炒股就看金麒麟分析師研報,權威,專業,及時,全面,助您挖掘潛力主題機會!
CVPR 2025,自動駕駛傳來重大進展:
Scaling Law首次在這條賽道被驗證!

來自中國的小鵬汽車,完整拿出了技術方案和AI司機「智能湧現」的成果。
自動駕駛的「ChatGPT時刻」,真的要來了嗎?
CVPR 2025,小鵬汽車拿出了什麼成果
今年的CVPR線下會議在美國田納西州納什維爾舉辦,日期是6.11-6.15。觀衆老爺們看這篇推送的時候,CVPR才啱啱結束幾個小時——新鮮出爐
CVPR的自動駕駛分論壇(Workshop on Autonomous Driving),歷年都是業內極具影響力的技術風向標和盛會。比如2022年的WAD,Wayve首次披露了自己低傳感器端到端路線方案,馬上成為自動駕駛賽道炙手可熱的明星公司;再比如,特斯拉最早在CVPR WAD上詳細分享了佔用網絡技術,隨後成為業內悉數跟進的量產方案……
今年的WAD,中國的小鵬汽車是唯一一家受邀發表主題演講的車企
小鵬在演講前一天,啱啱開啓了最新SUVG7的預售,創造了量產L3級AI算力第一車的紀錄,單車算力超過2200TOPS,何小鵬將G7定義為「真正的AI汽車」。

隨之而來也有爭議:預售價23.58萬的G7不給激光雷達,智能輔助駕駛靠譜嗎?
其實答案就在小鵬CVPR的演講中。
先看實驗結果。幾個月前,小鵬汽車在後裝算力的車端部署了新一代自動駕駛基座模型,實現了無任何規則代碼託底情況下,基座模型直接控車並安全完成一系列駕駛任務。
比如絲滑地加減速、變道繞行、轉彎掉頭、等待紅綠燈等等:

整個自動駕駛系統全流程模型化,其實就是馬斯克宣講多年的AI司機,其最重要的特徵是展現出對環境、路況的全局理解和思考。
比如這個場景下,直行道上,先是前方大車切出後,然後又看到了裏邊臨停車,但系統全程沒有任何「緊急避險」的舉措,而是從容有序的減速繞行,絲滑通過場景:

再比如這個場景:系統首先提前變道,避讓施工區,但就在轉向過程中,又突遇從小路匯入主路的大貨車:

再比如雨天的窄路彎道,道路一側已經被各種違停車佔滿,行進途中又突遇臨時上下客的網約車,系統沒有絲毫猶豫,直接發起繞行:

並且在繞行過程中,還避讓了一連串在機動車道上逆行的低速電驢。
所有場景主打的是決策果斷、路線合理,體驗絲滑。
小鵬解釋,同樣的場景傳統技術方案也有概率能通過,但熟練絲滑大打折扣,乘坐體感也不行。
目前市面上幾乎所有量產智能輔助駕駛,一旦周圍目標的距離、速度相對本車達到一定區間(比如突然匯入的大車、迎面而來的電驢,極度狹窄的道路空間等),必然首先觸發緊急剎車,車內乘員一頓前俯後仰之後,可能仍然需要接管……
至於一些極端場景,是這些傳統方案很容易「宕機擺爛」的。比如這個位於福州的路口,馬路對面的主幹道上有兩棵大樹佇立,車道竟然就在這兩棵大樹之間……不是本地司機,可能根本搞不明白該怎麼走。
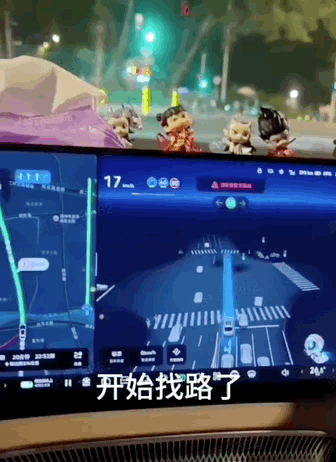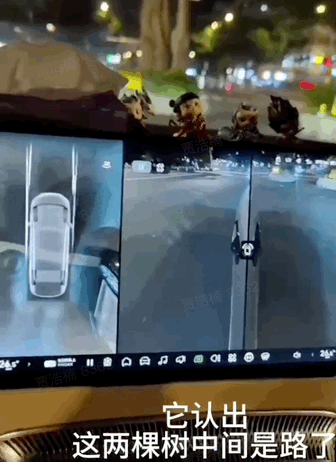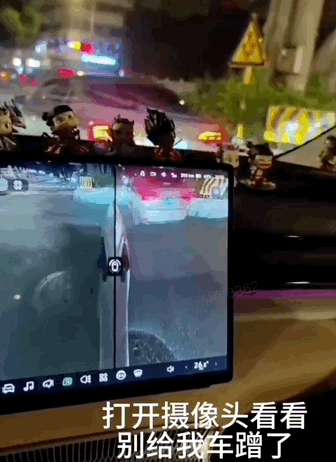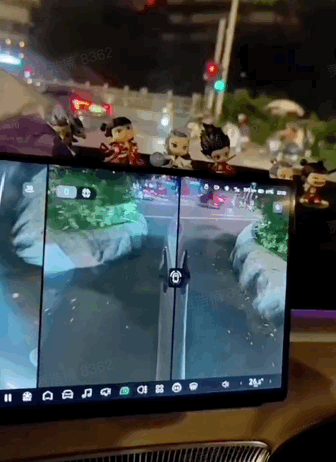
但小鵬的系統竟能準確辨識出車道,順利通過。這對目前的量產系統來說屬於「驚喜」,對於今後要上車的下一代模型來說就是「基操」。
小鵬世界基座模型負責人劉先明說,這就屬於典型的CoT場景,車端模型在整個過程中不斷實時推理:
鏈式思考能力(CoT,Chain of Thought),背後的基礎是小鵬自研的「自動駕駛基座模型」——物理世界模型。

既非行業常見的模擬訓練世界模型,也不是單一的VLA、VLM,更超出了端到端「一段或兩段」的爭論……
押注新技術路線背景下,小鵬最新的量產方案也和其他所有玩家產生了明顯不同。
小鵬的自動駕駛基座模型,到底是什麼?
上面道路實測的小鵬自動駕駛基座模型,其實就是4月小鵬公布的「下一代自動駕駛基座模型」的早期車端實測版本。
對於真正的自動駕駛模型,小鵬的理解和實踐與絕大多數業內玩家不同
現階段主流的「車端模型」,其實主體就是端到端算法,從傳感器取數據,然後輸出路線規劃,一般還會有一些強制規則安全兜底。

