
新智元報道
編輯:犀牛
【新智元導讀】本文深入梳理了圍繞DeepSeek-R1展開的多項復現研究,系統解析了監督微調(SFT)、強化學習(RL)以及獎勵機制、數據構建等關鍵技術細節。
最近,推理語言模型(RLMs)已經成為主流。
最新發布的、性能最強的LLM大都是推理模型。
尤其是DeepSeek-R1的發布,更是引發了廣泛的社會影響,同時也點燃了研究社區對推理的熱情。
但是,DeepSeek-R1的一些實現細節還沒有完全開源,比如DeepSeek-R1-Zero以及蒸餾的小模型等。
因此,許多複製DeepSeek-R1的研究應運而生(圖1),試圖通過相似的訓練流程和完全開源的訓練數據來重現DeepSeek-R1的優異性能。

這些研究探索了監督微調(SFT)和基於可驗證獎勵的強化學習(RLVR)的可行策略,重點關注數據準備和方法設計,產出了不少寶貴經驗。
為此,本文總結了近期的這些復現研究,以啓發未來的探索。

論文地址:https://arxiv.org/abs/2505.00551
本文的結構大致對應DeepSeek-R1的訓練流程,介紹當前在SFT、RLVR以及其他增強推理能力技術方面的複製工作:
監督微調提升語言模型推理能力:研究團隊全面梳理了通過監督微調(Supervised Fine-tuning, SFT)增強語言模型推理能力的相關研究。
用可驗證獎勵強化學習訓練推理語言模型:研究團隊介紹了近期通過可驗證獎勵強化學習(Reinforcement Learning from Verifiable Rewards, RLVR)訓練RLMs的研究,詳細闡述了訓練數據、學習算法和獎勵系統設計。
推理語言模型的更多發展方向:研究團隊注意到,儘管DeepSeek-R1推動了RLMs的訓練,但仍有許多監督策略尚未探索。他們提出了RLMs的更多發展方向,包括獎勵建模和偏好優化,並分析了當前RLMs的優缺點,例如強大的分佈外泛化能力和偶爾的過度思考。
通過監督微調提升RLMs
推理數據集大多數從收集多樣化領域的問題開始,例如數學、科學、編程和謎題,數據來源包括現有的基準測試或網絡爬取。
在收集原始數據後,通常會進行多輪過濾以提升數據質量,包括:
去重:通過嵌入相似性或n-gram方法去除重複數據;
拒絕採樣:剔除低質量數據;
真值驗證:確保數據準確性。
