
新智元報道
編輯:英智
【新智元導讀】AI也會偷偷努力了?Letta和UC伯克利的研究者提出「睡眠時計算」技術,能讓LLM在空閒時間提前思考,大幅提升推理效率。
AI「睡覺」時也能思考了?
Letta和UC伯克利研究者提出了「睡眠時計算」(Sleep-time Compute)技術,旨在提高LLM推理效率,讓模型在空閒時間思考。

過去一年,推理模型可太火了。回答問題之前,它會先自己琢磨琢磨。
然而,測試時擴展計算存在明顯的弊端,會導致高延遲,推理成本也大幅增加。
睡眠時計算讓模型在空閒時也「動動腦筋」。
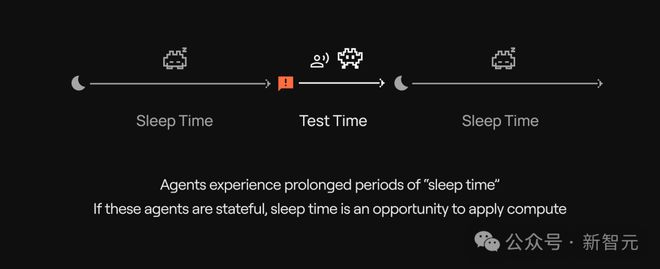
簡單來講,模型在沒有接收用戶查詢的空閒時間,提前分析和推理上下文信息。
通過預測用戶可能提出的問題,預先算出有用結果,這樣用戶提問時,模型就能更快、更高效地給出答案。
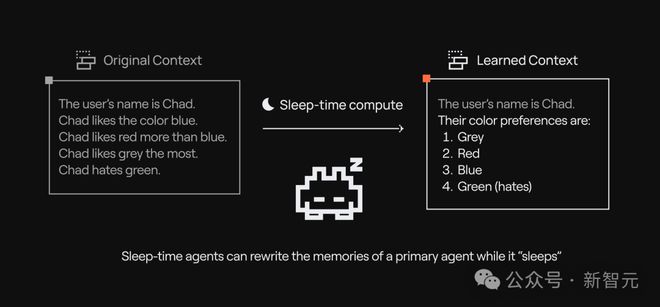
這項技術在保持準確性的同時,降低了推理成本,給AI系統提供了全新的方向。

論文鏈接:https://arxiv.org/abs/2504.13171
研究發現:
睡眠時計算
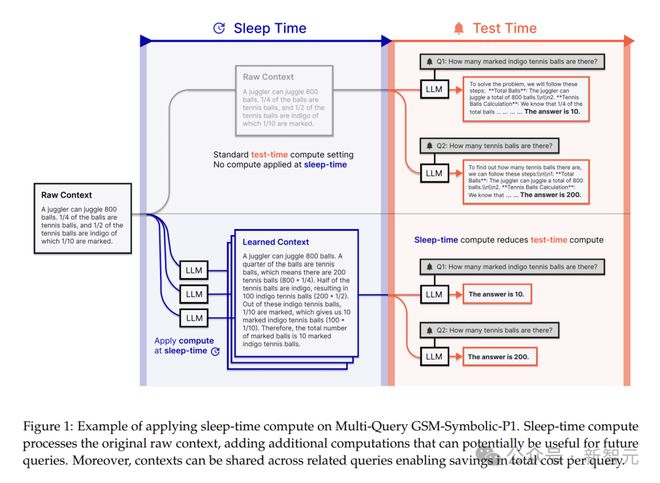
在標準的測試時計算中,用戶輸入提示(包含上下文c和查詢q),模型進行推理並輸出答案a,可表示為。
但在實際中,很多時候在q到來之前就已經有了c,此時模型通常處於空閒狀態。
睡眠時計算是利用這段空閒時間,讓模型僅基於上下文c進行推理,生成一個新的、更有利於回答查詢的上下文c',這個過程表示為。
在測試時,用c'代替c,模型通過給出答案。
由於提前做了很多準備工作,此時所需的測試時預算b會遠小於原來的B,大大減少了計算量。
打個比方,你是一個圖書管理員(模型),有人來問圖書館的藏書(上下文)。
以往,有人問了,纔去圖書館找答案,這樣效率很低。而現在,你可以在空閒時,先整理分類書籍,預測讀者可能會問的問題,並做好相應的筆記(預計算)。
這樣讀者提問時,就能根據筆記和整理好的書籍迅速回答。

實驗結果
為驗證睡眠時計算的有效性,研究人員進行了一系列實驗。
