炒股就看金麒麟分析師研報,權威,專業,及時,全面,助您挖掘潛力主題機會!
深夜,沉寂已久的Kimi突然發布了新模型——
開源代碼模型Kimi-Dev,在SWE-bench Verified上以60.4%的成績取得開源SOTA。
參數量只有72B,但編程水平比最新的DeepSeek-R1還強,和閉源模型比較也表現優異。
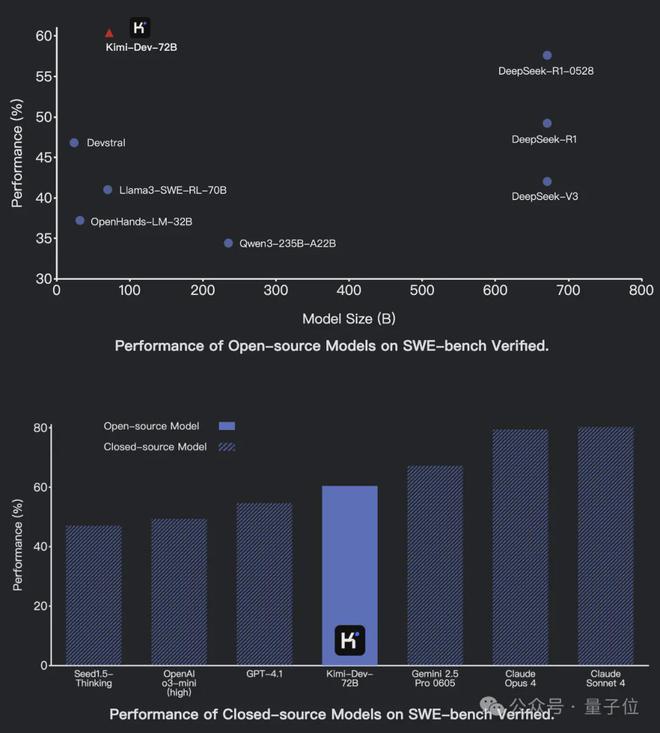
有網友看到後表示,感覺月之暗面的實力被低估了,其水平應該比xAI強。

Kimi-Dev採用MIT協議,目前權重和代碼均已發布,還有網友製作的量化版本也已在抱抱臉上線。
那麼,Kimi-Dev是如何做到的呢?
目前,Kimi-Dev的完整技術報告暫未出爐,不過官方透露了其中的一些關鍵技術。
Kimi-Dev-72B的設計核心是BugFixer和TestWriter兩種角色的結合,BugFixer和TestWriter都遵循一個共同的最小框架,包含兩個階段:

為了增強Kimi-Dev-72B作為BugFixer和TestWriter的先驗知識,Kimi團隊以Qwen 2.5-72B基礎模型為起點使用約1500億高質量真實數據進行中期訓練。
具體來說,Kimi團隊收集了數百萬個GitHub issue和PR提交,目的是讓Kimi-Dev-72B能夠學習人類開發人員如何推理並解決GitHub問題。
另外,Kimi團隊還進行了嚴格的數據淨化,確保訓練數據當中不包含SWE-bench Verified裏的內容。
經過中期訓練和監督微調(SFT)後,Kimi-Dev-72B在文件定位方面已經表現出色,之後的強化學習階段主要側重於提升其代碼編輯能力。
強化學習訓練採用了Kimi k1.5中的策略優化方法,主要有三個關鍵設計:
一是僅基於結果的獎勵(Outcome-based Reward Only)——訓練中僅使用代碼在Docker環境中的最終執行結果(成功為 1,失敗為 0)作為獎勵,而不考慮任何與代碼格式或編寫過程的因素。
這確保了模型生成的解決方案的正確性以及與實際開發標準的一致性。
二是採用了高效提示集(Efficient Prompt Set),過濾掉在多樣本評估下成功率為零的提示,以更有效地進行大批量訓練。
此外,強化學習階段還採取了循序漸進的策略,逐步引入新提示,逐步增加任務難度。
三是正向示例強化(Positive Example Reinforcement),也就是在後面的訓練過程中,Kimi-Dev會將它之前已經解決的問題的方案重新納入當前的訓練批次中進行學習,從而鞏固和強化之前有效的、成功的解決模式和方法。
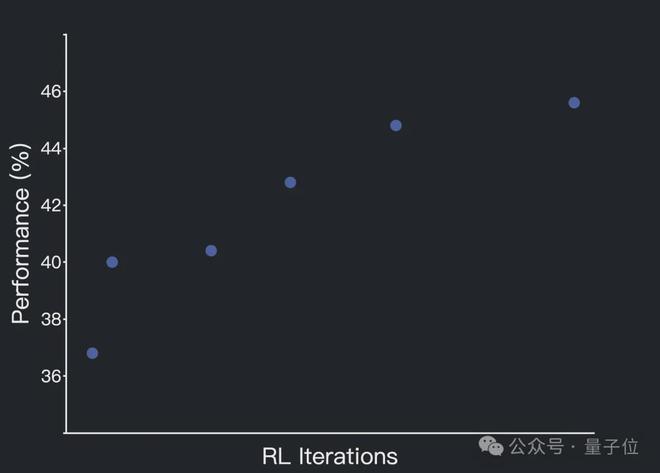
經過強化學習後,Kimi-Dev-72B能夠同時掌握兩種角色。在測試過程中,它會採用自我博弈機制,協調自身Bug修復和測試編寫的能力。
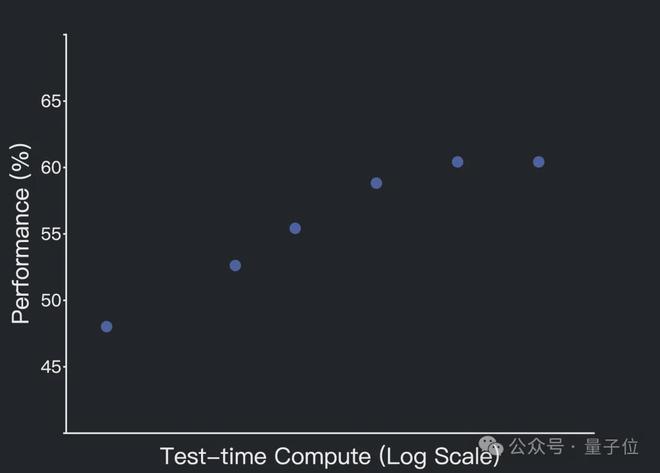
Kimi-Dev-72B會遵循標準Agentless設定,為每個問題生成最多40個補丁候選(patch candidates)和40個測試候選(test candidates)。
在測試時間自我博弈中,觀察到了規模效應(scaling effect)。
以上就是Kimi團隊介紹的Kimi-Dev背後的關鍵,更多細節將在後續的技術報告中揭曉,感興趣的話可以關注Kimi團隊的發布。
下一步,Kimi團隊還計劃探索更復雜的軟件工程任務,並將於與流行的IDE、版本控制系統和CI/CD流水線進行更深入的集成。
項目主頁:
https://moonshotai.github.io/Kimi-Dev/
GitHub:
https://github.com/MoonshotAI/Kimi-Dev
HuggingFace:
https://huggingface.co/moonshotai/Kimi-Dev-72B