炒股就看金麒麟分析師研報,權威,專業,及時,全面,助您挖掘潛力主題機會!

新智元報道
編輯:KingHZ
【新智元導讀】AI頂流Claude升級了,程序員看了都沉默:不僅能寫代碼能力更強了,還能連續幹活7小時不出大差錯!AGI真要來了?這背後到底發生了什麼?現在,還有機會加入AI行業嗎?如今做哪些準備,才能在未來立足?
在Dwarkesh Patel主持的節目中,Anthropic的Sholto Douglas、Trenton Bricken等人,一起討論了Claude 4是如何思考的。

三人私交甚好,聊了2小時20多分鐘,主要集中在4個話題:
1. 過去一年中人工智能研究的變化;
2. 新的強化學習(RL)體系以及其可擴展性;
3. 如何追蹤模型的思考過程;
4. 各國、勞動者和學生應如何為通用人工智能(AGI)做準備。

對於Sholto Douglas的「AI取代人類白領工作」觀點,網友紛紛表現出了極大的興趣。

另外值得一提的是,Sholto Douglas在清華大學交流學習過。
強化學習立新功
過去一年最大的變化是:強化學習(RL)終於在語言模型上真正奏效了。
這一點現在有了明確的證據:如果提供合適的反饋機制,確實找到了某種算法,能讓模型表現出接近專家級人類的可靠性與性能。
目前,這種成果最明確地體現在兩個領域——
程序設計競賽(competitive programming)和數學推理。
任務的難度可以分為兩個維度來理解:
一個是任務的智力複雜度(intellectual complexity),
另一個是任務所涉及的時間跨度(time horizon)。
現在已經證明,模型確實可以在多個維度上達到人類智能的頂峯。
當然,長期自主表現(long-running agentic performance)還欠佳,但它正在「蹣跚起步」。
預計到今年年底,我們將看到更明確的進展——
語言模型能完成實際工作,就像真正的軟件工程師那樣。
可驗證獎勵的強化學習
現在看到的真正限制,其實是:
LLM可以處理智力高度複雜的問題,但前提是問題上下文要明確、邊界要清晰。
如果任務比較模糊,或者需要在環境中反覆探索、試錯、迭代,它們就會喫力。
只要你能為模型提供一個良好的「反饋閉環」(feedback loop),它通常就能做得不錯;但如果這個閉環不清晰,它就容易「迷路」。
具體而言,就是「可驗證獎勵的強化學習」(RL from verifiable rewards)。
它的核心是:獎勵信號必須是「乾淨」的,也就是說——它必須準確、明確、客觀。
最早語言模型的調優方法是RLHF(Reinforcement Learningfrom Human Feedback,從人類反饋中強化學習),典型的形式是「成對反饋」(pairwise feedback),即:
人類對兩段輸出打分,告訴模型哪一段更好。
隨着訓練迭代,模型生成的輸出越來越接近人類「想要的答案」。
但問題在於,這種方法並不能真正提升模型在「高難度問題」上的表現,因為人類其實不是很擅長判斷「哪個答案更好」。
所以,更理想的是提供一種能客觀判斷模型輸出是否正確的信號。
比如,數學題的正確答案;代碼是否通過了單元測試。
這類都是典型的、非常乾淨的獎勵信號(clean reward signal)。
比如說,完成諾獎級研究所涉及的任務,往往具備更多層次的「可驗證性」。
相比之下,一部「值得獲獎」的小說需要的是審美判斷與文學品味,
這些就非常主觀,難以量化。
所以模型很可能會更早地在科學研究領域實現「諾獎級突破」,而不是先寫出一部能贏得普利策獎的小說。