Stateful GSM-Symbolic是從GSM-Symbolic的P1和P2拆分而來,增加了問題的難度。
Stateful AIME則從2024年和2025年美國數學邀請賽題目中選了60個問題,同樣拆分成上下文和問題。
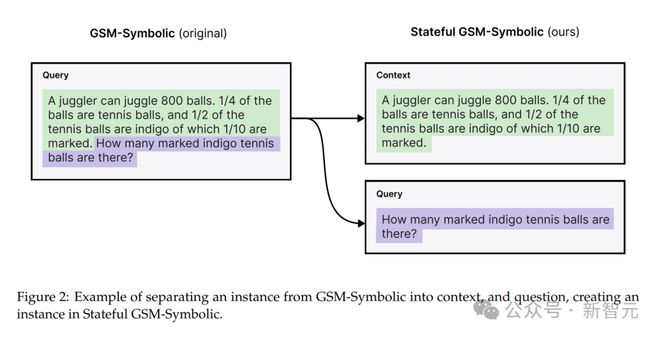
Multi-QueryGSM-Symbolic數據集是為了研究共享上下文的影響,每個上下文包含多個查詢。
在GSM-Symbolic數據集上,用GPT-4o-mini和GPT-4o進行實驗。在AIME數據集上,使用OpenAI的o1、o3-mini、Anthropic的Claude Sonnet 3.7 Extended Thinking以及Deepseek-R1等模型。
基線採用標準測試時計算,即測試時同時把上下文c和查詢q提供給模型。
改善帕累託邊界
睡眠時計算能否改變測試時計算與準確率之間的帕累託邊界?
在Stateful GSM-Symbolic和Stateful AIME中,睡眠時計算展現出了強大的優勢,它能將達到相同準確率所需的測試時計算量減少約5倍!
這意味着在資源有限時,用睡眠時計算可讓模型保證準確率的同時,大幅減少計算資源消耗。
從圖中可以看出,在低測試時預算下,睡眠時計算的性能遠超過基線。
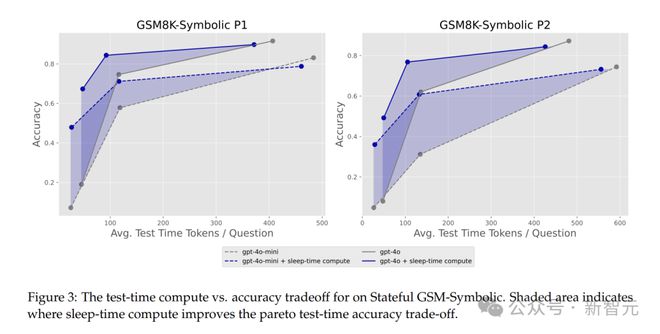
應用睡眠時計算後,測試時間和準確率有顯著的帕累託偏移。
擴展睡眠時計算
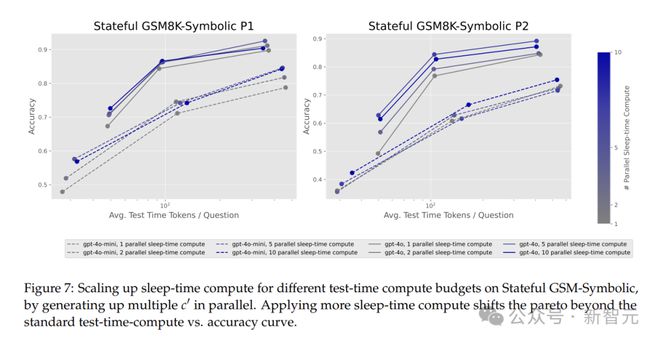
擴展睡眠時計算規模,能否進一步優化帕累託邊界?
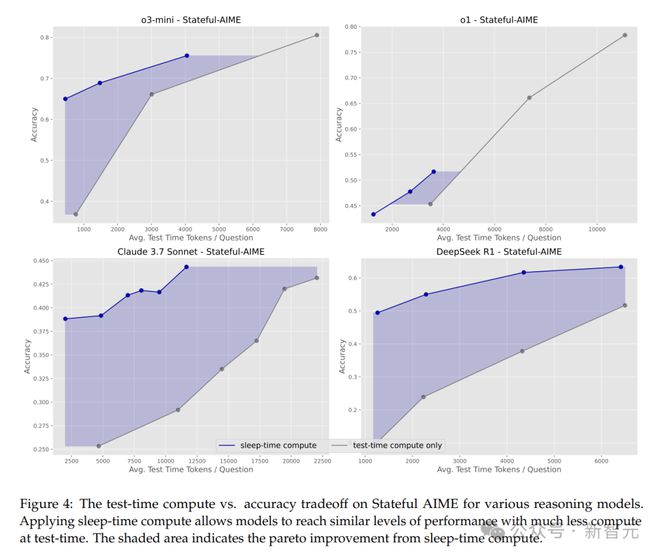
Stateful GSM-Symbolic任務中,擴展睡眠時計算會使帕累託曲線外移,相似的測試時間預算下,性能最高提升13%。
在Stateful AIME任務中,擴展睡眠時計算,性能提升高達18%。
這表明通過合理增加睡眠時的計算資源投入,可以進一步優化模型性能。
分攤睡眠時計算
當單個上下文對應多個關聯問題時,分攤測試時計算與睡眠時計算能否帶來總體token效率提升?
