
編輯:編輯部 ZJH
【新智元導讀】啱啱,LMArena陷入了巨大爭議,斯坦福MIT和Ai2等的研究者聯手發論文痛斥,這個排行榜已經被Meta等公司利用暗中操作排名!Karpathy也下場幫忙錘了一把。而LMArena官方立馬回應:論文存在多處錯誤,指控不實。
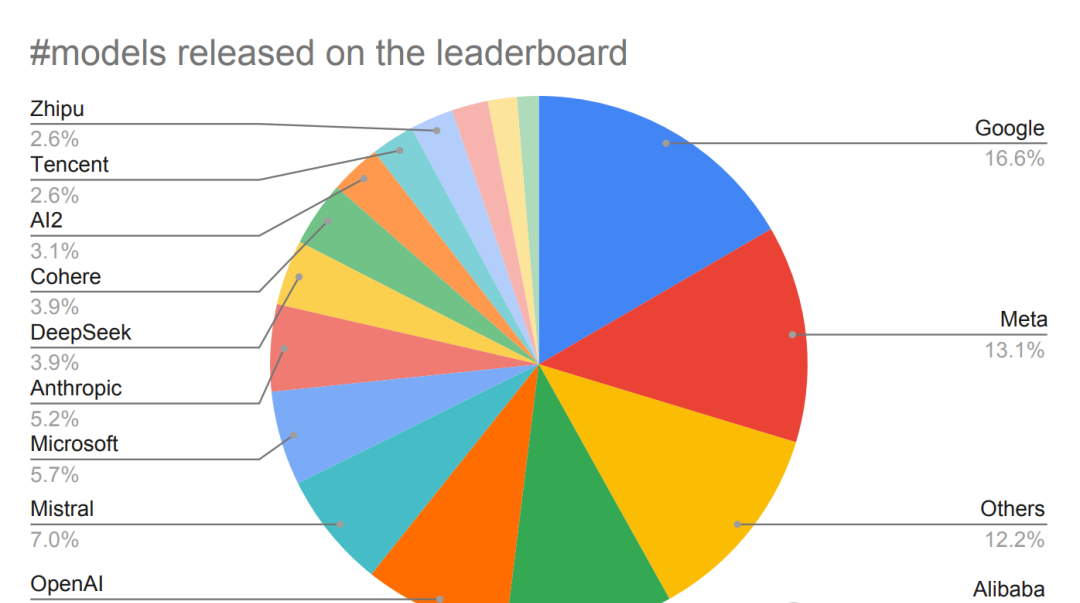
已經有越來越多的人發現:大模型排行榜LMArena,可能已經被大廠們玩壞了!
就在最近,來自Cohere、普林斯頓、斯坦福、滑鐵盧、MIT和Ai2等機構的研究者,聯手祭出一篇新論文,列出詳盡論據,痛斥AI公司利用LMArena作弊刷分,踩着其他競爭對手上位。

與此同時,AI大佬、OpenAI創始成員Andrej Karpathy也直接下場,分享了一段自己的親身經歷。
