作者 | 程茜
編輯 | 心緣
智東西6月17日報道,今日凌晨,「大模型六小虎」之一MiniMax發布全球首個開源大規模混合架構的推理模型MiniMax-M1,並官宣了為期五天的連更計劃。
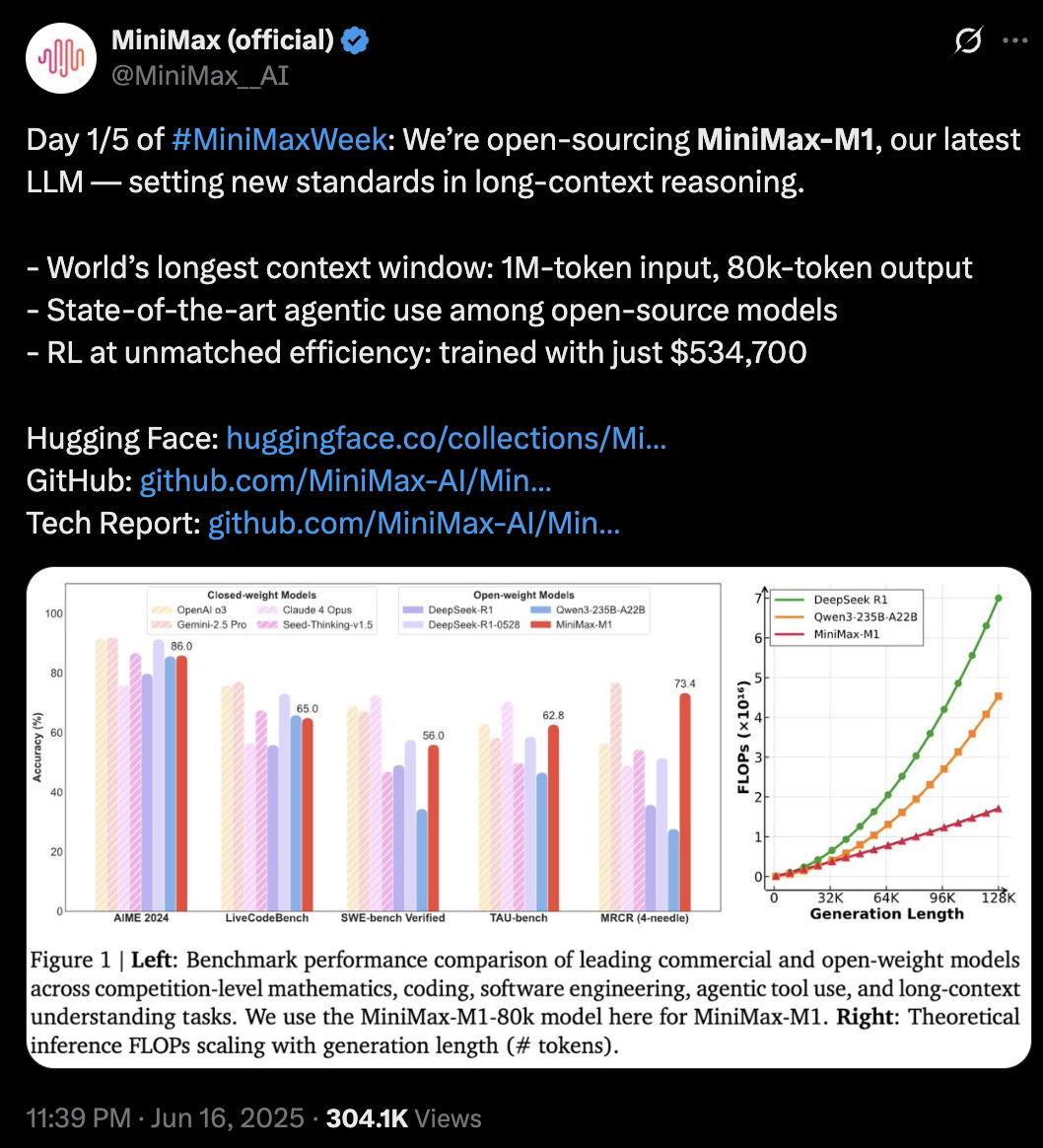
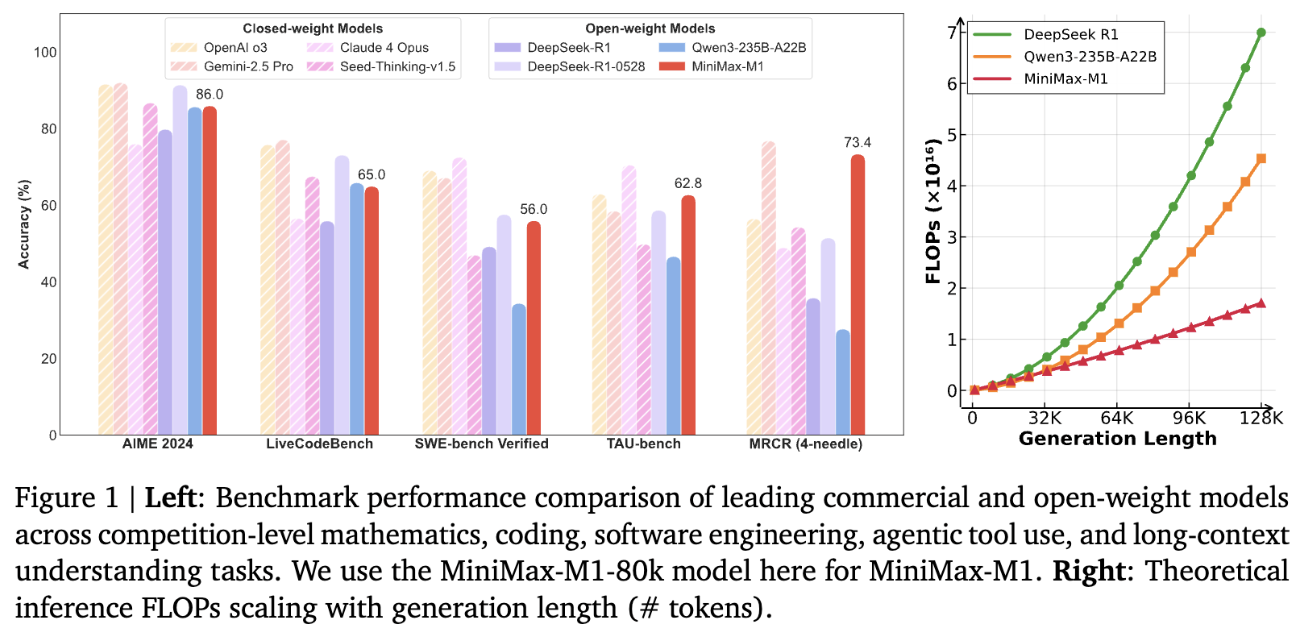
M1參數規模為4560億,每個token激活459億參數,原生支持100萬上下文輸入以及業內最長的8萬token推理輸出,輸入長度與閉源模型谷歌Gemini 2.5 Pro一致,是DeepSeek-R1的8倍。此外,研究人員訓練了兩個版本的MiniMax-M1模型,其思考預算分別為40K和80K。
MiniMax在標準基準測試集上的對比顯示,在複雜的軟件工程、工具使用和長上下文任務方面,MiniMax-M1優於DeepSeek-R1和Qwen3-235B等開源模型。
其博客提到,在M1的整個強化學習階段,研究人員使用512塊H800訓練了三周,租賃成本為53.74萬美金(摺合人民幣約385.9萬元),相比其一開始的成本預期少了一個數量級。
