炒股就看金麒麟分析師研報,權威,專業,及時,全面,助您挖掘潛力主題機會!

近年來,鏈式推理和強化學習已經被廣泛應用於大語言模型,讓大語言模型的推理能力得到了顯著提升。然而,在圖像生成模型中,這種成功經驗尚未得到充分探索。圖像生成模型往往直接依據給定文本生成圖像,缺乏類似人類創作過程中的推理,導致生成的圖像在語義遵循上仍有一定侷限。
近期,上海科技大學、微軟亞洲研究院和復旦大學提出了 ReasonGen-R1 框架,一個兩階段訓練框架,將鏈式推理監督微調(Supervised Fine-tuning)與強化學習(Reinforcement Learning)相結合,以提升自迴歸圖像生成模型的推理和創作能力。ReasonGen-R1 使得自迴歸圖像生成模型可以端到端地在輸出圖片之前先進行文本「思考」,大幅提升了基座模型的語義遵循能力,並在多個語義指標上取得突破。
目前,ReasonGen-R1 已全面開源(包括訓練、評測代碼,訓練數據以及模型)。

方法概覽
ReasonGen-R1 的訓練包括兩個核心階段:監督微調階段(SFT)以及強化學習階段(RL)。
監督微調階段首先構建了一個大規模圖片生成推理數據集,共包含 20 萬條圖像-文本對。該數據集基於 LAION 美學子集,利用 GPT-4.1 根據圖片自動生成兩類描述:一是多樣化的簡潔圖片描述(包括常規敘述、基於標籤和以物體為中心的敘述),二是豐富的推理式 CoT(chain-of-thought)敘述。多風格的簡潔圖片描述設計有效避免了模型在 SFT 階段對單一 prompt 模式的過擬合。
隨後,ReasonGen-R1 按照「Prompt → CoT →
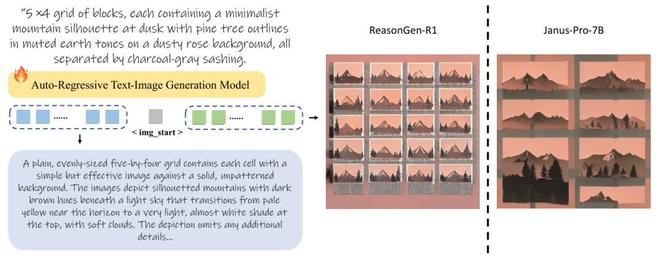
圖1. ReasonGen-R1 模型架構概覽。ReasonGen-R1通過監督微調(SFT)以及強化學習(RL)使得模型可以先進行鏈式推理,再生成最終圖片。
強化學習階段通過 Group Relative Policy Optimization(GRPO)進一步優化模型輸出。為了有效評價生成輸出圖像的質量和輸入文本-輸出圖像的一致性,ReasonGen-R1 採用了預訓練視覺語言模型 Qwen-2.5-VL-7B 作為獎勵模型,讓其對於每個輸出圖片,根據圖片以及輸入文本是否一致,給出 0、1 獎勵。
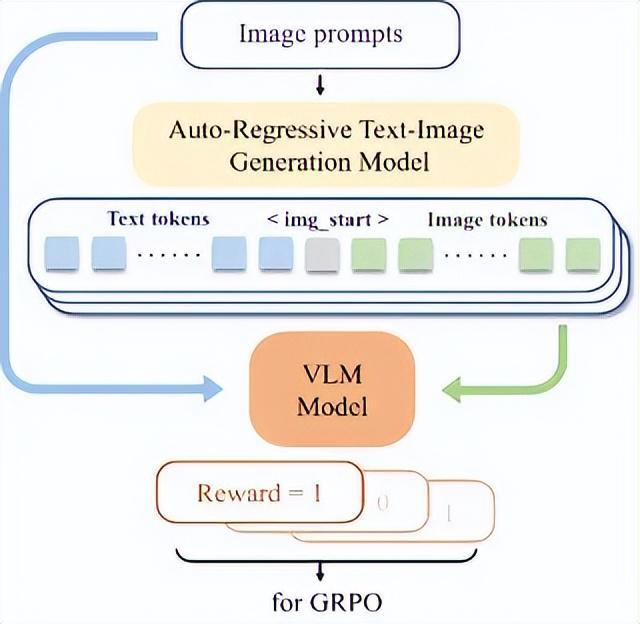 圖2. ReasonGen-R1強化學習框架概覽。
圖2. ReasonGen-R1強化學習框架概覽。此外,為確保訓練穩定性,ReasonGen-R1 提出了一種改進的自適應熵損失函數,該損失函數能夠將輸出 token 的熵動態調節到目標熵附近,有效防止了在文本圖像混合強化訓練過程中訓練不穩定導致模式崩塌的問題。
圖3. 自適應熵損失中用於更新熵損失參數的loss function
ReasonGen-R1 實驗結果
團隊基於 Janus-Pro-7B 模型對 ReasonGen-R1 進行了全方面測試,選取了三個圖像生成語義遵循指標:GenEval、DPG-Bench 以及 T2I-Benchmark。
如圖 4 所示,ReasonGen-R1 在所有指標上都較基座模型有了顯著的提升。這些結果表明,將文本推理通過 SFT-RL 的框架應用於圖片生成,能夠顯著提升自迴歸圖像生成模型的性能。
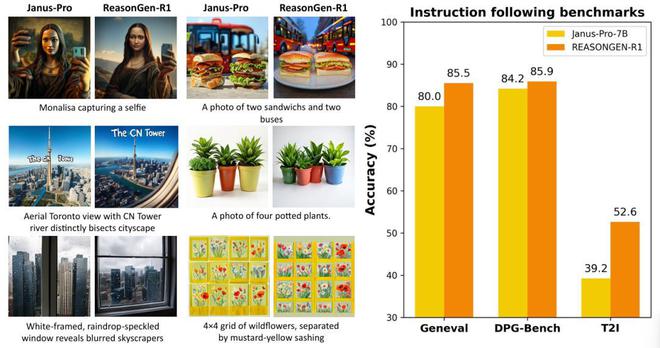
圖4. 左圖:基座模型Janus-Pro-7B和ReasonGen-R1生成圖像可視化比較;右圖:三個指令遵循指標上的表現比較。ReasonGen-R1在所有指標上均超過了基座模型,體現了指令遵循能力的巨大提升。
為深入探討 ReasonGen-R1 各個模塊的貢獻,研究還進行了以下消融實驗:
SFT 階段的作用:為了測試 SFT 階段對於模型最終性能的影響,ReasonGen-R1 對比了直接強化學習的結果。如表 1 所示,僅使用強化學習(RL)而未進行監督微調(SFT)時,模型表現顯著下降,證明了 SFT 階段對模型後續強化學習階段的重要性。
獎勵模型規模影響:實驗還對比了不同大小的獎勵模型。如表 1 所示,較小規模的獎勵模型(Qwen-2.5-VL-3B)無法提供足夠精準的反饋信號,嚴重影響強化學習階段的表現。因此,選擇高精度、大規模的獎勵模型至關重要。

