炒股就看金麒麟分析師研報,權威,專業,及時,全面,助您挖掘潛力主題機會!
機器之心報道
編輯:Panda
近段時間,關於 AI 自我演進/進化這一話題的研究和討論開始變得愈漸密集。
本月初我們就曾梳理報道了一些,包括 Sakana AI 與不列顛哥倫比亞大學等機構合作的「達爾文-哥德爾機(DGM)」、CMU 的「自我獎勵訓練(SRT)」、上海交通大學等機構提出的多模態大模型的持續自我改進框架「MM-UPT」、香港中文大學聯合 vivo 等機構的自改進框架「UI-Genie」,參閱文章《LSTM 之父 22 年前構想將成真?一周內 AI「自我進化」論文集中發布,新趨勢湧現?》
那之後,相關研究依然還在不斷湧現,以下拼圖展示了一些例子:

而前些天,OpenAI CEO、著名 大 v 山姆・奧特曼在其博客《溫和的奇點(The Gentle Singularity)》中更是暢想了一個 AI/智能機器人實現自我改進後的未來。他寫道:「我們必須以傳統的方式製造出第一批百萬數量級的人形機器人,但之後它們能夠操作整個供應鏈來製造更多機器人,而這些機器人又可以建造更多的芯片製造設施、數據中心等等。」
不久之後,就有 用戶 @VraserX 爆料稱有 OpenAI 內部人士表示,該公司已經在內部運行能夠遞歸式自我改進的 AI。這條推文引起了廣泛的討論 —— 有人表示這不足為奇,也有人質疑這個所謂的「OpenAI 內部人士」究竟是否真實。

https://x.com/VraserX/status/1932842095359737921
但不管怎樣,AI 也確實正向實現自我進化這條路前進。
MIT 昨日發布的《Self-Adapting Language Models》就是最新的例證之一,其中提出了一種可讓 LLM 更新自己的權重的方法:SEAL,即 Self-Adapting LLMs。在該框架中,LLM 可以生成自己的訓練數據(自編輯 /self-editing),並根據新輸入對權重進行更新。而這個自編輯可通過強化學習學習實現,使用的獎勵是更新後的模型的下游性能。

這篇論文發布後引發了廣泛熱議。在 Hacker News 上,有用戶評論說,這種自編輯方法非常巧妙,但還不能說就已經實現了能「持續自我改進的智能體」。

論文一作 Adam Zweiger 也在 上給出了類似的解釋:

也有人表示,這表明我們正在接近所謂的事件視界(event horizon)—— 這個概念其實也出現在了山姆・奧特曼《溫和的奇點》博客的第一句話,不過奧特曼更激進一點,他的說法是「我們已經越過了事件視界」。簡單來說,event horizon(事件視界)指的是一個不可逆轉的臨界點,一旦越過,人類將不可避免地邁入某種深刻變革的階段,比如通向超級智能的道路。
當然,也有人對自我提升式 AI 充滿了警惕和擔憂。

下面就來看看這篇熱門研究論文究竟得到了什麼成果。
自適應語言模型(SEAL)
SEAL 框架可以讓語言模型在遇到新數據時,通過生成自己的合成數據並優化參數(自編輯),進而實現自我提升。
該模型的訓練目標是:可以使用模型上下文中提供的數據,通過生成 token 來直接生成這些自編輯(SE)。
自編輯生成需要通過強化學習來學習實現,其中當模型生成的自編輯在應用後可以提升模型在目標任務上的性能時,就會給予模型獎勵。
因此,可以將 SEAL 理解為一個包含兩個嵌套循環的算法:一個外部 RL 循環,用於優化自編輯生成;以及一個內部更新循環,它使用生成的自編輯通過梯度下降更新模型。

該方法可被視為元學習的一個實例,即研究的是如何以元學習方式生成有效的自編輯。



最後,他們還注意到,雖然本文的實現是使用單個模型來生成自編輯並從這些自編輯中學習,但也可以將這些角色分離。在這樣一種「教師-學生」形式中,學生模型將使用由另一個教師模型提出的編輯進行更新。然後,教師模型將通過強化學習進行訓練,以生成能夠最大程度提高學生學習效果的編輯。
針對具體領域實例化 SEAL
理論有了,該團隊也打造了 SEAL 的實例。具體來說,他們選擇了兩個領域:知識整合和少樣本學習。
其中,知識整合的目標是有效地將文章中提供的信息整合到模型的權重中。下圖展示了相關設定。

而下圖則給出了少樣本學習的設定。
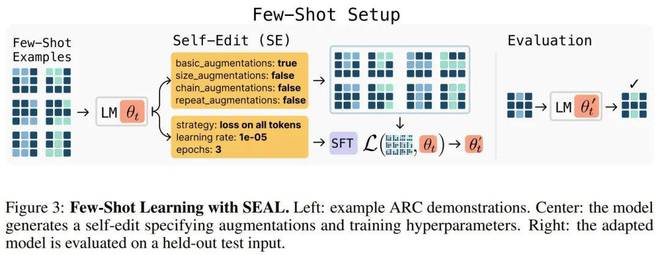
對這兩種實例化的更詳細描述請訪問原論文,下面來看看 SEAL 的實際表現。
實驗結果
少樣本學習
實驗所用的模型是 Llama-3.2-1B-Instruct,基準為 ARC。參與對比的方法包括 ICL(上下文學習)、TTT + 自編輯(無強化學習)、Oracle TTT。結果見下表。

可以看到,與基線相比,SEAL 顯著提高了適應成功率:72.5% vs. 20%(使用基礎模型的自編輯但未進行強化學習訓練)和 0%(無適應),但性能仍低於 Oracle TTT,表明新方法仍有進一步改進的空間。
知識整合
知識整合則使用了更大一些的 Qwen2.5-7B,目標是整合 SQuAD 文章中的新事實內容。這裏對比的方法包括基礎模型、僅在文章上訓練的模型、在文章 + 合成數據訓練的模型、在文章 + GPT-4.1 合成數據上訓練的模型。結果見下表。
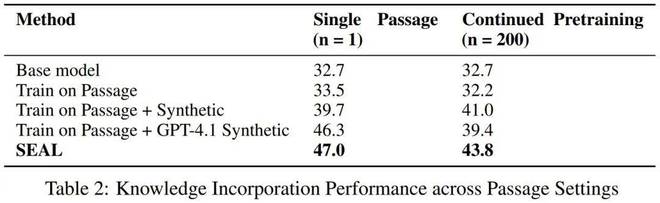
可以看到,在單篇文章(n = 1)和持續預訓練(n = 200)這兩種情況下,SEAL 方法的準確度表現都超過了基準。
首先使用基礎 Qwen-2.5-7B 模型生成的合成數據訓練後,模型的表現已經能獲得明顯提升,從 32.7% 分別提升到了 39.7% 和 41.0%,之後再進行強化學習,性能還能進一步提升(47.0% 和 43.8%)。
圖 4 展現了每次外部強化學習迭代後的準確度。

可以看到,兩次迭代足以使 SEAL 超越使用 GPT-4.1 數據的設定;後續迭代的收益會下降,這表明該策略快速收斂到一種將段落蒸餾為易於學習的原子事實的編輯形式(參見圖 5 中的定性示例)。

在這個例子中,可以看到強化學習如何導致生成更詳細的自編輯,從而帶來更佳的性能。雖然在這個例子中,進展很明顯,但在其他例子中,迭代之間的差異有時會更為細微。
另外,該團隊也在論文中討論了 SEAL 框架在災難性遺忘、計算開銷、上下文相關評估方面的一些侷限,詳見原論文。