M1在MiniMax APP和Web上支持不限量免費使用。API價格方面,第一檔0-32k的輸入長度時,輸入0.8元/百萬token, 輸出8元/百萬token;第二檔32k-128k的輸入長度時,輸入1.2元/百萬token, 輸出16元/百萬token;第三檔128k-1M輸入長度時,輸入2.4元/百萬token, 輸出24元/百萬token。
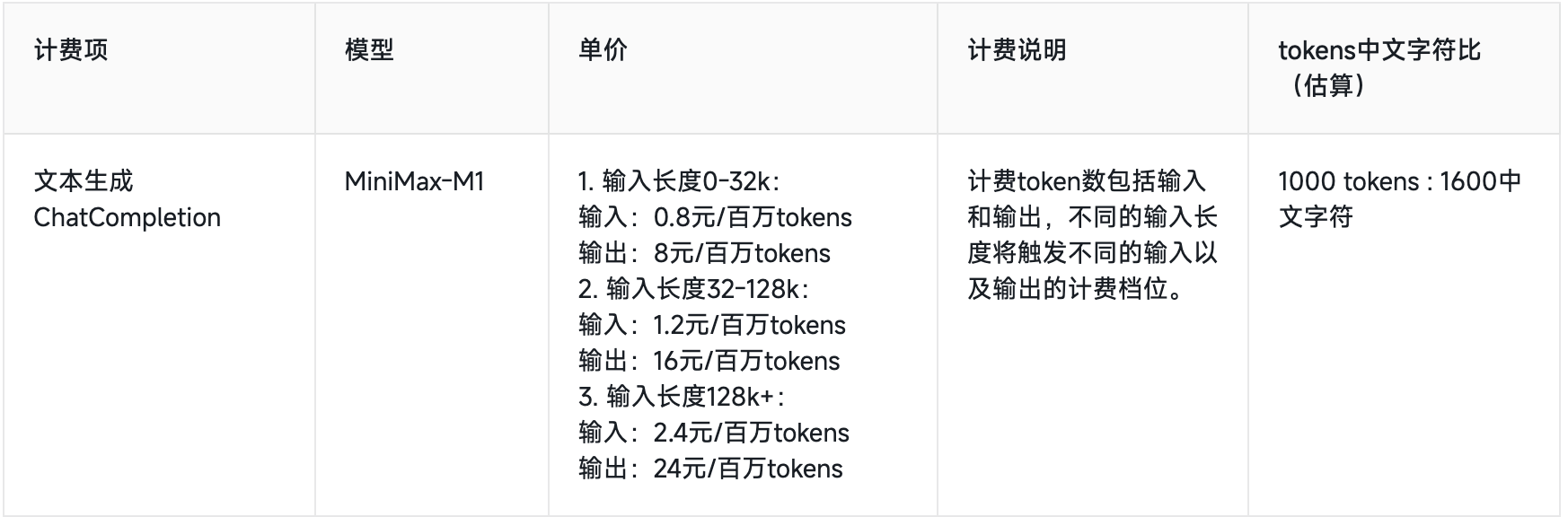
DeepSeek-R1輸入長度是64k,輸出默認32k最大64k,因此可以對標M1第一檔和第二檔價格。不過,M1第一檔、第二檔價格相比DeepSeek-R1優惠時段都沒有優勢。
在標準時段,M1第一檔輸入價格是DeepSeek-R1的80%、輸出價格為50%;第二檔輸入價格是DeepSeek-R1的1.2倍、輸出價格相同。
第三檔是M1的絕對優勢區,DeepSeek-R1不支持128k-1M的輸入長度。
