
今年 3 月,英偉達 2025 春季 GTC 大會,理想汽車自動駕駛技術研發負責人賈鵬在台上介紹了他們的最新成果:MindVLA 大模型。
這是一個擁有 22 億參數的視覺-語言-動作(Vision-Language-Action Model,VLA)模型,賈鵬進一步介紹稱,他們已經成功將該模型部署於車端。在理想看來,VLA 模型是解決 AI 與物理世界交互難題最有效的方法。
在過去的一年裏,端到端架構成為智能駕駛領域的技術熱點,推動車企從傳統的分模塊規則設計轉向一體化系統。曾憑藉規則算法領先的車企面臨轉型陣痛,而後發者則抓住了彎道超車的機會。
理想便是其中的代表。
理想去年在智能駕駛上的進步可謂飛快,7 月份就率先實現了全國無圖 NOA(導航輔助駕駛),還推出了獨特的「端到端(快系統)+VLM(慢系統)」架構,受到行業廣泛關注。

今晚,隨着理想 AI Talk 第二季進行,我們對李想口中的「人工智能公司」有了更深的了解。
是「司機大模型」,也是你的司機
理想汽車 CEO 李想第一次提到 VLA,是在去年 12 月的與騰訊新聞科技主筆張小珺對談的 AI Talk 第一季上。當時他說:
我們在做的理想同學和自動駕駛,按照行業的標準其實是分割開的,處於早期階段。我們做的 Mind GPT,其實是大語言模型;我們在做的自動駕駛,我們自己內部叫行為智能,但是像李飛飛(斯坦福終身教授、前 Google 首席科學家)的定義,叫空間智能。只有你真正大規模去做的時候,你才知道,這兩個之間,有一天一定會連在一起,我們自己內部叫 VLA(Vision Language Action Model,視覺語言行動模型)。
