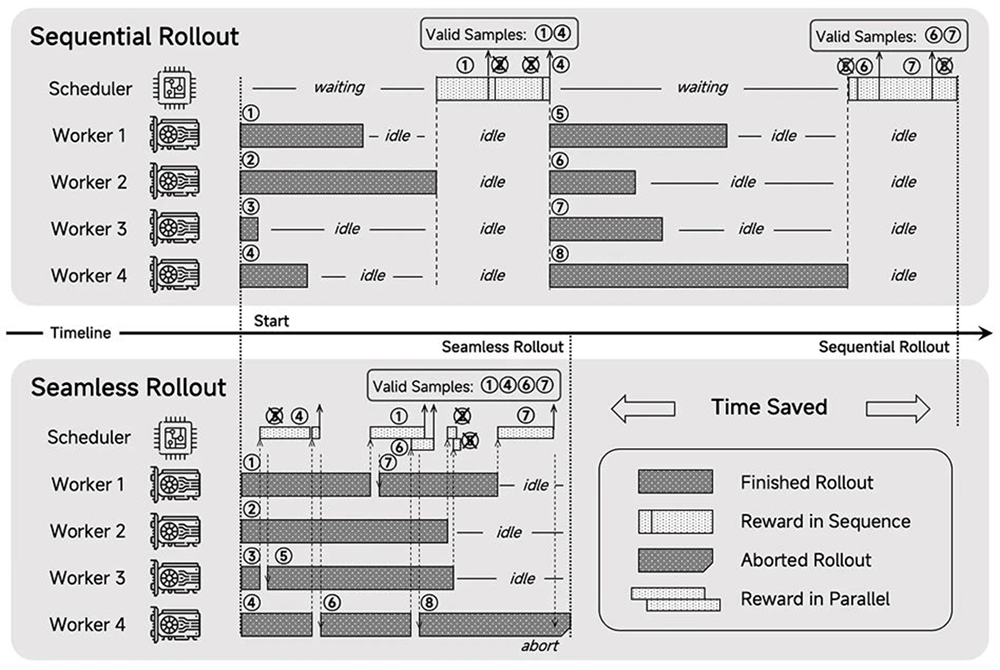
▲MiMo-7B-RL Seamless Rollout引擎概覽
二、7B強化學習模型,性能超過阿里32B模型和OpenAI o1-mini
小米大模型Core團隊將MiMo-7B-Base與Llama-3.1-8B、Gemma-2-9B、Qwen2.5-7B等規模相當的開源基礎模型進行了比較,所有模型評估都共享相同的評估設定。
結果如圖所示,MiMo-7B-Base在所有基準和評估的k值取得了高於其他對比模型的pass@k分數。隨着k增加,MiMo-7B-Base與其他模型的分數差距穩步拉大,特別是在LiveCodeBench上。
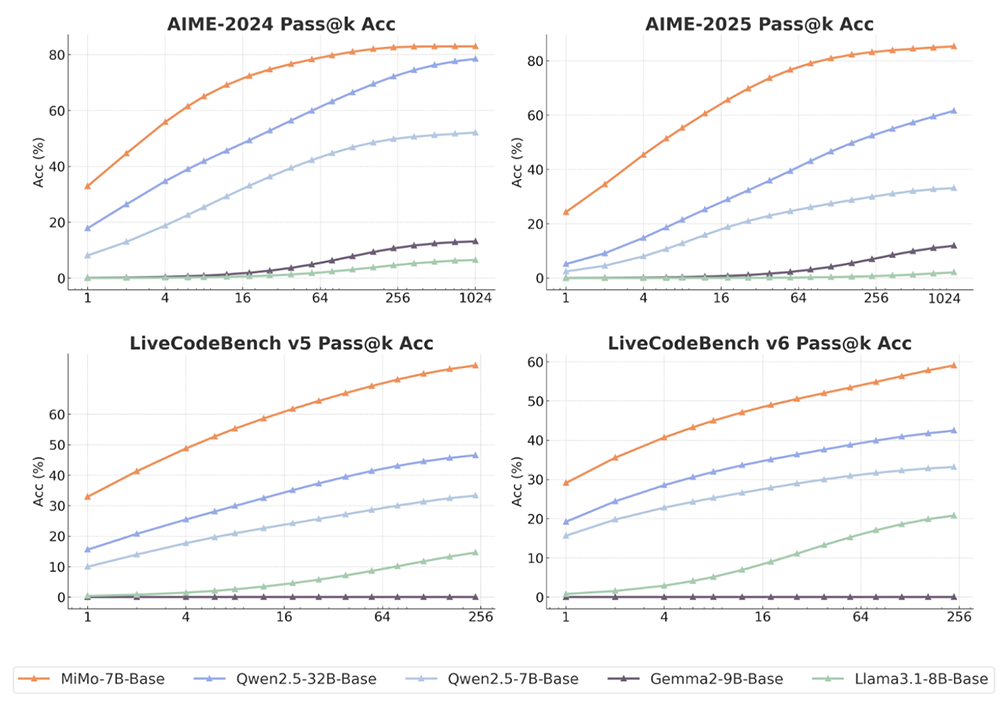
在評估語言推理模型的BBH基準測試上,MiMo-7B-Base的分數為75.2分,比Qwen2.5-7B高出近5分。