但小鵬認為,這種傳統模式儘管一定程度上AI化了,但端到端本質仍然是「小腦」,對輸入的道路信息做出的反應是被動式、條件反射式的關鍵這種「條件反射」還是黑盒,過程難以把握
其實也是L4玩家質疑L2路線的核心依據:不會思考的模型,數據量再大也只能模仿人類行為,無法真正超越人類達到「自動駕駛」的層級。
小鵬認為問題出在了現行的技術方案上:只侷限在車端算力的一畝三分地,模型大小是受限的,能真正消化的數據也是受限的。
只有超越車端芯片算力的限制,應用更大的模型、更海量的數據,才能真正實現車端的智能
小鵬「世界基座模型」本身是以大語言模型為骨幹網絡,使用海量優質駕駛數據訓練的VLA大模型,參數量高達720億,部署在雲端。
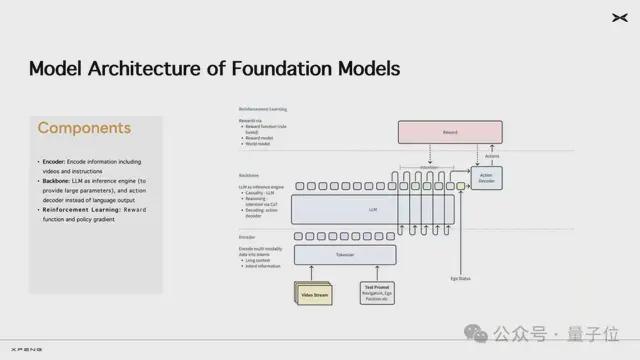
VLA,全稱Vision-Language-Action,一般同時包含視覺編碼器、語言編碼器、跨模態融合模塊、動作生成模塊,能同時理解視覺圖像、自然語言,並生成動作控制指令的AI模型架構。
2023年谷歌Robotics團隊的RT-1打響VLA第一槍,用人類操作示範構建多模態訓練集,以圖像、語言指令和連續控制信號作為輸入,訓練機器人理解語言並直接輸出動作。後續RT-2又把CLIP等視覺語言基礎模型引入控制流程中,基本奠定了「圖像+語言+動作」統一建模的VLA基線,成為具身智能和自動駕駛的新希望。
VLA特別之處在於,不再是分模塊「各自為政」,而是通過建立視覺信號、語言指令與物理動作之間的關聯映射,實現環境理解到行為輸出的閉環決策。
簡單說,過去一個任務需要分別訓練圖像識別模型、語義理解模型、控制策略模型;而現在,VLA一個模型就能從圖片和語言中「看懂任務」,並「動手完成」。
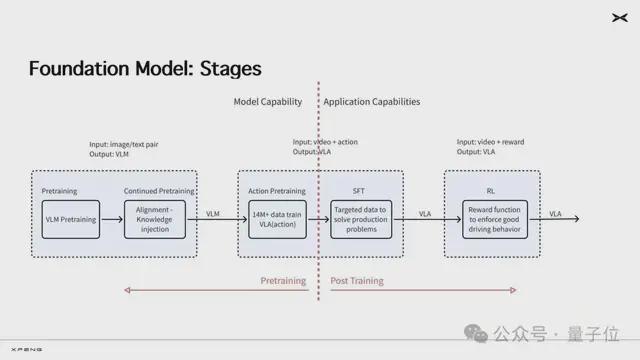
基座模型完成預訓練、監督精調(SFT)之後,就進入強化訓練階段。強化學習是小鵬基模訓練最大的特點,也是模型能力的隱形護城河。
小鵬自研開發的強化學習獎勵模型主要從三個方向上去激發基模潛能:安全、效率、合規。實際上也是人類駕駛行為中的幾個核心原則。
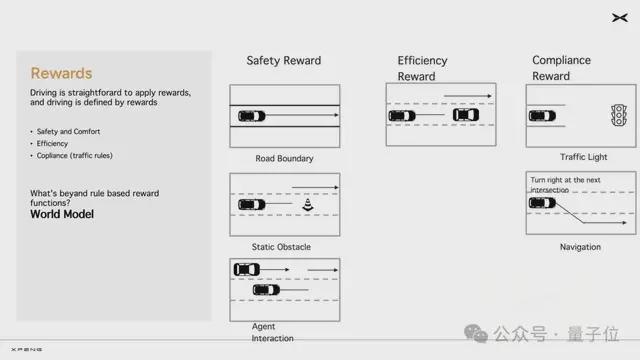
比如遇到不認識的障礙物要繞行是為了安全、路上遇到特別慢的車適時變道超車是為了通行效率、按照紅綠燈車道線道路標牌的指示開車是為了合規…….
劉先明還透露,小鵬已在開發世界模型(World Model),今後會用於基座模型的強化訓練。