普利策獎獎章
但至少兩位創作者,已經用LLM寫出了完整的長篇書稿。
他們都非常擅長為設計文章結構和提示(scaffolding&prompting)。
也就是說,關鍵不是模型不行,而是你會不會用。
智能體的未來:操作電腦
本質上,「電腦操作智能體」(Computer Use Agent)和「軟件工程」智能體沒有多大區別。
只要能電腦操作把表示成token輸入,LLM就能處理。
模型現在能「看圖」,能畫圖,能理解複雜的概念,這些基本已經實現。
電腦操作唯一的區別是:比數學和編碼更難嵌入反饋迴路中。
但這只是難度更高,不代表做不到。
而且,大家低估了現在AI實驗室到底有多「糙」。
外界以為這些實驗室運轉得像完美機器,其實完全不是。
這些大模型的開發流程,實則是在巨大的時間壓力下倉促構建的。
實驗室在瘋狂招人、培訓人,根本還沒輪到把「AI操作電腦」當作重點。
相比之下,「編碼」是更有價值、也更容易落地的方向。所以更值得優先集中資源突破。
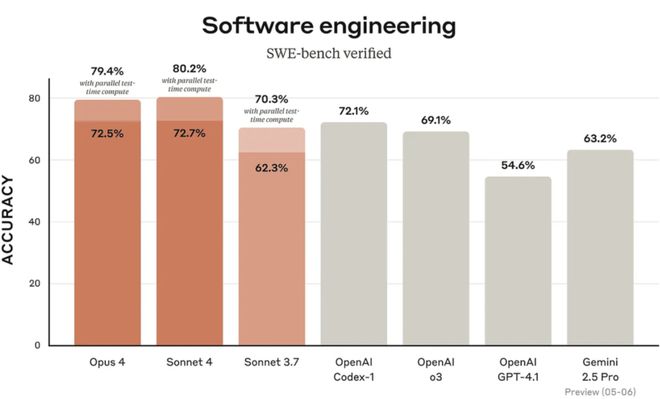
在軟件工程基準測試SWE-bench中,Claude4與其他模型的比較
一旦模型能搞定代碼,價值會呈超級指數級釋放。 而電腦操作雖然也重要,但優先級自然就排後面了。
還有個被低估的因素:研究員們喜歡研究他們認同的「智能標準」。
為什麼是數學、競賽編程先突破?因為那是他們認可的「聰明」。
他們覺得:「要是模型能在AIME(美國數學競賽)上贏我,那纔是真的強。」
但你讓它做Excel報表?無人在乎。
所以現在的局面是: 模型在他們心目中已經夠聰明瞭,但大家還沒把精力花在「電腦操作」這塊上。
一旦資源傾斜過來,這塊進展也不會慢。
Ai2的科學家Nathan Lambert,也認同這種觀點:
RLVR沒學會新技能,是因為投入的算力不夠大。
如果投入算力總量的10%-25%,我猜模型會讓人刮目相看。

AGI雛形:LLM
如果未來一兩年內,智能體開始上崗,軟件工程實現自動,模型的使用價值將呈指數級增長。而這一切的前提,是海量算力的支持。
關鍵在於推理的算力問題,但這被嚴重低估了。
目前,全球大約有1000萬張H100級別的算力芯片。
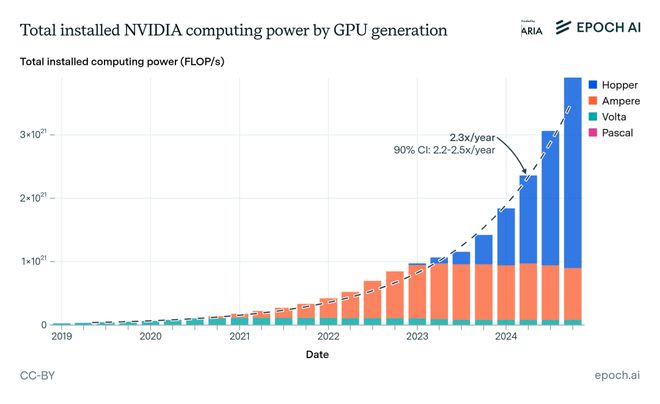
Epoch AI估算的GPU算力變化和趨勢
有研究估算,一張H100的浮點運算能力,大致相當於一顆人腦。
如果以AGI達到人類推理效率為假設,這意味着今天的地球上,理論上已經能同時運行1000萬個AGI。
這個數字到2028年預計將達到1億張。但即便如此,可能仍不夠。
因為人類正以每年2.25到2.5倍的速度擴張算力,但在2028年左右,將迎來上限:晶圓產能的物理瓶頸。
建廠周期很長,一旦觸頂,算力增長就會放緩。
再者,有些人認為人類離真正擁有長上下文、一致意圖、強多模態能力的AGI還很遠。
這正是在「AGI實現速度」上,業內意見分歧的關鍵所在。
這背後有兩個關鍵認知差異:
第一,業內很多專家認為——要在長上下文推理、多模態理解等方面實現突破,沒那麼快。
人類級別的推理能力,通常需要算力提升幾個數量級才能支撐。
第二,芯片問題,還包括電力、GDP等限制等可能讓算力增長停滯,而如果到2028或2030年還沒實現AGI,那之後每年的實現概率,也許就會開始大幅下滑。
窗口期,稍縱即逝。
AGI的機會
就AGI實現問題,Leopold Aschenbrenner寫了Situational Awareness。