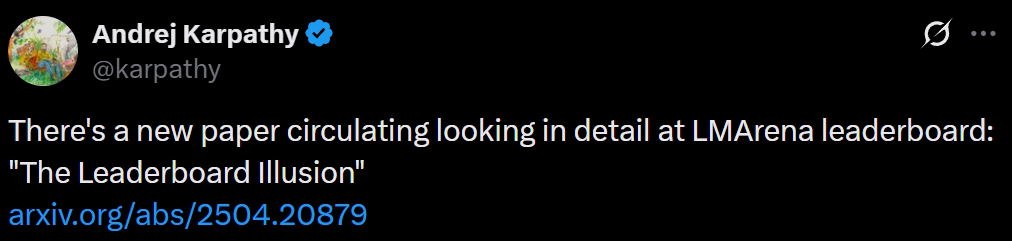
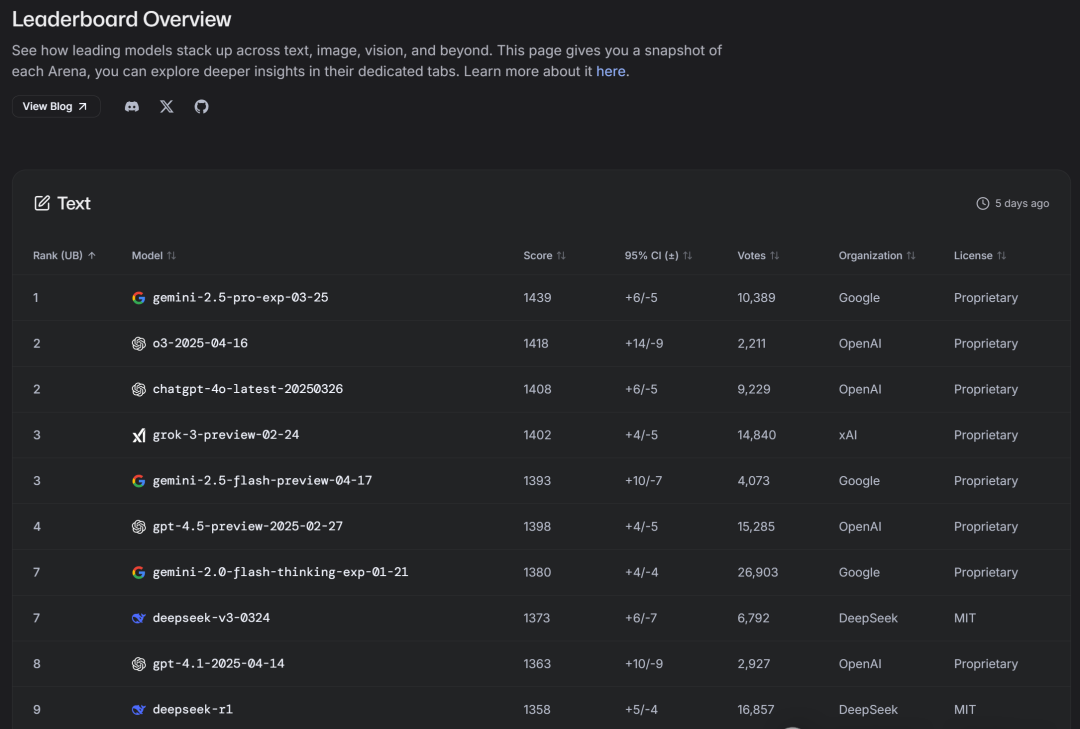
前一段時間,Gemini模型一度在LMArena排名第一,遠超第二名。
但Karpathy切換使用後,感覺還不如他之前用的模型。
相反,大約在同一時間,他的個人體驗是Claude 3.5是最好的,但在LMArena上的排名卻很低。
他還發現一些其他相對隨機的模型,通常小得可疑,據他所知幾乎沒有現實世界的知識,但排名也很高。
他開始懷疑,谷歌等AI巨頭在暗中操縱LMArena的排名。
要知道,就在本月初,就有報道稱LMArena可能正在成立新公司,籌集資金。
在這個時候曝出醜聞,不知對此是否會有影響。
業內聯名痛斥巨頭