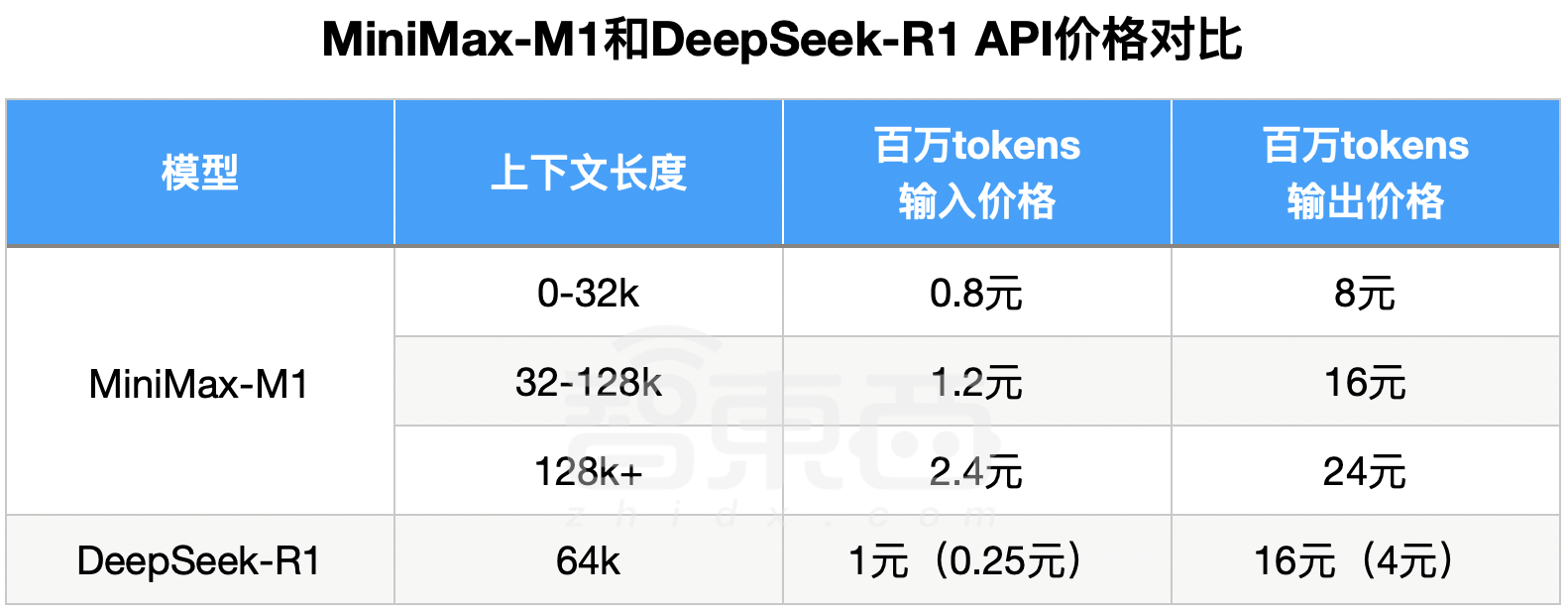
▲MiniMax-M1和DeepSeek-R1 API價格對比
幾乎與MiniMax同時,「大模型六小虎」另外一家月之暗面,也發了開源代碼模型Kimi-Dev,編程能力強過DeepSeek-R1。
體驗地址:https://chat.minimax.io/
GitHub地址:https://github.com/MiniMax-AI/MiniMax-M1
Hugging Face地址:https://huggingface.co/collections/MiniMaxAI/minimax-m1-68502ad9634ec0eeac8cf094
技術報告地址:https://github.com/MiniMax-AI/MiniMax-M1/blob/main/MiniMax_M1_tech_report.pdf
一、Agent工具使用能力一騎絕塵,數學、編程略遜
基於業內主流17個評測集,MiniMax-M1的評測結果在軟件工程、長上下文、工具使用等方面的表現優於其他開源或閉源模型。