SuperGPQA基準測試結果展示出MiMo-7B-Base在解決研究生水平問題方面的出色表現。在閱讀理解基準測試DROP上,該模型的表現優於其他對比模型。
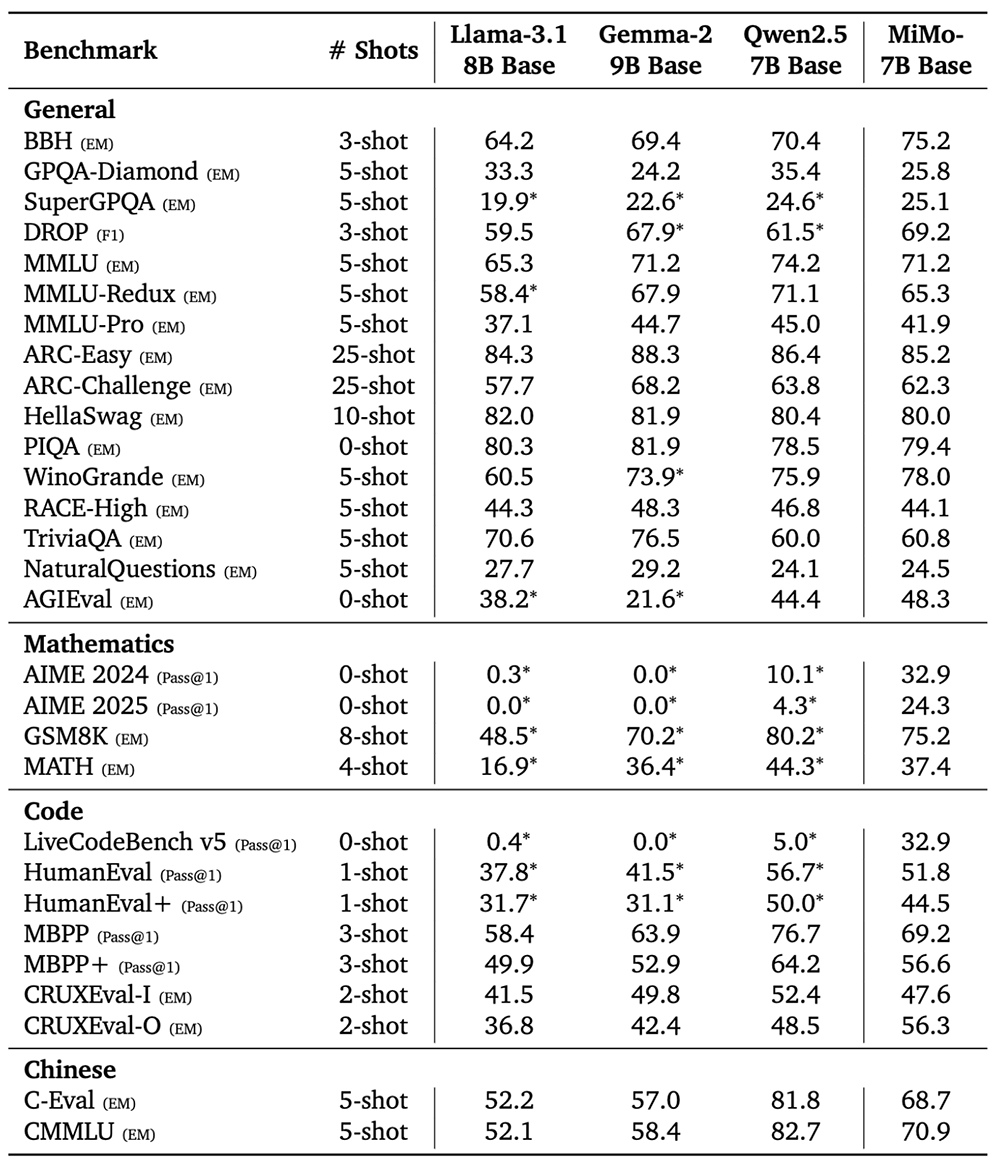
在代碼和數學推理任務中,MiMo-7B-Base的多項分數超過Llama-3.1-8B、Gemma-2-9B。
MiMo-7B-Base在支持的32K上下文長度內實現了近乎完美的NIAH檢索性能,並在需要長上下文推理的任務中表現出色,多數情況下分數都超過了Qwen2.5-7B。這些結果驗證了其在預訓練期間將多樣化數據與高質量推理模式相結合的策略的有效性。
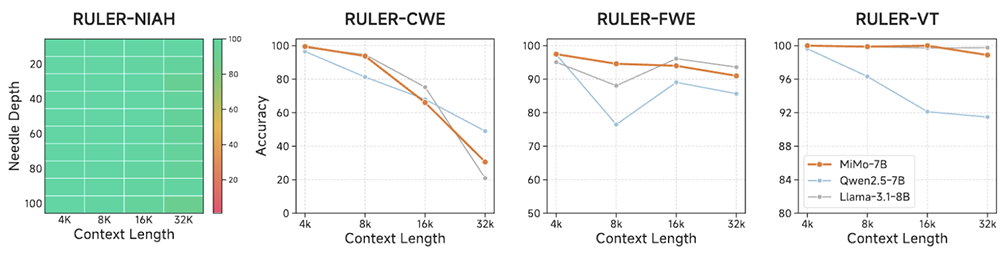
▲RULER上的長上下文理解結果
MiMo-7B-RL在多項通用基準測試接近或超過擁有32B參數規模的QwQ-32B Preview模型,數學和代碼性能更是全面領先。
