
編輯:Aeneas 好睏
絕了,啱啱曝出大瓜:去年MIT博士生一篇轟動一時的論文,很大可能是造假,目前已被MIT要求撤稿!他的造假水平高到什麼程度?連諾貝爾經濟學獎得主大牛導師都被騙過了。現在,導師已正式割席,大義滅親。
去年,一篇MIT二年級博士的論文一經發表,立馬驚豔了學術圈。
這篇論文通過調查一個研究材料科學的大型實驗室,用詳實的數據展示出,使用AI工具的科學家,如何獲得了大幅的生產力提升。
甚至作者還發現,使用AI進行科學研究,產生了有趣的二級效應。

論文地址(發稿時還在):https://arxiv.org/abs/2412.17866
當時,這項研究不僅登上了各大媒體的頭版,更是得到了圈內人的大量好評——「這是迄今為止關於AI對科學發現影響的最佳論文」。
|
|


甚至,作者還將論文提交給了全球最頂級的經濟學期刊之一——「The Quarterly Journal of Economics」。並且表示,自己已經收到了「修改並重新提交」的通知。
這意味着,文章很可能即將發表。
結果,就在啱啱,這篇論文的導師——諾貝爾經濟學獎得主Daron Acemoglu以及David Autor教授突然「大義滅親」,公開請求撤稿。
原因是,其中的寶貴數據,很可能是作者僞造的!

現在,MIT Economics官網上已經發布正式公告,請求arXiv正式撤稿。
網友們也調侃起論文作者的導師:我們不要盲目相信高被引諾獎經濟得主的判斷。

MIT請求撤稿,導師大義滅親
MIT官網表示,24年11月的這篇預印本論文發布於arXiv之後,可信性引起了質疑。
MIT已經展開了內部保密審查,得出結論——論文必須撤回。因此,MIT正式聯繫了arXiv和經濟學頂刊,要求撤回該論文。

此前,MIT就已經讓這名學生去申請撤稿了,但學生並沒有聽話。
甚至,學校着重強調,論文作者目前已經離校,不屬於MIT。
其實,這篇論文在去年底發表後,立刻聲名大噪,隨即就引起不少質疑。
隨着質疑聲越來越大,論文作者的導師也開始發現不對勁了。
他們選擇將此事上報,於是學校開始了內部審查。

David Autor和Daron Acemoglu
最終,學生在論文中致謝的這兩位教授,聯合發表了聲明——
MIT經濟系一名前二年級博士生的論文「Artificial Intelligence, Scientific Discovery and Product Innovation」,儘管尚未在任何經同行評審的期刊上發表,但已在AI與科學領域廣為人知並被廣泛討論。
雖然學生隱私法和麻省理工學院的政策禁止披露保密審查的結果,但我們希望明確指出,我們對這些數據的來源、可靠性或有效性,以及該研究的真實性,均缺乏信心。
我們希望藉此澄清事實,並表明我們的觀點:在現階段,學術界或公衆在討論這些議題時,不應採信該論文所報告的研究結果。
全文如下:

上下滑動查看
AI讓新材料發現暴增44%?編的
要知道,在去年年底,這篇文章發表時,可是引起了不小的轟動。
作者提出的許多觀點,實在是振奮人心:
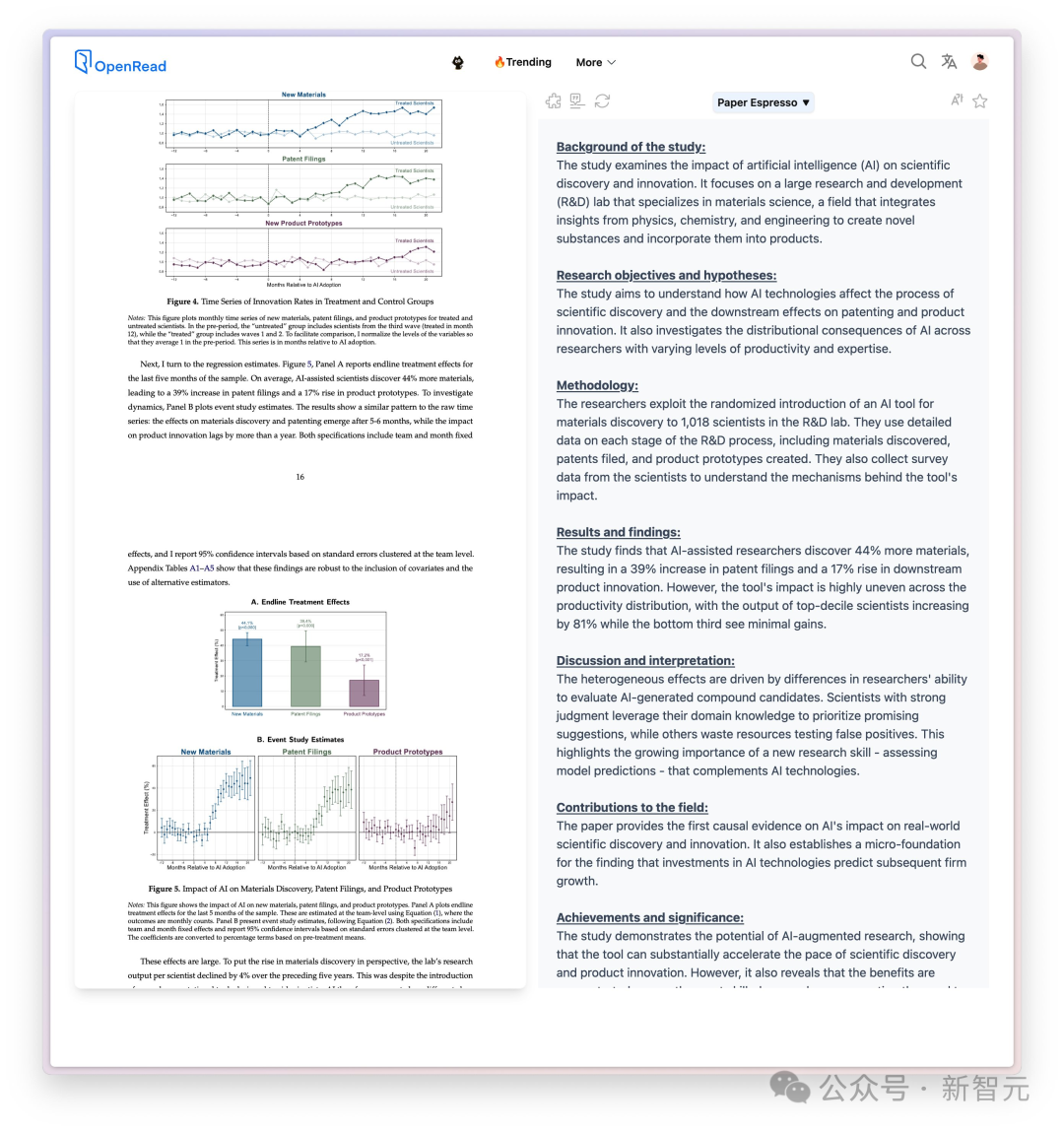
· AI正以驚人的速度推動新發現,直接讓研究人員發現的材料數量增加了44%,專利申請量增加了39%,下游產品創新量增加了17%。
· AI對生產力分佈的影響極不均衡,排名前1/10的科學家的產出增長了81%,而排名後1/3的科學家的產出增長卻微乎其微。
· 對於表現最佳的人,AI充當了共同智能,放大了他們的創造力和產出。

論文作者Aidan Toner-Rodgers
沃頓商學院教授Ethan Mollick也轉發了這篇論文。
讀者們表示,這項研究太棒了!非常歡迎這種研究大模型對於科研影響的論文。
可是如今卻要告訴大家,這篇論文竟是靠數據造假得來的?
事情鬧得這麼大,曾以題為「The Scientist vs. the Machine」的文章對此事進行報道的大西洋周刊撰稿人,也在線喫起了瓜。



UCL教授去年就曾提出質疑
其實,去年11月這篇論文一經發表,就已經有專業人士感覺到不對了。
這篇論文的造假嫌疑很大,很多人懷疑,為何此人的導師竟然讓這篇論文通過。
倫敦大學學院無機與材料化學教授Robert Palgrave,當時就公開懷疑:論文中的觀點,很多根本就站不住腳,極其不嚴謹!

