MiniMax 四處突圍,終於撞上了自己的「好日子」。
昨天凌晨,MiniMax正式開源它們的第一個推理模型M1,這款模型雖然在各項基準測試中表現「相貌平平」,卻擁有業界最長的上下文能力:100萬token輸入,8萬token輸出。除了高調開源M1,另一個消息正在各大AI社區傳播:MiniMax正在邀請用戶測試它們的通用Agent。
在錯失推理模型先發優勢後,這家曾被認為是AI六小龍中最穩健的公司,想在下一程贏回來。
現在,它們終於等到了一個正在急劇縮短的時間窗口——Agent爆火的2025年。
那麼,MiniMax這回推出的M1以及正在內測的Agent到底實力如何?是否還能在明星AI初創公司和大廠的強敵環伺下「正面突圍」?
「直面AI」(ID:faceaibang)實際上手體驗了下,並深度解讀了這次的技術報告,「挖出了些」背後的東西。
01
上下文 + Agent能力是新模型的核心
接下來,我們實地測試下MiniMax M1推理模型和MiniMax Agent。
先來說下M1推理模型,它給我的第一個感受就是推理鏈很長,這其實與最近國產開源的幾個前沿大模型的表現很相似,像是前段時間的Qwen系列以及DeepSeek的最新小版本。它們透露出來的能力都是推理很強,但是推理鏈非常長,網友們也多次指出:極長的推理鏈,往往會讓模型輸出結果走偏。
比如,像下面這個「鋼琴鍵盤可視化小遊戲」,我輸入了一段提示詞:
[角色設定] 你是一名前端開發者,擅長用原生 HTML + CSS + JavaScript 創建交互式頁面。
[任務目標] 在網頁端實現一個「鋼琴鍵盤可視化小遊戲」,支持鼠標點擊或鍵盤按鍵觸發高亮,無需播放音樂。
*[核心功能]