Leopold Aschenbrenner:專注於AGI的投資人,OpenAI超級對齊團隊前成員
其中,有個小標題就叫做「This Decade or Bust」,大意為「這十年,不成則廢」。
意思是:我們能不能搞定AGI,基本就看這十年了。
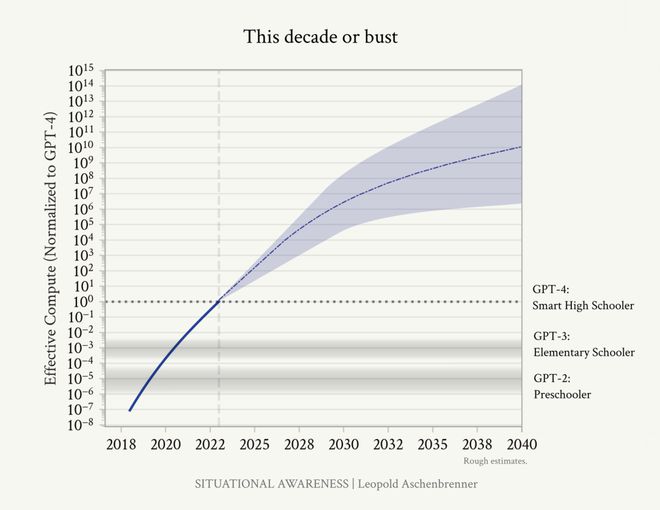
長文中對有效算力的預測
未來幾年,還可以顯著增加訓練算力,特別是在強化學習(RL)上。
2025年,RL非常值得關注,因為往裏面投入的算力會遠超以往。
在RL階段用,DeepSeek-R1和o1的是差不多的算力,所以年初它們之間差距不大。
但隨着時間推移,算力差距會被逐漸放大,帶來明顯的結果分化。
但DeepSeek不斷碰到非常底層的硬件限制,然後思考:
理想條件下,我們想表達的算法是什麼?
在現實限制下,我們又能表達什麼?
在不斷試錯中,DeepSeek一步步迭代出更優的「約束兼容解」。
而且最難得的是——
新方案通常非常簡潔優雅,再加上超強的工程能力,效果就出來了。
還有一個有意思的地方:他們引入了Meta提出的「multi-token prediction」方法。
Meta當時發過論文,講的是一次性預測多個token,而不是傳統的逐token預測。