李想認為,基座模型到一定時刻一定會變成 VLA。原因在於,語言模型只能通過語言和認知去理解三維的世界,這是顯然不夠的。「它需要真正向量的,用 Diffusion(擴散模型)的方式,用生成的方式(去認識世界)」。
可以說,VLA 的誕生,既是對語言智能和空間智能深度結合的一次大膽嘗試,也是理想汽車對「智能汽車」概念的一次重新詮釋。

李想在今晚的 AI Talk 中進一步定義:「VLA 是一個司機大模型,像人類的司機一樣去工作。」它不僅是一項技術,更是一個能與用戶自然溝通、自主決策的智能夥伴。
那麼,VLA 究竟是什麼?核心其實非常直白:通過整合視覺感知、自然語言理解和動作生成能力,讓車輛變成一個能與人溝通、能自己做決定的「司機 Agent」。

▲ 導航走 ETC 時,駕駛員可以直接命令系統走人工通道(輔助駕駛開啓狀態)
想象一下,你坐在車裏,隨口說一句「今天有點累,開慢點吧」,車輛不僅能聽懂你的意思,還會調整速度,甚至選擇一條更平穩的路線。這種自然流暢的交互,正是 VLA 想要實現的。李想透露,所有的短指令,都有由車端直接處理,複雜指令則交由雲端 32 億參數模型解析,確保高效與智能兼得。

實現這樣的目標並不容易。VLA 的特別之處在於,它把視覺、語言和動作三個維度打通了。用戶的一個簡單指令背後,可能涉及到對周圍環境的實時感知、對語言意圖的精準理解,以及對駕駛行為的快速調整,三者缺一不可。
而 VLA 的厲害之處就在於,它能讓這三者無縫協作。
從願景到現實,VLA 的研發是一片無人區。李想坦言:「視覺和動作數據的獲取最為困難,沒有公司能替代。」
要理解 VLA 的技術底色,還得看看理想汽車在智能駕駛上的演進脈絡。