巧鑽漏洞,暗箱操作
這篇報告,研究者花費了5個月時間分析了競技場上的280萬場戰鬥,涵蓋了43家提供商的238個模型。
結果表明,少數提供商實施的優惠政策,導致過度擬合競技場特定指標,而不是真正的AI進步。
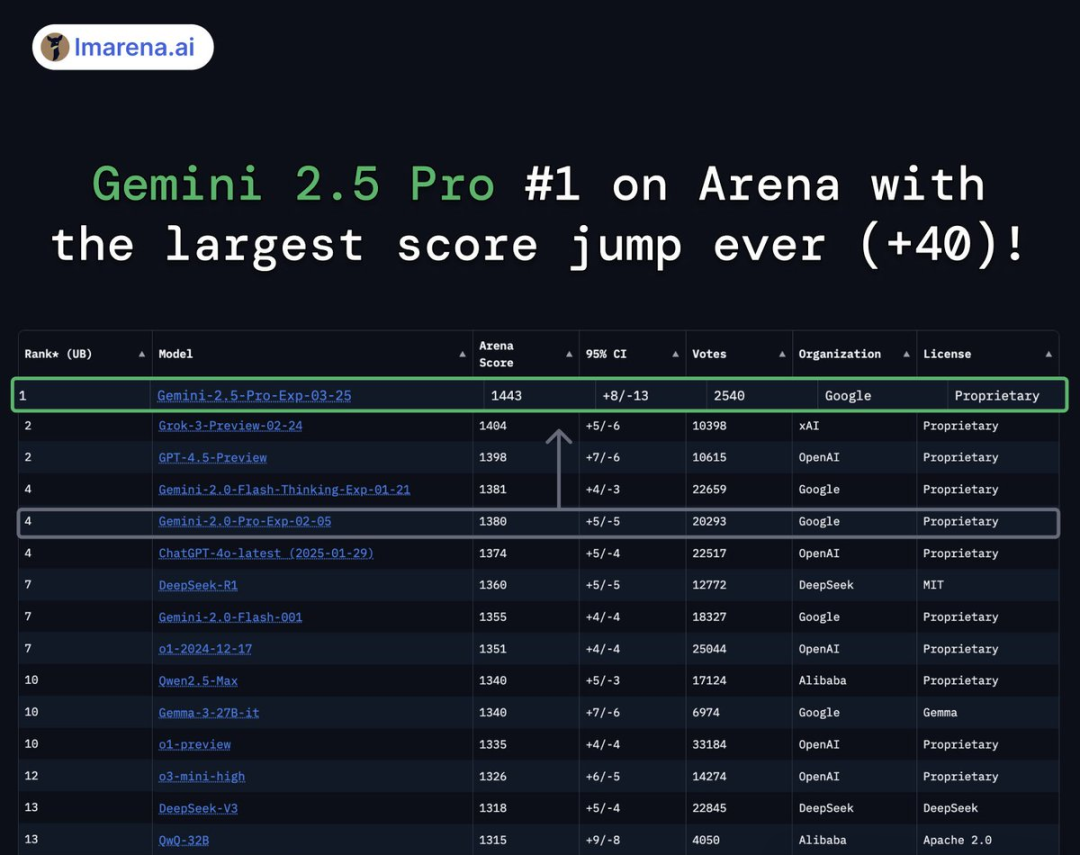
因為存在未公開的私下測試機制,少數公司能在模型公開發布前測試多個變體,甚至選擇性地撤回低分模型的結果。
如此一來,公司便可以「挑三撿四」,只公布表現最好的模型得分,從而讓LMArena的排行榜的結果出現嚴重「偏見」。
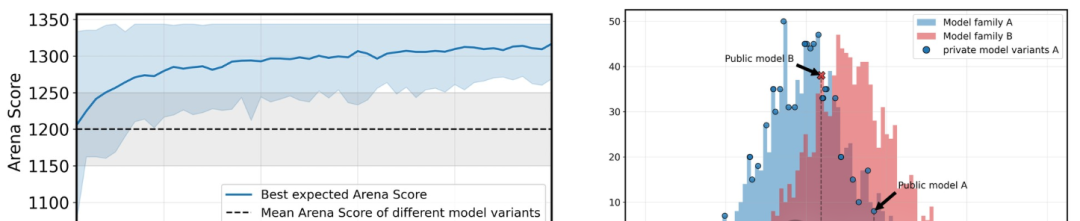
而這種優勢,會隨着變體數量的增加,而持續疊加。
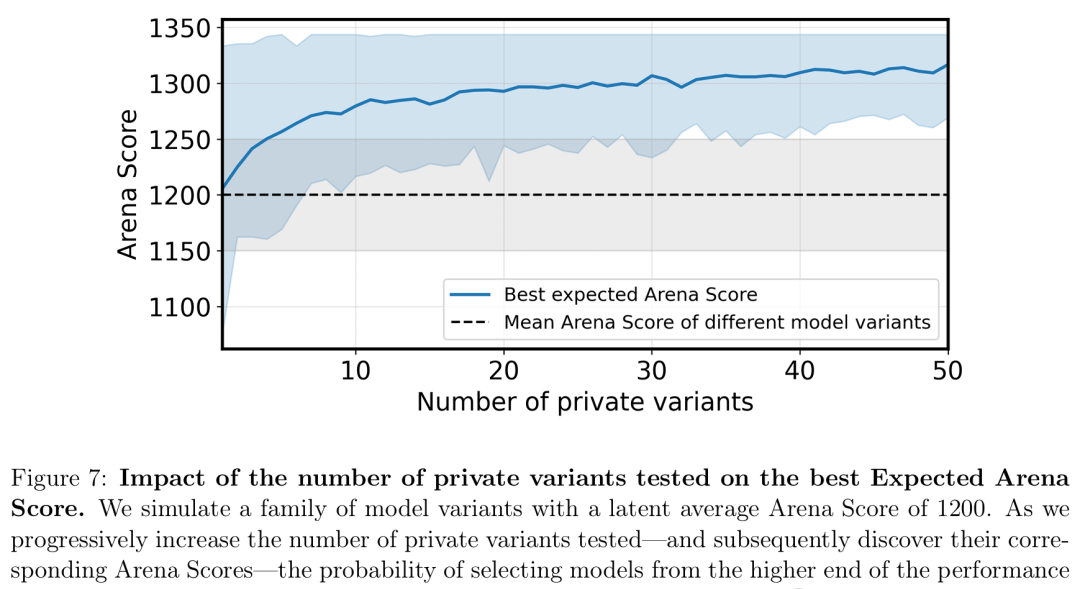
