炒股就看金麒麟分析師研報,權威,專業,及時,全面,助您挖掘潛力主題機會!

新智元報道
編輯:犀牛
【新智元導讀】NVIDIA等研究團隊提出了一種革命性的AI訓練範式——視覺遊戲學習ViGaL。通過讓7B參數的多模態模型玩貪喫蛇和3D旋轉等街機遊戲,AI不僅掌握了遊戲技巧,還培養出強大的跨領域推理能力,在數學、幾何等複雜任務上擊敗GPT-4o等頂級模型。
你肯定玩過貪喫蛇遊戲。
或許是在諾基亞的單色螢幕上,或許是在童年教室的文曲星裏,又或者在喧囂街機遊戲廳裏的一角。
我們控制着那條像素小蛇,笨拙地轉向,只為去喫掉一個又一個憑空出現的豆子。
規則十分簡單,又很明確:喫掉食物,變長;撞到牆壁或者自己,遊戲結束。
如果將一個AI扔進這個遊戲裏,不給它灌輸任何人類的數學公式或者幾何定理,會發生什麼呢?
它會變得更擅長玩遊戲?沒錯。
但讓人沒想到的是,通過遊戲的訓練,這個AI還可以成為一位「數學天才」!
近日,來自萊斯大學、約翰霍普金斯大學以及英偉達的研究人員特別研究了這樣的問題。
結果顯示,一個沉迷於街機遊戲的7B參數MLLM(多模態大模型),竟然在複雜的數學和幾何推理任務上,一舉擊敗了GPT-4o這樣的頂級閉源大模型。

論文地址:https://www.arxiv.org/pdf/2506.08011
這為我們揭示了一個足以顛覆AI訓練範式的驚人現實。
研究者發現,AI從貪喫蛇這類簡單遊戲中領悟到的,並非只是如何通關的技巧,而是一種更加底層、更通用的認知能力——一種可以跨領域遷移的「直覺」與推理能力。
也許,智能並不一定只是來源於海量知識的「壓縮」,也可能蘊藏於最簡單的規則和最純粹的遊戲之中。
ViGaL:視覺遊戲學習
研究者提出了一種新的後訓練範式:ViGaL(Visual Game Learning,視覺遊戲學習 )。
通過讓模型玩類似街機的小遊戲,來幫助MLLM發展出跨領域的推理能力。
如圖1所示,研究者證明了對一個7B參數的多模態模型Qwen2.5-VL-7B進行後訓練,讓它玩類似「貪喫蛇」這樣的簡單街機遊戲,不僅能泛化到其他遊戲,還在多模態數學基準(如MathVista)和多學科問答(如MMMU)上獲得了顯著的跨領域能力提升。
儘管在RL訓練中從未見過任何解題過程、方程或圖表,模型的性能不僅超越了像GPT-4o這樣的頂級大模型,還超過了在領域內數據集上後訓練過的專用模型。
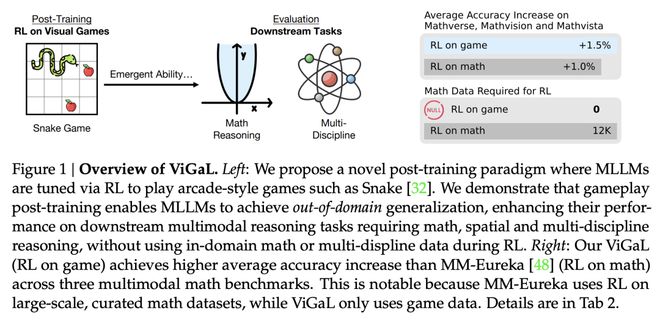
更重要的是,模型在多模態推理上的提升並未犧牲其通用視覺能力,而專用模型通常做不到這一點。
有意思的是,最近一直有研究人員質疑RL是否需要領域內的標準答案,本文的結論則能進一步證明,領域內問題本身可能都不重要。
為什麼有效?
