
李彥宏點名批評DeepSeek幻覺高。這回,他真的沒錯。但大模型的幻覺問題,又遠非錯與對那麼簡單。
DeepSeek-R1作為今年年初的新晉國產開源大模型,以強大的推理能力和更懂國人的文筆,在蘋果美區App免費下載排行榜上力壓ChatGPT一頭,甚至一度成為「AI」的代言詞。
然而,自從R1席捲全網後,關於它經常「胡說八道」的批評就不絕於耳,比如它實在太能編了,讓人真真假假分不清。
除了用戶端之外,李彥宏及其代表的大廠們也「苦」DeepSeek已久:一方面,大廠不得不依賴DeepSeek的潑天流量導入自身門戶入口;另一方面,儘管投入大量人力物力研發深度推理模型,其成果卻難以突破用戶心智。
在2025百度AI開發者大會的開幕上,李彥宏直接點出全民AI大模型 DeepSeek-R1 的痛點:「只支持單一模態、幻覺率較高、又慢又貴」。一番犀利評論,再度引發了各界對DeepSeek-R1以及大模型「幻覺」的評議。
但出現強烈幻覺的並不止DeepSeek一家,OpenAI在其內部測試中發現:o3/o4-mini雖然全面替換了o1系列,但是幻覺現象越來越強了;國內第一個混合推理模型——阿里通義的Qwen3也在X上被網友指出幻覺現象仍舊大量存在。
關於幻覺的解釋有很多,尤其是當推理模型問世後,大家都認為推理模型的思考模式和模型性能攀升後,幻覺就會被消滅,但事實證明:幻覺的生存能力太強了,用戶們還是常常被「LLM生編硬造,邏輯閉環的幻覺操作」看呆。
不過,另有一說:大模型的幻覺也算是創作力的副產品,並不完全是桎梏。
今天我們重新講講大模型幻覺,看看AI圈子最大的黑箱問題到底解決了沒有,解決進度到哪了?
01
李彥宏對DeepSeek-R1的批評確實有據可循。
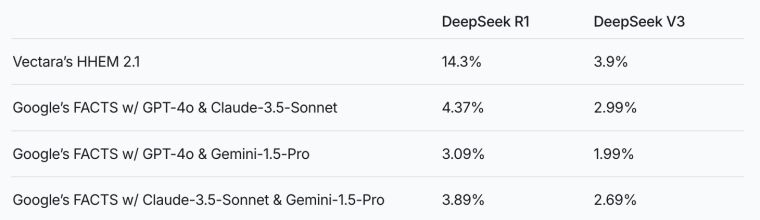
AI數據服務公司Vectara的一項HHEM幻覺評估中,DeepSeek-R1的幻覺率高達14.3%,而其前代基礎模型DeepSeek-V3僅為3.9%,R1的幻覺甚至要比V3的幻覺高出4倍。阿里通義的QwQ-32B-Preview的幻覺率則高達16.1%。
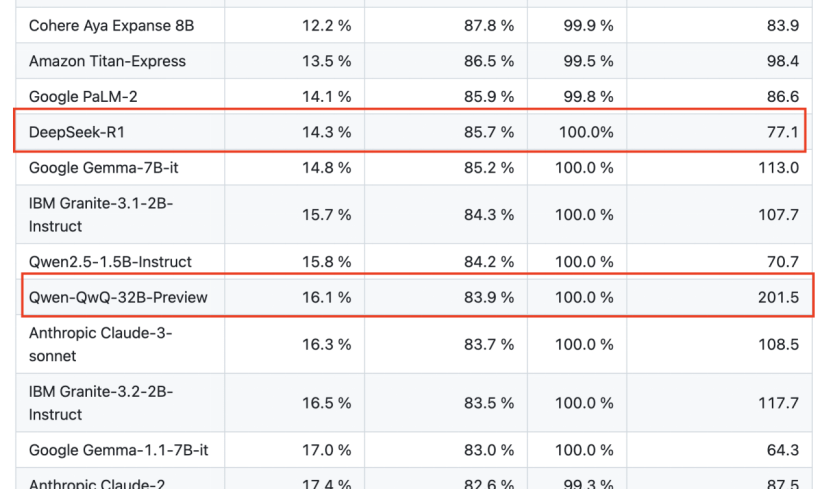
更值得注意的是,除了DeepSeek-R1和Qwen系列之外,縱觀業內,幾乎所有最先進的大模型都遭到了幻覺問題的挑戰。一般來說,當新模型出現,幻覺程度就會低於其前身模型,但是這一常理性的現象並不在推理模型上適用。