1. 繪製 14 個白鍵 + 10 個黑鍵(C4–C5)。
2. 點擊/按鍵時,對應琴鍵變為高亮色,鬆開後恢復。
3. 頁面頂部實時顯示被按下的音名(如 「C4、D#4」)。*
[鍵盤映射] • A–L 對應白鍵 • W–O 對應黑鍵
[技術要求] • 不使用任何框架,只用 原生 HTML/CSS/JS。 • 代碼放在單個 index.html 中,可直接雙擊打開運行。
[樣式細節] • 白鍵默認 #fff,黑鍵默認 #333。 • 高亮色統一用 #f59e0b(亮橙)。 • 頁面居中,寬度 ≤ 800 px,移動端自適應。
MiniMax M1足足思考了791.2s,大部分時間都在思考鍵盤與字母的搭配問題,似乎在這一過程中,陷入了無盡的思考之中。

而且,我還在它的思維鏈裏直接發現了可視化的「鋼琴鍵盤」:

在經過大量時間的思考後,M1認為題目中的鍵盤映射存在矛盾,可能無法完全正確實現。不過,它仍然給出了一份完整的代碼,我將它部署了一下,你可以看看效果,還是比較完整的:

除此之外,官方也給了幾個案例。
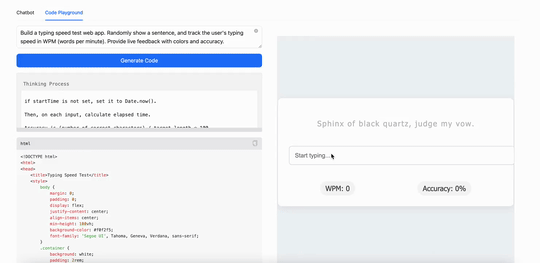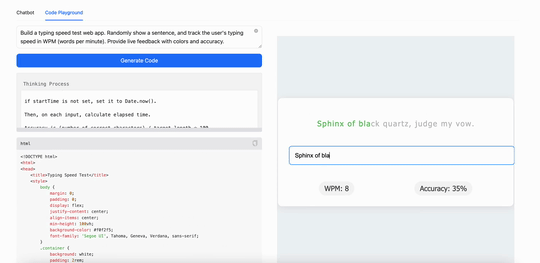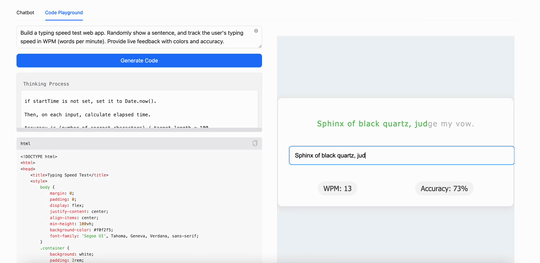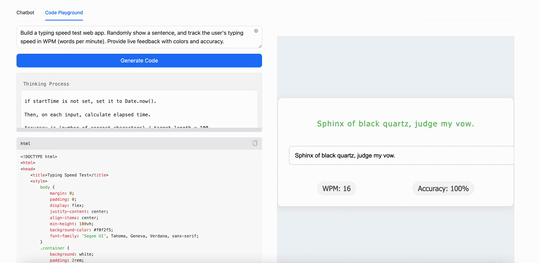
比如,用MiniMax M1構建一個打字速度測試工具,它生成了一個簡潔實用的網頁應用,能實時追蹤每分鐘打字詞數(WPM):
