炒股就看金麒麟分析師研報,權威,專業,及時,全面,助您挖掘潛力主題機會!
大模型≠隨機鸚鵡!Nature子刊最新研究證明:
大模型內部存在着類似人類對現實世界概念的理解。
LLM能理解現實世界和各種抽象概念嗎?還是僅僅在「鸚鵡學舌」,純粹依靠統計概率預測下一個token? 長期以來,AI社區對這一問題存在很大的分歧。
有一種猜測是,純粹基於語言的形式(例如訓練語料庫中token的條件分佈)進行訓練的語言模型不會獲得任何語義。
相反,它們僅僅是根據從訓練數據中收集的表面統計相關性來生成文本,其強大的湧現能力則歸因於模型和訓練數據的規模。這部分人將LLM稱為「隨機鸚鵡」。
但現在研究證明,並非如此!
中國科學院自動化研究所與腦科學與智能技術卓越創新中心的聯合團隊在《Nature Machine Intelligence》發表題為《Human-like object concept representations emerge naturally in multimodal large language models》的研究。

團隊通過行為實驗與神經影像分析相結合,分析了470萬次行為判斷數據,首次構建了AI模型的「概念地圖」,證實多模態大語言模型(MLLMs)能夠自發形成與人類高度相似的物體概念表徵系統。
研究邏輯與科學問題:從「機器識別」到「機器理解」
傳統AI研究聚焦於物體識別準確率,卻鮮少探討模型是否真正「理解」物體含義。
論文通訊作者何暉光研究員指出:「當前AI能區分貓狗圖片,但這種‘識別’與人類‘理解’貓狗的本質區別仍有待揭示。」
團隊從認知神經科學經典理論出發,提出三個關鍵問題:
為回答這些問題,團隊設計了一套融合計算建模、行為實驗與腦科學的創新範式。
研究採用認知心理學經典的「三選一異類識別任務」
(triplet odd-one-out)
,要求模型與人類從物體概念三元組
(來自1854種日常概念的任意組合)
中選出最不相似的選項。
通過分析470萬次行為判斷數據,團隊首次構建了AI模型的「概念地圖」
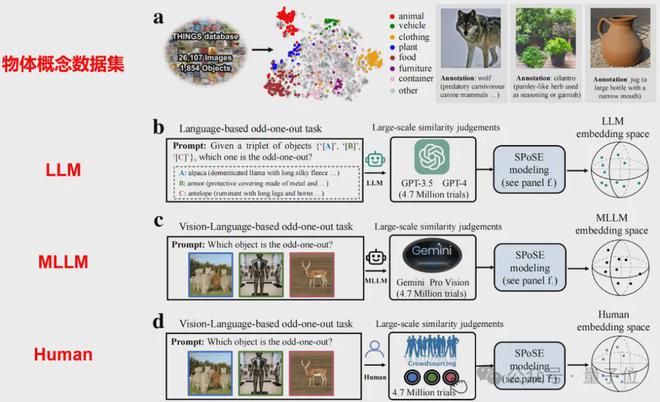
具體來說,本研究突破傳統神經網絡節點分析範式,首創「行為認知探針」方法:
「我們不是通過解剖AI模型內部的海量神經元來理解它,而是讓AI像人類一樣做選擇題,從而逆向破解它的認知系統。」論文第一作者杜長德解釋道。這種方法為研究閉源商業模型(如GPT-4)的認知特性提供了可行路徑。
核心發現:AI的「心智維度」與人類殊途同歸
核心發現有以下幾點。
1、低維嵌入揭示普適認知結構
研究採用稀疏正定相似性嵌入方法,從海量大模型行為數據中提取出66個核心維度。
令人驚訝的是,純文本訓練的ChatGPT-3.5與多模態Gemini模型均展現出穩定的低維表徵結構,其預測人類行為選擇的準確度分別達到噪聲上限的87.1%和85.9%。這暗示不同架構的AI模型可能收斂到相似的認知解決方案。
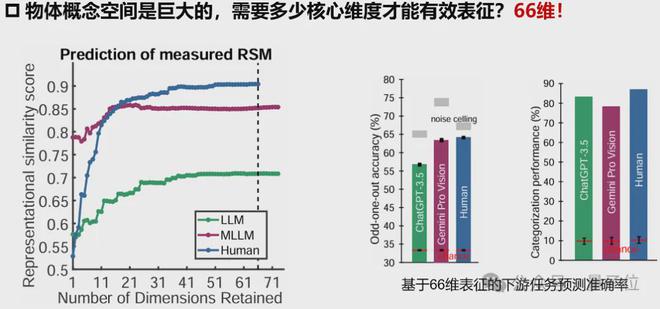
2、湧現的語義分類能力
在沒有顯式監督的情況下,模型自發形成了18個高級物體概念類別
(如動物、工具、食物)
的聚類
(圖3)
MLLM的分類準確率達78.3%,接近人類的87.1%,顯著高於傳統視覺模型
(包括監督學習、自監督學習等模型)
值得注意的是,模型表現出與人類一致的「生物/非生物」「人造/自然」分類邊界,印證了認知神經科學的經典發現。