隨後,他展開抽絲剝繭的分析。
這篇論文研究的是一家匿名的美國大公司在無機材料發現上的工作。在這家公司中,有超過1000名科學家在尋找新材料,尤其是醫療保健、光學和工業製造領域。
但是論文中,有重重疑點。
比如作者提到,該實驗室從2022年就開始使用AI了。他們是多有前瞻性,才能在22年就設立一個多年的、有1000多名被試的隨機對照實驗?
而且,作者竟然能查閱實驗室員工的記錄本,這有多大的可能?
而且論文的具體細節,也有很多可疑之處。
第一個問題,實驗室究竟在研究什麼類型的材料?
文中沒有詳細說明,但提到說無機材料是重點,包括生物材料、陶瓷和玻璃、金屬和合金以及聚合物。
這就奇怪了。
比如教授表示,自己不認為論文中的方法,可以將生物材料進行原子化的模擬。
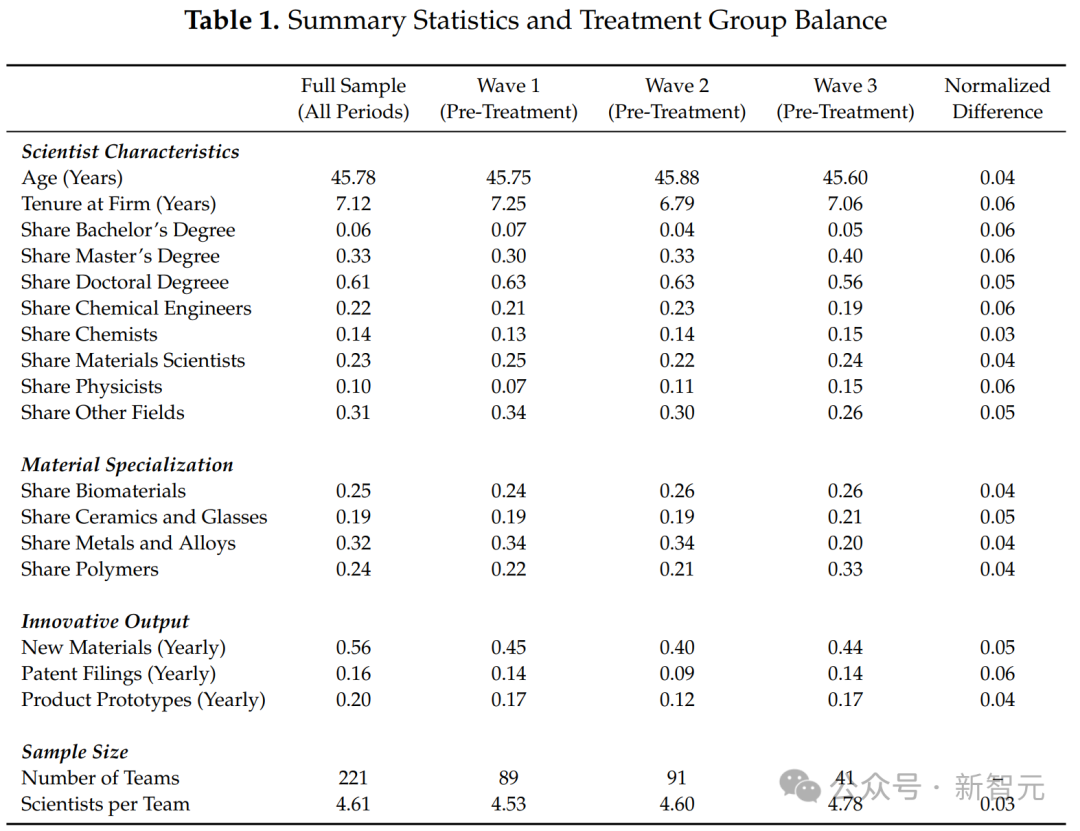
陶瓷和玻璃可能包含大量的無序結構,這種結構也很難以高通量的方式進行建模,這是谷歌Deepmind的首篇材料學論文失敗的原因。
金屬和合金也是同理,它們是大量無序的,很難建模。
聚合物倒是有可能以這種方式建模,但如果要獲得晶體結構,也是很難的一件事。
第二個問題,論文是用SOAP方法,來評估新材料是否出現在了已有數據庫中,作者使用的數據庫是Materials Project和Alexandra。
然而,他們卻並不包括實驗結構,所以作者並沒有跟真實的材料進行比較,只是在跟之前的計算結果進行比較。
在這裏,作者使用的判斷方法並不嚴謹。
甚至,作者使用的SOAP方法,還被詭異地修改過了。
「第二項對更靠近質心的原子增加了額外權重,這反映了中心原子更能預測材料屬性的事實。」
論文中的這一句,前提本身就是錯誤的。因為這些材料都是周期性結構,沒有中心。
總之,這種新穎性指標,根本就不令人信服。

論文似乎在將AI幫助研究者發現了新材料,但如何驗證,這種預測跟實際生產的材料相同呢?
另外,論文中只講瞭如何將AI整合到實驗流程中,但關於驗證AI是否提供了實際有用的結果,卻幾乎沒提。
最後,教授還是口下留情,讚美說這篇論文引人入勝,付出了巨大努力。也繼續強調了「華點」:一個學生如何在一家大公司展開如此廣泛的研究?

