炒股就看金麒麟分析師研報,權威,專業,及時,全面,助您挖掘潛力主題機會!

新智元報道
編輯:KingHZ
【新智元導讀】RNN太老,Transformer太慢?谷歌掀翻Transformer王座,用「注意力偏向+保留門」取代傳統遺忘機制,重新定義了AI架構設計。全新模型Moneta、Yaad、Memora,在多個任務上全面超越Transformer。這一次,谷歌不是調參,而是換腦!
谷歌又有新的注意力了!
他們提出的新架構參數減少40%,訓練速度較RNN提升5-8倍,在某些任務上性能甚至Transformer好7.2%!
在大語言模型(LLMs)中,他們引入了新的注意力偏向策略,並重新構想了「遺忘」這一過程,用「保留」來取而代之。

所謂的「注意力偏向」現象,是指人類天然傾向於優先處理特定事件或刺激
受人類認知中的「關聯記憶」(associative memory)與「注意力偏向」(attentional bias)概念啓發,谷歌的團隊提出了統一視角:
Transformer與RNN,都可以被看作是優化某種「內在記憶目標」(即注意力偏向),從而學習鍵值映射的關聯記憶系統。
他們發現:
為此,他們把這一切都被整合進了名為Miras的新框架中,提供四個關鍵設計維度,指導下一代序列模型的構建。
1.記憶架構— 如何構建記憶,決定了模型的記憶能力,比如向量、矩陣、MLP等
2.注意力偏向— 模型如何集中注意力,負責建模潛在的映射模式
3.保留門控— 如何平衡學習新概念和保留已學概念
4.記憶學習算法— 模型如何訓練,負責記憶管理,比如梯度下降、牛頓法等
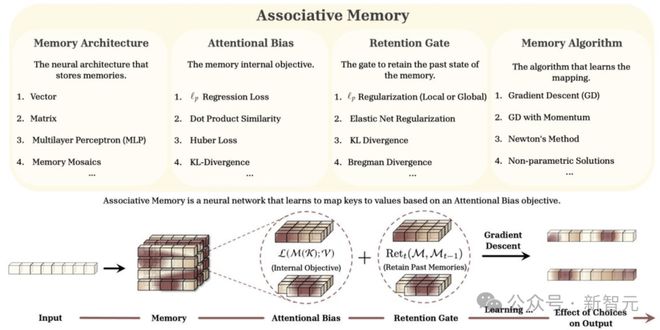 圖1:Miras框架概述
圖1:Miras框架概述這次他們,一口氣提出了三種新型序列模型,在某些任務上甚至超越了超越Transformer。
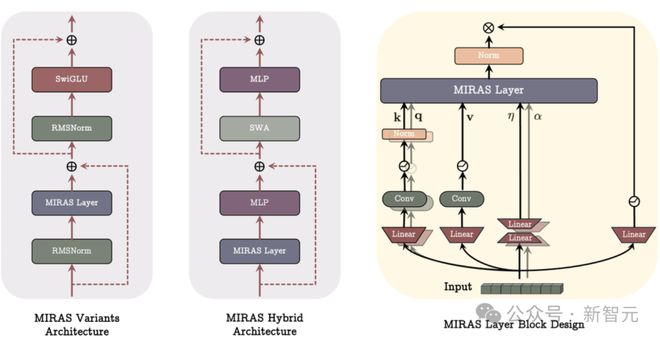
這三種新模型——Moneta、Yaad和Memora,超越了現有線性遞歸神經網絡的能力,同時保持快速可並行訓練的過程。
新模型各有所長,在特定任務中表現卓越:
· Moneta:在語言建模任務中PPL指標提升23%
· Yaad:常識推理準確率達89.4%(超越Transformer7.2%)
· Memora:記憶密集型任務召回率提升至91.8%
在多個任務上,新模型提升明顯:
• 在PG19長文本建模任務中,參數量減少40%情況下保持相當性能
• 線性計算複雜度使訓練速度較傳統RNN提升5-8倍
• 在CLUTRR關係推理基準上創造92.3%的新SOTA紀錄

論文鏈接:https://arxiv.org/abs/2504.13173
模型沒有失憶,
但也有問題
研究者定義並形式化了注意力偏向的概念,作為序列模型的內部記憶目標,旨在學習輸入(即鍵和值)之間的潛在映射。
廣義上講,關聯記憶是將一組鍵K映射到一組值V的操作符(Operator)。
為了學習數據中的潛在映射模式,它需要一個目標,該目標針對某種類型的記憶並衡量學習到的映射質量:

研究人員不再用「遺忘」(forget)這個詞,而是提出了「保留」(retention)的概念。
因此,「遺忘門」(forget gate)也就變成了「保留門」(retention gate)。
模型並不會真的清除過去的記憶——
它只是選擇對某些信息不那麼「上心」而已。
此外,研究人員提供了一套全新的替代保留門控(忘記門)用於序列模型,帶來了新的洞察,幫助平衡學習新概念和保留先前學到的概念。
現有的深度學習架構中的遺忘機制,可以重新解釋為一種針對注意力偏向的ℓ₂正則化。
比如,softmax注意力是Miras的一個實例,利用Nadaraya-Watson估計器找到MSE損失的非參數解時,無需保留項。

論文鏈接:https://arxiv.org/abs/2407.04620
實際上,這次谷歌團隊發現大多數現有模型(如Transformer、RetNet、Mamba等)都採用了類似的注意力偏向目標,即嘗試最小化鍵值對之間的ℓ₂ 範數(均方誤差)。
但它存在幾個問題:
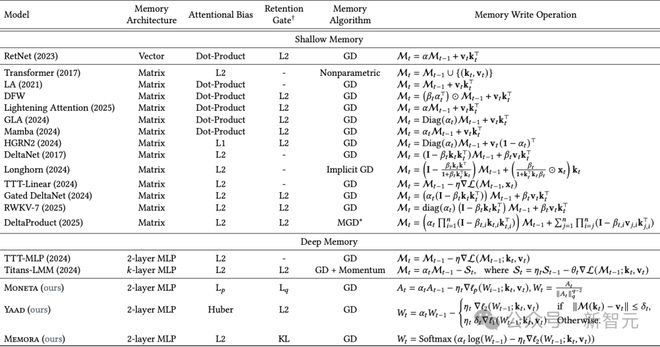
表1:基於Miras框架視角的近期序列模型概覽
目標函數:注意力偏向策略
基於關聯記憶概念的神經架構設計,被轉化為學習鍵值之間的基本映射,可以利用最小化目標函數L來實現:
為了求解上述優化問題,最簡單的方法就是利用梯度下降。
具體來說,給定一對新的鍵值對,可以通過以下方式更新記憶(一下叫做更新方程):
這一公式可以被重新解釋為一種瞬時驚訝度度量,其中模型記憶那些違反目標預期的token。
更新方程可以看作是在線梯度下降的一步,涉及損失函數序列的優化:
衆所周知,在線梯度下降可以被視為跟蹤正則化領導者(Follow-The-Regularized-Leader, FTRL)算法的一個特例。
這其實對應於某些特定選擇的損失函數。
具體來說,假設W₀ = 0,則更新方程中的更新規則等價於下列方程(以後稱為二次更新方程):
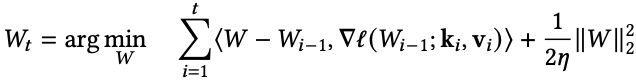
以上方程使用了損失函數的線性近似和二次正則化。
然而,從原則上講,也可以使用其他損失函數的近似以及其他正則化函數。
更具體地說,可以將二次更新方程推廣到如下形式:

其中:
不同的損失函數和正則化項,對應不同的算法。
在這種情況下,記憶的更新不僅依賴於當前輸入數據的特徵,還受到記憶結構的影響,正則化項在其中起到了平衡學習和記憶穩定性的作用。
Miras提出的三類新型注意力偏向策略。
ℓₚ範數:記憶精度可調
如正文所述ℓ2迴歸損失通常是自然選擇,但其對數據噪聲較為敏感。
自然的擴展是採用ℓ範數目標函數類。
具體而言,設M為記憶模塊,k為鍵集合,v為值集合,ℓ注意力偏向定義為:
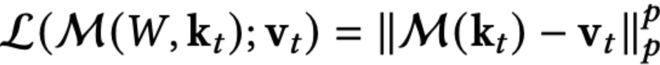
不同的範數對應對噪聲的敏感度:
ℓ₁更抗異常值,
ℓ₂是常規選擇,
ℓ∞ 聚焦於最大誤差。
Huber損失:「應對異常」心理機制
Huber損失具備容錯機制的記憶模塊。
儘管ℓ2範數目標是許多統計與機器學習任務的常見選擇,但其對異常值和極端樣本的敏感性衆所周知。
這種敏感性同樣存在於將ℓ2損失用於注意力偏向的場景。
為解決該問題,並借鑑穩健迴歸的思路,研究者建議採用Huber損失類型作為注意力偏向,從而降低異常數據對記憶學習過程的負面影響。
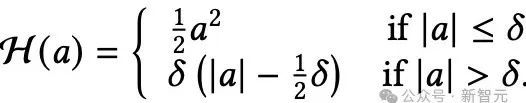
Huber損失結合了ℓ₂(正常情況下)和ℓ₁(出現大誤差時),在面對異常值時也能保持學習的穩定性。
魯棒優化:考慮最壞情況
魯棒優化(Robust Optimization)的核心思想:最小化最壞情況下的損失;在一個不確定性集合(uncertainty set)內優化性能。
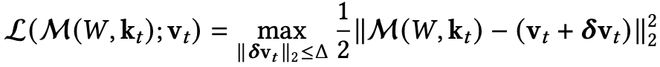
類似「備份記憶」策略——即使現實偏離,也不崩盤。
魯棒優化使模型在輸入有小幅變動時也能保持穩定。
正則化:保留門策略
在多數傳統模型中(如 LSTM、Mamba、Transformer),信息的遺忘或記憶更新是隱式的,模型只是不斷地「覆蓋」舊狀態。
但現實中,大家知道:
並不是所有信息都值得被長期記住,有些應該快速遺忘,有些則必須深深保留。
因此,Miras 框架提出了一個明確的設計目標:
引入可控的、可設計的保留機制 Retention Gate,使模型顯式判斷是否保留舊記憶。
這就是Retention Gate的作用核心。
另一種解讀的方法是,將更新方程視為從最新的鍵值對(kᵢ, vᵢ)中學習(通過使用其梯度或驚訝度度量),同時保持接近先前狀態Wᵗ₋₁,以保留先前記憶的token。
這種形式可以推廣為:
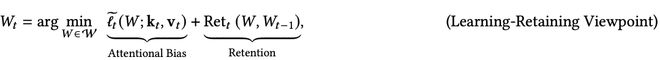
其中,右側第一項是ℓ(W; k_t, v_t)的近似,最小化它對應於從新概念(kₜ, vₜ)中學習。
第二項則對W的變化進行正則化,以使學習動態穩定,並保留先前學到的知識。
Retention函數可能包括局部和全局組件:
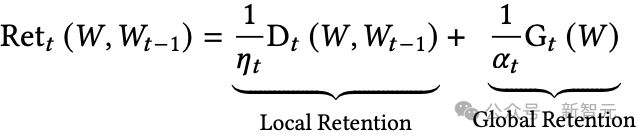
其中:
從目標函數角度,保留門對應正則項。
基於概率的機制:將記憶處理為概率分佈(比如用KL散度)來保持其穩定性。
彈性網(Elastic net):結合了軟遺忘(ℓ₂)和硬遺忘(ℓ₁)的方法。
Lq穩定性:可調節記憶對變化的抵抗程度。
Bregman散度:引入非線性、能感知數據結構形狀的記憶更新方式。
三個新模型
研究人員利用 Miras 框架構建了三個新模型:
• Moneta ——靈活且表達力強。它採用可定製的 ℓp/ℓq範數來靈活控制記憶更新的精度。
• Yaad ——抗噪和抗極端值能力強。它使用Huber損失和自適應更新機制來保持模型的穩定性。
• Memora ——穩定且規範的記憶控制。它通過KL散度和Softmax更新方法,確保記憶在合理範圍內波動。
在實驗中,這些新模型在以下任務中表現優於現有最強模型:語言理解、常識推理、發現罕見事實(像「大海撈針」那樣找出隱藏信息)、 在長文本中保留細節信息。
實驗表明,Miras中的不同設計選擇產生了具有不同優勢的模型。
Moneta專注於記憶更新中的可定製精度,使用靈活的ℓₚ/ℓq 範數。
Yaad使用Huber損失和自適應更新來保持穩定性。
Memora利用KL散度和Softmax更新來保持記憶的邊界。
實驗結果
首先關注語言建模中的困惑度(perplexity)以及常識推理任務的表現。
研究者在表2中報告了Memora、Yaad、Moneta三個模型變體,以及一些基準模型(參數量為340M、760M 和 1.3B)的結果。
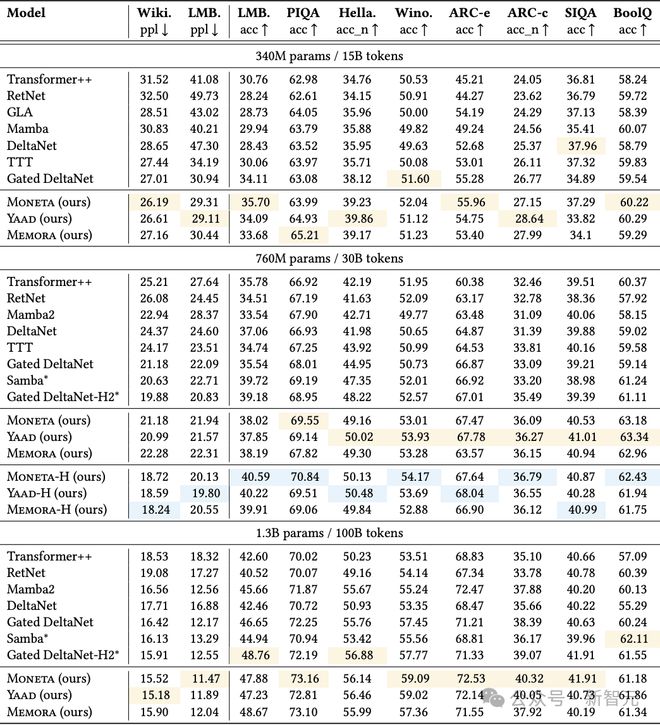
表2:Miras各個變體與基準模型在語言建模和常識推理任務中的表現。帶有*標記的為混合模型,高亮的內容是表現最好的純模型和混合模型
所有模型變體都優於包括Transformer++、現代線性遞歸模型和混合方法在內的全部基準方法。
尤其是在與混合模型的比較中取得更好表現更為關鍵,因為所有模型變體都是純遞歸結構(完全不依賴注意力機制)。
在Miras的三個變體中,雖然Moneta的表現略遜於Memora和Yaad,但這三者的差距並不大,且具體哪個模型效果最好會因任務類型和模型大小而異。
擴展模式分析(Scaling Pattern)
為了評估新模型的擴展能力,並與基準模型做對比,研究者繪製了模型在不同大小和上下文窗口下的性能變化圖。
上下文長度
研究者將訓練時使用的上下文長度從2K擴展到32K,分別在模型大小為340M和760M的兩個版本上進行實驗。結果如圖3中間和右側所示。
Miras的三個變體在上下文長度增加時的擴展能力均優於當前最先進的基準模型。
這種性能優勢主要來自兩個方面:
(1) 更強表達能力的記憶結構。與Mamba2和GSA這些使用向量或矩陣形式記憶的基準模型不同,新模型變體使用了兩層的多層感知機(MLP),能更有效地學習長序列信息;
(2) 保留門(retention gate)和注意力偏向的設計:新的模型突破了傳統做法,這有助於更高效地管理固定容量的記憶。
模型大小
研究者還在圖3左側展示了模型的計算量(FLOPs)與困惑度的關係。
在相同的 FLOPs(計算預算)下,三個模型變體的表現都超過了所有基準模型。再次證明了強大的記憶機制設計對模型性能的重要性。