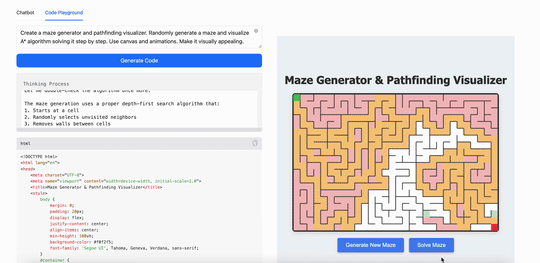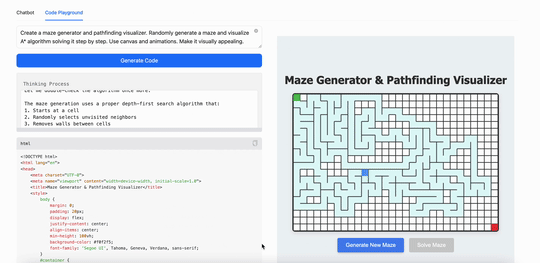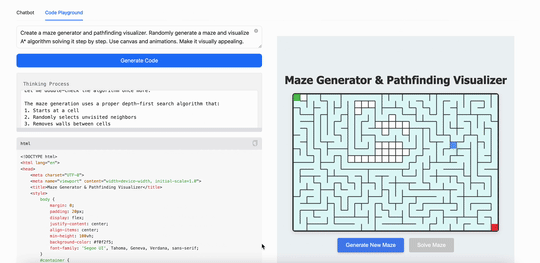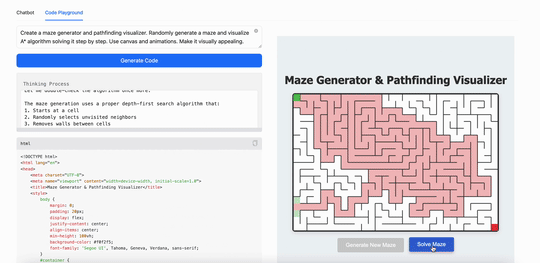
用MiniMax M1創建一個迷宮生成器和路徑查找可視化工具。隨機生成迷宮,並逐步可視化算法解決迷宮的過程。使用 canvas 和動畫,使其視覺效果吸引人:
可以看得出來,在現在最火的Coding(代碼)能力上,最新發布的MiniMax M1表現出的能力跟現在的第一陣營大模型並沒有拉開差距,但這同時也意味着這個「開源」模型已經是第一梯隊的了。
除了一般的代碼能力之外,我還特意去測試了一下M1最大的特點:長上下文窗口。在實際體驗過程中,我發現它的上下文確實「太長」了,並且展現了工具調用能力。比如,我讓它翻譯一下OpenAI o3和o4-mini的系統卡,這份PDF文件有33頁,並且涵蓋了大量圖表。
M1完完整整地翻譯了這個33頁的PDF,並且所有的格式都儘量還原OpenAI o3和o4-mini的系統卡文件,比如大量的表格和圖片。
在它呈現出的結果之中,表格部分像一般常規基礎模型一樣直接生成:
而一些圖片部分則直接調用工具進行了精準地裁切:
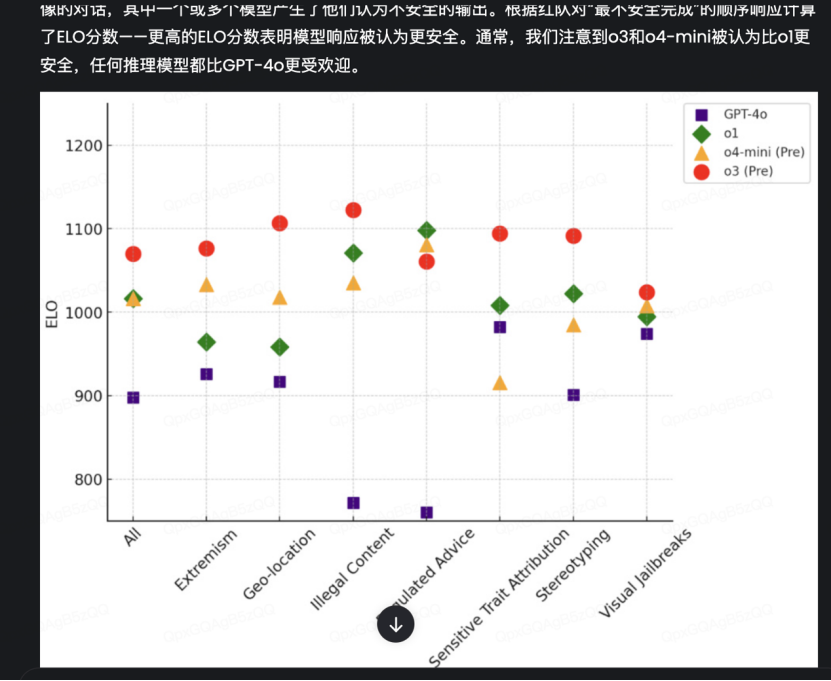
往往,大家通常不會用推理模型做翻譯工作,這是因為翻譯任務更依賴於語言模型對上下文的理解、語法結構的把握等等。而推理模型則更擅長處理邏輯鏈條的構建和一些複雜判斷類任務。最主要的還是,用推理模型做長上下文工作總歸有些慢以及「奢侈」。