李想表示,早期的系統是「昆蟲級別」智能,僅有百萬參數,靠規則和高精地圖驅動,遇到複雜路況就束手無策。後來,端到端架構和視覺-語言模型讓技術躍升至「哺乳動物級別」,擺脫地圖依賴,全國無圖 NOA 成為現實。
實際上,這一步已經讓理想汽車走在了行業前列,但他們顯然不滿足於此。在李想看來,VLA 的出現,標誌着理想汽車的智能駕駛技術邁入了「人類智能」的新階段。

相比之前的系統,VLA 不僅能感知 3D 物理世界,還能進行邏輯推理,甚至生成接近人類水平的駕駛行為。
舉個簡單的例子,假設你在一條擁堵的街道上說「找個地方掉頭」,VLA 不會機械地執行指令,而是會綜合路況、車流和交通規則,找到一個最合理的時間和位置完成掉頭。
李想表示,VLA 能通過生成數據快速適應新場景,哪怕初次遇到複雜修路,三天內也能優化應對。這種靈活性和判斷力,正是 VLA 的核心優勢。
理想的老師,是 DeepSeek
支撐 VLA 的,是理想汽車自研的一套複雜而精妙的技術體系。這套體系讓汽車不僅能「看懂」世界,還能像人類司機一樣思考和行動。
首先是 3D 高斯表徵技術,即用很多個「高斯點」來拼出一個 3D 物體,每個點都含有自己的位置、顏色和大小等信息。這項技術通過自監督學習,利用海量真實數據訓練出一個強大的 3D 空間理解模型。有了它,VLA 就能像人一樣「看懂」周圍的世界,知道哪裏是障礙物,哪裏是可通行區域。

▲當記憶車位被佔,系統會自動尋找其他車位。還能聽懂駕駛員指令,通過牆上的指示牌找到「C3 區」
接着是混合專家架構(MoE),該架構由專家網絡、門控網絡和組合器組成。當模型參數超過千億級別時,傳統方法會讓所有神經元參與每個計算,比較浪費資源,MoE 架構中的門控網絡會根據任務的不同調用不同的專家,保證激活參數不會大幅增加。