圖3:在C4數據集上擴展模型規模和序列長度時的表現趨勢。(左)隨着模型規模增加的表現;(中)在模型規模為340M時,序列長度增加帶來的影響;(右)在模型規模為760M時,序列長度增加帶來的影響
大海撈針任務(Needle In Haystack)
為了評估模型在處理長文本時的有效上下文能力,研究者採用了「大海撈針」(Needle In Haystack)任務。
在「大海撈針」任務中,模型需要從一段很長的干擾文本中找出一條特定的信息(即「針」)。
在RULER基準中的S-NIAH(單一大海撈針)任務,在文本長度分別為1K、2K、4K和8K的情境下對新模型和基準模型進行測試,結果見表3。
所有模型變體都以顯著優勢超過了所有基準模型。
值得注意的是,在處理合成噪聲數據(S-NIAH-PK)時,Moneta 的表現優於其他模型。這一發現說明 -範數目標函數和保留門機制在噪聲環境下更具魯棒性,能更好地保持模型性能。
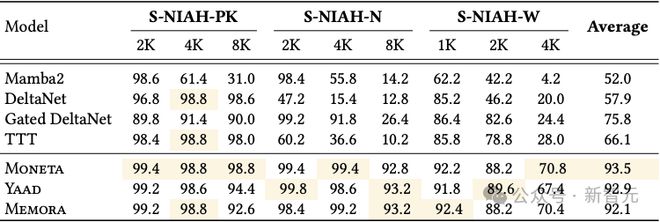
表3:Moneta、Yaad、Memora以及基準模型在RULER中的NIAH任務上的表現。最佳結果用高亮表示。
更多細節和理論推導,請參閱原文。
作者介紹
Peilin Zhong目前是谷歌紐約的算法與優化團隊的研究科學家。
他在哥倫比亞大學獲得了博士學位。
在此之前,他曾是清華大學跨學科信息科學研究院(姚班)的本科生。
他的研究興趣廣泛,主要集中在理論計算機科學領域,特別是算法的設計與分析。
具體包括並行算法和大規模並行算法、隱私算法、壓縮算法、流式算法、圖算法、機器學習、高維幾何、度量嵌入、數值線性代數、聚類以及與大規模數據計算相關的其他算法。
參考資料:
https://arxiv.org/abs/2504.13173
https://x.com/TheTuringPost/status/1914316647386714289