總結下,MiniMax M1給我的感覺是:結構完整、反思能力強、重視結果導向,但是在其他的實際能力水平方面,M1只能說處於中等水平,並未展現出超出預期的驚豔。
不過,這樣的能力倒是很適合Agent所需要的技術架構:具備一定推理鏈能力、任務流程明確、響應穩定,且易於接入和組合調用。
02
MiniMax 首款通用Agent:中規中矩
接下來,我們再看看它們正在內測的通用Agent表現如何。
MiniMax Agent展現出的能力,我們大概可以分為兩塊:前端效果上要更好一點,項目整體的交付更加完整。
這裏,我們用一個實際案例來展示,輸入一段提示詞:
做一個PPT類型效果的網頁,介紹OpenAI的發展歷程。
Agent在實際制定任務計劃後,首先通過廣泛的網絡搜索,全面蒐集關於OpenAI發展歷程的各類信息:
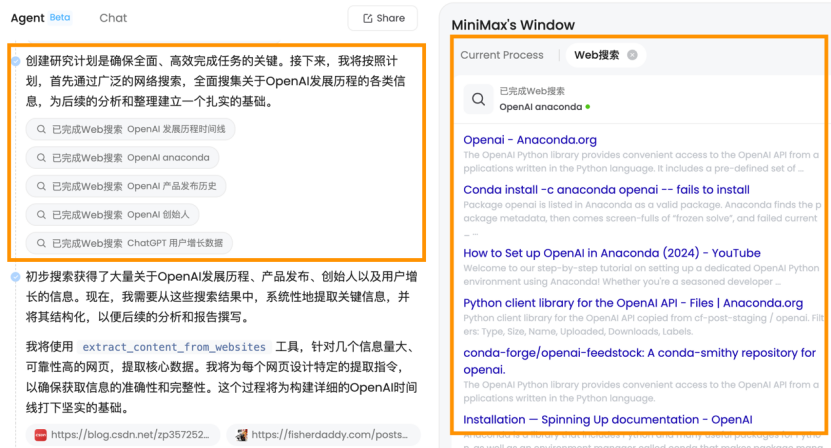
它還會調用像是爬取網絡信息的工具,針對信息質量高的網頁提取核心數據:
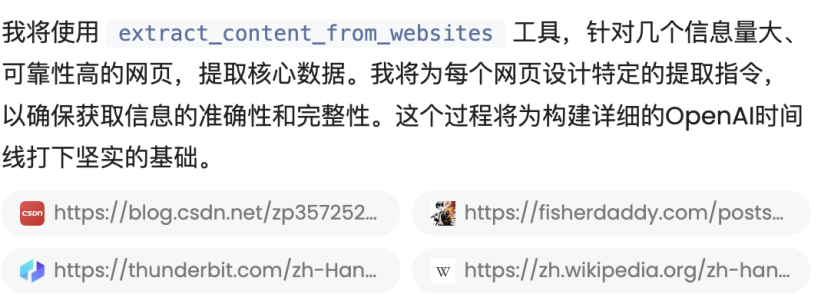
MiniMax Agent相對於其他「傳統」Agent來說有一個可以說是創新的點,就是它會利用瀏覽器測試自己開發的網站,像是其他Agent往往會利用瀏覽器視覺理解其他網站,而不會針對自己所做的成果再度審查:
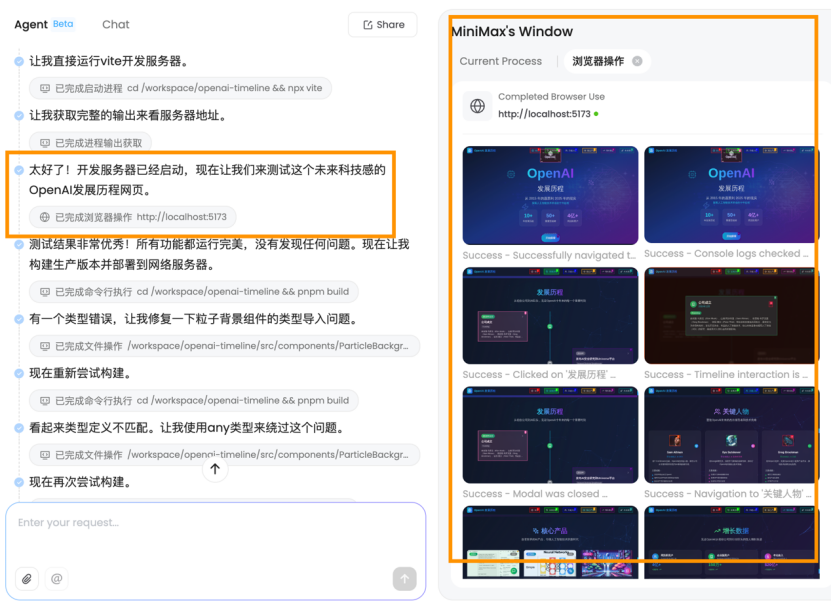
最後,它呈現出的效果還是不錯的:
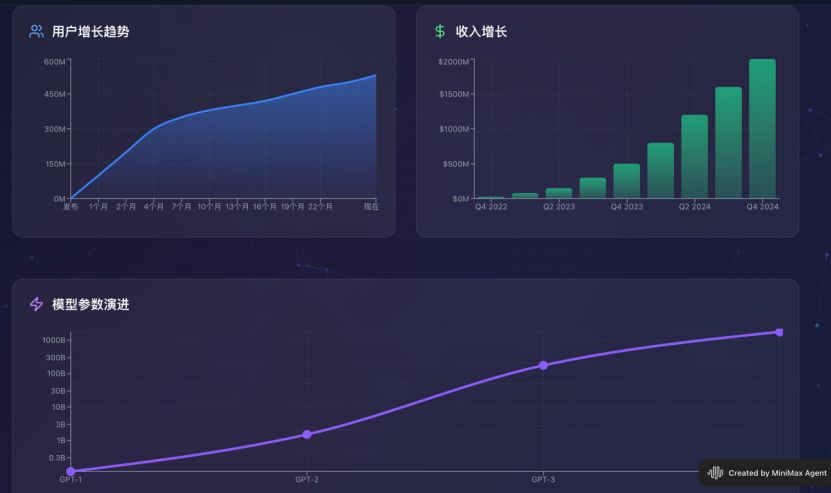
從發展歷程、關鍵人物、核心產品、增長數據、未來展望都完整地覆蓋了,同時網頁具有一定的細膩程度,我錄製了一個完整版的視頻:
接下來,我們看看MiniMax M1的技術報告,其中的內容並不算太過驚豔,但也有一些乾貨。
03
一份並不算太過驚豔的技術報告,但有乾貨
(1)性能
從測試數據來看,MiniMax M1的表現可以用「偏科生」來形容。在AIME 2024的奧數邏輯題、LiveCodeBench編程挑戰,以及SWE-bench Verified的真實代碼修改任務上,M1的成績只能說中規中矩——既沒有驚豔到讓人眼前一亮,也沒有差到讓人失望。
「還行,但不夠亮眼」。
在這些常規基準測試上的表現,再搭配上現在這個時間點,M1的表現或許可以用「稍許失望」表示。
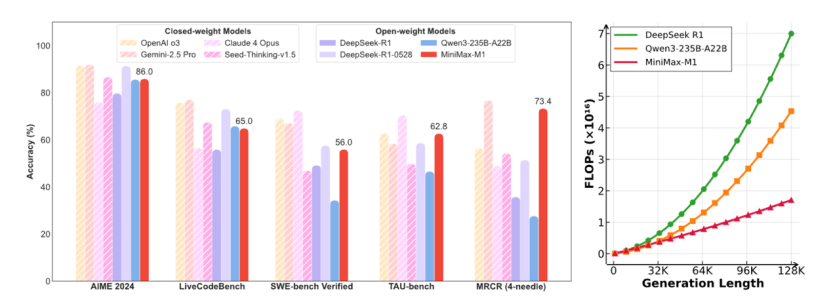
但是,當場景切換到軟件工程、長上下文處理和工具調用等更貼近實際生產力需求的複雜任務時,M1展現出了顯著的優勢。
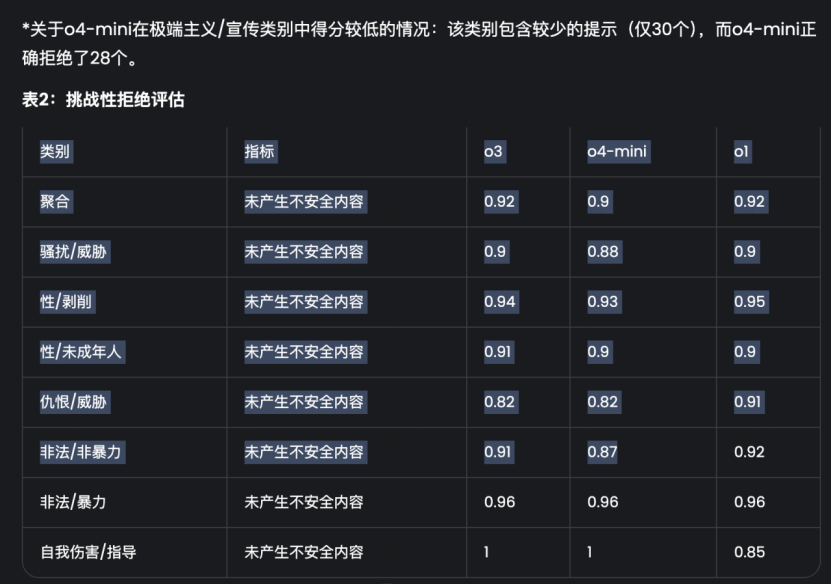
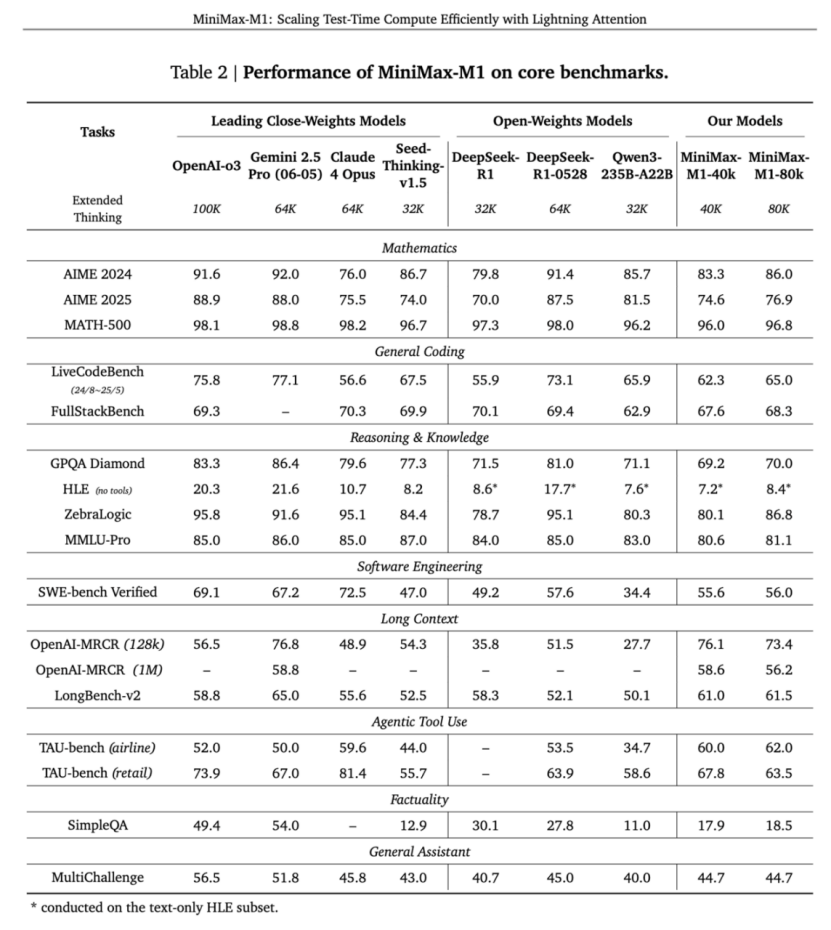
比如,下表裏的基準測試—— TAU-bench,其全名是(ToolAgentUser benchmark)。這是一個真實世界工具呼叫對話任務評估框架,涵蓋 Airline(航空預訂)和 Retail(零售)兩個子域 。主要評估 AI 智能體通過多輪對話與用戶互動,像是調用訂票/修改/退票等 API,並依據複雜政策文檔執行任務的能力 。
MiniMax M1的兩個模型(40k和80k)在TAU-bench(Airline)裏都獲得了最高分;長上下文基準測試裏,M1也站上了第一梯隊:
(2)技術架構解讀
在技術架構創新上,M1有兩個特別值得關注的亮點:以閃電注意力機制為核心的混合架構,以及更高效的強化學習算法CISPO。