世界模型被認為是自動駕駛「專用Sora」,用來生成各種交通場景的corner case,源源不斷產生高價值訓練數據。
但劉先明認為自動駕駛的世界模型遠遠不是今天的「仿真建模」,它應該是一種實時建模和反饋系統,能夠基於動作信號模擬真實環境狀態,渲染場景,更重要的是,能生成場景內其他智能體(也即交通參與者)的響應,也就是說,所有智能體都不是NPC,都需要通過跟其他智能體的交互產生博弈行為。這樣的世界模型,纔算得上一個閉環的反饋網絡。
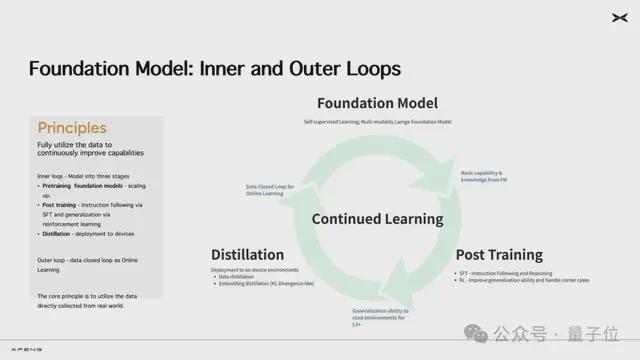
最後,雲端模型將通過知識蒸餾方式生產小尺寸模型,部署到車端,成為「AI汽車」全新的大腦。模型在車端部署之後,持續獲取新的駕駛數據和用戶反饋,又能繼續用於雲端基模的訓練,讓基模不斷迭代。這個過程被小鵬汽車稱為持續在線學習(Online Learning),由VLA和OL構成的這套技術架構,將讓基模常訓常新。
你可能會問,為什麼不用相同的數據,去直接訓練一個可在車端直接部署的小模型呢?
小鵬提到了在實踐中,同樣的數據在10億、30億、70億、720億參數上看到了非常明顯的Scaling Law效果:隨着參數規模越大,模型的能力越強
目前基座模型累計喫下了2000多萬條視頻片段(每條時長30秒)。在不斷擴大訓練數據量的過程中,研發團隊同樣清晰地看到了規模法則(Scaling Law)的顯現:
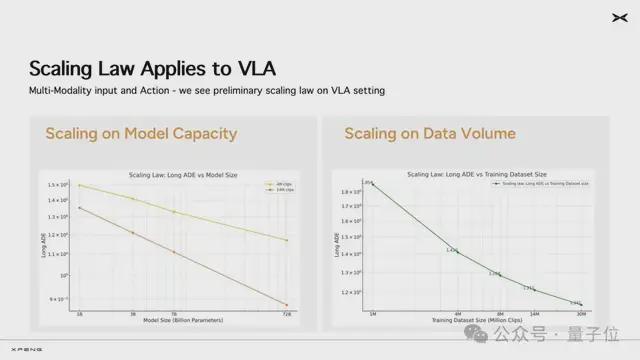
這是大模型浪潮以來,行業內首次明確驗證規模法則(Scaling Law)在自動駕駛VLA模型上持續生效
而要想把大模型的能力儘可能延續到車端相對較小的模型上,知識蒸餾是目前最好的方法。這比直接訓練一個車端小模型更難,但上限也更高
因為模型參數的利用率是有限的,雲端有更多的數據,能學到更多的東西,智能湧現效應更強。再蒸餾到車端的小模型上,可以讓小模型有更強的表現。
另外,自動駕駛本身具有「多模態」或者說「多解輸出」的特點,容易遇到「模態不統一」的困境。意思是同一個駕駛場景可能會有多種路徑選擇,而且它們都是對的。當模型使用的數據量增大,就會出現越來越多的「相似場景,多種解法」的訓練數據,對於參數量不足(智商不足)的小模型來說,可行解法越來越多,可能造成模型的confusion,導致模態坍塌。因此,直接訓練車端小模型,實際上並不能通過數據的增加實現scaling law。
但如果本身雲端訓練了更大的模型,作為老師,去教車端的模型學習,就會有「模態統一」的優勢。