聊到這裏,李想還順帶誇了一下 DeepSeek:
DeepSeek 運用了人類的最佳實踐…… 他們在做 DeepSeek V3 的時候,其實 V3 也是一個 MoE 的,671B 的一個模型。我覺得 MoE 是個非常好的架構。它相當於把一堆專家組合在一起,然後每一個是一個專家能力。
最後,理想為 VLA 引入了稀疏注意力機制(Sparse Attention) ,說人話就是 VLA 會自動調整關鍵區域的注意力權重,從而提升端側的推理效率。
李想表示,在這個新的基座模型訓練過程中,理想的工程師們花了很多時間去找到最佳的數據配比,融入了大量 3D 數據和自動駕駛相關的圖文數據,並減少了文史類數據的比例。
從感知到決策,VLA 借鑑了人類思維的快慢結合模式。它既能快速輸出簡單的動作決策,比如緊急避讓,也能通過短思維鏈進行「慢思考」,應對更復雜的場景,比如臨時規劃一條繞開施工區域的路線。為了進一步提升實時性,VLA 還引入了投機推理和並行解碼技術,充分利用車端芯片的算力,確保決策過程快而不亂。
在生成駕駛行為時,VLA 用到了 Diffusion 模型和基於人類反饋的強化學習(RLHF)。Diffusion 模型負責生成優化的駕駛軌跡,而 RLHF 則讓這些軌跡更貼近人類習慣,既安全又舒適。比如,VLA 會在轉彎時自動減速,或者在併線時留出足夠的安全距離,這些細節都體現了對人類駕駛行為的深度學習。

世界模型是另一關鍵技術,理想通過場景重建和生成,為強化學習提供了高質量的虛擬環境。李想透露,世界模型將驗證成本從每萬公里 17-18 萬元降至 4000 元。它讓 VLA 在模擬中不斷優化,應對複雜場景如履平地。