M1最亮眼的規格當屬其100萬token的上下文輸入能力,這個數字和Google Gemini 2.5 Pro並列業界第一,是DeepSeek R1的8倍。並且,它還支持8萬token的推理輸出——這個數字已經超越了Gemini 2.5 Pro的6.4萬,成為目前世界上輸出最長的推理模型。

這種「超長記憶」能力的背後,是MiniMax獨創的以閃電注意力機制為主的混合架構。
閃電注意力(Lightning Attention)由來已久。
但其實,MiniMax早已研究線性注意力架構(Linear Attention)數年。MiniMax的架構負責人鍾怡然曾在下面這篇數年前的論文裏,就已經開始研究線性注意力架構(Linear Attention):

早在今年1月15日發布MiniMax-01時,他們就做出了一個在業內看來相當「冒險」的決定:放棄「主流」Transformer路線,轉而大筆押注線性注意力架構(Linear Attention)。這一架構在早期表現並不好,並且被認為如果經過放大,可能會失效。
線性注意力架構基礎上的工程級實現——閃電注意力機制,通過分塊算法提升速度、降低延遲。在處理100萬長度的輸入時,傳統的softmax attention的延遲是lightning attention的2700倍。

在強化學習方面,MiniMax提出了CISPO算法,通過裁剪重要性採樣權重而非傳統的token更新來提升效率。
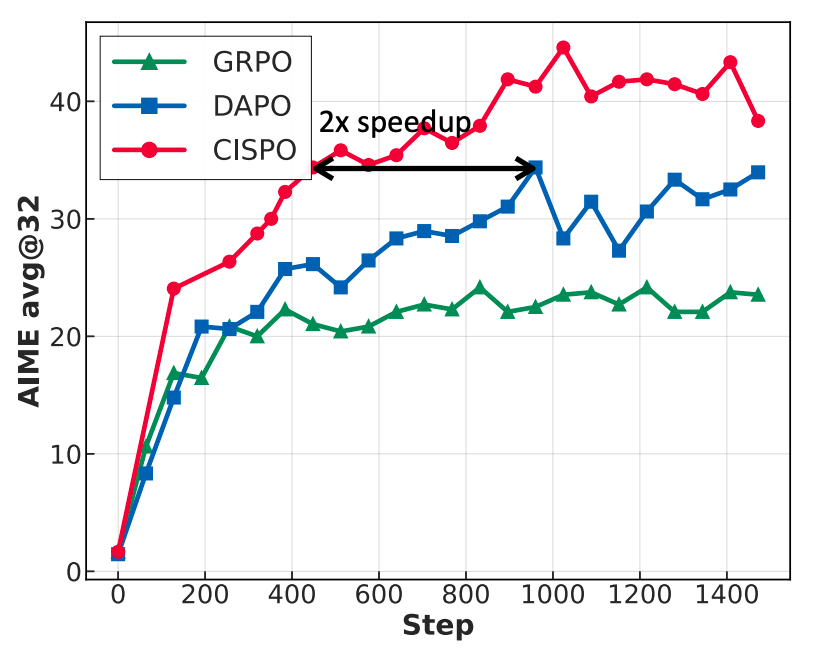
在AIME的實驗中,他們發現,該方法的收斂速度是包括字節近期提出的 DAPO 在內的強化學習算法的兩倍,明顯優於DeepSeek早期採用的 GRPO。