為了保證數據的覆蓋面和豐富性,許多數據集在選擇過程中明確強調難度和多樣性,通常使用啓發式方法或模型通過率來優先選擇較難的問題。
此外,大多數數據集依賴經過驗證的思維鏈(COTs)或解決方案來確保正確性和質量。
驗證方法因領域而異,例如:
數學問題通常通過Math Verify驗證;
編程問題通過代碼執行或單元測試驗證;
通用任務則由大語言模型(LLM)作為評判者進行驗證。
這種結合領域驗證和選擇性保留的方法,使數據管理人員能夠提煉出高質量的推理軌跡,從而更好地支持監督微調。
雖然這些數據集覆蓋多個領域,但如表1所示,大多數數據集主要集中在數學和編程任務上。涉及更廣泛推理任務(如科學、邏輯謎題和開放性問題)的覆蓋率仍然相對有限。
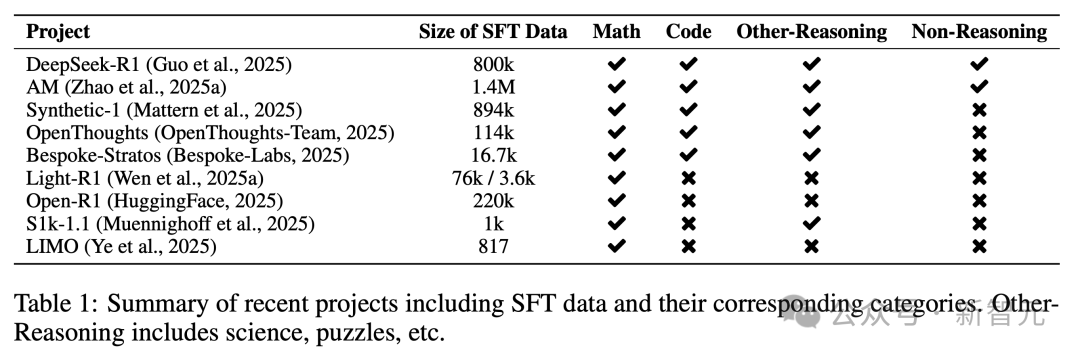
值得注意的例外包括DeepSeek-R1和AM,它們在數據收集和蒸餾過程中納入了更廣泛的領域,旨在培養更通用的推理能力。

長度分佈
圖2展示了數據集的token長度分佈情況。
儘管這些數據集的長思維鏈(CoTs)都來源於同一個教師模型——DeepSeek-R1,但它們的分佈卻存在明顯差異。
例如,AM和Synthetic-1的數據集傾向於較短的序列,而Light-R1和Open-R1的分佈範圍更廣,尾部更長,這表明它們包含更多複雜問題,這些問題通常會引發更長的思維鏈。
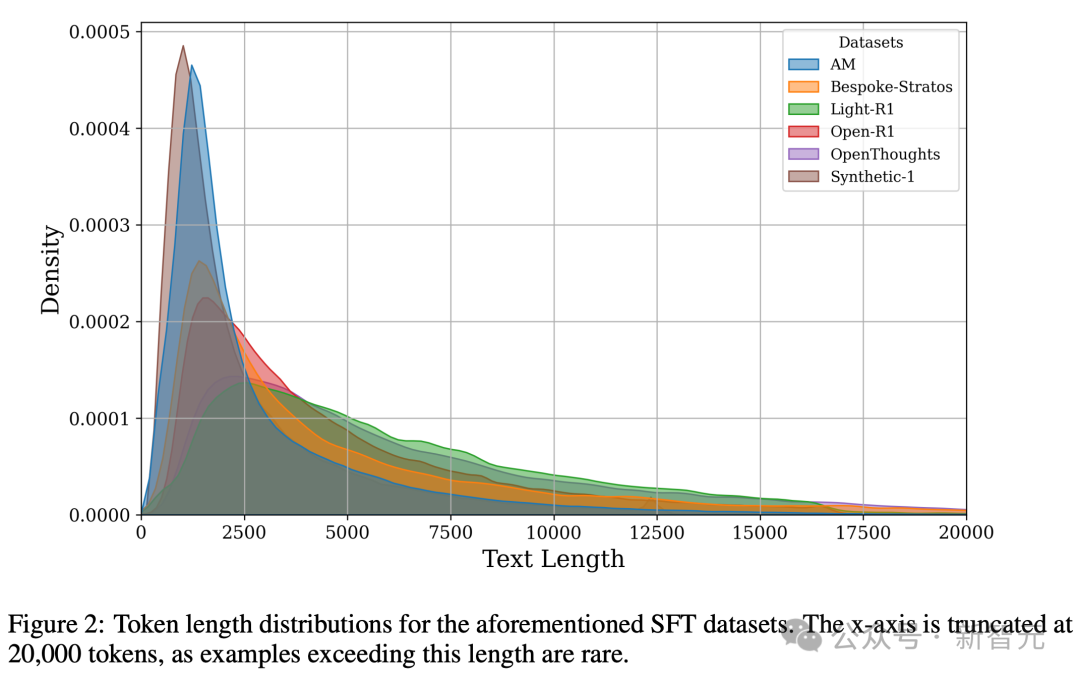
圖3中展示了常用數學推理數據集之間的交叉引用結構。該圖清晰地呈現了數據集之間的依賴網絡和共享數據,幫助研究人員更好地解讀結果,避免重複的訓練或評估設定。
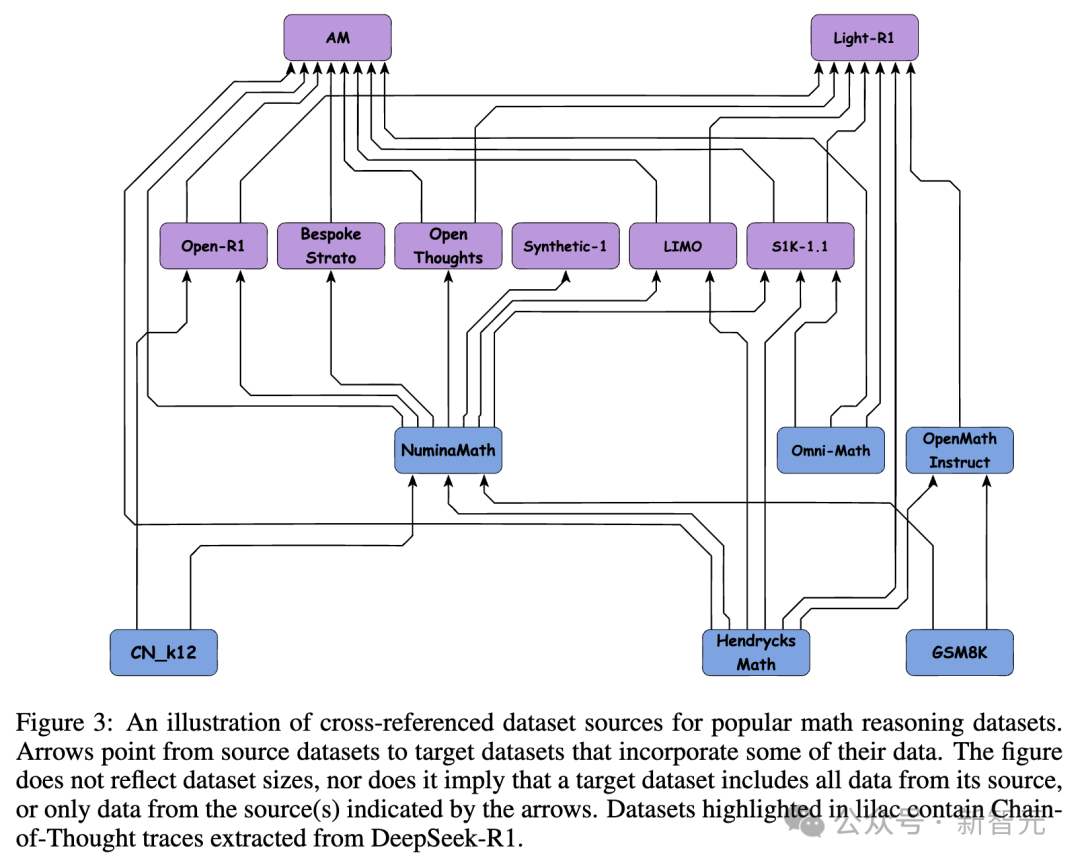
圖中箭頭從源數據集指向包含其部分數據的目標數據集。以淡紫色高亮顯示的數據集包含從DeepSeek-R1提取的思維鏈(Chain-of-Thought)軌跡
性能比較
在實踐中,SFT階段對於讓基礎模型從更強的模型中學習高質量推理軌跡至關重要。
表2展示了在常見數學推理基準(如AIME24/25和MATH500)上的SFT結果比較,突出不同數據集選擇和初始模型檢查點的影響。

雖然許多方法強調通過增加訓練樣本數量來提升性能,但LIMO和S1k-1.1表明,通過精心挑選的小規模數據集也能取得優異成果。
訓練細節