現在回看,這位教授果然不愧是專業人士。
畢竟外行看熱鬧,內行看門道。在真正專業的火眼金睛前,造假的行為總會露出蛛絲馬跡,無可遁逃。
假的就是假的,真不了。
AI、材料、欺詐
同時,Robert Palgrave教授也分享了另一篇詳細扒皮文,出自材料科學家Ben之手。
讓我們跟着這位大佬一起看看,論文的「雞腳」是從哪裏露出來的。

具體來說,這篇文章分析了一項隨機試驗的數據,其中涉及一家美國公司研發實驗室的一千多名材料研究人員。
作者Toner-Rodgers熟練地追蹤了這些AI工具的使用對以下方面的影響:
研究人員發現的材料數量
這些新材料申請的專利數量
基於這些新材料開發的新產品原型數量
研究人員在實驗、判斷和構思之間的時間分配隨時間的變化
研究人員在採用AI工具前後對AI的態度
不僅這些指標中的每一個都顯示出非常清晰的效果,而且作者還運用了幾乎所有能想到的方法來探索它們。其中不乏一些非常複雜的方法論:
他通過一個非常精密的算法計算新材料的質量。這種算法測量的是每種發現的材料與「目標」屬性之間的距離。
他通過計算原子位置的差異來測量新材料的晶體結構與現有材料的結構相似性。即使對於材料科學家來說,這也是非常困難的,更不用說經濟學家了!
他使用二元語法分析來確定專利的新穎性。
他使用一個LLM(Claude 3.5)來自動分類研究任務。
數據好看得不像話
第一個本應亮起的紅燈,是數據來源本身。
這是一家美國公司,僅材料發現領域就擁有(至少)1018名研究人員,數量驚人。這就將範圍縮小到少數幾家公司,比如蘋果、英特爾和3M。
然而,論文所列出的研究人員在材料專業方向的細分情況,卻非常奇怪。
因為很少有公司會進行大規模的材料研究,而且這些研究還相當均勻地分佈在各種材料領域,涉及生物材料和金屬合金等截然不同的領域。

