炒股就看金麒麟分析師研報,權威,專業,及時,全面,助您挖掘潛力主題機會!

強化學習(RL)到底是語言模型能力進化的「發動機」,還是只是更努力地背題、換個方式答題?這個問題,學界爭論已久:RL 真能讓模型學會新的推理技能嗎,還是只是提高了已有知識的調用效率?
過去的研究多數持悲觀態度:認為 RL 帶來的收益非常有限,有時甚至會讓模型「同質化」加重,失去多樣性。然而,來自英偉達的這項研究指出,造成這一現象的根本原因在於:數學、編程等任務在 base model 的訓練數據中被過度呈現,以及 RL 訓練步數不足。

ProRL 來了!長期訓練 = 推理能力質變!
由 NVIDIA 團隊提出的 ProRL(Prolonged Reinforcement Learning)框架,將 RL 訓練步數從傳統的幾百步大幅提升至 2000 步以上,釋放了小模型潛藏的巨大潛力。結果令人震驚:
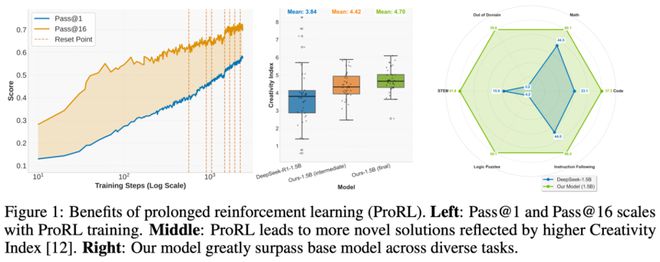
這一突破主要來自於穩定長期的強化學習,然而,長期 RL 訓練並不容易,容易出現熵崩塌、性能震盪、甚至「擺爛」。為此,團隊構建了完整的技術組合拳:
引入了數學、編程、科學問答(STEM)、邏輯謎題、指令遵循等多領域數據,這些任務具有程序化可驗證的正確答案,為 RL 訓練提供了可靠、客觀的監督信號,不再依賴「易被騙」的獎勵模型。
在 GRPO(Group Relative Policy Optimization)框架基礎上,融合 DAPO(Decoupled Clip and Dynamic Sampling)關鍵的解耦裁剪(Decoupled Clipping)來避免策略更新失衡,以及動態採樣(Dynamic Sampling)來過濾掉「太容易」或「完全不會」的無效樣本,提升訓練效率。
與一些去 KL 正則的做法相反,本論文發現適度 KL 懲罰是穩定訓練的關鍵。同時引入參考策略重置機制:當 KL 驟增或性能下滑時,重置參考策略為當前模型副本,並重置優化器,讓訓練「重啓」。這個簡單機制有效打破訓練停滯,使模型持續進化。
基於 ProRL 技術,團隊訓練出 Nemotron-Research-Reasoning-Qwen-1.5B,展現出驚人的性能優勢:
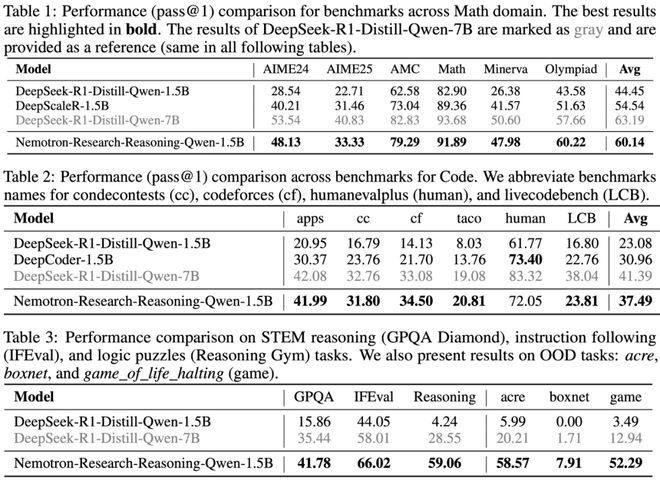
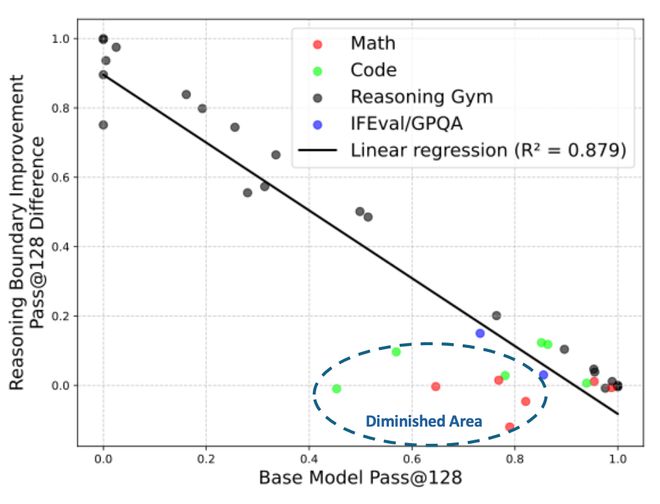
ProRL 真的能夠拓寬模型能力邊界
近來,對於 RL 是否能夠拓寬模型的能力邊界一直有爭議。作者在文章中着重分析了 RL 是否能夠拓寬能力邊界的問題,並且發現,長期穩定的 RL 能夠帶來模型能力的真正提升。圍繞着這個主題,文章主要揭示了三個方面的發現:
總結
這項來自 NVIDIA 的研究,讓我們重新認識了 RL 的真正潛力——不僅能優化策略,還能擴展模型的能力邊界。
通過 ProRL,我們第一次看到「小模型」也可以在複雜推理任務中「迎難而上」,甚至跑贏大模型。而這種進步,不靠更多數據、不靠更大模型,只靠更長、更穩、更聰明的訓練流程。
未來,如果你想做出推理能力強、部署成本低、泛化能力強的小語言模型,ProRL 可能正是那把鑰匙。