炒股就看金麒麟分析師研報,權威,專業,及時,全面,助您挖掘潛力主題機會!

為了防止高考生使用AI作弊,今年高考期間,騰訊混元、通義千問、Kimi、豆包等國內知名AI大模型的圖片識別問答功能均暫停服務。對於這些企業的做法,小雷卻有一些質疑,之前小雷測試AI大模型做高考題,大多表現不佳,暫停圖片識別問答服務似乎過於高看自家AI大模型的能力。
到截稿時,2025年高考全國一卷僅有語文、英語和數學三套試卷公布,其中語文高考題目曝光後,已有多家媒體實測AI大模型撰寫作文。不過作文寫得如何,每個人的觀點可能不同,小雷看到的幾篇評測基本是截取AI大模型撰寫的文章,沒有給出點評,文章質量需要讀者評判。
 (圖源:百度搜索截圖)
(圖源:百度搜索截圖)慎重起見,小雷選擇了有標準答案的數學科目,測試AI大模型的能力,所選的AI大模型分別為DeepSeek、豆包、訊飛星火、文心一言、Kimi、通義千問,它們能考上985、211嗎?
首先說一下測試環境和題目,考慮到部分AI大模型不支持手動開關聯網模式,因而所有AI大模型啓用聯網搜索,深度思考功能也全部打開。
所選的數學題,包含一道單選題、一道多選題、一道填空題、一道簡答題,最終會按照題目的分數進行打分。
第一道題屬於開胃小菜,難度不算大,參與測試的六款AI大模型也沒有令小雷失望,全部計算出了正確答案,而且給出了詳細推理過程。本題測試中,所有AI大模型均獲得滿分5分。(圖片從左往右以此為:DeepSeek、訊飛星火、豆包、Kimi、文心一言、通義千問,下圖同)
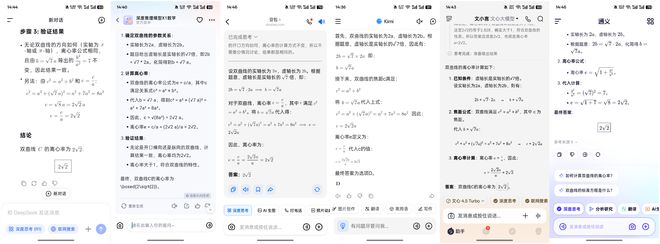 (圖源:App截圖)
(圖源:App截圖)儘管這道題難度不算高,但這六款AI大模型的表現令小雷眼前一亮。此前測試AI大模型的數學計算能力時,面對稍微複雜一些的問題,AI大模型很難計算出正確答案。
僅一輪測試,DeepSeek、訊飛星火、豆包、文心一言、Kimi、通義千問六款AI大模型就證明了它們的能力,存在被高考生用於的作弊的可能性,暫停圖片識別問答功能絕非為了蹭高考的熱度。
這道題難度相當高,僅有豆包在兩分鐘內計算出正確答案,訊飛星火和通義千問耗時略長一些,其他幾款AI大模型用時更長,尤其是DeepSeek,耗時足足572秒,接近10分鐘。
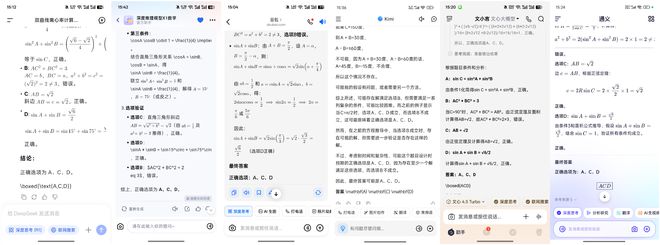 (圖源:App截圖)
(圖源:App截圖)若是AI大模型像考生一樣每次只做一道題,推理較慢的三款AI大模型,存在兩小時時間做不完題的可能性。
儘管本輪測試中所有AI大模型均正確回答出了問題,但結合推理所需時長來看,豆包、訊飛星火、通義千問表現較好。
與上一題相比,這一題的難度有所下降,訊飛星火、文心一言、Kimi、通義千問、DeepSeek五款大模型均迅速計算出了正確答案,文心一言幾乎是秒算。豆包雖計算出了正確答案,但在輸出答案時卻犯了迷糊,排除了-2。因此,小雷不得不扣掉豆包的三分,該題豆包只能得2分。
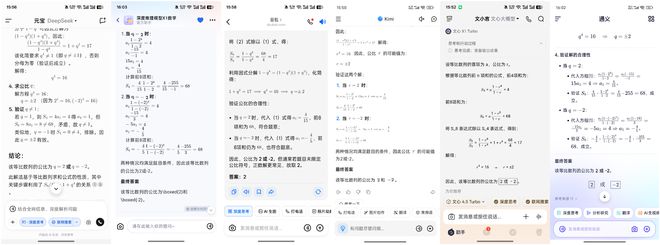 (圖源:App截圖)
