炒股就看金麒麟分析師研報,權威,專業,及時,全面,助您挖掘潛力主題機會!
大自然用了億萬年優化的神經算法,或許正是突破當前人工智能瓶頸的鑰匙。[1]」近日,美國哈佛大學團隊和合作者探索了生物強化學習中多個時間尺度的存在,藉此證明在多個時間尺度上學習的強化學習智能體具有獨特的計算優勢,並發現在執行兩種行為任務的小鼠實驗中,當多巴胺能神經元(Dopaminergic Neurons)編碼獎賞預測誤差時,表現出了多樣化地折扣時間常數的特性。
這一成果為理解多巴胺能神經元的功能異質性提供了新範式,為「人類和動物使用非指數折扣」這一經驗性觀察提供了機制基礎,並為設計更高效的強化學習算法開闢了新途徑。
 圖 | 相關論文(來源:Nature)
圖 | 相關論文(來源:Nature)日前,相關論文發表於Nature[2],加拿大麥吉爾大學助理教授、原美國哈佛大學博士後研究員保羅·馬賽(Paul Masset)是第一作者兼共同通訊作者。
 (來源:https://mila.quebec/en/directory/paul-masset)
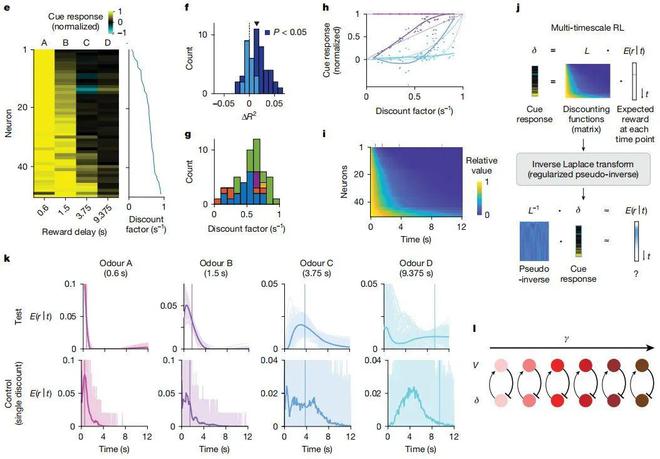
(來源:https://mila.quebec/en/directory/paul-masset)研究中,研究團隊使用專有模型解釋了時間折扣(temporal discounting)的異質性,這種異質性既體現在由線索引發的瞬時反應中,也體現在被稱為「多巴胺斜坡」的較慢時間尺度波動裏。其中的關鍵在於,單個神經元在不同任務中測量得到的折扣因子具有顯著相關性,這表明這些折扣因子擁有同一種細胞特異性屬性。
需要說明的是,時間折扣(Temporal Discounting)是指個體對獎勵或懲罰的主觀價值評估會隨着時間延遲而下降的心理現象。這一概念在行為經濟學、神經科學和強化學習領域具有重要意義。折扣因子(Discount Factor)則是強化學習中的核心參數,用於衡量智能體對於未來獎勵的重視程度。

大腦中的強化學習也表現出多時間尺度特性嗎?
不少人工智能領域的最新進展都依賴於時序差分(TD,temporal difference)強化學習。在這一學習方法中,時序差分的學習規則被用於學習預測信息。
在該領域之中,人們基於對於未來的預期值,來不斷地更新當前的估計值,這讓時序差分方法在解決「未來獎賞預測」和「行動規劃優化」這兩類任務上展現出了卓越性能。
對於傳統時序差分學習來說,它採用固定折扣因子的標準化設定,即僅僅包含單一學習時間尺度。這一設定在算法收斂後會導致指數折扣的產生,即未來獎勵的價值會隨着時間單位呈現出固定比例的衰減。
儘管這種固定折扣因子的標準化設定,對於保持學習規則的簡潔性和自洽性至關重要,但是衆所周知的是人類和動物這些生物體在進行跨期決策時,並不會表現出指數型折扣行為。
相反,生物體普遍表現出雙曲線折扣行為:即獎賞價值會隨延遲時間出現「先銳減、後緩降」的特徵。
人類與動物這些生物體能夠動態地調節自身的折扣函數,以便適應環境的時間統計特性。而當這種調節功能失調的時候,可能是出現心理異常或罹患某種疾病的標誌。
研究團隊表示,將時序差分學習規則加以進一步擴展之後,能夠讓人造神經系統與生物神經系統學習更加複雜的預測表徵。越來越多的證據表明,生物系統中存在豐富的時間表徵,尤其是在基底神經節中。需要說明的是,基底神經節是脊椎動物大腦中一組起源不同的皮質下核。而探明這些時間表徵到底是如何學習的,仍然是神經科學領域和心理學領域的一個關鍵問題。
在大多數時間學習理論中,一個重要組成部分便是多重時間尺度的存在,這使得系統能夠捕捉不同持續時間範圍內的時間依賴性:較短的時間尺度,通常能夠處理快速變化的關係以及即時依賴性關係;較長的時間尺度,通常能夠捕捉緩慢變化的特徵以及處理長期依賴性關係。
此外,人工智能領域的研究表明,通過納入多個時間尺度的學習,深度強化學習算法的性能可以得到提升。那麼,大腦中的強化學習是否也表現出這種多時間尺度特性?
