英偉達推出ProRL方法:強化學習訓練至2000步,打造全球最佳1.5B推理AI模型
IT之家 6 月 5 日消息,科技媒體 marktechpost 昨日(6 月 4 日)發佈博文,報道稱英偉達推出 ProRL 強化學習方法,並開發出全球最佳的 1.5B 參數推理模型 Nemotron-Research-Reasoning-Qwen-1.5B。
背景簡介
推理模型是一種專門的人工智能系統,通過詳細的長鏈推理(Chain of Thought,CoT)過程生成最終答案。
強化學習(Reinforcement Learning,RL)在訓練中扮演非常重要的角色,DeepSeek 和 Kimi 等團隊採用可驗證獎勵的強化學習(RLVR)方法,推廣了 GRPO、Mirror Descent 和 RLOO 等算法。
然而,研究者仍在爭論強化學習是否真正提升大型語言模型(LLM)的推理能力。現有數據表明,RLVR 在 pass@k 指標上未能顯著優於基礎模型,顯示推理能力擴展受限。
此外,當前研究多集中於數學等特定領域,模型常被過度訓練,限制了探索潛力;同時,訓練步數通常僅數百步,未能讓模型充分發展新能力。
ProRL 方法的突破與應用
英偉達研究團隊爲解決上述問題,推出 ProRL 方法,延長強化學習訓練時間至超過 2000 步,並將訓練數據擴展至數學、編程、STEM、邏輯謎題和指令遵循等多個領域,涵蓋 13.6 萬個樣本。
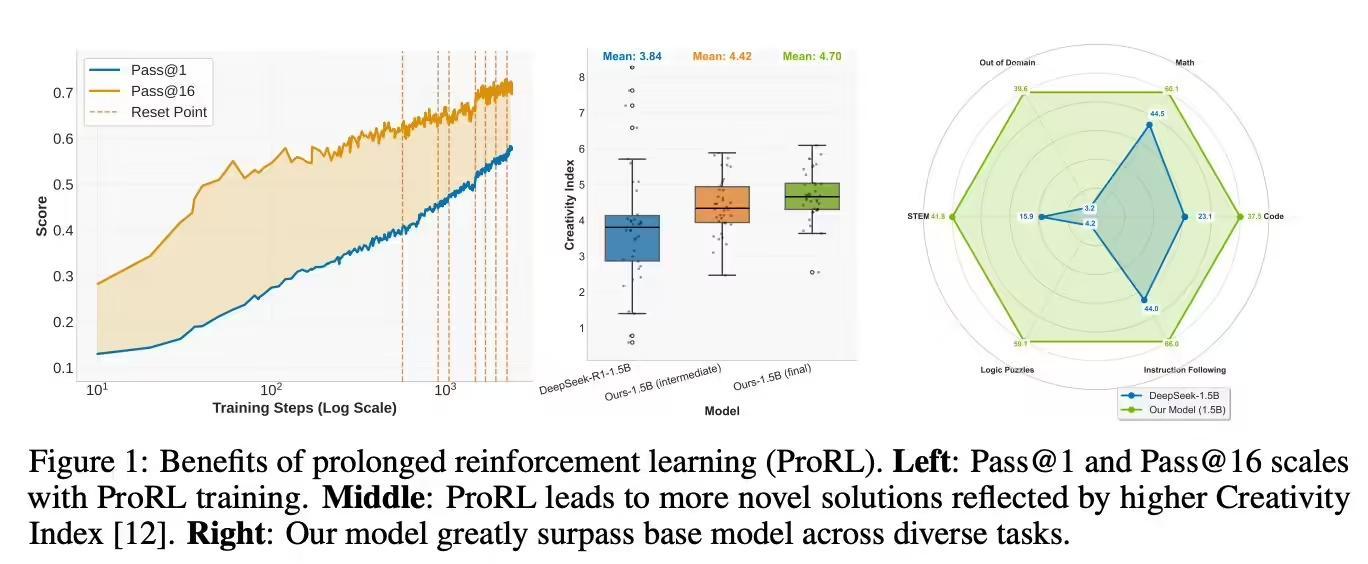
他們採用 verl 框架和改進的 GRPO 方法,開發出 Nemotron-Research-Reasoning-Qwen-1.5B 模型。
這是全球最佳的 1.5B 參數推理模型,在多項基準測試中超越基礎模型 DeepSeek-R1-1.5B,甚至優於更大的 DeepSeek-R1-7B。
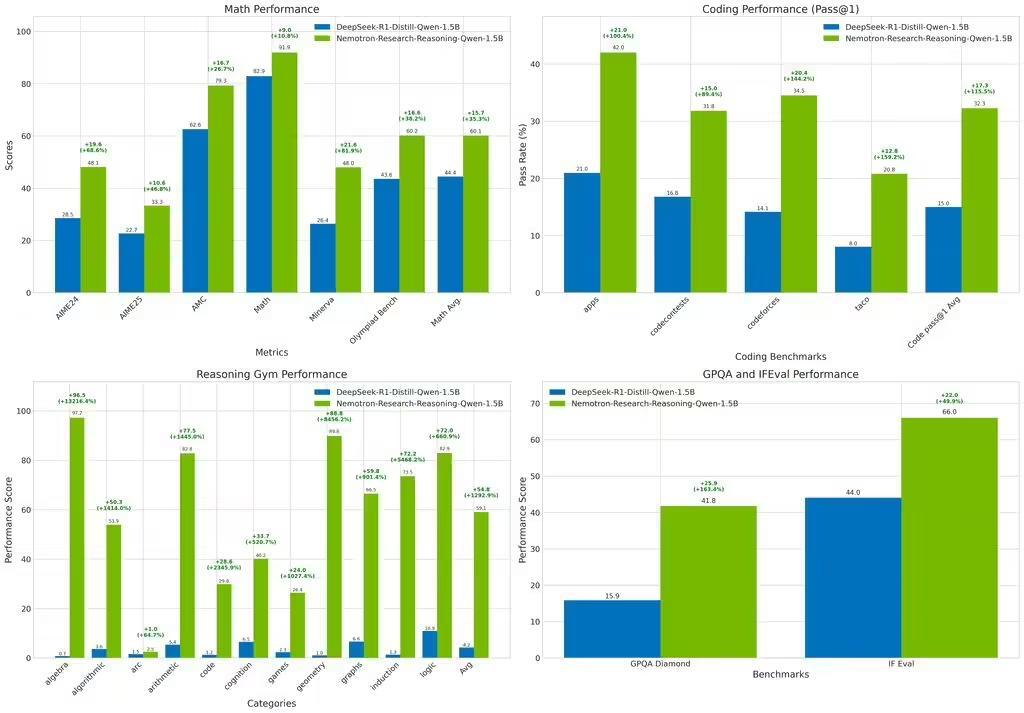
測試結果顯示,該模型在數學領域平均提升 15.7%,編程任務 pass@1 準確率提升 14.4%,STEM 推理和指令遵循分別提升 25.9% 和 22.0%,邏輯謎題獎勵值提升 54.8%,展現出強大的泛化能力。
免責聲明:投資有風險,本文並非投資建議,以上內容不應被視為任何金融產品的購買或出售要約、建議或邀請,作者或其他用戶的任何相關討論、評論或帖子也不應被視為此類內容。本文僅供一般參考,不考慮您的個人投資目標、財務狀況或需求。TTM對信息的準確性和完整性不承擔任何責任或保證,投資者應自行研究並在投資前尋求專業建議。
熱議股票
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10