OpenAI發布的MRCR測試集中,M1的表現略遜於Gemini 2.5 Pro,相比其他模型效果更好。MRCR評估的是大語言模型區分隱藏在長上下文中多個目標的能力,要求模型在極其複雜且多重干擾的長文本中,準確區分多條几乎相同的信息,還需識別其順序。
在評估軟件工程能力的測試集SWE-bench Verified中,MiniMax-M1-40k和MiniMax-M1-80k的表現略遜於DeepSeek-R1-0528,優於其他開源模型。
Agent工具使用方面,在航空業的測試集TAU-bench(airline)中,MiniMax-M1-40k表現優於其餘的開源和閉源模型,零售業測試集TAU-bench(retail)中,與DeepSeek-R1表現相當。
但在數學、編程能力等方面,其得分相比Qwen3-235B-A22B、DeepSeek-R1、Claude 4 Opus等都較低。
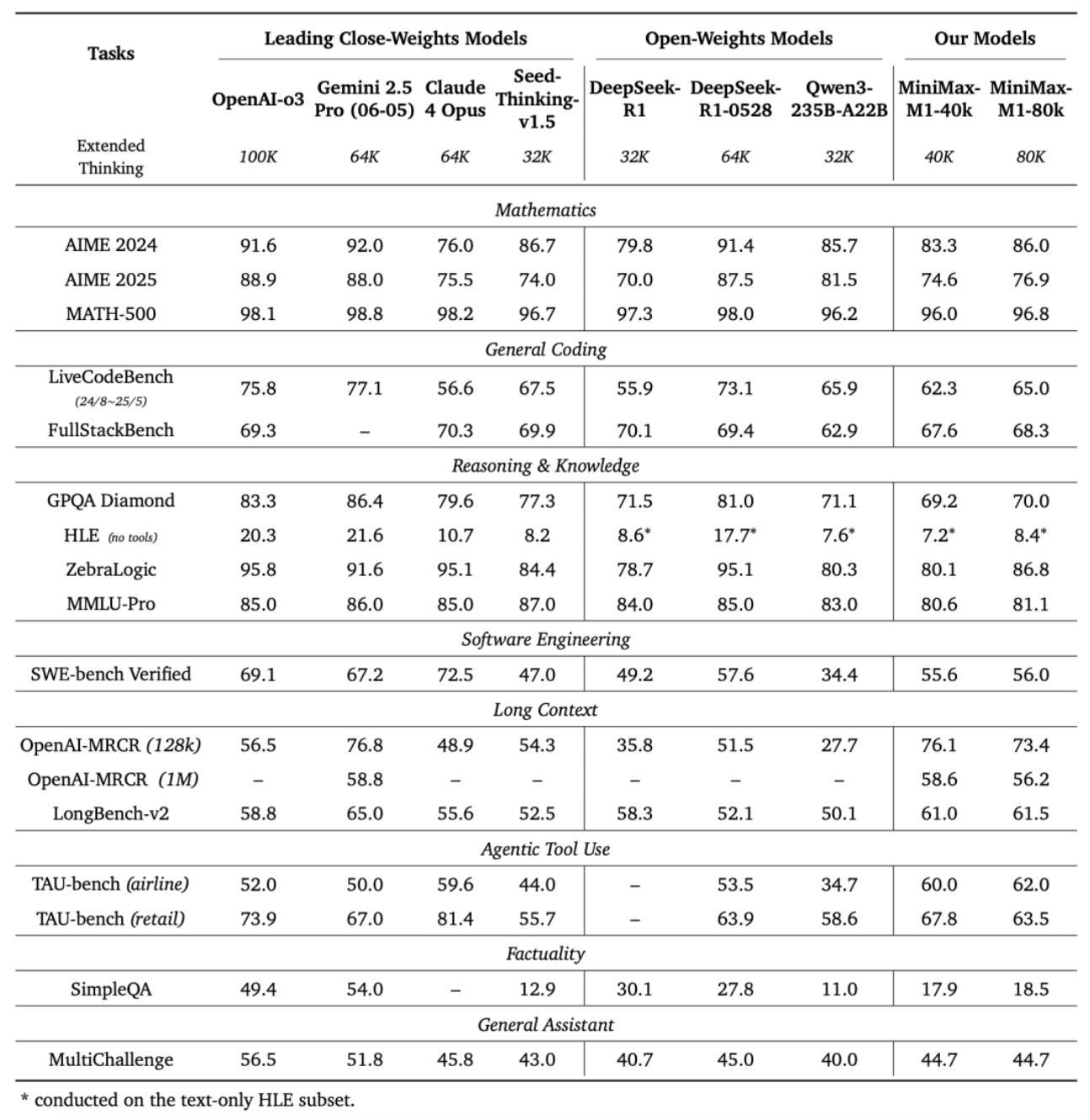
▲MiniMax-M1評測結果