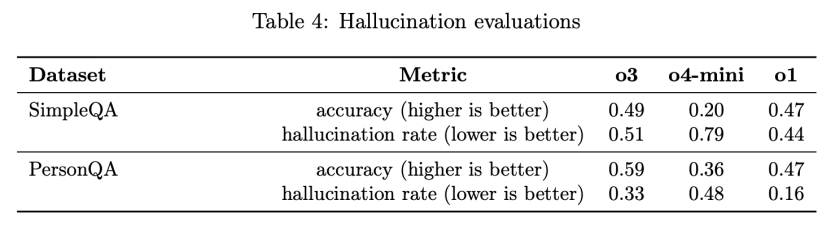
OpenAI的內部評估系統卡里提供了一個具有代表性的例子:他們設計了一項名為PersonQA的基準測試,用於衡量模型回答人物信息問題的準確性。結果發現,o3在PersonQA上的幻覺率上升到了33%,幾乎是被全面替代的前代模型o1(16%)的兩倍。輕量版推理模型o4-mini的幻覺率高達48%。
在最新出爐的一版Vectara的幻覺測試中,馬斯克 xAI的Grok-3比Grok-2幻覺更嚴重,谷歌Gemini 2.0系列中強調深度推理的Flash-Thinking版本比標準版幻覺問題更突出。
當業界追求更強推理能力的大語言模型時,事實準確性與生成內容一致性幾乎無法「魚與熊掌兼得」。
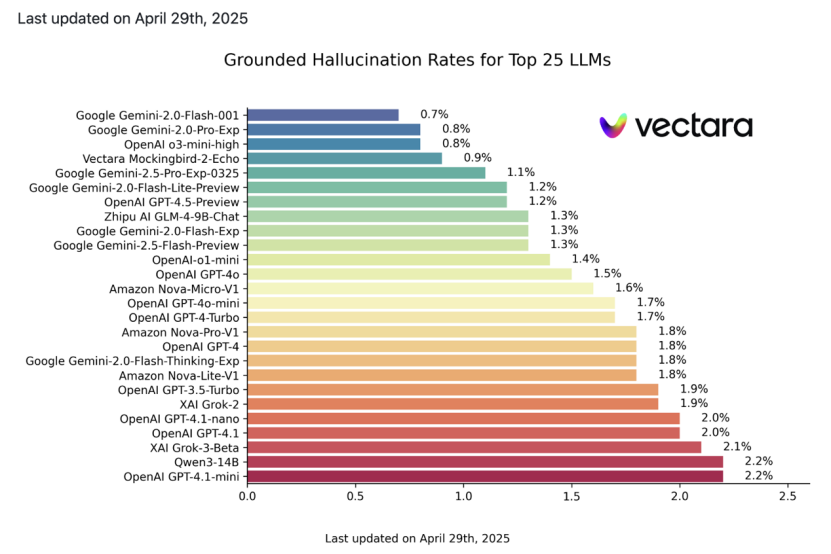
可見,「幻覺」是當下大模型領域的通病,而DeepSeek-R1正是該問題的顯著案例之一。
每當新模型發布時,大家往往先入為主:當推理模型出來後,模型能力大幅度提升,幻覺就會被逐漸消滅;相反,也有一種猜測,推理模型往往要比通用模型幻覺更強。但這些觀點其實全都是錯的。
比如 o1 相對於 4o 並沒有增加太多的幻覺,反過來也可以說,o1並沒有大幅度降低幻覺。
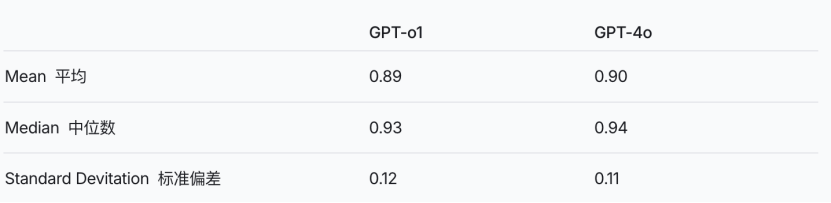
o3和o4-mini 幻覺的提升連OpenAI的研究人員在系統卡論文中也說道「仍需繼續研究」。可以說,在一定程度上,LLM的幻覺現象仍然是個黑盒,隨着模型的不斷發展,這層迷霧仍然籠罩在各大基礎模型廠商的上空。
廣義上,普遍認為像DeepSeek-R1這樣的推理模型往往喜歡多輪思考,放大幻覺。
推理模型和深度思考模型通常採用多輪推理或長鏈式思考策略,通過逐步分解問題、生成中間步驟,最終得出答案。這種設計本來是為了模擬人類複雜的邏輯推理過程。但是,多輪思考也可能導致模型在每一步生成中引入微小的偏差或錯誤,這些偏差在後續步驟中被放大,促成多米諾骨牌效應的出現。
為什麼大家再談LLM的幻覺?除了百度等廠商為了應對DeepSeek的競爭,破除唯「DeepSeek論」之外,還有一個原因:普通用戶們在實際體驗中越來越感到恐懼了。