對於複雜推理等長上下文任務,通常會調整模型配置中的RoPE縮放因子(θ)和最大上下文長度,以支持擴展的上下文能力。
例如,Open-R1將θ設為300,000,上下文長度設為32,768個token。常用的學習率包括1.0 × 10⁻⁵和5.0 × 10⁻⁵,批大小通常為96或128。
此外,通常採用打包(packing)技術來提高訓練效率。
RLVR在推理語言模型中的應用
RL數據集
DeepSeek-R1-Zero通過獨立的RLVR流程在推理和知識任務中取得了優異表現。其RLVR過程中使用的高質量精選數據集是成功的關鍵。
因此,多項複製研究探索瞭如何利用開源數據和強大模型高效創建訓練數據集的策略。
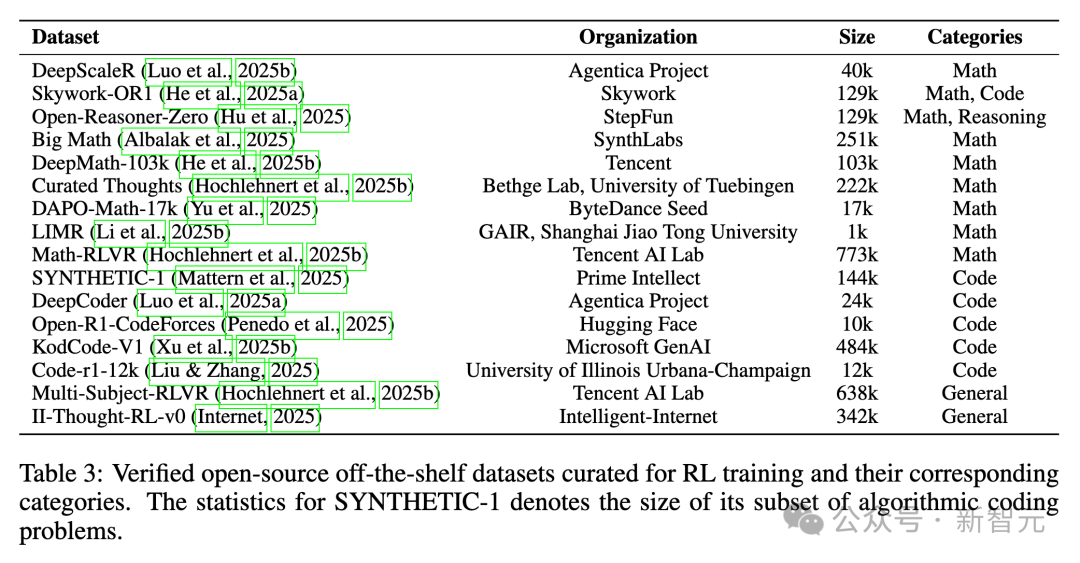
這些數據集涵蓋R訓練中可驗證的多種任務,主要聚焦於數學和編程問題解決的數據集。表3提供了這些數據集的統計概覽。
RL組件
隨着DeepSeek-R1-Zero和DeepSeek-R1的發布,DeepSeek展示了通過強化學習(RL)微調LLM以應對複雜推理任務的成功經驗。
基於精心挑選的訓練數據,相關研究主要集中在配置RL框架的關鍵部分,以實現卓越性能:採用高效的RL算法(如GRPO)以及設計獎勵機制。
表4提供了這些研究方法的比較。
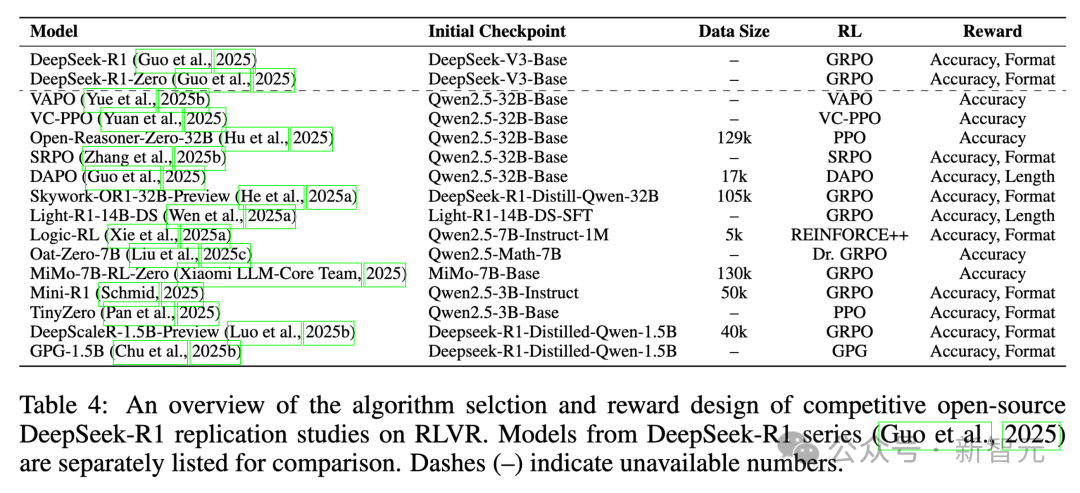
表4總結了多個競爭性開源 DeepSeek-R1 複製研究在強化學習驗證任務(RLVR)中使用的算法和獎勵設計方案。為了便於比較,DeepSeek-R1 系列模型的相關信息被單獨列出
在基於結果-獎勵的RL方法中,PPO和GRPO是最常用的微調大語言模型的算法。
有趣的是,近期的一些複製研究對這些方法進行了各種改進,針對特定目標優化了訓練效果。
研究團隊回顧了幾種代表性的基於RL的大語言模型微調算法,包括 REINFORCE、PPO、GRPO及其變體。此外,他們還梳理了這些方法的改進及其背後的動機,旨在清晰概述基於結果-獎勵的RL訓練方法的技術進步。
獎勵機制
獎勵是RL訓練的核心,因為它定義了優化的目標,引導模型的行為。
一個設計良好的獎勵機制能提供清晰、一致的信號,幫助模型學習到有效的策略。
然而,獎勵模型常常容易被「獎勵欺騙」(reward hacking,指模型通過鑽空子獲得高分而非真正解決問題),因此近期研究更傾向於使用基於規則的結果獎勵系統。
