炒股就看金麒麟分析師研報,權威,專業,及時,全面,助您挖掘潛力主題機會!

機器之心發布
機器之心編輯部
來自清華大學交叉信息院和螞蟻技術研究院的聯合團隊,正式開源全異步強化學習訓練系統 ——AReaL-boba² (AReaL v0.3)
作為 AReaL 里程碑版本 AReaL-boba 的重磅升級,AReaL-boba² (正式全名:A-ReaL-double-boba) 堅持 boba 系列 「全面開源、極速訓練、深度可定製」 的開發理念,再次加量:除了更全的功能和更詳細的文檔說明,更以全異步 RL 為核心,發布 SOTA 代碼模型,全面奔向 Agentic RL:
異步強化學習(Asynchronous RL)是一種重要的 RL 範式,它將數據生成與模型訓練完全解耦,以不間斷的流式生成和並行訓練,極大提高了資源使用率,天然適用於多輪次交互的 Agent 場景。
AReaL-boba² 通過強化學習算法和訓練系統的共同設計(co-design),在完全不影響模型效果的同時,實現了穩定高效的異步 RL 訓練,不斷朝全面支持 Agentic AI 的最終目標衝刺。
本次 AReaL 升級為用戶提供更完善的使用教程,涵蓋詳細的代碼框架解析、無需修改底層代碼即可自定義數據集/算法/Agent 邏輯的完整指南,以及高度簡化的環境配置與實驗啓動流程,如果你想要快速微調推理模型,快試試雙倍加量的 AReaL-boba² 吧!
最強最快 coding RL 訓練
AReaL-boba² 基於最新的 Qwen3 系列模型,針對 8B 和 14B 尺寸進行 coding RL 訓練,並在評測代碼能力的排行榜 LiveCodeBench v5 (LCB),Codeforce (CF) 以及 Codecontests (CC) 上取得了開源 SOTA 的成績。
其中,基於部分內部數據的最強模型 AReaL-boba²-14B 在 LCB 排行榜上取得了69.1分,CF rating 達到2044,CC 取得46.2分,大幅刷新 SOTA。
此外,AReaL 團隊還基於開源數據集發布了完全開源可復現的 AReaL-boba²-Open 系列模型,同樣能在 8B 和 14B 尺寸上大幅超過現有基線。
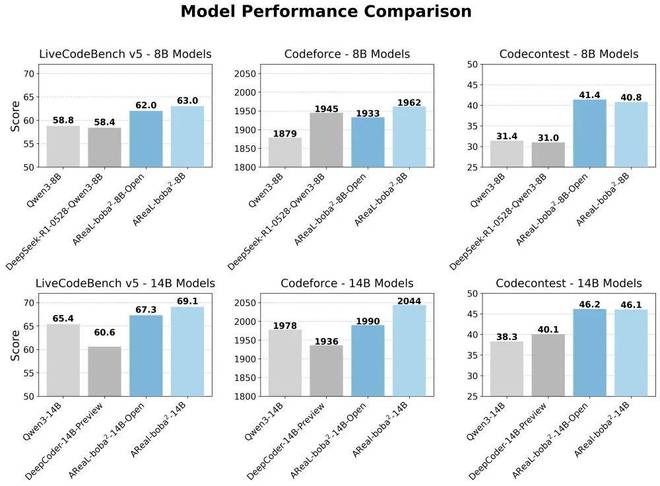
Table 1: AReaL-boba²-8B/14B 在 LiveCodeBench, Codeforce, Codecontest 等 benchmark 上達到同尺寸 SOTA 水準。
AReaL 團隊還在數學任務上進行了異步 RL 訓練的擴展性分析(scaling analysis):針對不同模型尺寸(1.5B,7B,32B)以及不同 GPU 數量,基於異步 RL 的 AReaL-boba² 系統的訓練效率都大幅超過了採用傳統同步 RL 的訓練系統。相比於共卡模式,AReaL-boba² 所採用的分卡模式顯存碎片更少,在更大模型尺寸下(32B)依然能夠保持良好的擴展性。
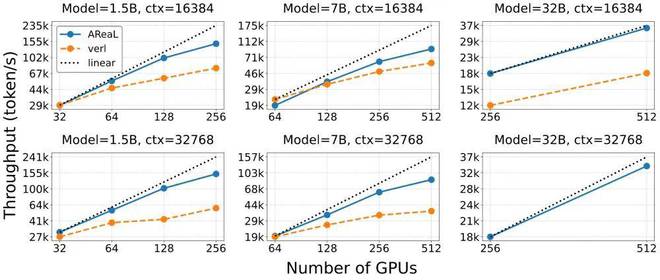