這主要是因為大模型通過大規模訓練數據,已經能夠構建高度自洽、邏輯幾乎閉環的知識體系,模型對語義上下文的理解和生成能力越來越強,幻覺卻也越來越真實了。甚至產生了一種「性能與幻覺齊飛」的詭異現象。
可以說,幻覺已經事實上不再是評判模型性能的主要標準了。
大家在日常使用中,肯定都有過這樣的體驗:AI 杜撰不存在的信源、生成看似真實的學術引用、「現場」構造僞造的網頁鏈接,甚至在長長的思維鏈裏不斷「故意迎合」用戶,諂媚用戶。
如果只是普通的日常使用場景,幻覺現象的隱蔽性並不會降低用戶信任。但是,當大模型商業化後,涉及專業領域或複雜問題時,這種不確定性就會引發用戶對可靠性的質疑,甚至產生對AI本身的恐懼感。
02
李彥宏2024年曾說,過去24個月裏AI行業經歷的最大變革之一是大模型基本消除了「幻覺」問題。這一說法一時讓各路網友覺得他出現了幻覺。
確實,某些領域(例如文生圖、視頻等多模態輸出方面)隨着模型能力的提升,幻覺現象確實已經大幅降低了。
但是,儘管幻覺問題在這些受控場景下大幅改善,在生成長文本或複雜視覺場景時仍未解決。
最直觀的例子就是:每當各大廠商推出新一輪的深度思考模型時,都不得不再度老調重彈幻覺問題。可以說,幻覺問題已經被研究了好幾年了,但直到今天都沒有辦法找到一個極好的方式克服幻覺,arXiv上一篇一篇的論文砸向這個黑盒領域。
不過,技術開發者應對 AI 幻覺,也確實有一些手段。目前比較主流的方式還是檢索增強生成(RAG),這個方式有點老了但是管用,也是最廣的應用思路。

RAG,即在模型回答前先檢索資料。英偉達 CEO黃仁勳就強調,要讓AI減少幻覺,很簡單,「給每個回答加一道規則:先查證再作答」。 具體而言,模型接到問題後,像搜索引擎那樣查詢權威來源,然後依據檢索到的信息作答。如果發現引用的信息與已知事實不符,就丟棄該信息並繼續查找 。通過這種方式,模型不再僅憑參數記憶回答,而是有據可依。讓模型能夠引入最新的網頁/數據庫內容,在內部機制裏學會對不知道的事物說「我確實不知道」。
百度2024年發布的檢索增強的文生圖技術iRAG,就是為了解決文生圖中的幻覺問題,結合了自身的億級圖片資源庫,讓生成的圖片更真實、更貼合現實。
此外,一個更基本的方法是「嚴格控制訓練數據的質量」。
當然,全面的數據治理過於困難,因為互聯網語料過於複雜且知識隨時間變化,像是「弱智吧」的語料就極難正確過濾。