這些系統通常分為三類:
準確性獎勵:準確性獎勵評估回答是否正確,通常給正確回答打 1 分,錯誤回答打 0 分或 -1 分。
格式獎勵:格式獎勵鼓勵回答遵循預定義的結構或推理格式,通常給正確格式打 1 分,偏離格式則打 0 分或 -1 分。
長度獎勵:長度獎勵影響模型回答的詳盡程度。一些方法獎勵生成特定長度的回答,而另一些方法則鼓勵在保證準確性的前提下儘量簡潔。
採樣策略
直觀來說,在訓練過程中合理選擇樣本對RL的有效性至關重要。
一方面,課程學習方法通過逐步增加任務難度,提高了複雜樣本的利用率。另一方面,合理使用拒絕採樣技術可以提升樣本效率並穩定訓練。
RLVR在其他任務上的應用
通過RLVR,DeepSeek-R1的複雜推理能力顯著增強,在複雜語境理解和問題解決等推理密集型任務中取得成功。
RLVR使大模型能夠在無需人工指導的情況下,通過可驗證的答案學習和執行任務,激發其複雜推理能力。
受此啓發,多項研究探索了RLVR在不同任務中的複雜推理範式。
邏輯推理:TinyZero和Mini-R1嘗試在倒計時遊戲中重現DeepSeek R1的「靈光一現」時刻,使用簡單的基於規則的獎勵系統。
面向應用的實際任務:推理語言模型需要通過思考、規劃和反思來學習處理現實世界的應用型任務。
超越監督的探索:通過強化學習過程,研究發現大模型展現出了令人驚喜且意想不到的能力。
這些結果凸顯了複雜推理語言模型通過RL訓練策略,超越監督數據資源甚至人類能力的潛力。
更多發展方向
雖然DeepSeek-R1的成功推進了RLMs的訓練,但仍有許多監督策略有待探索。
推理增強的替代方法 :旨在解決傳統 RLVR 在捕捉中間步驟和對齊人類期望方面的侷限性。
主要方向包括:
過程級獎勵建模 (Process-level Reward Modeling, PRM):對推理的中間步驟提供反饋,而非僅評估最終結果。例如rStar-Math使用過程偏好模型和自我演進,PRIME使用隱式PRM,僅依賴結果標籤進行訓練,更具可擴展性並減少獎勵欺騙。
偏好優化策略 (Preference Optimization):特別是 直接偏好優化 (Direct Preference Optimization, DPO),相比PPO或GRPO計算資源需求更少。一些研究探索使用DPO提升推理能力,如Light-R1、Iterative DPO、RedStar、DPO-R1。