(圖源:App截圖)在本輪測試中,DeepSeek服務器繁忙的問題頻繁發生,小雷不得不借助第三方應用。好在,現階段許多AI應用已接入DeepSeek,小雷使用的騰訊元寶App,無論是推理速度,還是穩定性,都遠高於DeepSeek網頁版或App。
前三道題,幾款AI應用僅在體驗上存在一定的差異,能力基本沒有表現出區別,第四道題不同,它的複雜度遠超前面三道題,也是檢驗AI大模型能力最重要的一項挑戰。
在本輪測試中,豆包、訊飛星火、Kimi、文心一言、DeepSeek依然表現出色,正確計算出了兩道題的答案。通義千問解答這道題時,能夠推理出第一道小題的答案,但第二道小題卻給出了錯誤答案,表現稍遜一籌。
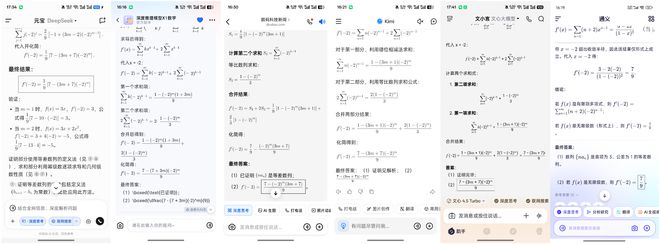 (圖源:App截圖)
(圖源:App截圖)豆包、訊飛星火、文心一言、Kimi、DeepSeek可以在本輪測試中拿到滿分17分,通義千問因答錯了第二道小題,只能獲得7分。
依靠公式和邏輯推理的數學題,似乎更符合AI的特性,但往年的評測中,AI大模型通常做閱讀理解和寫作文效果較好,面對複雜的數學題找不到答題方法。
光明網在去年6月的報道中提到,復旦大學NLP實驗結果顯示,AI大模型在做2024年高考題時,在語文領域的表現遠強於數學,部分數學題AI大模型甚至全軍覆沒,沒有一個能夠正確計算出答案,遇到多選題時也是錯誤頻出。究其原因,數學失之毫釐差之千里,不能出一丁點錯誤,文史類內容則可以允許出現部分錯誤和較為模糊的答案。
一年時間過去,AI大模型進步神速,深度思考模式的加入、針對數學題的專項優化,令AI大模型在處理高考數學題時更加遊刃有餘。
四道題目測試下來,最終得分如下:
經過測試,DeepSeek、訊飛星火、Kimi、文心一言均獲得滿分,豆包表現不錯,因一時疏忽,遺憾丟了三分,痛失高考狀元。通義千問計算較為簡單的問題時,都保持了極高的水準,但處理較難的問題時出現了計算錯誤,需要再接再厲。
 (圖源:豆包AI生成)
(圖源:豆包AI生成)總是向AI行業潑冷水的蘋果,日前在論文中表示,AI推理模型只是「假思考」,根本沒有穩定、可理解的推理過程,更像是記憶,處理複雜任務時可能會崩潰。AI研究者Lisan al Gaib復刻蘋果測試方法後表示,模型不是因為推理能力差失敗,而是因為蘋果限制了輸出token。
或許AI大模型推理能力仍存在上限,但我們看得到它們的進步。去年復旦大學NLP實驗室測試AI大模型時,它們面對高考數學題表現糟糕,小雷在幾次AI大模型橫評測試中,也得到了類似的結果。今年的測試中,AI大模型基本都能計算出問題的正確答案,曾經難住AI大模型的多選題,也未能再對AI大模型造成困擾。
AI大模型數學題解答能力提升,最大受惠者可能是學生群體。國內學習機廠商和教育輔導平台,已陸續加入AI答題能力,但許多設備的AI大模型僅能解答中小學問題,例如行業翹楚小猿搜題,題目庫不包含大學課程。
這六款AI大模型的優秀表現,證明了國內頭部AI企業的實力,高考數學題已被征服,高等數學也不會遠了。學習機廠商、教輔平台可以與頭部AI企業合作,增強產品AI答題的能力,繼續強化AI教育硬件業務。