3、可解釋的認知維度
研究為AI模型的「思考維度」賦予語義標籤。例如:



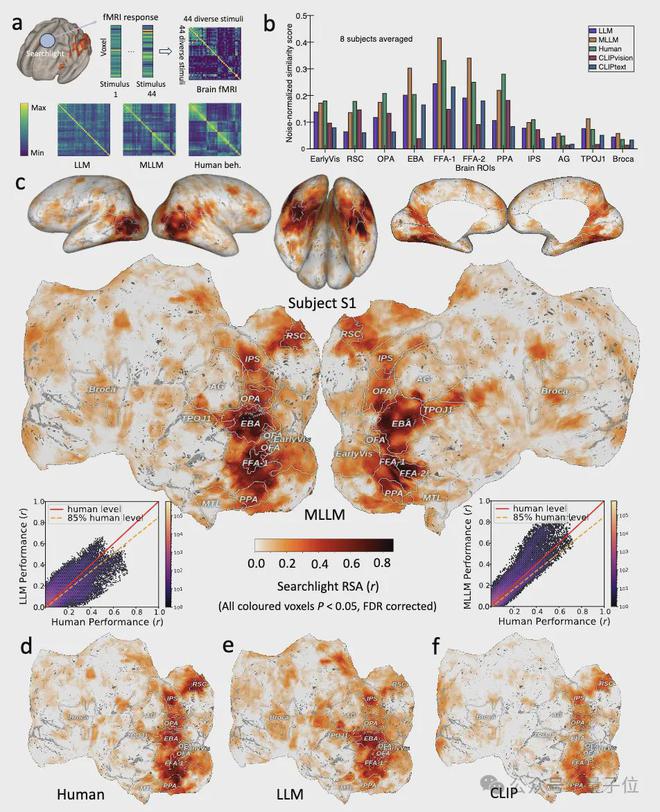
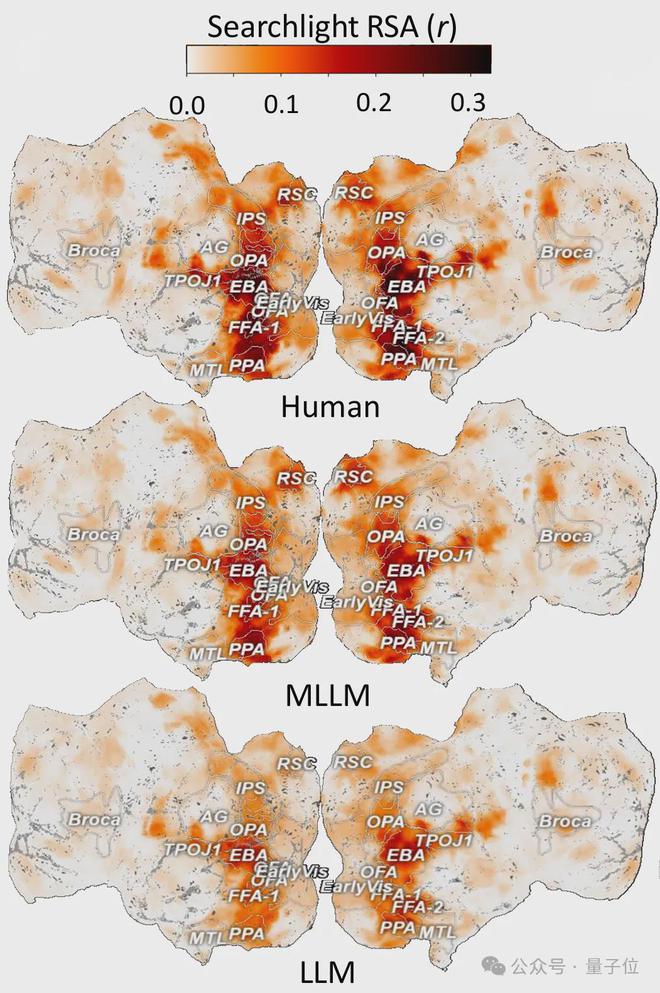
4、與大腦神經活動的驚人對應
通過分析7T高分辨率fMRI數據
(NSD數據集)
,團隊發現MLLM的表徵與大腦類別選擇區域
(如處理面孔的FFA、處理場景的PPA、處理軀體的EBA)
的神經活動模式顯著相關。
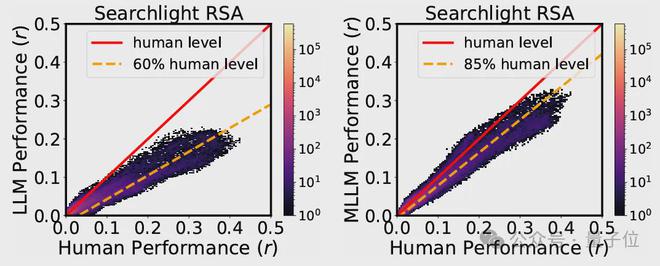
在梭狀回面孔區
(FFA)
,MLLM的低維「心智」嵌入預測神經活動的準確度達到人類水平的85%,遠超純文本模型
(60%)
這一發現為「AI與人類共享概念處理機制」提供了直接證據。
5、哪個模型在行為選擇模式上更接近人類?
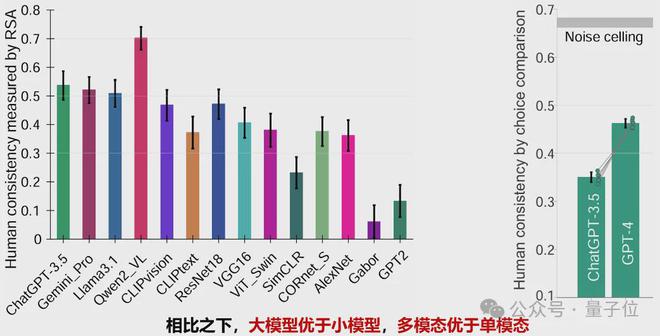
研究還對比了多個模型在行為選擇模式上與人類的一致性
(Human consistency)
結果顯示,大模型
(如ChatGPT-3.5、Gemini_Pro、Qwen2_VL)
和多模態模型
(如CLIP)
在一致性方面表現更優,而傳統單模態模型
(如 ResNet18、VGG16、AlexNet、GPT2)
一致性得分較低。
此外,隨着模型性能的提升
(如從ChatGPT-3.5到GPT-4)
,一致性得分顯著提高,但仍有一定提升空間,尚未達到理論上限
(Noise ceiling)
總體而言,大模型和多模態模型在模擬人類行為選擇模式上更具優勢。
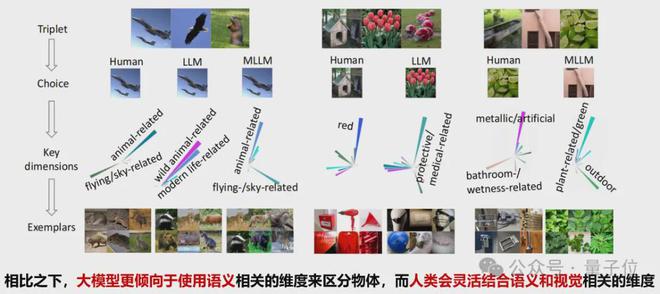
6、人類和大模型做決策時所依賴的主要維度有什麼不同?
下圖展示了人類與LLM及MLLM在決策判斷任務中所依賴的關鍵維度的差異。
通過一系列三元組選擇示例,揭示了人類在做決策時更傾向於結合視覺特徵和語義信息進行判斷,而大模型則傾向依賴於語義標籤和抽象概念。
儘管兩者在某些選擇上趨於一致,但在背後起作用的關鍵認知維度也存在一些區別:
人類更具靈活性和感知整合能力,而模型則更側重語言驅動的語義歸類。這種對比反映出當前人工智能在模仿人類決策過程中的侷限性與進步空間。
本文研究發現具有廣闊的應用前景,包括:
團隊還指出了下一步重點:
團隊簡介
自動化所副研究員杜長德為第一作者,何暉光研究員為論文通訊作者。