泛化性:RLMs在學習推理能力時,能夠很好地泛化到域外任務。
持續預訓練(例如在數學領域)能顯著增強專業和通用推理能力。
監督微調 (SFT) 通過提供高質量示例和結構化歸納先驗,對泛化能力至關重要,為後續強化學習奠定穩定基礎。精心策劃的高質量數據尤為重要。
強化學習 (RL) 展示了強大的域外泛化潛力,甚至超越了模仿學習。經過RL訓練的模型可以在不同任務、語言和模態上泛化,例如Llama3-SWE-RL和RL-Poet。像AGRO這樣整合On-policy和Off-policy經驗的方法可以增強泛化能力。
安全性 :推理語言模型面臨一些安全挑戰,包括過度思考(生成過長推理鏈,增加成本,可能忽略環境反饋) 和獎勵欺騙(模型利用獎勵函數的漏洞或模糊性獲取高分)。
自我演進過程引入了失控和未對齊的風險。
越獄攻擊 (Jailbreaking) 是一個普遍關注的問題。推理增強的模型可能會犧牲安全性(「安全稅」)。
應對措施包括改進算法設計、訓練策略、對齊安全策略以及開發具有推理能力的防護模型。
多模態和多語言:
多模態推理語言模型:整合視覺、音頻等多種模態。當前多模態模型的推理能力通常弱於單模態模型。將單模態推理能力遷移到多模態是前景廣闊但具有挑戰性的方向。
多語言推理語言模型:主要挑戰在於某些語言資源的有限性。在英語中訓練的推理能力向其他語言泛化程度有限。可能需要專門的能力來促進跨語言的洞察或「頓悟」。未來的研究需要專注於更高效的跨語言訓練策略,特別是針對低資源語言。
結論
在本文中,研究團隊全面概述了受DeepSeek-R1啓發而進行的復現工作,特別重點關注了其背後的監督微調和強化學習方法。
他們探討了開源項目如何整理指令微調數據集,如何實現基於結果獎勵的強化學習策略,以及如何設計旨在增強模型推理能力的獎勵系統。
除了總結當前各項工作的趨勢之外,還對該領域未來充滿希望的方向提出了自己的看法。這些方向包括將推理技能擴展到數學和編程任務之外,提升模型的安全性和可解釋性,以及改進獎勵機制以促進更復雜的推理行為。
團隊希望本次綜述不僅能捕捉到近期進展,還能為正在進行的研究提供堅實的基礎,並標誌着向實現通用人工智能邁出了更進一步。
參考資料:
https://arxiv.org/abs/2505.00551