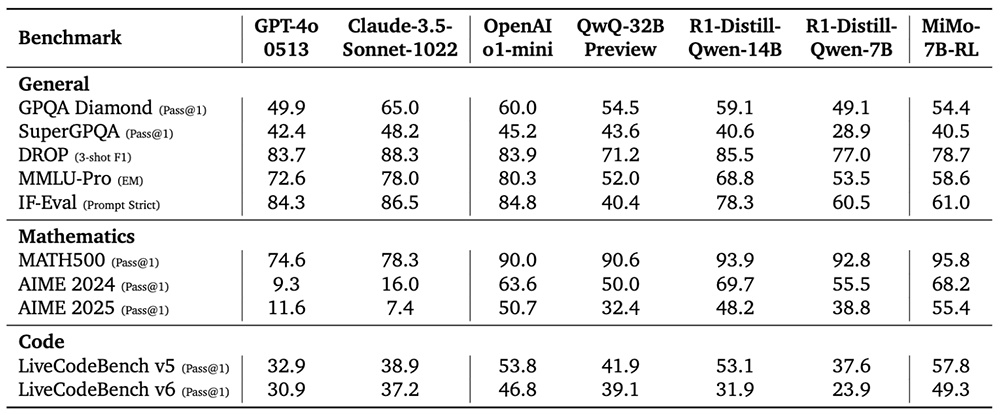
在數學基準測試AIME 2025測試、代碼基準測試LiveCodeBench v6中,MiMo-7B-RL的得分均超過OpenAI o1-mini。
MiMo-7B系列4款大模型的多項數學和代碼測試對比如下:
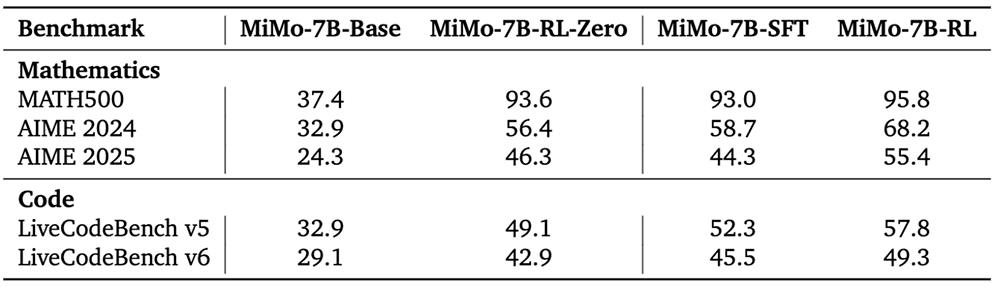
結語:今年大模型的三大熱點,MiMo一舉覆蓋
今年,在DeepSeek爆紅後,開源和推理迅速成為大模型領域的熱門風向。如今低調許久的小米也正式加入這一戰局。
作為國產手機頭部企業之一,小米這次開源的四款模型參數規模只有7B,小到可以滿足在端側設備上本地運行的需求,貼合了大模型的另一大趨勢——從卷參數規模轉向追求經濟高效。
通過在預訓練和後訓練過程中的多項創新聯動,MiMo-7B-Base在數學、代碼和通用任務上都展現了出色的推理能力。這項研究可以為開發更強大的推理模型提供參考。