邁向通用人工智能(AGI)的核心目標之一就是打造能在開放世界中自主探索並持續交互的智能體。隨着大語言模型(LLMs)和視覺語言模型(VLMs)的飛速發展,智能體已展現出令人矚目的跨領域任務泛化能力。
而在我們觸手可及的開放世界環境中,圖形用戶界面(GUI)無疑是人機交互最普遍的舞台。想象一下 --- 你的 AI 不僅能看懂螢幕,還能像人一樣主動探索界面、學習操作,並在新應用裏靈活應對,這不再是幻想!
近期,吉林大學人工智能學院發布了一項基於強化學習訓練的 VLM 智能體最新研究《ScreenExplorer: Training a Vision-Language Model for Diverse Exploration in Open GUI World》。它讓視覺語言模型(VLM)真正學會了「自我探索 GUI 環境」。

論文地址:https://arxiv.org/abs/2505.19095
項目地址:https://github.com/niuzaisheng/ScreenExplorer
該工作帶來三大核心突破:
在真實的 Desktop GUI 環境中進行 VLM 模型的在線訓練;
針對開放 GUI 環境反饋稀疏問題,創新性地引入「好奇心機制」,利用世界模型預測環境狀態轉移,估算環境狀態的新穎度,從而有效激勵智能體主動探索多樣化的界面狀態,告別「原地打轉」;
