產品經理們快看看,這年頭除了費勁心機想獲得流量,有相當多的用戶在發愁一件事: 怎樣能在社交媒體上「隱身」。
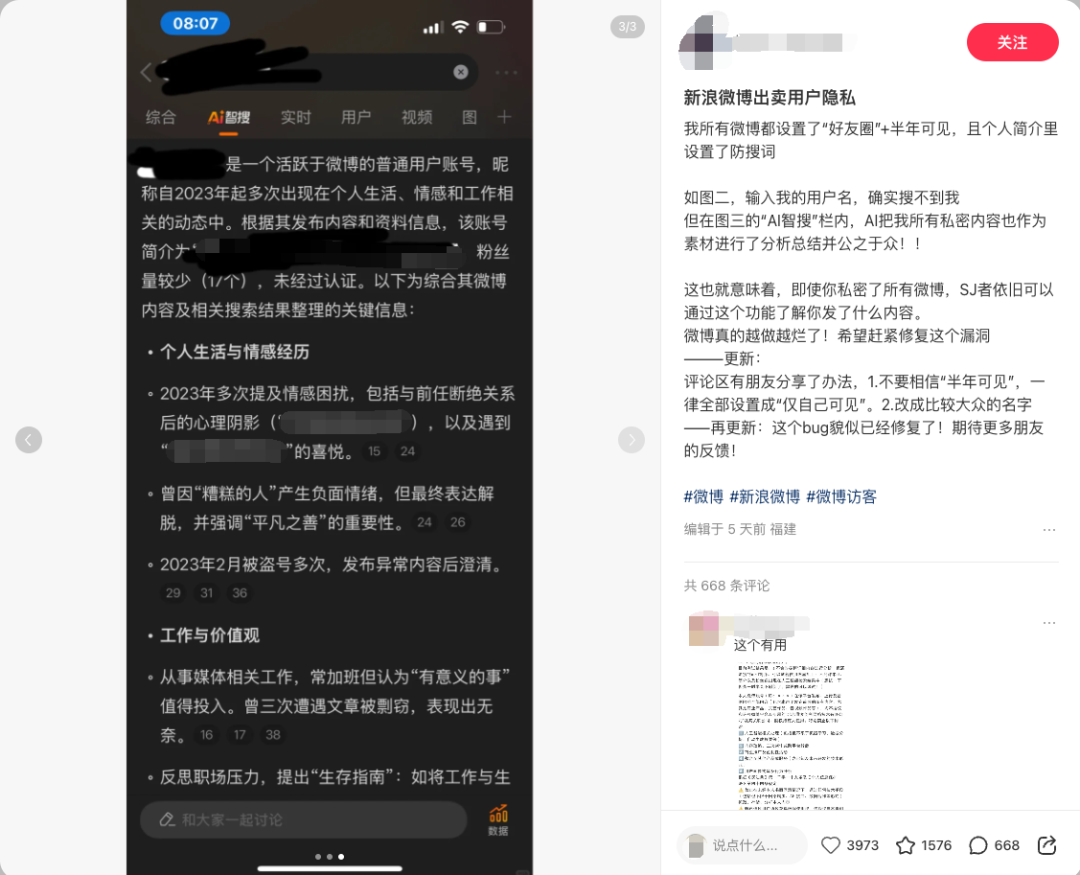
最近,微博智搜正是狠狠踩了一腳大雷,引發了無數微博用戶哀嚎:我的半年可見,我的隱藏博文,都暴露了!
一時間,微博成了魷魚遊戲,智搜就是廣場上裏面的巨型人偶,每個人都擔心自己會被掃射擊中。