騰訊此前發布的混元深度思考模型T1,針對長思維鏈數據中的幻覺和邏輯錯誤,訓練了一個Critic批判模型來進行嚴格篩選。這種「雙重把關」策略——即模型先產出回答,然後再覈對其中的關鍵實體和事實,再決定是否輸出,也能在一定程度上降低幻覺率。
即使有上述手段的加持,要徹底根治幻覺仍充滿挑戰。OpenAI就在最新報告中坦承:「為什麼模型規模變大、推理能力增強後幻覺反而更多,我們目前也不完全清楚,還需要更多研究」。
03
幻覺,也並非全無益處。各大廠商正站在一個幻覺與創造力交匯的十字路口:幻覺並非純粹的缺陷,同樣也能帶來模型更佳的創造力。
大模型的幻覺一般分為:事實性幻覺和忠實性幻覺。當大模型回答的內容與用戶的指令或者上下文信息不一致時,可能就會出現所謂的「靈感」。 不管是違背輸入文本,還是違背客觀事實, 「幻覺」產生的部分往往是模型發揮想象的結果。
有個專業術語叫「外箱式創意」,指的是「跳出既有框架的創作力」 ,這正是大模型區別於檢索引擎的魅力所在。大家往往潛意識裏認為AI做的是低「創意密度「的任務,無法佔領諸如科幻文學這類的高創造力寫作。
然而,劉慈欣對此有話說。

前段時間,劉慈欣在一次採訪中說他曾拿自己所寫的長篇中的一章發給 DeepSeek,讓它在這個基礎上續寫。結果發現它寫出來的東西,甚至要比自己寫得好。這甚至讓他有了一種很大的失落感。
但是,劉慈欣本人仍喜愛DeepSeek:「為什麼呢?因為我想到,由於人腦的生物特性,有一些沒法衝破的認知極限,但 AI 卻有可能突破。如果它真的可以突破極限,那麼我甘心樂意被 AI 取代。當然,現在它還做不到。未來的路還很遙遠。」
OpenAI CEO奧特曼也曾提及AI的幻覺特性並非全然是壞事,在創作領域仍有積極意義。這也可能是未來LLM的一個方向。
面對幾乎成為大模型固有特性的幻覺現象,要低到什麼地步,我們纔可以接受?
這沒有固定的答案,而是依賴於應用場景。在需要精準性的高風險or涉及倫理的領域裏,LLM 的幻覺固有特性幾乎斷絕了商業空間。
從哲學上看,這反映了人類對技術的期望:AI應比人類更可靠。折射出人類對 LLM 的角色定位,如果將 AI 僅僅視作鋤頭而已,那麼AI幾乎永不可能達到這樣的標準。如果將 AI 視作天然具有幻覺特性的工具,接受「幻覺」是AI的固有特質,就要賦予AI區分虛構與現實的能力,讓它在需要的時候學會說「我不知道」。
或許我們也應該換種思路研究AI。