私下測試模型變體數量對最佳預期得分的影響
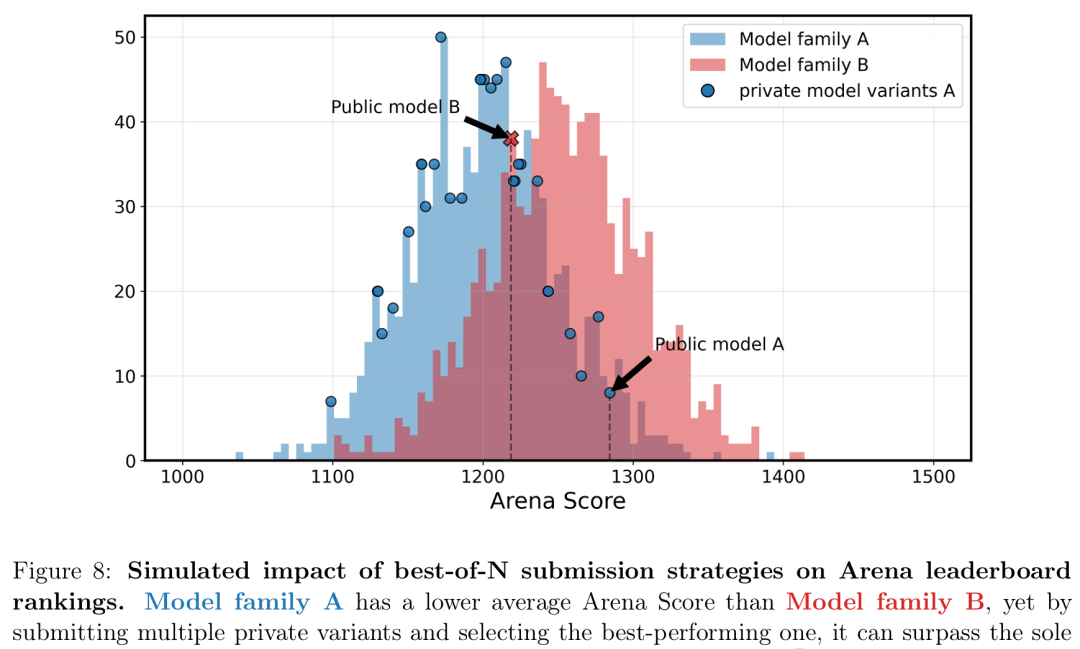
「best-of-N」提交策略對排名的模擬影響
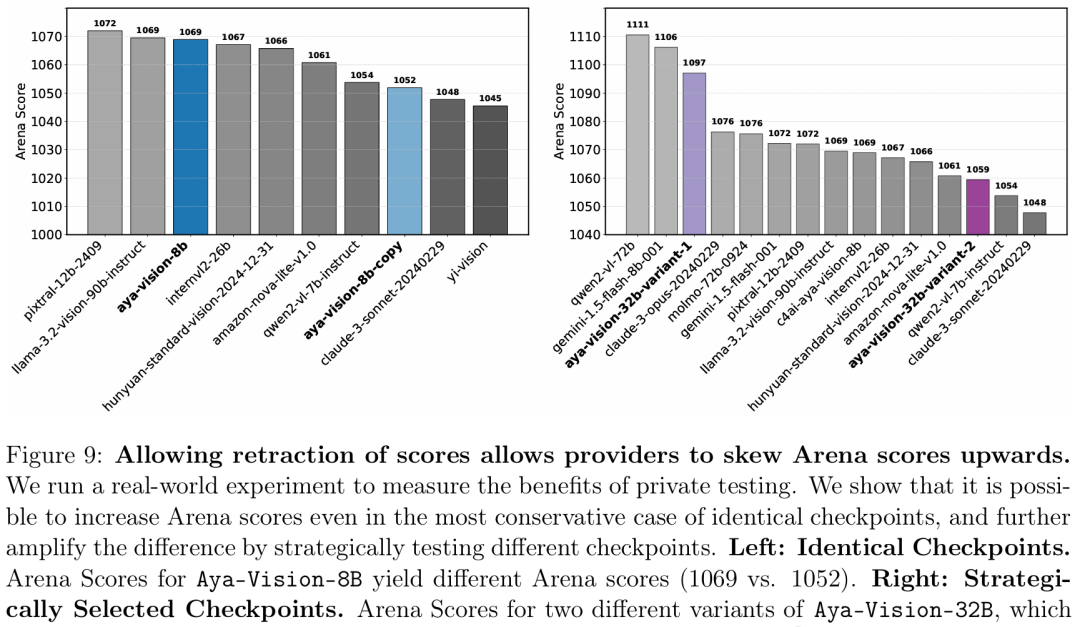
允許撤回評分會導致提供商有意抬高競技場分數
比如說,Meta在發布Llama 4之前,曾私下在LMArena上測試了27個LLM變體。
而最終只公布了其中一個分數。
巧的是,這個模型恰恰就在LMArena上名列前茅。
Cohere的AI研究副總裁、論文合著者Sara Hooker在接受外媒採訪時抱怨說:「只有少數公司會被告知可以私下測試,而且部分公司獲得的私下測試機會,遠超其他公司。」
「這就是赤裸裸的兒戲。」

從「行業標準」到「人人喊打」?