此外,受 DeepSeek-R1 啓發,構建了「經驗流蒸餾」訓練範式,每一代智能體的探索經驗都會被自動提煉,用於微調下一代智能體。這不僅大幅提升探索效率、減少對人工標註數據的依賴,更讓 ScreenExplorer 的能力實現了持續自主進化,打造真正「學無止境」的智能體!論文同時開源了訓練代碼等。
方法
實時交互的在線強化學習框架
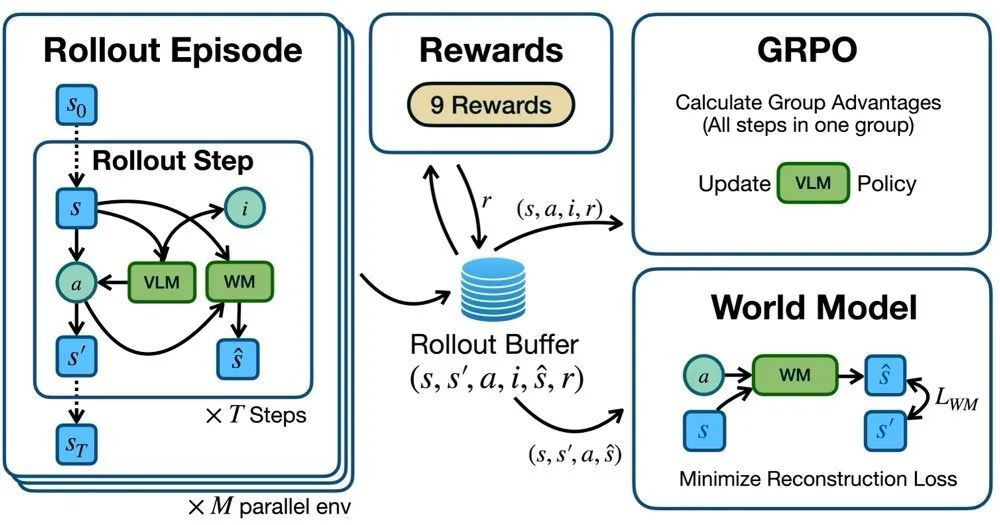
文章首先構建了一個能夠與 GUI 虛擬機實時交互的在線強化學習環境,VLM 智能體可以通過輸出鼠標和鍵盤動作函數調用與真實運行的 GUI 進行交互。強化學習環境通過提示詞要求 VLM 智能體以 CoT 形式輸出,包含「意圖」與「動作」兩部分。最後,強化學習環境解析函數調用形式的動作並在真實的操作系統中執行動作。在採樣過程中,可以並行多個虛擬機環境進行採樣,每個環境採樣多步,所有操作步都存儲在 Rollout Buffer 中。
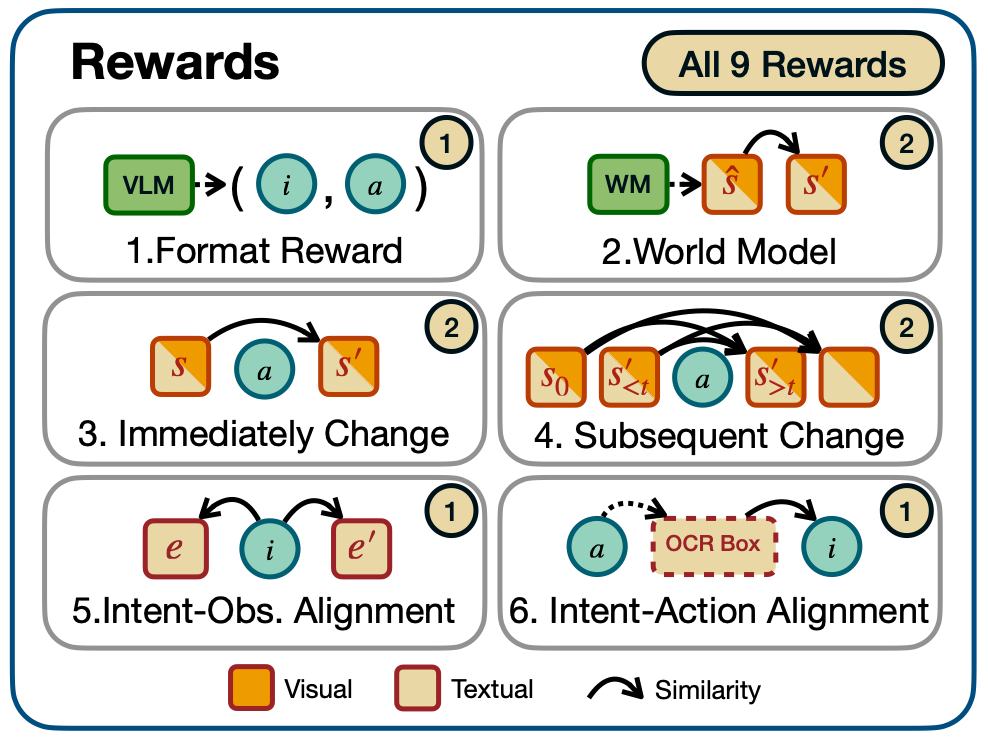
啓發式 + 世界模型驅動的獎勵體系
文中構建了啓發式 + 世界模型驅動的探索獎勵,啓發式探索獎勵鼓勵軌跡內畫面之間差異度增大。世界模型可以導出每一個動作的好奇心獎勵,鼓勵模型探索到越來越多的未見場景,此外還有格式獎勵和意圖對齊獎勵。綜合以上獎勵,為每一步動作賦予即時獎勵,進而鼓勵模型與環境開展有效交互的同時不斷探索新環境狀態。
計算 GRPO 的組優勢函數計算