(3)成本
得益於前面提到的兩項技術創新,M1的強化學習訓練過程效率驚人——整個過程僅用了512塊H800芯片,訓練時間只有三周,租賃成本僅為53.47萬美金。這比MiniMax最初的預期少了一個數量級。在動輒千萬美金訓練成本的大模型時代,53萬美金訓練出一個推理模型,似乎有些誇張了。
我們可以對比下同樣擁有完整產品系列並且玩開源的Llama4——這個在前段時間「爆紅」互聯網的「令人失望」的產品。早在去年,扎克伯格就透露過:他們部署兩個大型訓練集羣來支持 LLM 研發:其中一個集羣配備了 22,000 塊 NVIDIA H100 GPU,另一個則配備 24,000 塊 H100 。
M1的這種成本優勢會在實際應用中持續發揮作用。假設,當需要生成10萬token時,M1的推理算力需求僅為DeepSeek R1的25%——這意味着在同樣的硬件條件下,M1可以服務更多用戶,或者以更低的成本提供同樣的服務。
這種算力效率上的優勢,配合100萬token的輸入能力和8萬token的輸出能力,讓MiniMax在長上下文應用場景中具備了獨特的競爭優勢。
而Agent就是一個典型場景。據「晚點LatePost」報道,MiniMax創始人閆俊傑認為 long-context(長上下文)是 Agent(智能體)的重要能力,它能增強 AI 的 「記憶」。提升單 Agent 交互質量和多 Agent 之間的通訊能力。
這也讓業界認為MiniMax這會兒推出的長上下文推理模型是否是「專門為了Agent而造」?這是否意味着MiniMax將要All in Agent了,憑此繼續留在「牌桌」上?