與此同時,研究者還發現:
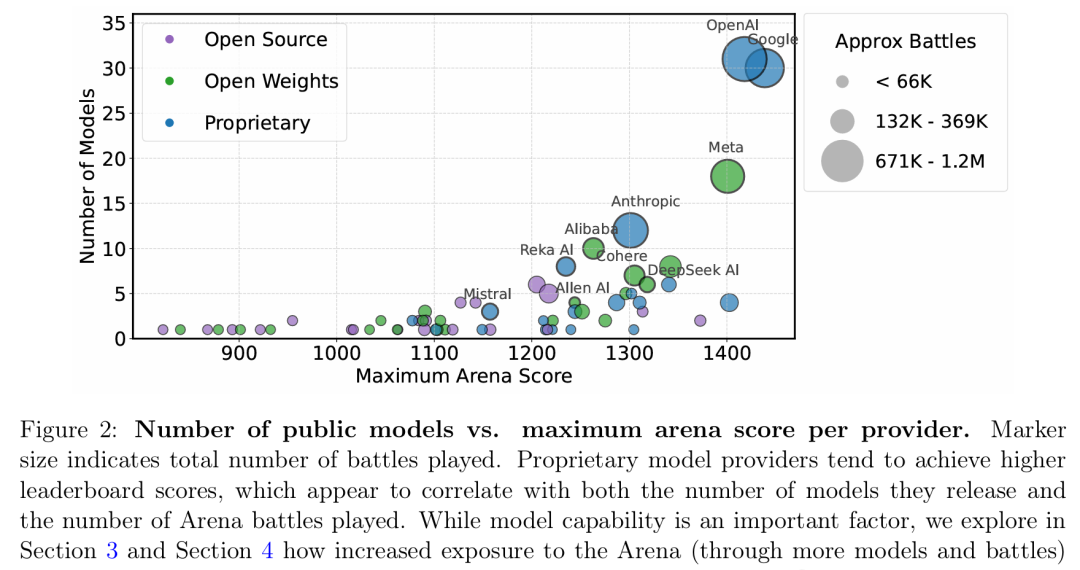
閉源商業模型(如Google、OpenAI的模型)在LMArena中參與次數更多
與之對比,開源模型(開放權重)不僅對戰次數較少,而且更容易在Arena中被移除
這導致了一個長期的數據訪問不平等現象
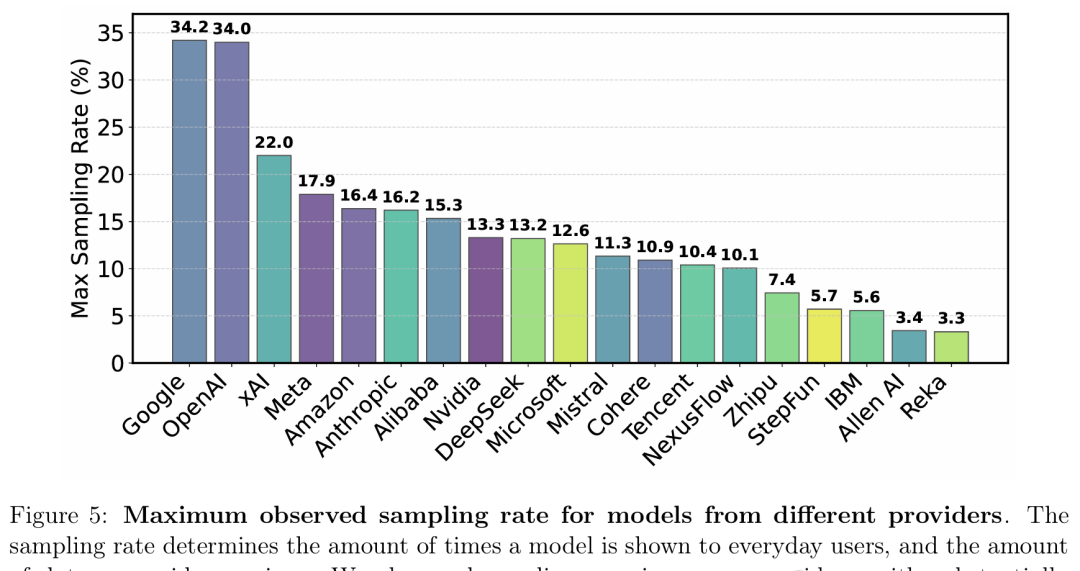
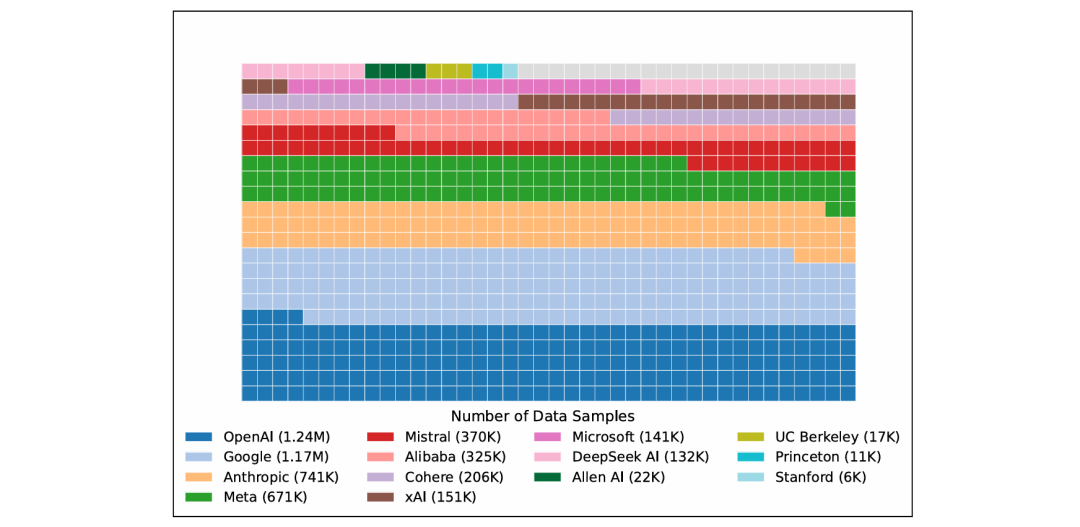
不同模型提供者的最大觀測採樣率
採樣率反映了模型在LMArena中被普通用戶看到的頻率,也直接決定了該模型開發者能獲取多少用戶交互數據。
LMArena是一個開放的社區資源,提供免費反饋,但61.3%的所有數據都流向了特定的模型提供商。
具體來說,他們估算:
Google和OpenAI的模型分別獲得了Arena上約19.2%和20.4%的全部用戶對戰數據
而83個開源模型的總數據佔比僅為29.7%
模型開發者的數據可用性情況
而保守估計哪怕是有限的額外數據,也可能帶來高達112%的相對性能提升。
這進一步說明模型在Arena上的表現很容易被「過擬合」——即優化的是排行榜表現,而不是真正的通用模型質量。
值得注意的是,LMArena的構建和維護依賴於組織者和開源社區的大量努力。
組織者可以通過修訂他們的政策來繼續恢復信任。
論文還非常清楚地提出了五個必要的改變:
公開全部測試
限制變體數量
確保移除模型的公平性
公平抽樣
提高透明性
官方回應
論文有大量錯誤和詆譭
鋪天蓋地的質疑襲來,LMArena火速出來回應了!