說到訓練,VLA 的成長過程也頗有章法。整個流程分為三個階段:預訓練、後訓練和強化學習。「預訓練像學習知識,後訓練像駕校學車,強化學習像社會實踐。」李想說。
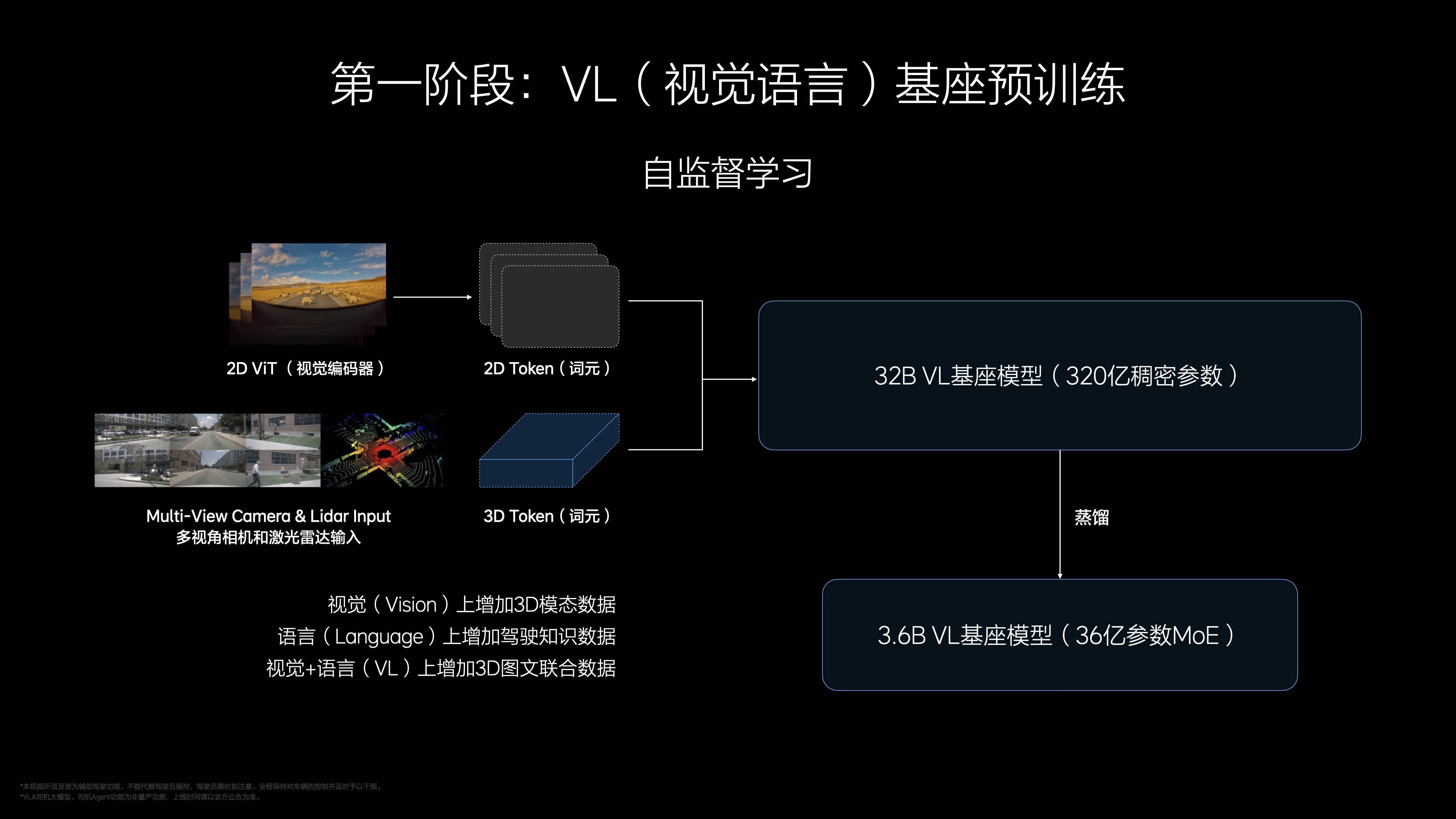
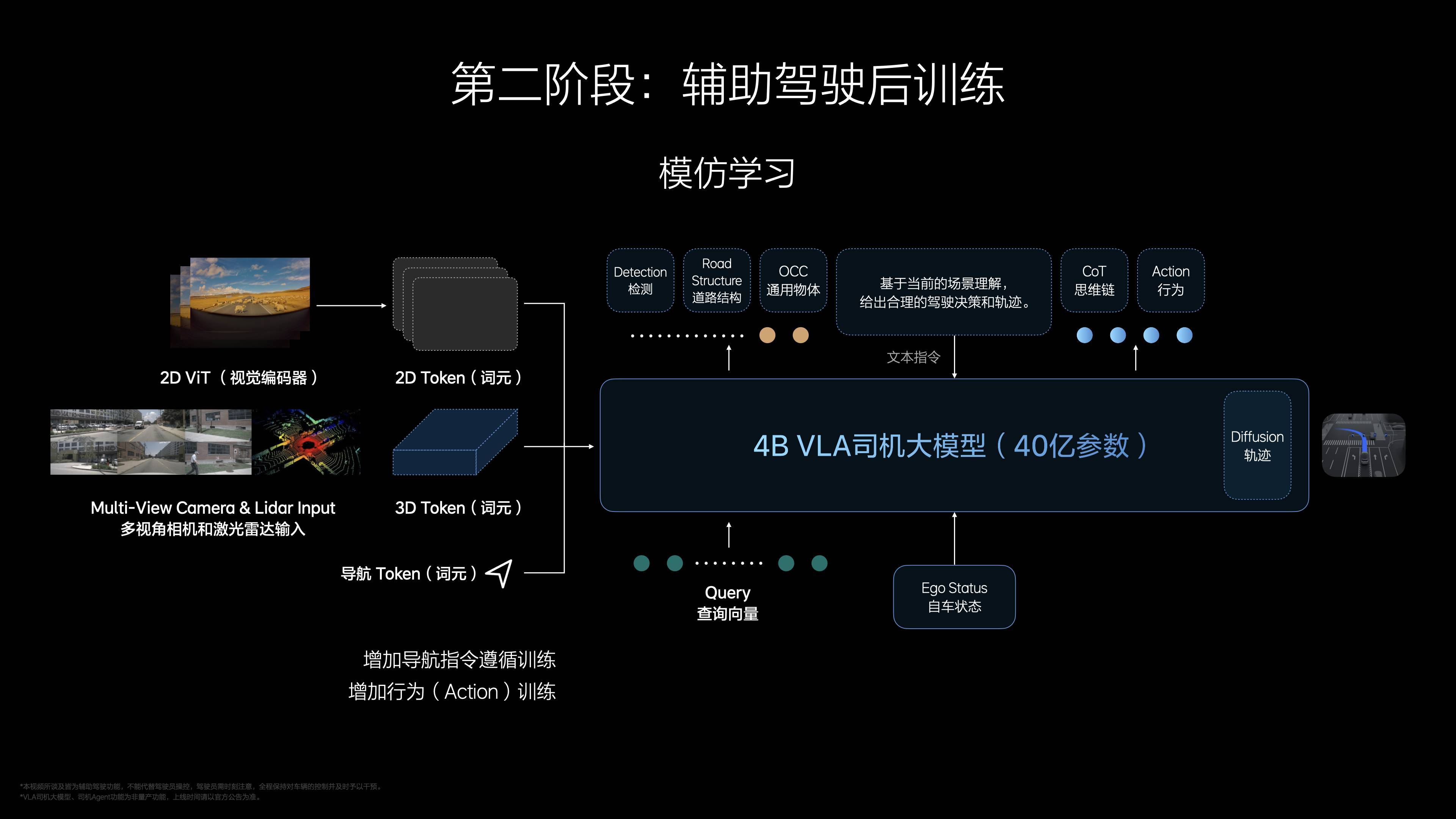
預訓練階段,理想汽車為 VLA 打造了一個視覺-語言基座模型,塞進了豐富的 3D 視覺數據、2D 高清影像和駕駛相關的語料,讓它先學會「看」和「聽」;後訓練加入動作模塊,生成 4-8 秒駕駛軌跡,模型從 3.2 億參數蒸餾到 4 億。
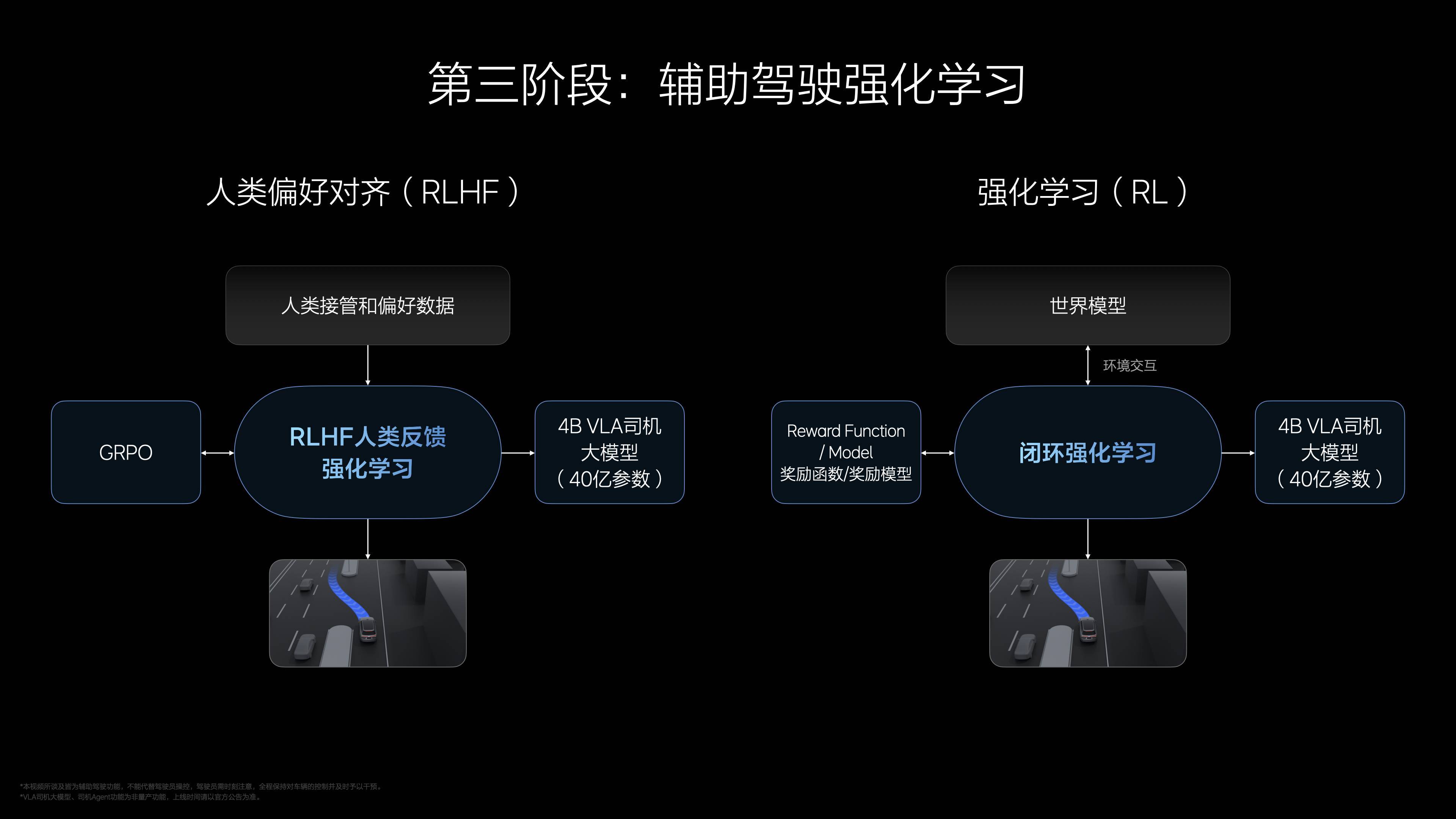
強化學習分為兩步:先用 RLHF 對齊人類習慣,分析接管數據,確保安全舒適;再用純強化學習優化,基於 G 值(舒適性)、碰撞和交通規則反饋,讓 VLA「開得比人類更好」。李想提到,這一階段在世界模型中完成,模擬真實交通場景,效率遠超傳統驗證。
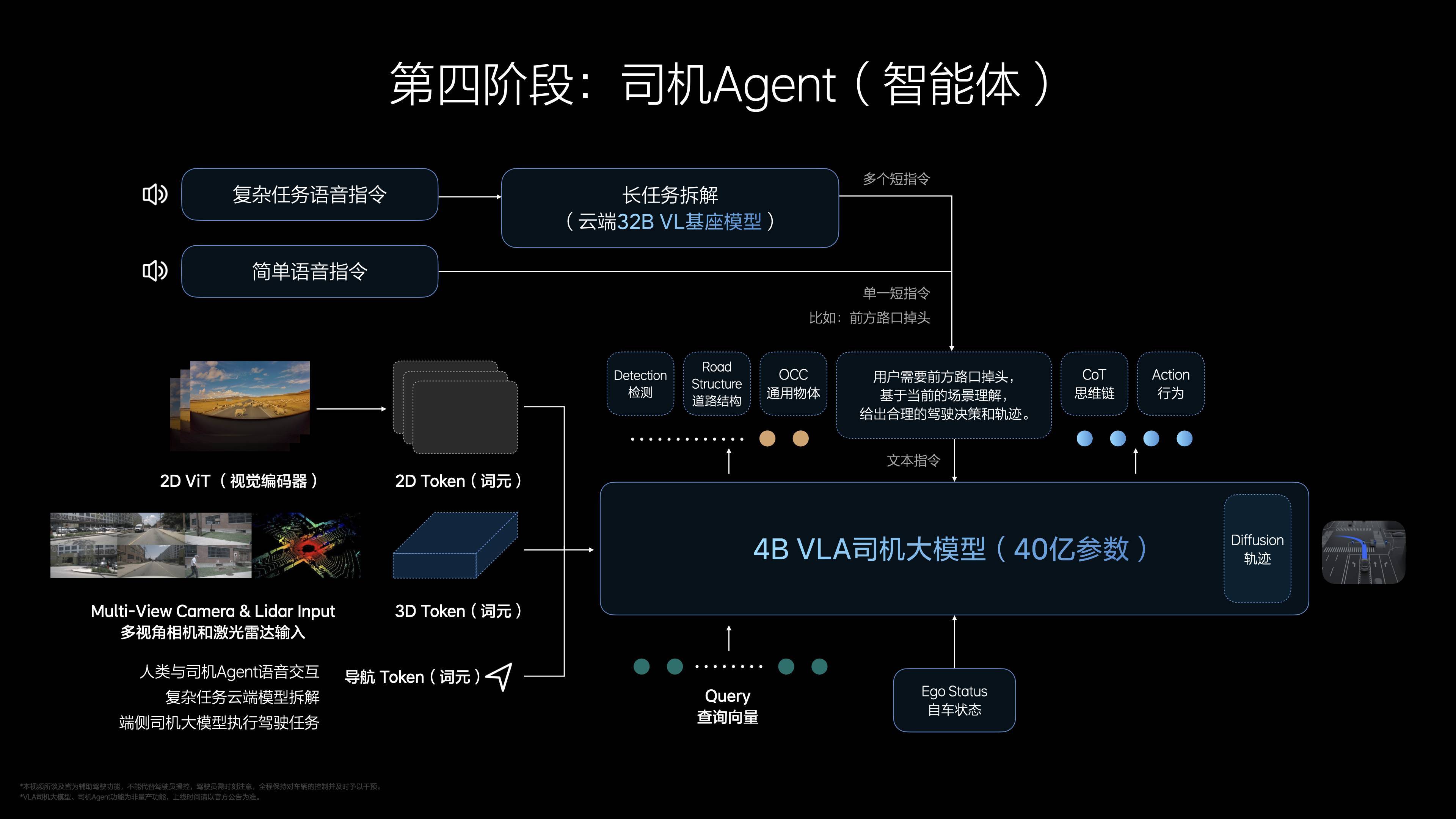
這樣的訓練方式,既保證了技術上的先進性,也讓 VLA 在實際應用中足夠可靠。
李想坦言,VLA 的成功離不開行業標杆的啓發。DeepSeek 的 MoE 架構不僅提升了訓練效率,還為理想提供了寶貴經驗。他感慨:「我們站在巨人的肩膀上,加速了 VLA 的研發。」這種開放學習的態度,讓理想在無人區中走得更遠。
從「信息工具」到「生產工具」
當下,AI 行業正經歷一場從「信息工具」到「生產工具」的深刻變革。隨着大模型技術的成熟,AI 不再侷限於處理數據和提供建議,而是開始具備自主決策和執行任務的能力。