論文鏈接:https://arxiv.org/abs/2404.19737
這一思路挺聰明的。
但奇怪的是,Meta後來並沒有把這個方法應用到Llama系列模型裏,而DeepSeek卻在他們的新模型論文中實現了。
具體原因無人知曉,但這個差異很值得玩味。
LLM孕育AGI
部分人覺得AI發展會很慢,比如說AlphaGo雖然厲害,但它離真正的通用人工智能(AGI)還很遠:
你看看AlphaGo,它已經能主動探索,AlphaZero還能泛化到新的視頻遊戲,看起來擁有了一整套與世界互動的先驗能力。
但顯然,現在回頭看,雖然現在深度學習還在使用其中很多方法,但AlphaZero本質上並不是「AGI雛形」。
所以關鍵問題是:
為什麼LLMs比AlphaZero更接近AGI?
為什麼只加一點點訓練、注意力或結構調整,就可能達到「類人智能」?
AlphaZero所處的任務環境——雙人對戰、完全信息遊戲
——對強化學習算法太「友好」了。
相比之下,要構建真正類似AGI的系統,你必須搞定的是:
回顧過去十年的AI討論,有一種傳統看法是:
AI是線性尺度:先是「愚蠢的AI」,然後是AGI,最後是ASI(超級智能)。
但模型其實呈現出「鋸齒狀」特徵:
它在某些環境裏表現特別好(因為訓練數據豐富),在另一些就不行。
那麼問題來了:
我們還能把它們稱為「通用智能」嗎? 還是說,它們只是「訓練在哪就聰明在哪」?
這和GPT-2時代的討論很像。
當時大家發現:小模型只要在某個任務上做微調(fine-tune),效果就很強。
但到了GPT-4這種規模,用足夠多樣的數據、足夠大的計算量去訓練,它就能天然泛化到很多子任務上,而且比那些「專門訓練的小模型」泛化得更好。
強化學習現在也在走同樣的路徑:
現在我們已經看到了一些早期跡象,比如模型在推理類任務上的泛化能力,開始顯現。
有一個很好的例子是:「回溯能力」的出現(backtracking)。
模型會嘗試一條解法,然後「啊這不行」,重新走另一條路徑。這種「反思式推理」正是RL訓練難題過程中逐步顯現出來的。
所以大家總說:「AI只擅長被RL訓練過的任務」。
但別忘了,這些任務本身就是語言、科學、編碼、心理狀態等多種領域的融合。
要做好這件事,AI模型不僅要是個優秀程序員,還得能用語言清晰思考,甚至有點哲學家氣質。
而它確實已經在從訓練中泛化出這種混合能力了。
這纔是我們真正接近「通用智能」的原因。
這並不是說AI一定會做某件事,或一定會朝某個方向發展。
但如果你問:「什麼纔是真正有經濟價值的?」
現在的AI正在學會寫代碼。
而人類最有價值的能力,可能就是——
成為出色的機器人。
AI取代白領工作
最後回到那個核心問題:AI智能體將開始實際使用電腦,完成白領工作,為什麼是未來幾年內的事?為什麼不是幾十年?
關鍵是:這種未來是不是即將到來?
我們該做的,是構建一個類似SWE-bench的評估系統。
不僅評估軟件工程,還要擴展到所有白領工作。
把它們拆解成可衡量的任務,進行跟蹤和測量。
比如:你能不能靠互聯網賺錢?這是一個非常清晰的獎勵信號。
但要做到這一點,需要一整套複雜行為組合。
如果用這種「容易判斷的獎勵信號」進行預訓練,會非常有幫助。
例如:
這些信號都可以用來訓練模型。
只要模型能完成這條「長路徑」,它就能學到真正有用的能力。
相反,如果一直卡在
「每生成5個token就要給一次獎勵」的模式, 訓練過程會變得非常慢,效率也很低。
假設能用美國全部電腦的螢幕行為數據,只要預訓練一次,就可以設計出完全不同的強化學習任務。
這是理解強化學習的關鍵思維方式:
只要能拿到最終獎勵,長任務反而更容易評估效果。
比起只用互聯網上現有的公開數據,這種訓練方式會強得多,泛化能力也更好。
接觸到的數據越多,設計的訓練任務就越豐富。
我們需要構建連續分佈的行為數據庫。
但這也帶來一個問題:
當模型處理的任務越來越長、越來越複雜,它拿到 第一個獎勵信號 的時間也會越來越久。
這意味着:每完成一次任務,所需的算力也會顯著增加。
所以整體進展的速度,可能會因此變慢。
因為你必須花更多計算資源,才能判斷一次任務是否成功。
這個說法直覺上沒錯。
但別忘了,人類面對困難任務時,非常擅長拆解步驟、重點練習難點。
一旦模型把基礎能力打牢,AI也可以像人一樣:跳過簡單部分,專練最難的環節。
沒有捷徑,大力出奇跡
沒有什麼通向AGI的神奇捷徑。
你要想搞出真正通用的智能系統,
就必須擴規模、上大模型,願意為此付出更多計算成本。
這就是「苦澀的教訓」,必須接受。