它的官號第一時間發推回應稱,這項研究存在諸多事實錯誤和誤導性陳述,充滿了「不確定和可疑的分析」。
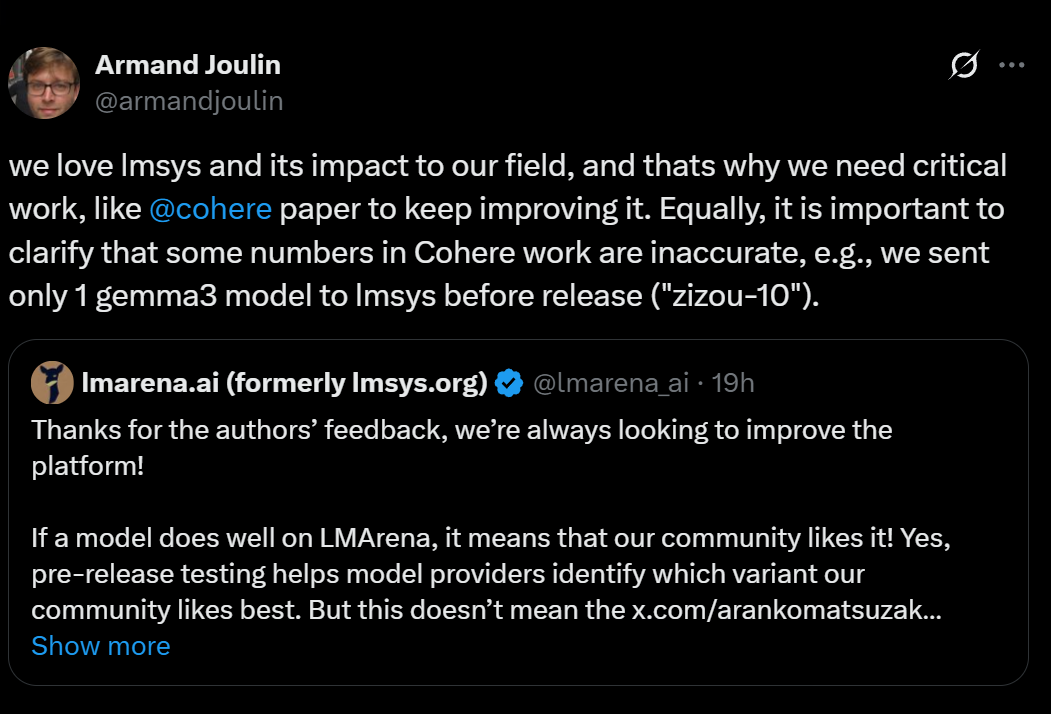
而他們的說法,得到了谷歌DeepMind首席研究員Armand Joulin的聲援。
他表示,論文中的一些數據是不準確的,比如谷歌只向LMArena發過一個Gemma 3的模型,進行預發布測試。
具體來說,關於某些模型提供商未得到公平對待的說法:
這不符合事實。LMArena表示他們一直盡力滿足所有收到的評估請求。如果一個模型提供商選擇提交比另一個模型提供商更多的測試,這並不意味着後者受到了不公平對待。每個模型提供商對如何使用和重視人類偏好都有不同的選擇。
事實錯誤:
LMArena的模擬(如圖7/8所示)存在缺陷。這就像說:「NBA的平均三分球命中率是35%。庫裏的三分球命中率是NBA中最高的,為42%。這不公平,因為他來自NBA球員的分佈,而他們都有相同的潛在均值。」
論文中的許多數字與實際情況不符。LMArena在幾天前發布了博客,公布了不同提供商的測試模型的實際統計數據。例如,開源模型佔40%,而不是8.8%!
所謂112%性能提升的說法具有誤導性,論文的結果基於LLM-judge基準,而不是Arena中的實際人工評估。
LMArena的政策並非「祕而不宣」。早在一年多前,LMArena就設計並公開分享了他們的政策。
模型提供商不僅僅選擇「要披露的最佳分數」。公共排行榜上列出的任何模型都必須是所有人都可以使用的正式版本,並且計劃提供長期支持。LMArena會使用新的數據對模型進行至少一個月的持續測試。LMArena的政策中一直明確說明了這些要點。
顯示無法通過API或開源權重公開獲取的預發布模型的分數毫無意義,因為社區無法使用這些模型或自行進行測試。這將違反LMArena一年多以前制定的政策。LMArena制定這項規則正是為了明確這一點:如果模型在排行榜上,則必須保證可用性。
模型下架並非不公正或缺乏透明度,這與事實不符。排行榜旨在反映社區對最佳AI模型進行排名的興趣。LMArena還會下架不再向公衆提供的模型。這些標準已在我們的政策中公開聲明,並且在社區進行私下測試期間始終有效。

LMArena的政策(上下滑動查看)
要不,換個平台試試?