李想在 AI Talk 第二季中提出,AI 可分為信息工具(如搜索)、輔助工具(如語音導航)和生產工具。他強調:「人工智能變成生產工具,纔是真正爆發的時刻。」隨着大模型技術成熟,AI 不再侷限於處理數據,而是開始具備自主決策和執行任務的能力。
這種趨勢,在「具身智能」概念中體現得尤為明顯——AI 系統被賦予物理實體,能夠感知、理解並與環境互動。

理想汽車的 VLA 模型正是這一趨勢的生動實踐。它通過整合視覺、語言和動作智能,將汽車打造成一個能夠自主駕駛、與用戶自然交互的智能體,完美詮釋了「具身智能」的核心理念。
只要人類會僱佣專業司機,人工智能就能成為生產工具。當 AI 成為生產工具時,人工智能纔會真正爆發。
李想的這段話,點明瞭 VLA 的核心價值——它不再是簡單的輔助工具,而是能夠獨立執行任務、承擔責任的「司機 Agent」。這種轉變,不僅提升了汽車的實用價值,也為 AI 在其他領域的應用打開了想象空間。
李想對 AI 的思考,總是帶着一種跳出框框的視角。他還提到:「VLA 不是突變的過程,是進化的過程。」這句話精準概括了理想汽車的技術路徑——
從早期的規則驅動,到端到端的突破,再到如今 VLA 的「人類智能」水平。這種進化思維,不僅讓 VLA 在技術上更具可行性,也為行業提供了可借鑑的範式。相比一些一味追求顛覆的嘗試,理想的務實路徑或許更適合複雜的中國市場。
從技術到信念,理想的 AI 探索並非坦途。李想坦言:「我們在 AI 領域經歷了很多挑戰,就像黎明前的黑暗,但我們相信,堅持下去就會看到光。」VLA 的研發面臨算力瓶頸、數據倫理等難題,但理想通過自研基座模型和世界模型,逐步迎來了屬於他們的技術曙光。