研究者假設玩遊戲可以培養一些通用的認知能力或技能,比如空間理解和順序規劃,這些技能可以遷移到多模態推理任務中。
相比在數學問題上進行監督微調(SFT)或RL,遊戲訓練可能激勵模型形成更靈活的思維方式和策略。
他們的消融實驗支持了這種觀點,提示和獎勵設計在實現有效學習方面都起着關鍵作用。
研究者還發現,不同遊戲強調不同的推理能力。
比如,「貪喫蛇」提升了與2D座標相關的數學問題表現。
而「旋轉」是一個識別3D物體旋轉角度的問題,可以在角度和長度相關的數學問題上令模型表現更好。
如圖2所示,模型經過思考選擇一個動作,輸出其思維鏈和決策。例如,最佳/最差移動或預測角度,並獲得獎勵。
通過遊戲,模型獲得推理能力,並將其遷移到下游多模態推理任務中,如數學和多學科問答。

更加令人振奮的是,同時訓練這兩個遊戲比單獨訓練任一遊戲的表現更優。
這意味着遊戲訓練具有可擴展性。
這可真是太棒了!對於模型來說,簡直就是玩的越多,學的越多。
這些實驗結果都表明,除了收集特定領域的數據,還可以設計可擴展、可控的前置遊戲(pre-text games),來激發模型產生能泛化到下游任務的推理能力。(圖3)
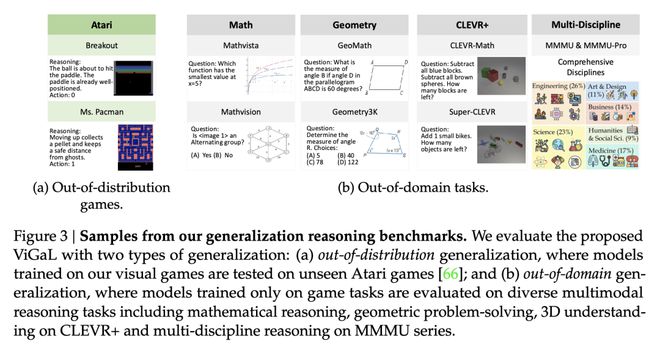
使用兩種類型的泛化來評估所提出的ViGaL:(a) 分佈外泛化,即在我們的視覺遊戲上訓練的模型在未見的Atari遊戲上進行測試;以及(b) 領域外泛化,即僅在遊戲任務上訓練的模型在多種多模態推理任務上進行評估,包括數學推理、幾何問題解決、CLEVR+上的3D理解以及MMMU系列上的多學科推理
合成遊戲環境可以提供結構化、基於規則的獎勵信號,具有高度的可控性,這使得通過難度規劃(difficulty scheduling)來實現穩定的RL成為可能。
值得一提的是,這些合成環境中進行數據擴展,要比收集人工標註的數據容易得多。
總之,這些發現揭示了一個極具前景的新範式——使用遊戲這類合成任務進行後訓練。
這讓人聯想到了自監督學習在計算機視覺和自然語言處理領域的崛起:在精心設計的合成前置任務上進行預訓練,最終都帶來了強大的泛化能力。
實驗結果
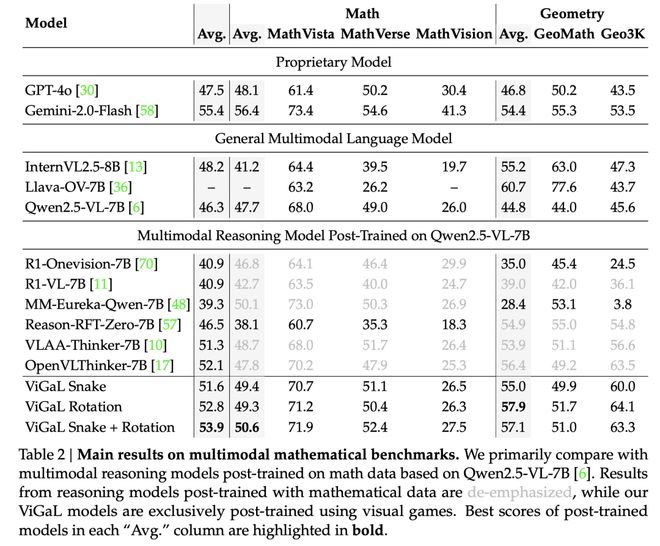
如表2所示,本文的方法在數學任務上的表現顯著優於專門針對數學任務進行RL訓練的模型。
例如,ViGaL Snake + Rotation在數學任務上的準確率比MM-Eureka-Qwen-7B高出0.5%,在幾何任務上高出28.7%!