經過實際調研之後可以發現,沒有一家現實中的公司能完美匹配這個數據,尤其是在金屬和合金領域佔有32%份額這一點上。
對此,有兩種可能的情況:
1. 確實有一家研發實驗室提供了數據,但作者進行了篡改
2. 數據從一開始就完全是捏造的
相比之下,第二種的可能性更高,原因是:
像這樣的大公司為什麼要費盡周折對自己的員工進行隨機試驗,追蹤他們績效的多個指標,然後卻把這些數據匿名提供給一位MIT的研究員,而不是自己發表研究成果?而且,這個人還只是一名博士一年級的學生。
即使在那些大型研發公司裏,也只會有一小部分研究人員致力於「材料發現」這項任務。一家公司以如此結構化的方式對一千多名員工進行AI應用實驗,可能性實在不大。
對這些員工所做任務的描述、領域之間的劃分以及所有其他提供的信息,看起來都過於完美。真正的公司不會有數百個研發團隊各自從事類似的任務,規模相近,並且都追蹤相同的指標。這讀起來就像是一名只讀過Top 1%經濟學創新研究論文的學生,對於研發實驗室運作方式的想象。
下一個本應亮起的紅燈,是「完美無瑕」的研究結果。
在探索的每個領域,都有一個相當明確的結果:
新材料?增加了44%(p<0.000)
新專利?增加了39%(p<0.000)
新原型?增加了17%(p<0.001)
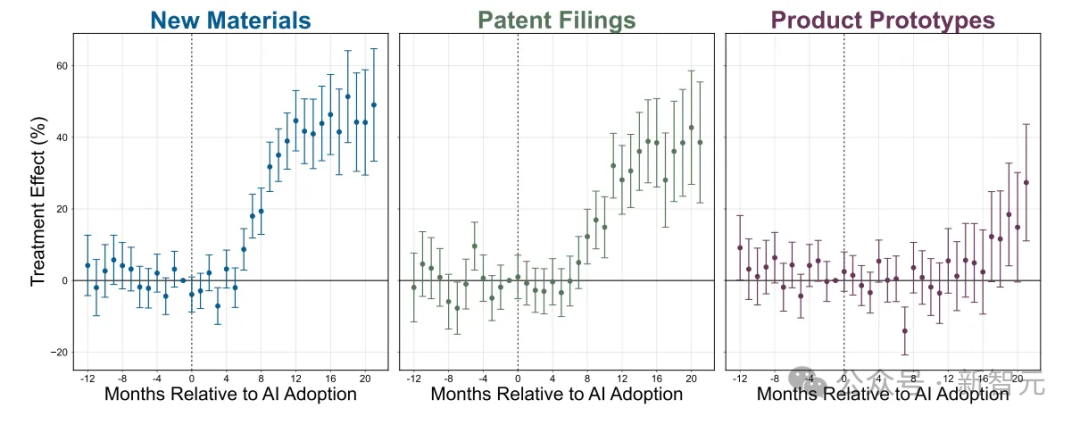
新材料的質量?提升了,並且具有統計顯著性。
新材料的新穎性?提升了,並且具有統計顯著性。
那些先前更有才華的研究人員在使用AI工具後進步更大嗎?是的。
這些結果是否反映在研究人員對其時間分配的自我評估中?是的。
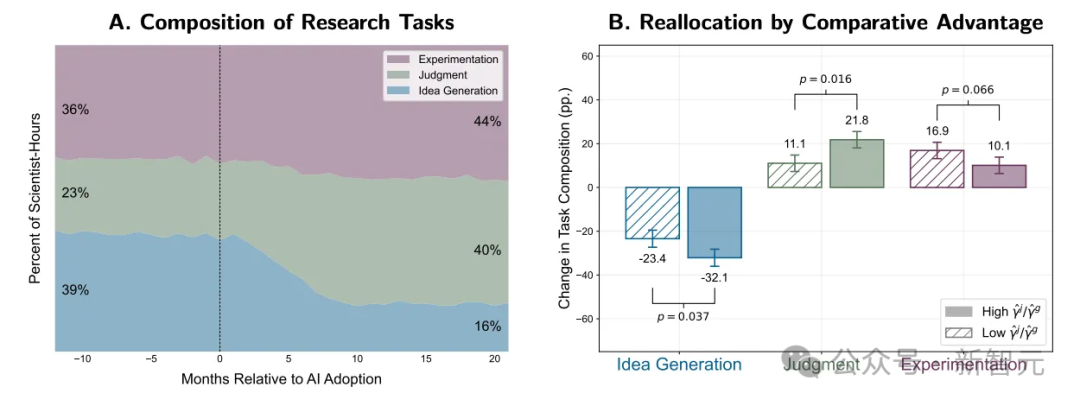
最後的圖表,更是堪稱每個經濟學家的夢想——完美體現了比較優勢原則的生效過程:
類似的,其他圖表看起來也都非常的刻意和規整。