表1. ReasonGen-R1在GenEval指標上對於架構設計的消融實驗
自適應熵損失函數的穩定作用:如圖 6 所示,在沒有熵損失的情況下,模型在經過 100 步的訓練後會出現熵爆炸,同時 Reward 開始緩慢下降。另一方面,施加固定熵懲罰(–0.002)會使熵持續下降,並在第 80 步時過低,進而引發圖片生成模式崩塌和獎勵急劇下滑。這些現象凸顯了在交錯文本與圖像的 RL 訓練中,對於熵損失正則化設定的敏感性。相比之下,採用 ReasonGen-R1 提出的自適應熵損失能夠將熵保持在最佳範圍內,確保訓練過程的穩定性以及獎勵的穩定增長。
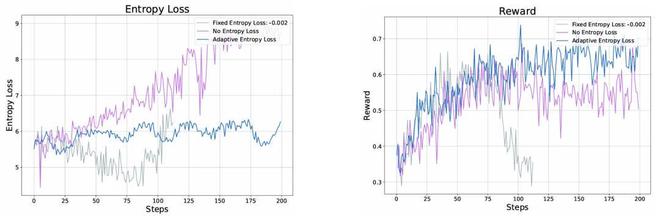 圖6. 對於各個熵正則化策略在強化學習中的效果比較
圖6. 對於各個熵正則化策略在強化學習中的效果比較ReasonGen-R1 CoT 分析
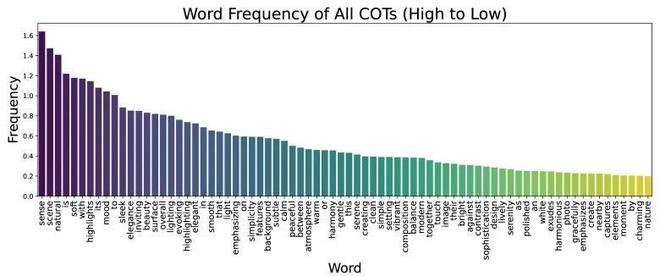
圖7. 1000次CoT輸出中的單詞頻率。只有出現頻率高於20%的單詞被展示。出現頻率最高的三個’a, an, the’被移除以關注保護更多信息的詞語
圖 7 展示了 ReasonGen-R1 推理鏈的模式。首先,它通過「感知」(sense)、「場景」(scene)和「自然」(natural)等高頻詞(在超過 140% 的 CoT 中出現)來奠定總體框架,強調整體語境和真實場景。接着,它細化視覺風格:諸如「柔和」(soft)、「高光」(highlights)、「氛圍」(mood)和「流暢」(sleek)等詞彙(均在超過 100% 的 CoT 中出現)用以描述光照質量、情感基調和質感。
更關鍵的是,「突出」(highlighting)和「強調」(emphasizing)這兩個詞各自在至少 70% 的 CoT 中出現,表明模型有意識地聚焦於主要主體。這揭示出 ReasonGen-R1 不僅僅是在描述物體,而是在主動規劃構圖焦點。
除了核心詞彙外,ReasonGen-R1 還運用了大量修飾詞——「背景」(background)用於建立環境氛圍;「特徵」(features)用於突出顯著視覺元素;「寧靜」(calm)用於渲染平和氛圍;「瞬間」(moments)用於傳達時間抓拍感;「捕捉」(captured)用於強調攝影真實感;等等——以在每條推理序列中注入細膩的、情境化的細節。
總體而言,ReasonGen-R1 的推理鏈通過場景框架、風格細節、主體聚焦和細節修飾等要素,有效地引導了圖像生成過程。