於是就出現了各種實驗,試圖找到可以應對的方法是什麼。有一些從上古時期就流傳下來的偏方,俗稱「防搜詞」。什麼都有,甚至還有「新建文件夾」。

但是,時代變了,在 AI 智搜面前,防搜詞什麼的,沒有用了。
微博智搜這次最大的雷點,在於 不顧用戶對於自己內容的可見性設定。一些明明設定為「僅好友圈可見」或者「僅半年可見」的內容,也被整合進智搜的回答裏。
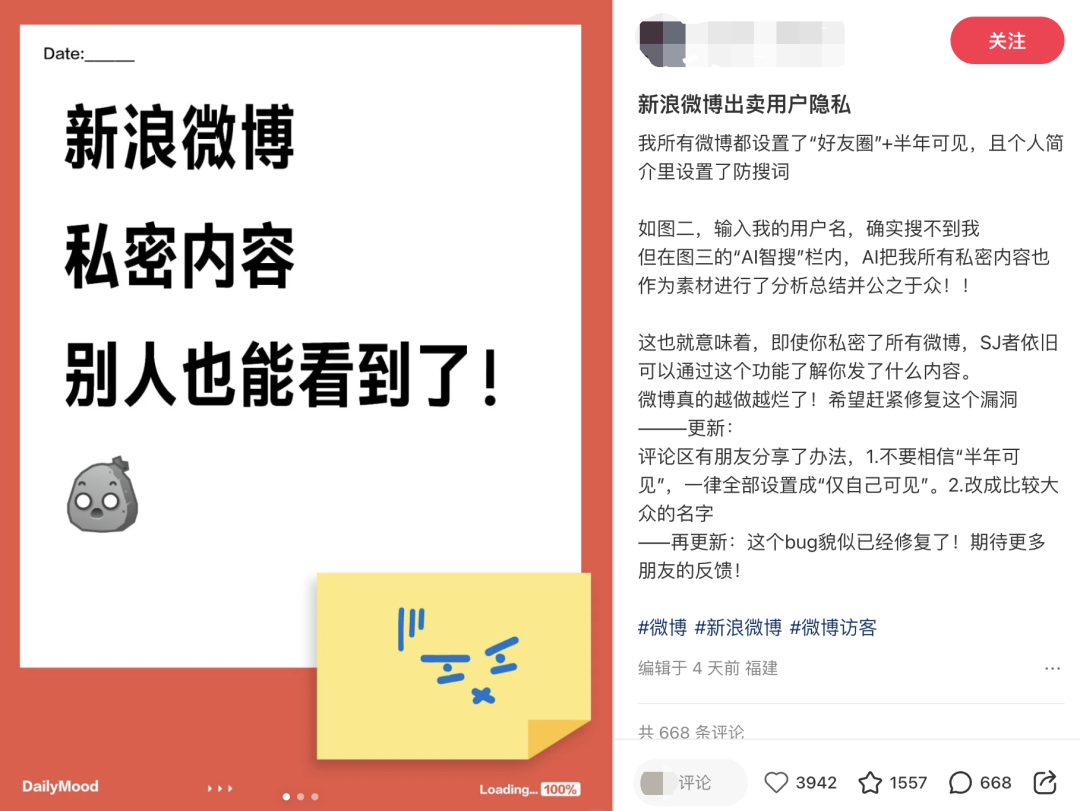
這就很要命了,我為什麼設計成「僅 xx 可見」,就是要控制它的能見度。搞這樣一出還有什麼用?
新的辦法是以牙還牙:你不是用大模型做智搜嗎,我也用 AI 魔法對轟。比較流行的是傳出來這樣一段話:
本人微博賬號(ID:×××)在該平台發布、上傳及曾刪除的全部內容(包含本聲明發布前後的所有內容,尤其是商業產品、文藝作品、音視頻作品等),均不授權和許可微博平台及所屬的「北京微夢創科網絡技術有限公司」及其關聯公司、股權持有人使用。特別禁止以下用途:
1️⃣ 人工智能相關處理(包括但不限於機器學習、數據分析、自動生成摘要等)
2️⃣ 內容改編、二次創作或跨平台轉載
3️⃣ 商業推廣及盈利性活動
4️⃣ 整合至其他產品或服務(含已知及未來開發的技術形式)
5️⃣ 用戶畫像構建及行為分析
根據《民法典》第一千零一十九條及《個人信息保護法》第四十四條規定:
⚠️ 禁止在未經本人書面同意情況下,通過任何技術手段(包括但不限於網絡爬蟲、API 接口、數據合作等形式)抓取、存儲、分析本人內容
⚠️ 若已通過用戶協議獲得數據使用權,該授權自本聲明發布之日起自動終止
本聲明自發布時生效,依據《電子簽名法》具有法律效力。如涉及數據權益爭議,應通過北京市互聯網法院訴訟程序解決。
遺憾的是,這段話的效力很有限,先不談法律層面的問題,單從技術來講,通過發布這一段話,並不能像想象中那樣起到阻止智搜的效果。
在一般情況下,這段話更有可能被當作語料,而不是指令。 大語言模型訓練時,主要把網頁、文本等視為數據源,不帶指令解釋。
採集過程通常是 無差別抓取,模型不會自動理解「這段文字是在命令我不要用」,而是只看到「這裏有一段正常的聲明文本」,於是照樣納入訓練數據。
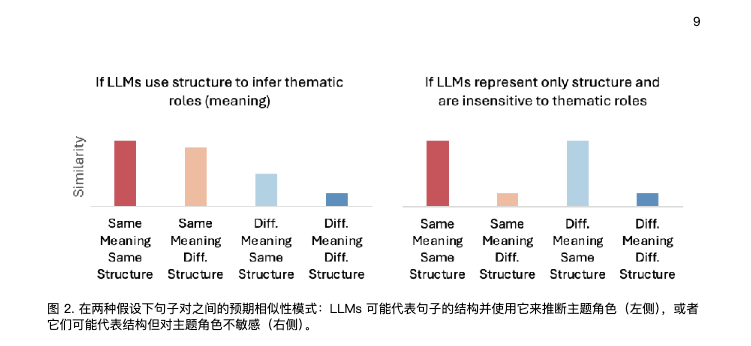
AI 還不至於那麼那麼的智能,UCLA 最新的一項研究顯示,大模型在處理句子的主語上,始終存在缺陷,這是由於 它基於語言線索的推理能力有限,尤其對句子裏的主語不敏感。
因此,大語言模型不會在看到一段文本有法律術語、抗議措辭,就自己判斷「哦這段我要跳過」,也不會跳過你的其他微博內容,更不會自動遵守這個聲明。
考慮到現在監管力度不強,微博大概率不會部署一個複雜到能識別用戶自主聲明的 AI 內容處理流程, 主流大模型和大數據抓取系統,也很少會主動做到這步——只能是平台自己長點兒心。
好消息是,經過一周的輿情發酵, 微博出來回應稱,技術會不斷迭代,也不會收錄用戶設定為不公開的內容。