正如貝佐斯所說:「當數據與個人經驗不一致時,個人經驗通常是正確的。」
Karpathy也有同感。
他認為這些大團隊在LMArena分數上投入了太多的內部關注和決策精力。
不幸的是,他們得到的不是更好的整體模型,而是更擅長在LMArena上獲得高分的模型,而不管模型是否更好。
對此Karpathy表示,既然LMArena已經被操控了,那就給大家推薦一個有望成為「頂級評測」的新排行榜吧!
它就是——OpenRouterAI。
OpenRouter允許個人/公司在不同LLM提供商之間快速切換API。
他們都有真實的用例(並非玩具問題或謎題),有自己的私有評測,並且有動力做出正確的選擇,因此選擇某個LLM就是在為該模型的性能和成本的組合投票。
Karpathy表示,自己非常看好OpenRouter成為一個難以被操控的評測平台。
創始成員離開
初心或已不在
如今的爆火,或許讓人早已忘記,LMArena最初只是UC Berkeley、斯坦福、UCSD和CMU等高校的幾位學生自己做出來的項目。
和傳統評測不同,LMArena採用的則是一套完全不同的方式——
用戶提出問題,兩個匿名AI模型給出答案,然後評判哪個回答更好,並最終將這些評分被匯總到一個排行榜上。
憑藉着這套創新性的方法,它一舉成為了當時幾乎唯一一個能較為客觀地反映LLM性能的排行榜。
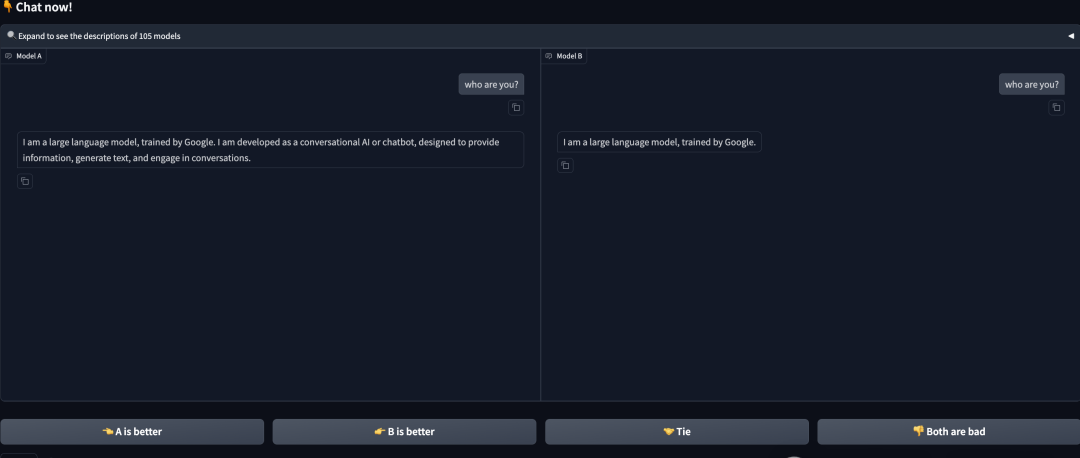
在輸入框中輸入問題,兩個不同的模型A和B同時回答。之後,用戶可選A或B的不同評價:A更好,B更好,平局,都不好
隨着科技公司投入數百億美元押注AI將成為未來幾十年的決定性技術,LMArena也迅速走紅。
在吸引客戶和人才方面,任何領先競爭對手的優勢都可能帶來重大影響,這就是為什麼衆多科技高管和工程師像華爾街交易員盯盤一樣密切關注LMArena。
之後的故事,大家就都知道了。
問題在於,作為課餘項目的LMArena本身並不完善。之所以能在持續的爆炸性增長下不失客觀性,靠的是創始人們堅定的初心。
隨着創始成員陸續畢業,新成員的加入,LMArena似乎也離它最初的路線,越來越遠。
一方面,由於投票不公開、以及哪些模型應該進入競技場是由某幾位成員獨斷決定的,導致LMArena自身機制就缺乏透明性。
另一方面,新團隊在某個時間點突然決定,把LMArena開放給頭部大公司做匿名模型測試。
這幫摸爬滾打了多年的老油條們,顯然不會錯失這一良機。基於對大量實測數據的分析,這些技術大佬們很快就「掌握」了LMArena的調性,紛紛刷起了高分。
從此,質疑聲便開始此起彼伏。