另外啱啱提到的強化學習方法,同樣也是模型越大效果越好。更大的雲端模型後訓練,再向車端小模型去蒸餾,得到的結果,比直接車端的小模型做強化訓練要好得多。
這樣的時間和認知下,小鵬從2024年開始,開始開拓、押注自動駕駛以及量產車的新技術路線,明顯和所有其他玩家不同。
首先是雲端,開發具有普遍認知能力的超大規模多模態模型作為基座模型。並且為此開始儲備超級計算集羣,目前已達10 EFLOPS,集羣運行效率常年保持在90%以上,全鏈路迭代周期可達平均5天一次。
這個水平遠超其他車企,和頂尖AI科技公司相當

車端側,出於自動駕駛安全性、實時性考慮,小鵬堅持把蒸餾後的「大腦+小腦」方案完整部署在本地,避免網絡時延安全隱患。
因此,超大算力、大模型針對性優化的計算芯片就成了必須——小鵬歷時5年自研的圖靈AI芯片的,「1顆頂3顆」,單顆有效算力相當於3顆主流芯片。

新車G7最後呈現的,其實就是小鵬最新AI認知的落地:3顆圖靈AI芯片2200TOPS+有效算力,車端VLM+VLA。
小鵬汽車CEO何小鵬稱:VLM是車輛理解世界的大腦,過去我們使用語音、觸屏、按鍵來操控汽車。而不久之後,VLM將替代徹底取代這些操控手段,成為人和汽車對話操控的新一代入口。
另外VLM也像車輛行動的總指揮,指導智駕和智艙等整車能力的進化,真正實現「AI定義汽車」。
車端的VLA-OL模型,則給智能輔助駕駛增加「運動型大腦」,還進一步增強了「小腦能力」同時具備持續強化學習能力,未來進化到自主強化學習,讓大模型持續進化。
何小鵬堅信,這條路線不僅是小鵬下一階段增長引擎,更是對現行所有量產L2路線的突破,也是自動駕駛和具身智能大一統的開端。
小鵬進入AI「無人區」
小鵬在CVPR 2025上的演講,技術上是一個轉折點。
L4和L2都在堆算力。比如小馬智行、百度Apollo、文遠知行等頭部Robotaxi玩家,單車算力也都超過了1000TOPS;包括小鵬在內,蔚來、理想、極氪等等新車,也都把算力數值堆到了「千TOPS」這個級別。

但兩個陣營的方向有明顯分化。L4是為了超多傳感器冗餘堆算力,L2則是為端側超大模型堆算力,一個保下限一個拼上限。
L4陣營的大佬,過去常嘲諷質疑智能輔助駕駛,認為兩個技術體系有不可跨越的鴻溝,依據就是L2太依賴端到端,而端到端的本質是模仿,但數據來源(即人類司機)的上限永遠不可突破,下限永遠不可預測。
而小鵬的新技術路線,第一次從技術層面回應了「端到端只能模仿不能超越」的問題:跳出數據侷限性的敘事,從AI本質出發,打造一個有完整認知能力和運動規劃協調能力的「大腦」。
這套方案中,關於「上限」問題的回答是模型本身的超大參數規模帶來的能力躍升,關於「下限」問題的答案,同樣是超大規模模型對強化學習的出色反饋。

小鵬的技術路線發展方向,要解決的不僅僅是車的問題。
新G7的量產方案中,小鵬開始用一整個「AI智能體」視角解決問題:
VLM則是車輛理解世界的「大腦」,統一艙駕和用戶直接交流。
而具身智能則是在此基礎上增加「脊柱、腦幹」,即複雜的運動規劃控制能力。
小鵬其實已經實現了新技術體系在車、機器人和飛行汽車的通用。

何小鵬自述在自動駕駛和機器人研發過程中自然而然積累的這樣的認知,於是開始主動佈局有完整認知能力的世界模型;以及從5年前就開始開發儲備雲端算力儲備,圖靈AI芯片、自動駕駛基座模型等等。
小鵬在CVPR WAD上的演講,本質上是小鵬汽車帶着工業問題和解法反哺自動駕駛學術界。
「一流的自動駕駛公司,首先是一流的AI公司」,小鵬造車10年得出了這樣的結論,現在又知行合一,孤身走進了「AI無人區」。