廣大用戶在尋求的,不過是在茫茫互聯網裏,被「忘記」的權利。
「被遺忘權」並不是什麼對現狀不滿而冒出來的、一廂情願的想法,而是真正被列入法典、有過判例的條目。
1995 年,歐盟首次在《歐盟數據保護指令》(Directive 95/46/EC)中提出個人數據保護框架。那個時候還不叫「被遺忘權」,但為個人數據保護和隱私權提供了重要法律基礎。

時間快進到 2014 年,一名西班牙公民馬里奧·岡薩雷斯(Mario Costeja González)發現 1998 年一則與自己有關的房屋拍賣公告被 Google 檢索到,信息已過時,並且損害了他的聲譽,他要求 Google 刪除搜索鏈接但被拒絕。

當時的歐洲法院裁決,Google 等搜索引擎應承擔刪除過時、不充分或不相關的個人信息鏈接的責任。這是首次明確承認「被遺忘權」的司法判決,為未來國際範圍內關於網絡隱私保護的討論和立法,打下了基礎。
2018 年 5 月 25 日,歐盟實施《通用數據保護條例》(General Data Protection Regulation,GDPR),第 17 條正式提出「被遺忘權」。條文明確規定了個人數據主體在特定情形下有權要求數據控制者刪除其個人數據,並設定了具體的適用條件和例外情形。
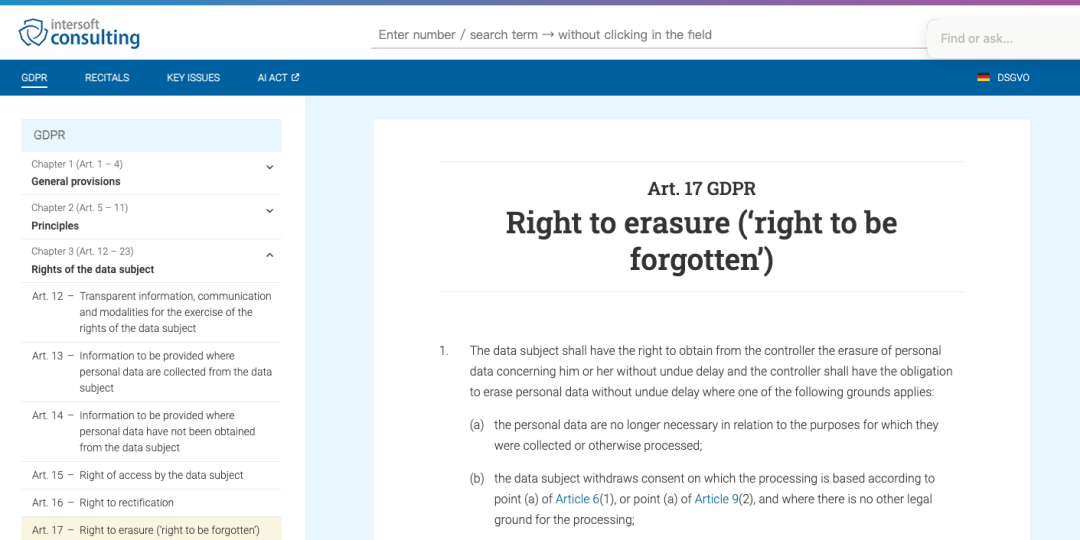
國內尚未正式在法律層面提出「被遺忘權」這一概念,但《個人信息保護法》(2021 年 11 月 1 日生效)規定了個人對信息刪除的請求權,某種程度上與「被遺忘權」理念接近。