比如下面這張表,展示的就是研究人員對自己判斷能力的自我評估,同他們在調查中對「不同知識領域在AI材料發現中所起作用」的反饋之間,是否存在關聯。
可以看到,四類中有三類顯示出規整的增長,另一類則保持不變(而這一類從基本原理來看似乎本就無關緊要,即使用其他AI評估工具的經驗)。
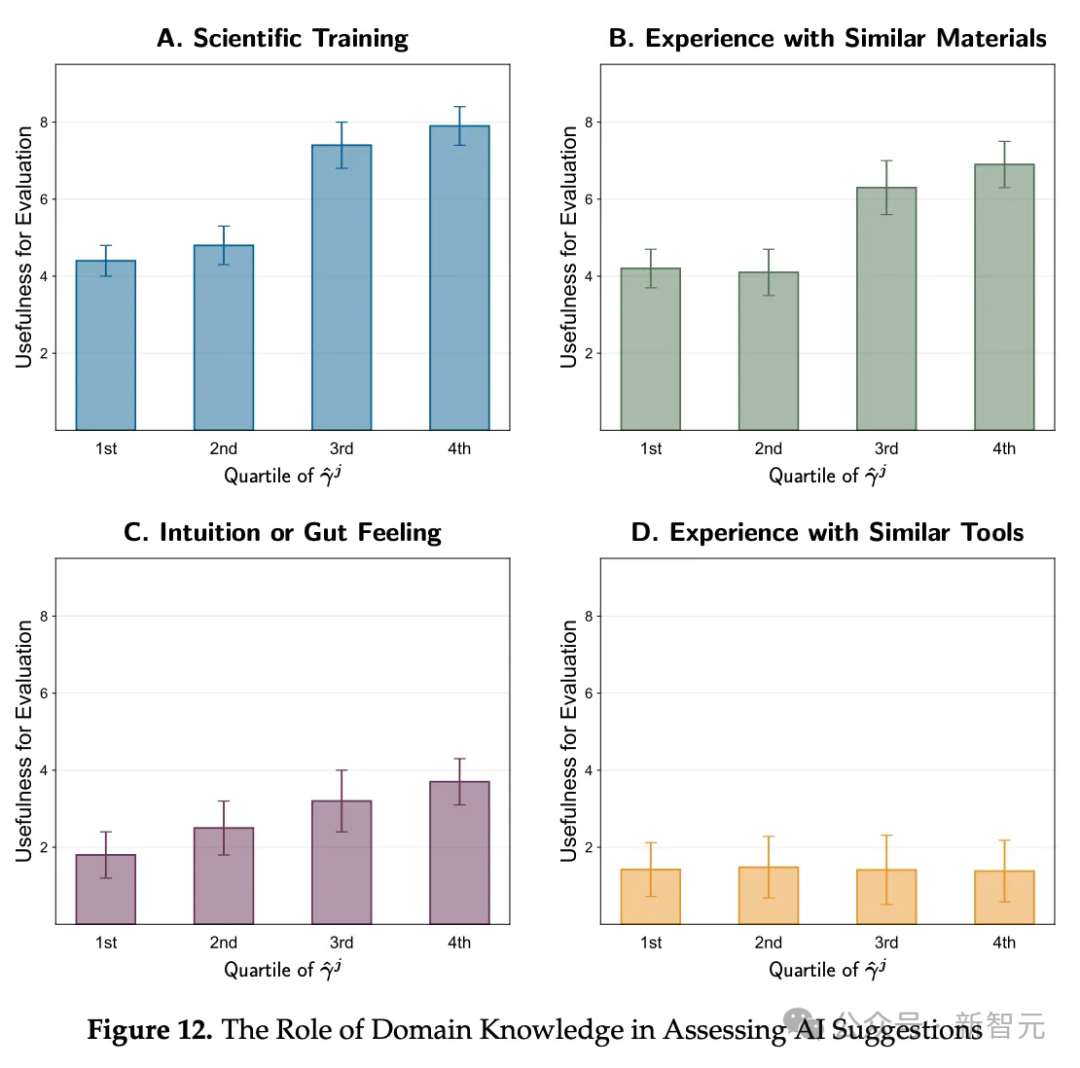
但仔細想想就會發現,這個圖表也毫無道理。
為什麼判斷力更強的研究人員,會系統性在這項調查問題上給出更高的平均分?
問題3:在1-10分的範圍內,以下各項在評估AI建議的候選材料方面有多大用處(科學訓練、類似材料的經驗、直覺或預感,以及類似工具的使用經驗)?
然後,更絕的是,作者是這樣描述公司一次幸運的裁員的,這次裁員奇蹟般地沒有干擾主要分析的數據收集,反而還提供了一個富有洞察力的例子來支持他的發現:
在最後的一個月,實驗室解僱了3%的研究人員,並對團隊進行了重組。與此同時,公司通過招聘不僅彌補了這些空缺,還實現了員工的淨增長。
雖然我沒有觀察到新員工的能力,但那些被解僱的人更有可能判斷力較弱。
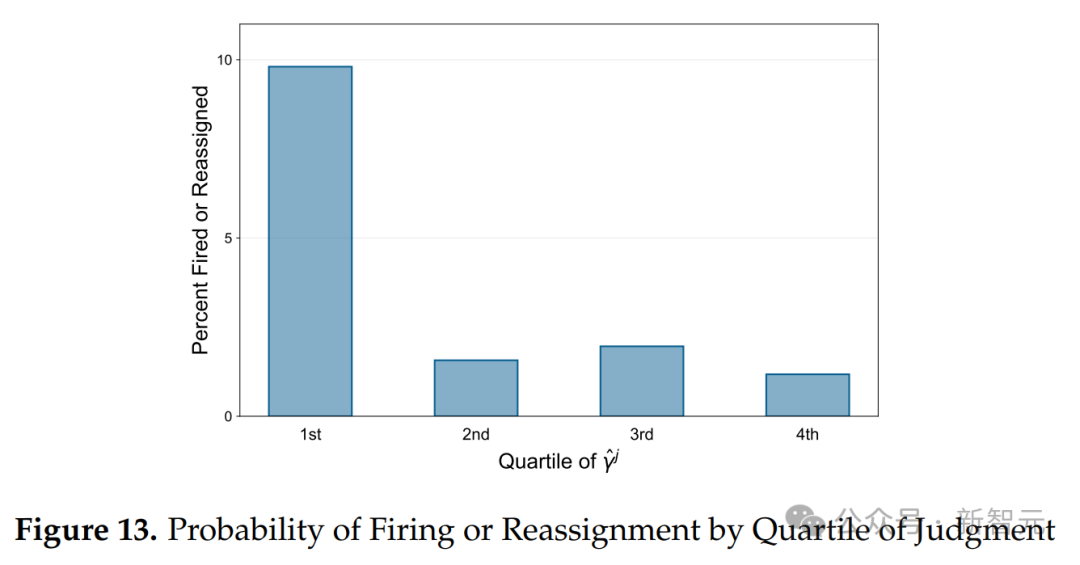
圖13顯示了按γˆj的四分位數劃分的被解僱或調崗的百分比。前三個四分位數的科學家被解僱的幾率不到2%,而最低四分位數的科學家則有近10%的幾率。
材料科學家怎麼看?
這篇論文中直接涉及材料科學的部分表現如何呢?
身為材料科學家的大佬表示,它們有點過於巧妙了。
以作者對「材料相似性」的分析為例,他聲稱通過晶體結構計算確定了新材料與已發現材料的相似程度。其中,圖表所呈現出的結果令人震驚地明確——AI發現的新材料更具創新性。
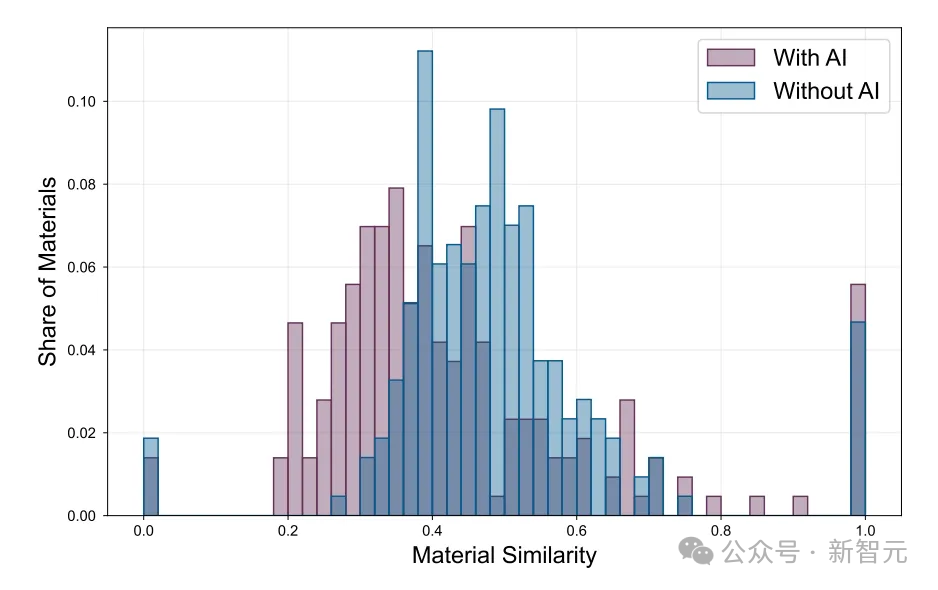
然而,令人難以置信的是,區區一名經濟學學生,竟能夠輕易地(而且沒有提供任何進一步的細節)實施他所引用的論文「Comparing molecules and solids across structural and alchemical space」中那種高度複雜的技術。