為此,研究團隊研究了多時間尺度強化學習的計算含義。隨後,他們發現多巴胺能神經元會在不同的時間尺度上編碼預測,從而能為大腦中的多時間尺度強化學習提供潛在的神經基礎。
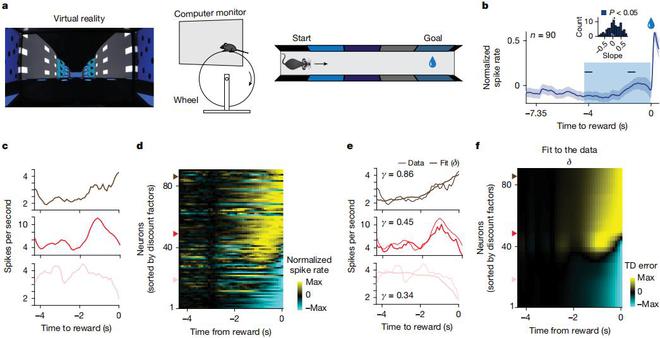 (來源:Nature)
(來源:Nature)
解釋多巴胺能神經元活動背後的多個原理
研究團隊發現,對於在各類複雜問題中的表現來說,那些採用多時間尺度學習的強化學習智能體,遠遠優於採用單一時間尺度的智能體。
為了說明多時間尺度表徵的計算優勢,他們展示了幾個示例任務:包括一個簡單的線性迷宮、一個分支迷宮、一個導航場景和一個深度 Q 網絡(DQN,deepQ-network)場景。
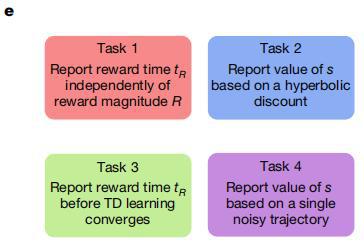 (來源:Nature)
(來源:Nature)在線性迷宮任務中,智能體需要在一條線性軌道中導航,並會在特定時間點(tR)遇到一定大小的獎勵(R)。
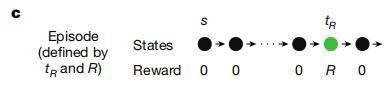 (來源:Nature)
(來源:Nature)R 和 tR 的數值會在不同的回合之間變化,但在同一回合內保持不變。每個回合由在初始狀態(s)呈現的提示信號開始。
在每個回合之中,智能體通過簡化強化學習算法,利用單個折扣因子或多個折扣因子來計算線索所預測的未來獎賞。
同時,智能體基於已經習得的線索關聯價值,通過解碼網絡針對價值信息進行任務特異性轉換,最終生成與任務需求相匹配的行為輸出。
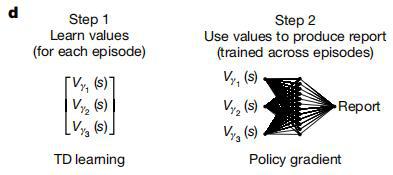 (來源:Nature)
(來源:Nature)由於某些任務涉及到多時間尺度值上的複雜非線性操作,於是研究團隊使用策略梯度為每個任務訓練了一個通用的非線性解碼器。
鑑於本次研究旨在評估多時間尺度價值表徵相比單時間尺度表徵的核心優勢,以及旨在探究這些優勢能在多大程度上被一個與代碼無關的簡易解碼器所利用。因此,在研究團隊的模型中,多時間尺度價值信號並不直接驅動行為輸出,而是作為一種增強型狀態表徵,以便能為後續任務特異性行為的解碼提供信息基礎。
通過此,他們分析了多時間尺度強化學習智能體的獨特計算優勢,並表明這一視角能夠解釋多巴胺能神經元活動背後的多個原理。
 (來源:Nature)
(來源:Nature)
為新一代算法設計帶來革命性啓示
研究團隊表示,「將多巴胺能神經元理解為通過時序差分強化學習算法計算獎勵預測誤差」的觀點,徹底改變了人們對於這類神經元的功能的認知。
但是,也有研究通過拓展記錄位點的解剖學範圍,揭示了多巴胺神經元響應存在顯著的異質性,不過這些發現難以在經典的時序差分強化學習框架中得到合理解釋。
同時,許多看似異常的發現可以在強化學習框架的擴展中得到調和和整合,從而進一步加強時序差分理論在捕捉大腦學習機制複雜性方面的強大能力和通用性。
在這項工作中,研究團隊還揭示了多巴胺能神經元異質性的另一個來源:即它們能在多個時間尺度上編碼預測誤差。