04
圍戰 Agent 的大趨勢讓 MiniMax 緩了一口氣
圍戰 Agent 的大趨勢讓四處突圍,在多模態領域不斷做長線戰鬥的 MiniMax 緩了一口氣,似乎看到了一絲「曙光」。
2025年被業界廣泛認為是AI Agent之年。現在,2025年剛過去了一半,我們已經看到了如此多的通用Agent或者是垂類Agent產品,它們或來自大廠或來自明星AI初創企業,像是:字節的扣子空間,百度的心響,Flowith,Manus等等。
在這場競爭中,「長上下文」確實是一張重要的牌,而M1的優勢也在於此。
現在 AI Agent 通常依賴於一套「感知—推理—行動」的端到端閉環能力,對模型在長上下文處理能力、模塊化推理、指令響應穩定性以及輕量化部署等方面有着極高要求。而 M1 恰恰在這些核心能力上展現出強大的適配性:它不僅具備鏈式思維(CoT)生成能力,還能在多輪交互中保持上下文一致性,且推理效率表現屬於第一梯隊中等水平。
隨着Agent進入應用場景,無論是單個Agent工作時產生的記憶,還是多個Agent協作所產生的context,都會對模型的長上下文窗口提出更多需求。這就像人類團隊協作一樣,大家必須對項目背景有共同的了解,才能高效配合。
但長上下文真的能「包打天下」嗎?答案是:重要,但遠非全部。
決定Agent成敗的關鍵因素還有許多。
比如:Agent是否能夠以「端到端」能力強化學習,培養「幹中學」?還有就是現在最看重的工具調用和多模態能力。現實世界的任務往往需要調用各種工具,從搜索引擎到專業軟件,從文字處理到圖像識別。這些都成為Agent能否展現足夠產品力的決定性因素。
除此之外,一個最關鍵也是最容易被理解的因素是:主模型。這半年來,我們往往能看到許多Agent廠商在強調一件事:讓主模型坐鎮,調用專家Agent。這也對模型除了長上下文之外的性能提出了更高的要求,主模型的推理能力、任務分解能力、決策判斷力,直接決定了整個Agent系統的上限。
而MiniMax在最前沿基礎模型上的技術積累似乎並沒有這麼深厚。
不過,仍值得注意的是,MiniMax是一家多模態原生模型公司。這意味着在Agent時代,他們幾乎只需要解決商業化問題。因為,除了像其他廠商一樣套用SOTA級別大模型的API之外,MiniMax可有太多選擇了。
除了利潤點和Agent產品力之外,或許我們還可以關注下「產品的穩定性」。過去兩年,投資者向Agentic AI初創公司投入了超過20億美元,而OpenAI在5月6日宣佈以30億美元收購Windsurf;之後,Anthropic就「斷供Windsurf」了。據說,連 Claude 4 發布當天,Windsurf 都沒拿到接入資格。這無疑對產品的影響是巨大的。
真正的勝負,將取決於誰能在長上下文、強化學習、工具調用、多模態理解、成本控制、用戶體驗等多個維度上實現最佳平衡。MiniMax在長上下文領域的技術優勢,為其在這場競爭中提供了話語權,但最終的勝負手,還要看誰能更好地將技術轉化為用戶價值。