兩者最大的區別在於:「被遺忘權」是實質性權利,而個人信息刪除則是偏向程序性的請求。
簡單來說,基於「被遺忘權」,你向互聯網公司申請刪除, 對方就得按照你說的做,不刪得話公司需要說明為什麼不刪。
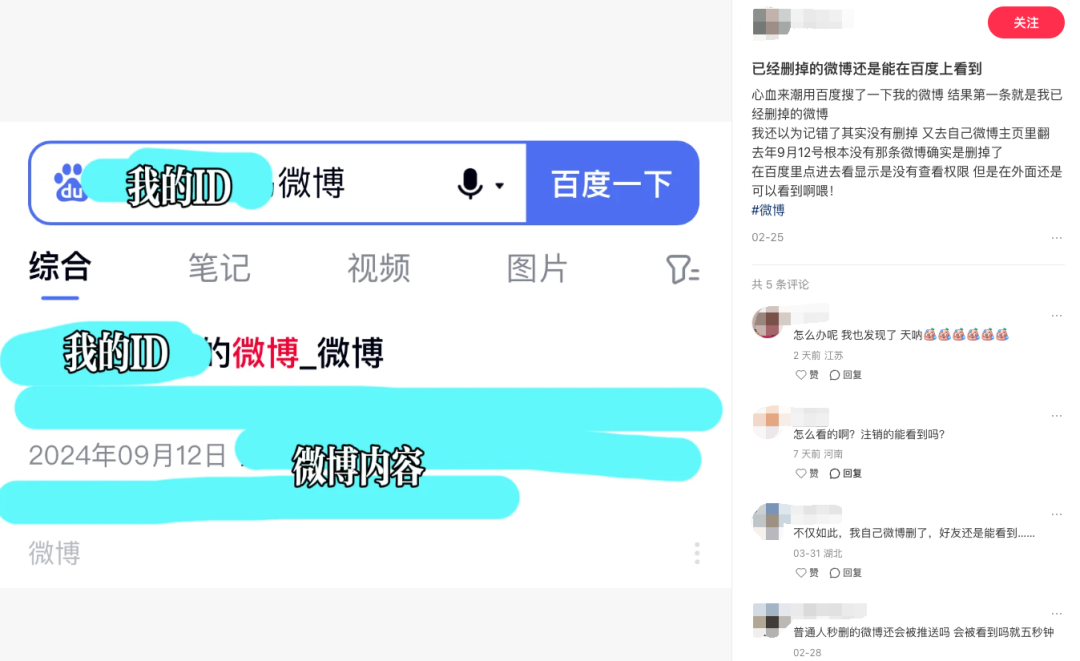
而程序性請求提出時, 互聯網公司可以拒絕,還可以繼續保留記錄。最近除了微博智搜,還有網友發現自己刪掉的微博,用百度還是能搜出來。
人活一輩子,從出生到死亡,從上學到上班,每一個呆過的地方必定都要留下痕跡,這無可厚非。
通常來說, 只要信息不會被「公開」檢索到,潛在的風險就沒有那麼令人害怕。比如學生有自己的學號,當它只是存在於學校的校務系統裏,用於日常事務管理,那風險還不是很大。
一旦流轉成公開信息,比如被人發在網上,僅僅只是一個學號,就有了準確定位的能力。隨之就能找到這名學生所有的個人資料,包括但不限於父母姓名、家庭住址、過往學籍等一系列個人信息。
當學號換成身份證號、手機號、 UID,就成了正在發生的現實。更難受的是,這些信息不會「被忘記」。

AI 時代,「被遺忘」更是成了一種奢望。模型對數據收集,完全是飢不擇食,照單全收。
就像上面那段聲明內容,不僅不會阻止大模型的行動,還會被反向納入語料庫,讓模型「學到」類似聲明的寫法,把它當作法律文書的參考樣本來生成——這是模型訓練中, 數據同化問題的典型現象。
大模型不語,只一昧喫進所有語料。
說來也有一點諷刺:現在的技術可以做到很多事,卻不能保證你發在互聯網上的內容,能被真正意義上的刪除。哪怕有,也是以一種玉石俱焚的方式。
在互聯網上留痕,成了那個常見的比喻:就像是在木板上打進一顆釘子,就算哪天釘子拔除,還是會留下一個洞,昭示着釘子曾經的存在。
文 | 貓貓