李想在採訪中還提到,VLA 的成功離不開中國 AI 的崛起。
他表示,DeepSeek、通義千問等模型的出現讓中國 AI 水平迅速接近美國。其中,DeepSeek 所秉持的開源精神尤為令人振奮,它直接直接促使理想開源星環 OS。李想稱:「這不是出於公司戰略考量,DeepSeek 給我們那麼大幫助,我們應該為社會貢獻點什麼。」

在追求技術突破的同時,理想汽車並未忽視 AI 技術的安全性和倫理問題。VLA 引入的「超級對齊」技術,通過基於人類反饋的強化學習(RLHF),讓模型的行為更貼近人類習慣。數據顯示,VLA 的應用使高速 MPI(平均干預里程)從 240km 提升至 300km。
更重要的是,理想汽車強調打造「有人類價值觀的 AI」,將道德和信任視為技術發展的基石。從更宏觀的視角看,VLA 的意義還在於,它重新定義了車企這一角色。
過去,汽車是工業時代的交通工具;如今,它正在演變為人工智能時代的「空間機器人」。李想在 AI Talk 中提到:「理想以前走的是汽車的無人區,以後走的是人工智能的無人區。」理想的這種轉變,為汽車行業的商業模式帶來了新的想象空間。
當然,VLA 的發展並非沒有挑戰。算力的持續投入、數據倫理以及消費者對自動駕駛的信任建立,都是理想汽車需要面對的課題。此外,AI 行業的競爭日趨激烈,國內外巨頭如特斯拉、Waymo 和 OpenAI 都在加速佈局多模態模型,理想需要在技術迭代和市場推廣上保持領先。「我們沒有捷徑,只能深耕。」李想說。
毫無疑問,VLA 的落地將是關鍵節點。
理想汽車計劃在 2025 年 7 月與純電 SUV 理想 i8 同步發布 VLA,並在 2026 年實現量產。這不僅是對技術的一次全面檢驗,更是市場的一塊重要試金石。