尤其是,在沒有任何計算材料研究領域專業知識的情況下,用如此精妙且規範的方式來完成這項工作。
這張圖表及其代表的數據,如果是真的,其本身可能就足以發表一篇關於AI材料發現的Nature了。但在他的論文裏,卻僅僅被歸入了附錄。
然而,這種方法論在推廣到不同類型的材料時,是毫無意義的。因此,也很難理解作者是如何用這種方式將如此廣泛類別的材料的結果簡化為單一品質因數的。
0.0到0.2以及0.8到1.0之間的空白,對於讀過幾篇論文的人來說可能看起來合理,但當推廣到幾類材料時就會顯得很奇怪,因此數據很可能是完全捏造的。
舉個例子,一種新型金屬合金與先前發現的合金參考類別相比,其相似性水平會與一種新型聚合物與其自身參考類別相比截然不同。
這需要一些非常複雜的方法論來對不同材料類型的這個單品質因數進行歸一化處理,而作者對此完全沒有提及。
此外,使用來自「材料計劃」(Materials Project)的數據來實現這些是異常困難的,需要極其複雜的「大數據」工作流程。
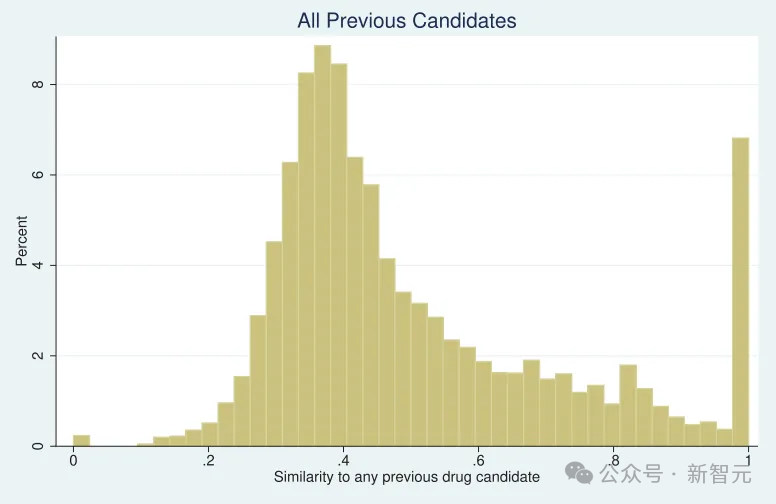
如果想要確鑿的證據,可以看看論文「Missing Novelty in Drug Development」中的圖表,作者也進行了引用並在藥物發現中使用了類似的方法論。
可以看到,它的分佈和MIT論文驚人地相似。這種分佈或許適用於藥物領域,但對於從晶體結構原子位置直接推導品質因數的廣泛材料而言,則完全不符合常理——這正是缺乏材料科學領域專業知識的人可能會犯的典型錯誤。
作者對「材料質量」的處理方式,甚至可能會把材料科學家逼瘋。
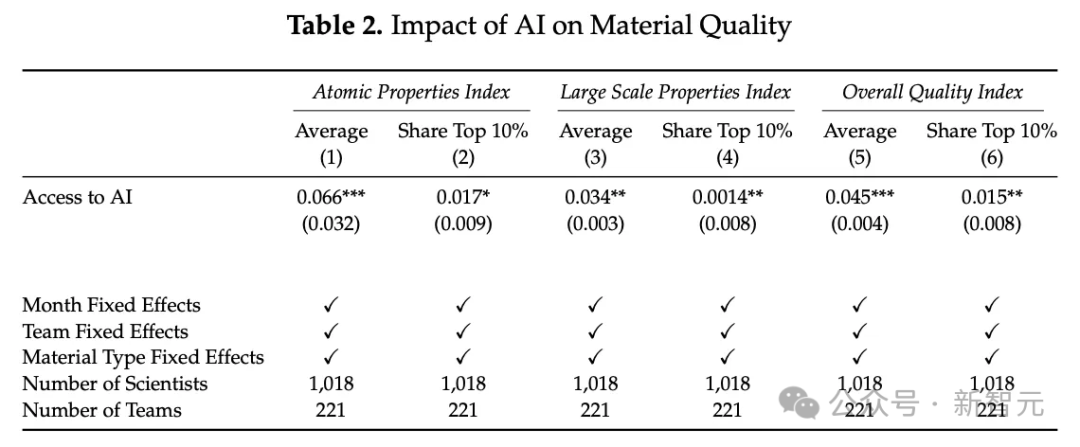
他用來計算新材料「質量」的方程式,堪稱是一個「垃圾進,垃圾出」的典範:

首先,通常沒有能夠輕易簡化為單一數值的「目標特性」,而且,即使有,其中一些也會以對數尺度分佈,這將極大地扭曲某些類別材料的數值。
此外,一個研發實驗室開發的新材料的「質量」很可能與實際的關鍵品質因數(如作者提出的「帶隙」或「折射率」)的改進完全無關。
相反,它們會是針對諸如耐久性、經濟性、易於製造等方面的。這些都是不容易簡化為單一數值的特性。
而且即使可以,要讓研究人員系統化地測量並記錄每個新材料的這些參數,說是天方夜譚都不為過。
然而,從這一堆胡言亂語中,作者還是設法得出了一個重大發現——所有1018名科學家,都在每一個類別中報告了具有統計學意義的顯著結果。
這未免也太完美了。
總的來說,作者極大簡化了材料工作複雜性的部分,對於大部分人來說,包括頂刊的編輯,都很難察覺出論文中的錯誤。
就是這樣一篇造假文章,已經讓作者取得了巨大聲譽,險些登上頂刊。
那些沒被發現,卻讓作者榮譽等身的造假文章,究竟還有多少呢?
參考資料:
https://economics.mit.edu/news/assuring-accurate-research-record
https://www.wsj.com/economy/will-ai-help-hurt-workers-income-productivity-5928a389
https://x.com/Robert_Palgrave/status/1923394441382903982
https://thebsdetector.substack.com/p/ai-materials-and-fraud-oh-my