杜長德,中國科學院自動化研究所副研究員,碩士生導師。
杜長德從事腦認知與人工智能方面的研究,在神經信息編解碼、多模態神經計算、NeuroAI、腦機融合智能等方面發表論文50餘篇,包括Nature Machine Intelligence、IEEE TPAMI、ICLR、ICML等。
曾獲得2019年IEEE ICME Best Paper Runner-up Award、2021年AI華人新星百強、中國科學院院長優秀獎等。長期擔任Nature Human Behaviour, TPAMI等重要期刊的審稿人。個人主頁:https://changdedu.github.io/

何暉光
,中國科學院自動化研究所研究員,博士生導師,國家高層次人才,中國科學院大學崗位教授,上海科技大學特聘教授。
其研究領域為腦-機接口、類腦智能、醫學影像分析等,在CNS子刊, IEEE TPAMI, ICML等發表文章200餘篇。他還是自動化學報編委,CCF/CSIG傑出會員。
論文的主要合作者還包括腦智卓越中心的常樂研究員等。該研究得到了中國科學院基礎與交叉前沿科研先導專項、國家自然科學基金、北京市自然科學基金項目以及腦認知與類腦智能全國重點實驗室的資助。
團隊還表示正在招收2026級博士生、碩士生。招生方向:腦機接口、NeuroAI、類腦智能、腦機融合智能等。歡迎對此方向感興趣的同學報考(郵箱:changde.du@ia.ac.cn)。
論文鏈接:https://www.nature.com/articles/s42256-025-01049-z
代碼:https://github.com/ChangdeDu/LLMs_core_dimensions
數據集:https://osf.io/qn5uv/