與此同時,MiniMax-M1-80k在大多數基準測試中始終優於MiniMax-M1-40k,這可以驗證其擴展測試時計算資源的有效性。
二、閃電注意力機制高校擴展計算,擅長處於長輸入+廣泛思考
M1是基於MiniMax-Text-01模型開發,採用了混合專家(MoE)架構和閃電注意力機制。
M1的閃電注意力機制可以高效擴展測試時計算。例如,與DeepSeek-R1相比,M1在10萬個token的生成長度下只需消耗25%的FLOP,使得M1適合於需要處理長輸入和廣泛思考的複雜任務。
另一個技術重點是使用大規模強化學習(RL)進行訓練,其應用範圍可涵蓋從傳統數學推理到基於沙盒的真實軟件工程環境等問題。
MiniMax為M1開發了RL擴展框架,重點包括:提出CISPO新算法,可通過裁剪重要性採樣權重而非token更新來提升性能,其性能優於其他競爭性RL變體;其混合注意力機制設計能夠提升RL效率,並利用混合架構來應對擴展RL時面臨的挑戰。
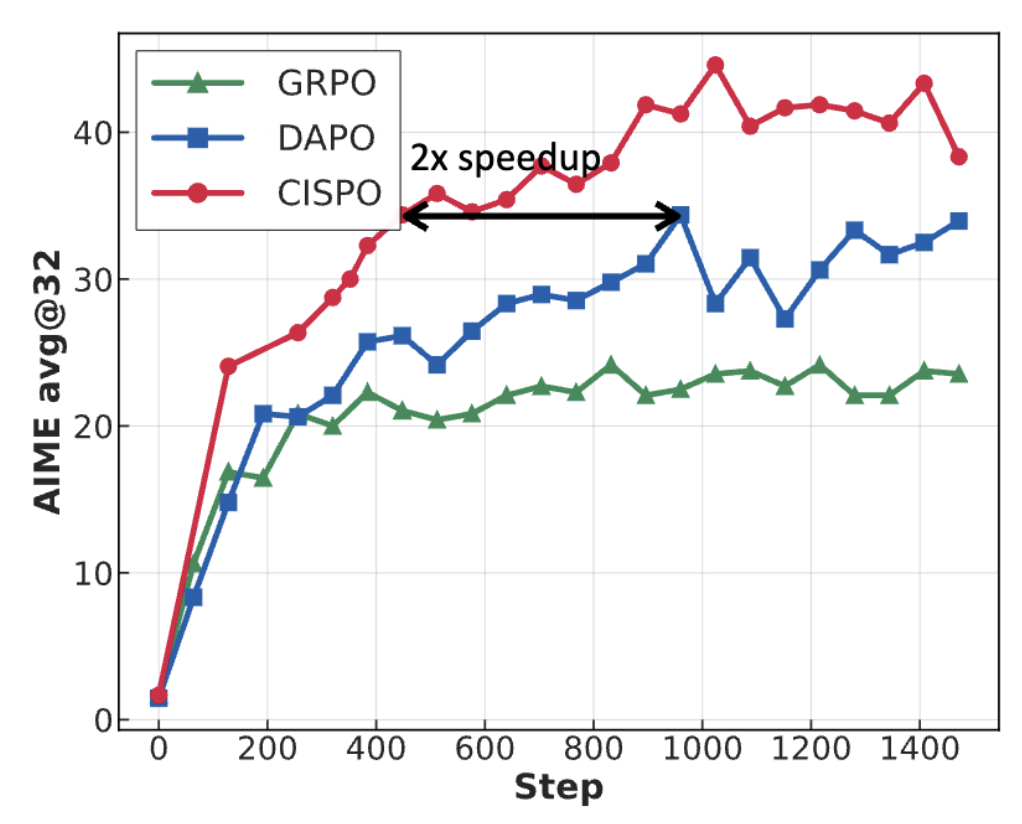
此外MiniMax提到,在AIME的實驗中,他們發現CISPO比字節近期提出的DAPO等強化學習算法收斂性能快了一倍,顯著優於DeepSeek早期使用的GRPO。
研究人員在基於Qwen2.5-32B-base模型的AIME 2024任務上,對GRPO、DAPO以及CISPO進行了對比,結果表明:在相同訓練步數下,CISPO的性能優於GRPO和DAPO;而當使用50%的訓練步數時,CISPO可達到與DAPO相當的性能表現。
結語:多Agent協作面臨超長上下文、數百輪推理挑戰
為了支持日益複雜的場景,大語言模型在測試或推理階段,往往需要動態增加計算資源或計算步驟來提升模型性能,MiniMax在研究報告中提到,未來大模型尤其需要「Language-Rich Mediator」(富語言中介)來充當與環境、工具、計算機或其他與Agent交互的Agent,需要進行數十到數百輪的推理,同時集成來自不同來源的長上下文信息。
在這樣的背景下,作為MiniMax推出的首個推理模型,MiniMax-M1正是其面對這一行業發展趨勢在算法創新上的探索。