圖靈獎得主Richard S. Sutton提出了強化學習的「苦澀的教訓」
當然,也不是說無腦堆大。
真正的科學問題是:
什麼時候用RL最合適?
因為需要模型不僅能「學」,還能在稀疏獎勵下自己「發現要學什麼」:
如果模型太小——推理很快,但學不到什麼有用的東西;
如果模型太大——學得快,但推理太慢,算力消耗太大,不划算。
所以這其實是一個「帕累託前沿」(Pareto Frontier)問題:
在當前這套模型能力+訓練環境下:
這就是現在大家都在做的「平衡的科學」。
尤其在強化學習中,模型要生成大量token,才能從中學習並獲取反饋。
這部分對推理能力和執行效率的要求非常高。
訓練再好,如果推理慢或太貴,也難以落地。
這就是「訓練好」≠「實用性好」的現實挑戰。
AI之下,迎接未來
那如果你是大學生,或者剛開始職業生涯的人,現在該怎麼辦?
Sholto Douglas等人建議:
別隻押注一個未來。
想象整個「可能世界的光譜」,提前為它們做準備。
最可能發生的情況是:你將擁有遠超以往的槓桿能力。
其實,這已經開始了。
很多YC初創公司,已經靠Claude寫出大部分代碼。
想象一下:
你要為這樣的未來做好準備。
當然,這一切仍然需要技術深度。
也許某一天,AI會在所有領域全面超越人類。但在那之前,還有一個很長的「合作階段」。
黃仁勳曾說過:「我身邊有十萬個通用智能, 但我依然有價值。 因為是我在告訴它們目標是什麼。」
在未來很多年裏,人類仍然非常重要。 只要那一天還沒到,你就還有機會和價值。
所以,請做好準備,迎接多個版本的未來。
打破限制,勇於探索
如果真的全被AI取代,那你做什麼都無所謂;但在所有其他可能性中,你的選擇非常重要。
Sholto Douglas等人給學生的建議是:掌握技術,打好基礎:學生物、學計算機、學物理。
更重要的是:認真想清楚,你最想改變世界的是什麼?
你可以學,而且比任何時候都容易。
每個人都擁有了「無限完美的私人導師」。
別讓你以前的工作方式或專業背景變成束縛。
短期內,需要認真思考:
現在還有太多「唾手可得」的效率提升空間。
很多人甚至連完整提示都沒寫過、沒舉過幾個例子、沒把AI接入工作流程,就放棄了。
人類本身就是生物意義上的通用智能。很多有價值的能力是通用的。
你以前學的專業、積累的經驗,可能沒你以為的那麼限制你。
Anthropic的很多員工也不是「AI出身」。
但他們天賦強、動機足、腦子快,來自各個領域,卻都能做得很好。
不需要什麼「權威機構」的許可,才能進入AI領域。
只要你願意開始、願意嘗試、願意申請,你就可以參與,也能為AI做貢獻。
參考資料:
https://www.dwarkesh.com/p/sholto-trenton-2 https://x.com/natolambert/status/1926293613312442810