研究人員想了解如何在每個上下文都有多個查詢的設定中,應用睡眠時計算來改善推理的總成本。
Multi-Query GSM-Symbolic數據集中,當每個上下文有10個查詢時,通過分攤睡眠時計算的成本,每個查詢的平均成本降低2.5倍。
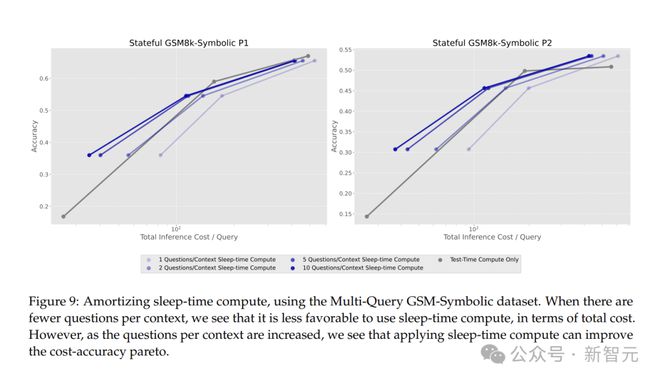
這對實際應用意義重大,處理大量相關查詢時,能大幅降低計算成本。
可預測查詢獲益更多
研究人員還發現,睡眠時計算在查詢可預測性高的場景中效果更好。
隨着問題從上下文中變得更加可預測,睡眠時計算和標準測試時間計算之間的準確度差距不斷擴大。
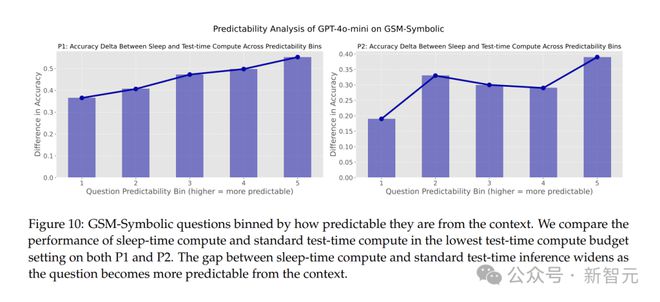
當問題更容易從上下文中預測時,睡眠時計算的效果就越好,模型的性能提升也更為明顯。
軟件工程中的應用
除了在數學推理任務中的出色表現,睡眠時計算在實際的軟件工程任務中也進行了測試。
研究人員引入了SWE-Features這個軟件工程基準,它聚焦於需要編輯多個文件和實現新功能的任務。
在這個場景中,研究人員將拉取請求(PR)作為查詢q,相關的PR作為上下文c。
在睡眠時間,智能體可以探索存儲庫,提前總結對相關PR的理解,生成新上下文c'。
而標準測試時計算的基線設定中,智能體在測試時才同時收到上下文和查詢信息。
評估方式是比較智能體預測的修改文件集和實際的修改文件集,通過計算F1分數衡量智能體表現。
結果顯示,在較低測試時計算預算下,利用睡眠時計算可顯著提高性能,測試時token數最多可減少約1.5倍。
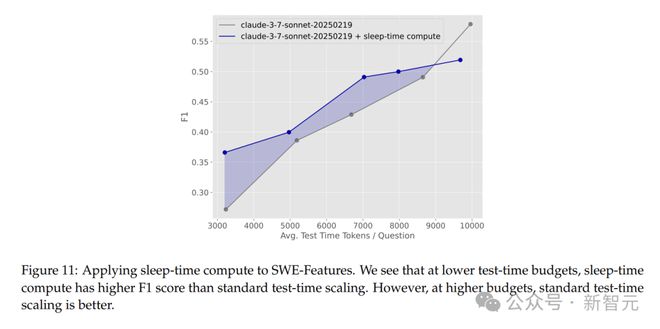
但在高測試時計算預算下,僅用標準測試時計算表現更好,因為它能更早開始編輯文件,且總體編輯文件較少。
啓用睡眠時計算的智能體雖然精度略低,但在處理複雜任務方面有一定優勢。
參考資料:
https://x.com/Letta_AI/status/1914356940412772414
https://x.com/charlespacker/status/1914380650993569817
https://www.letta.com/blog/sleep-time-compute