綜合來看,這些結果表明此次所觀察到的多巴胺反應中的一部分異質性,反映了強化學習框架中關鍵參數的變化。
相比傳統強化學習框架中基於標量預測誤差的方法,多巴胺系統能夠學習和表徵更豐富的信息,這是因為多巴胺系統使用了「參數化向量預測誤差」。在「參數化向量預測誤差」中,包含了對於獎勵函數未來時間演化的離散拉普拉斯變換。
需要說明的是,離散拉普拉斯變換(DLT,Discrete Laplace Transform)是經典拉普拉斯變換在離散時間或離散空間上的推廣,主要用於信號處理、系統控制和機器學習等領域。
另據悉,調整折扣因子已被用於在多種算法中提升性能,相關方法包括:通過元學習獲取最優折扣因子、學習依賴狀態的折扣因子,以及結合併行指數折扣智能體。
但是,神經元通過任務或情境來適配全局折扣函數的募集機制是什麼?解剖位置與折扣行為之間的關聯是什麼?以及 5-羥色胺等其他神經遞質對這種適配的貢獻是什麼?這些都是尚未解決的問題。
同樣的,向量化誤差信號對於下游時間表徵的調控機制仍有待進一步研究。而理解這種神經資源「調動」機制的背後原理,有助於人們在機制層面理解時間尺度多樣性在時間決策中的校準作用與失調作用。
目前,研究團隊所面臨的一個難題是,強化學習理論使用指數折扣,而人類和動物這些動物體經常表現出雙曲線折扣。
此前曾有研究探索了多巴胺能神經元的折扣機制,並認為單個多巴胺能神經元表現出雙曲線折扣。然而,此前這一研究採用非提示性獎勵反應作為零延遲獎勵的測量指標,這種方法可能導致結果更加偏向於雙曲線折扣模型。
相比之下,本次研究團隊的數據與單個神經元水平的指數折扣保持一致,這表明每個多巴胺能神經元所定義的強化學習機制,和強化學習算法的規則是互相符合的。
當這些不同的指數折扣在生物體層面結合時,可能會出現類似雙曲線的折扣。也就是說,多個時間尺度對全局計算的相對貢獻決定了生物體水平的折扣函數,並且該函數會根據環境風險率的不確定性進行校準。
因此,適當地引入折扣因子的異質性,對於適應環境的時間不確定性非常重要。這一觀點也與分佈式強化學習假說存在相似之處,該假說認為樂觀與悲觀的校準失衡會導致習得價值出現偏差。
由於遺傳、發育或轉錄因素導致的這種分佈偏差,可能會使生物體在學習過程中要麼傾向於追求短期目標、要麼傾向於追求長期目標。同樣的,這種觀點也可用於指導算法設計,使其能夠調動並利用這些自適應的時間預測。
總的來說,本次成果創立了一個全新的研究範式,能被用於解析多巴胺能神經元中預測誤差計算的功能機制,這不僅為生物體疾病狀態下的跨期決策障礙提供了新的機理解釋,更為新一代算法的設計帶來了重要啓示。
參考資料:
1.https://www.ebiotrade.com/newsf/2025-6/20250605082948946.htm
2.Masset, P., Tano, P., Kim, H.R.et al. Multi-timescale reinforcement learning in the brain.Nature(2025). https://doi.org/10.1038/s41586-025-08929-9
排版:溪樹