Fig. 1 異步 RL(藍色,AReaL 系統)和同步 RL(橘紅色,採用 verl 系統的官方實現)的訓練效率對比。採用異步 RL 的 AReaL 系統的訓練吞吐在不同模型尺寸(1.5B, 7B, 32B)下都有着更好的 GPU 擴展性(scaling)。
為何需要異步 RL 訓練?同步 RL 痛點剖析
在傳統同步 RL 訓練流程中,算法採用當前模型產生批量的輸出(batch output),然後用收集的輸出對當前模型計算損失函數並更新參數。同步 RL 訓練中每一個批次(batch)的數據都是由同一個模型版本產生,因此模型參數更新需要等待批次中數據全部生成完成才能啓動(Fig 2 左圖)。由於推理模型的輸出長短差異極大,在同樣的批大小(batch size)下,RL 訓練必須等待批次中最長的輸出生成完才能繼續進行訓練,以及進行下一個批次的數據收集,造成極大 GPU 資源浪費

Fig. 2 左圖(示意圖):同步 RL 訓練的計算過程,同批次輸出(藍色)需要等待最長的輸出生成完成,存在大量 GPU 空閒;右圖(示意圖):採用 1 步重疊(1-step overlap)的 RL 訓練計算過程,單步模型訓練與單批次數據收集同時進行。同批次內依然存在大量 GPU 空閒。
上圖展示了幾種常見的 RL 訓練數據流。
左圖為傳統共卡同步 RL 系統計算模式,即 RL 生成和訓練階段分別使用全部 GPU 交替進行。由於訓練任務需要完全等待生成完成,而生成階段所花費的時間取決於最長的輸出所完成時間,很容易造成 GPU 空閒。
右圖為 1-step Overlap RL,是一種同步 RL 的常見改進,由 DeepCoder 和 INTELLECT-2 項目採用。Overlap RL 採用分卡模式,收集一批次輸出的同時在不同的 GPU 上進行模型訓練,平衡了生成和訓練所需要的計算資源並避免了切換成本。但是,在 Overlap RL 系統中,每一個批次的訓練數據依然要求全部由同一個版本模型生成,生成時間依然會被最長的輸出所阻塞,並不能解決同步 RL 訓練效率低的問題。
AReaL-boba² 的高效祕訣:完全異步 RL 訓練
AReaL-boba² 通過算法系統 co-design的方式實現了完全異步 RL 訓練(fully asynchronous RL),從根本上解決了同步 RL 的各種問題。在 AReaL-boba² 的異步訓練框架中,生成和訓練使用不同 GPU 並完全解耦。生成任務持續流式進行以保證 GPU 資源始終滿載運行,杜絕了 GPU 空閒。訓練任務持續接收生成完成的輸出,在訓練節點上並行更新參數,並將更新後的參數與推理節點同步。
AReaL-boba² 的系統設計可以在保證穩定 RL 訓練的同時,參數同步的通信和計算花銷僅佔總訓練時間的 5% 以內。
此外,由於全異步 RL 中同批次數據可能由不同版本的模型產生,AReaL-boba² 也對 RL 算法進行了升級,在提速的同時確保模型效果。

使用 128 卡對 1.5B 模型在 32k 輸出長度、512 x 16 批大小設定下進行 RL 訓練,我們列出了每一個 RL 訓練步驟(模型參數更新)所需要的時間,異步 RL 相比同步 RL 相比,每個訓練步驟耗時減少 52%:

全異步 RL 訓練的系統架構:全面解耦生成與訓練
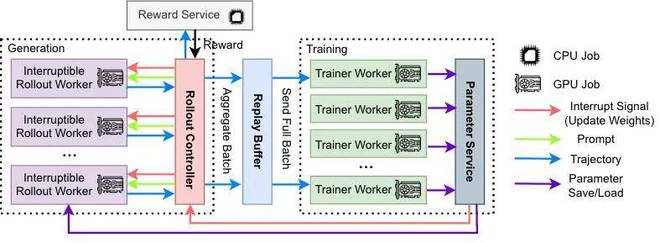
Fig. 4 AReaL-boba² 的異步 RL 系統架構。生成模塊(紫色)和訓練模塊(綠色)完全分離。
AReaL-boba² 系統架構的圍繞不同計算任務採取全面解耦的模塊化設計。對於模型輸出、模型訓練、和獎勵函數計算,採用不同計算資源徹底分離,實現全流水線異步執行。整體設計包含四個核心組件:
1.可中斷軌跡生成器(Interruptible Rollout Worker)
2.獎勵服務(Reward Service)
3.訓練器(Trainer Workers)
4.生成控制器(Rollout Controller)
算法改進保障收斂性能
雖然異步系統設計通過提高設備利用率實現了顯著的加速,但也引入一些問題導致收斂性能不如同步系統:
為了解決這些問題,團隊提出了兩項關鍵算法改進。
方法 1:數據陳舊度控制(Staleness Control)
對於異步 RL 算法,有一個重要的參數叫 staleness,可以用來衡量訓練數據的陳舊性。
staleness 表示當採用一個批次的數據進行模型訓練時,生成最舊的一條數據的模型版本和當前更新的模型版本之間的版本差(比如,一個批次中最舊的一條數據由 step 1 產生的模型輸出,當前模型由 step 5 產生,則該批次 staleness=4)。同步 RL 的批次 staleness 固定為 0。staleness 越大,則數據陳舊性越嚴重,對 RL 算法的穩定性挑戰也越大,模型效果也更難以保持。
為避免數據陳舊性帶來的負面影響,AReaL 在異步 RL 算法上設定超參數 max staleness ,即只在 staleness 不超過預設值 時,提交進行新的數據生成請求。
具體來說,軌跡生成器在每次提交新的請求時,都會通過生成控制器進行申請;控制器維護當前已經被提交的和正在運行的請求數量,只有當新的請求 staleness 不超過 限制時才允許被提交到生成引擎處。當 =0 時,系統等價於跟同步 RL 訓練,此時要求用於訓練的採樣軌跡一定是最新的模型生成的。
方法 2:解耦近端策略優化目標(Decoupled PPO Objective)
為了解決舊數據與最新模型之間的分佈差異帶來的問題,團隊採用了解耦的近端策略優化目標(Decoupled PPO Objective),將行為策略(behavior policy)近端策略(proximal policy)分離。其中:
最終,可以得到一個在行為策略生成的數據上進行重要性採樣(importance sampling)的 PPO 目標函數:
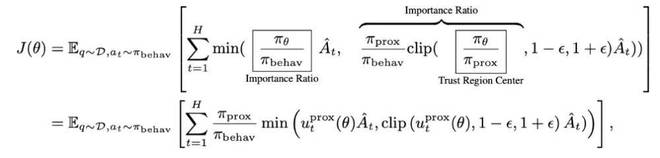
其中,係數 起到了在 token 級別篩選有效訓練數據的作用。當 遠遠小於 1 時,對應數據能夠被最新策略採樣的概率極低,故而在訓練目標中只佔據了可以忽略的比重。
效果驗證:速度 Max, 性能依舊強勁!