儘管MM-Eureka-Qwen-7B使用了高質量的數學和幾何數據集進行明確訓練。
這種強大的泛化能力不僅限於數學領域。
表3顯示,ViGaL Snake + Rotation在MMMU系列基準測試中的平均表現比R1-OneVision-7B高出5.4%,這些基準測試評估了多學科推理能力。
這一結果尤為引人注目,因為R1-OneVision-7B模型使用了涵蓋多個學科的精心策劃的綜合數據集進行訓練。
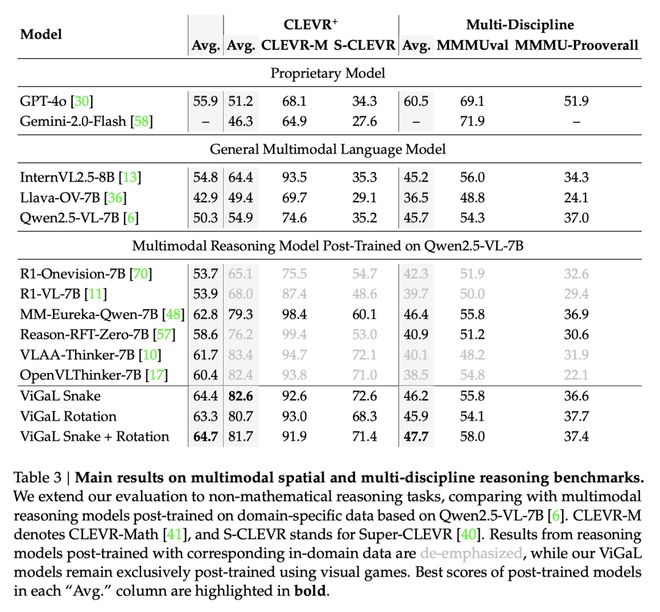
混合多種遊戲可增強泛化能力。
如上表2所示,在Snake遊戲上進行後訓練在CLEVR+基準測試中取得最佳性能,而在Rotation遊戲上訓練則在幾何推理任務中表現出更強的結果。
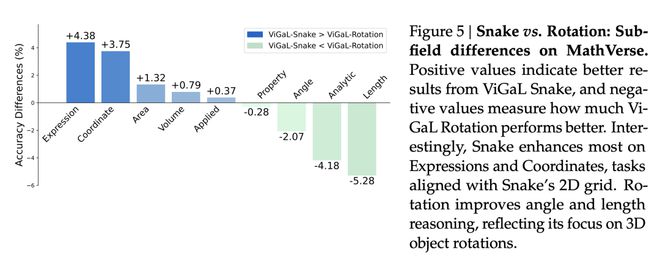
它們的比較優勢在圖5中進一步說明。
有意思的是,Snake模型在表達式和座標方面提升最為明顯,這些任務與蛇模型的二維網格相關。旋轉模型在角度和長度推理方面有所改進,這反映了它對三維物體旋轉的關注。
正值表示ViGaL Snake模型取得更好的結果,負值表示ViGaL旋轉模型表現優於Snake模型的程度
同時在 Snake 和 Rotation 遊戲上訓練模型,使其能夠從兩種環境中學習互補技能,從而將整體基準測試平均成績提高到63.1%。
這些發現表明,結合多樣化的遊戲環境可以顯著提升性能。
這展示了視覺遊戲學習(ViGaL)作為一種有前景的訓練範式,能夠增強可泛化的推理能力,而無需大規模的領域特定數據。
在增強推理能力的同時保持通用視覺能力。
為了全面檢驗推理任務上的泛化是否會導致通用視覺能力的下降,研究者在更廣泛的MLLM基準測試集上評估了ViGaL Snake + Rotation。
如表4所示,與RL調優前的Qwen2.5-VL-7B相比,模型在保持相當的通用視覺性能的同時,取得了更強的數學推理結果。
相比之下,其他通過RL後訓練提升數學性能的模型通常在通用視覺能力上表現出顯著下降。
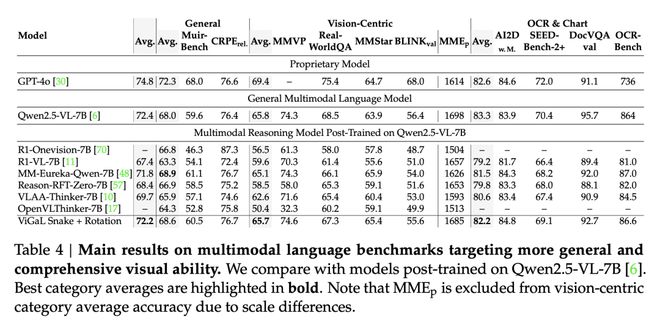
這些結果表明,本文的遊戲後訓練方法能夠在增強推理能力的同時,有效保持通用視覺能力。
參考資料:
https://www.arxiv.org/abs/2506.08011