AReaL 團隊基於 1.5B 模型在數學任務上設定不同 max staleness 進行 Async RL 訓練,得到如下訓練曲線。在 AReaL 的訓練設定中,經典的 PPO 可以清晰看到隨着 staleness 增大效果下降,而採用 decoupled PPO objective 後,即使 增加到 8,算法依然能夠保持訓練效果好最終模型性能。
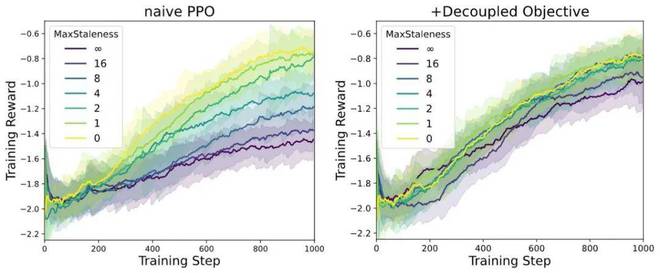
Fig. 5 針對不同 staleness 的算法穩定性結果。左圖:經典 PPO 算法在異步 RL 場景下模型效果很容易退化。右圖:採用 decoupled PPO objective,在 staleness=8 的情況下模型效果依然無損。
AReaL 團隊還把採用不同 max staleness 訓練的模型在 AIME24 和 AIME25 數據集上進行評測,採用 decoupled objective 的算法都能在 更大的情況下保持更好的模型效果。
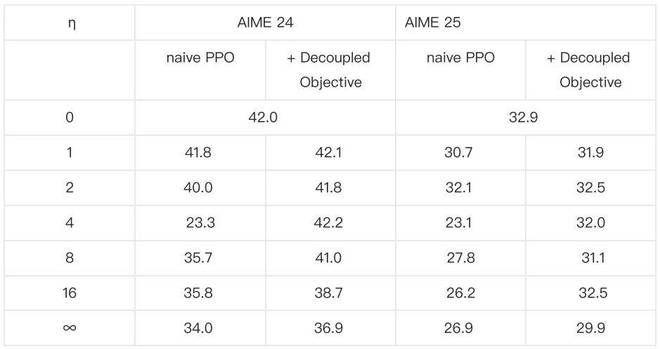
Table 2: 在數學任務(AIME24 & AIME25)上對於不同 max stalness,採用經典 PPO 算法和 decoupled PPO 進行異步 RL 訓練最終產生的模型效果比較,decoupled PPO 始終有更好效果。
想深入了解算法原理與實驗細節?請訪問原論文查看更多算法細節:https://arxiv.org/pdf/2505.24298
開源助力:輕鬆復現 SOTA 代碼模型
除了強大的 AReaL-boba² 訓練系統,團隊也帶來了訓練數據、訓練腳本和評估腳本。團隊也提供了完整的技術報告,確保可以在 AReaL 上覆現訓練結果以及進行後續開發。技術報告中呈現了豐富的技術細節,包括數據集構成、獎勵函數設定、模型生成方式、訓練過程中的動態數據篩選等等。
快來用 AReaL-boba² 訓練你自己的 SOTA 代碼模型吧!
彩蛋:擁抱 Agentic RL 浪潮
本次 AReaL-boba² 發布也支持多輪 Agentic RL 訓練!開發者可以根據自己的需求自由定製智能體和智能體環境,並進行 Agentic RL 訓練。目前,AReaL-boba² 提供了一個在數學推理任務上進行多輪推理的例子。
AReaL 團隊表示,Agentic RL 功能也正在持續更新中,未來會支持更多 Agentic RL 訓練的功能。
結語
AReaL 項目融合了螞蟻強化學習實驗室與清華交叉信息院吳翼團隊多年的技術積累,也獲得了大量來自螞蟻集團超算技術團隊和數據智能實驗室的幫助。AReaL 的誕生離不開 DeepScaleR、Open-Reasoner-Zero、OpenRLHF、VeRL、SGLang、QwQ、Light-R1、DAPO 等優秀開源框架和模型的啓發。
如同其代號 「boba」 所寓意,團隊希望 AReaL 能像一杯奶茶般 「delicious, customizable and affordable」 —— 讓每個人都能便捷、靈活地搭建和訓練屬於自己的 AI 智能體。
AReaL 項目歡迎大家加入,也持續招募全職工程師和實習生,一起奔向 Agentic AI 的未來!