在獲得每一步輸出的獎勵後,文中採用與 Deepseek-R1 相同的 GRPO 算法對 VLM 進行強化學習訓練。作者將同一個 Rollout Buffer 中所有動作視為一個組,首先根據 GRPO 的優勢函數計算每一步動作的優勢值:
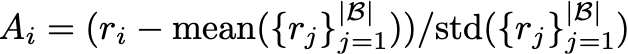
再使用 GRPO 損失函數更新 VLM 參數:
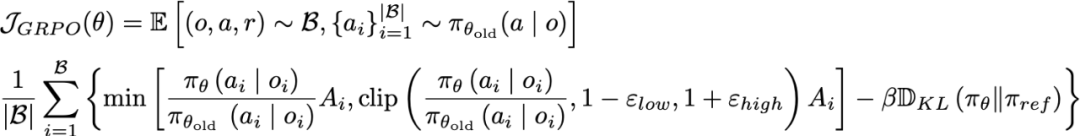
由此可實現每個回合多個並行環境同步推理、執行、記錄,再用當批數據實時更新策略,實現「邊操作邊學」的在線強化學習。
實驗結果
模型探索能力表現
文中的實驗使用了 Qwen2.5-VL-3B 和 Qwen2.5-VL-7B 作為基礎模型,如果不經訓練,直接讓 3B 的小模型與環境進行交互,模型只會在螢幕上「亂按一通」,未能成功打開任何一個軟件:
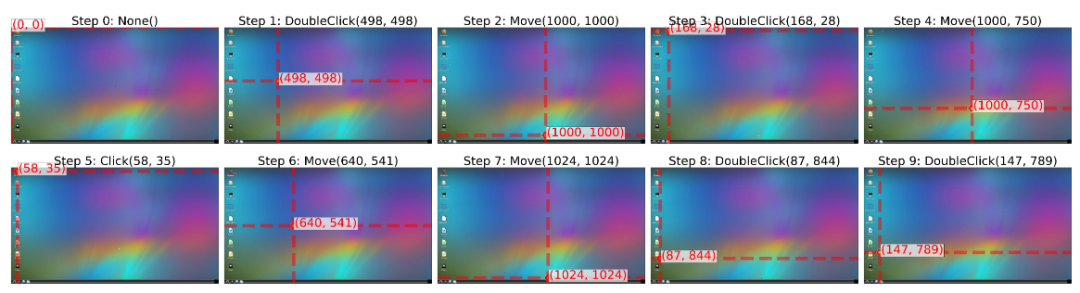
但是稍加訓練,模型就能成功打開一些桌面上的軟件:
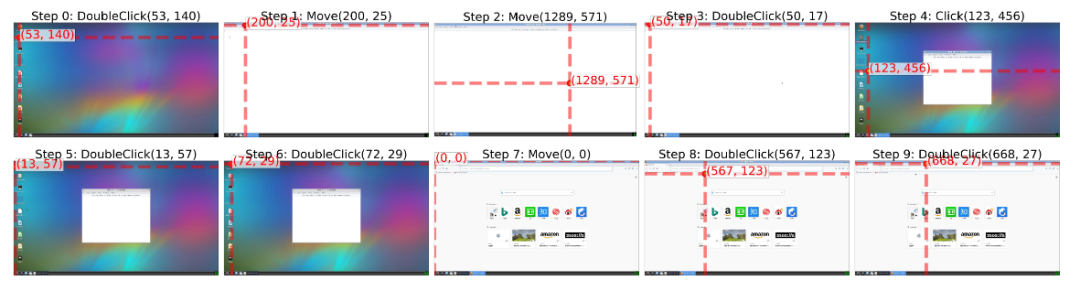
再進行一段時間的探索,模型學會探索到更深的頁面:

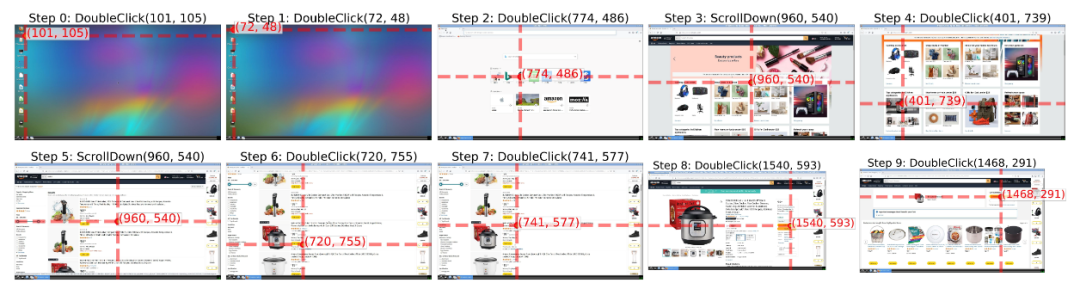
Qwen2.5-VL-7B 的模型表現更好,在一段時間的訓練後甚至能夠完成一次完整的「加購物車」過程:
基於啓發式和從世界模型導出的獎勵都非常易得,因此無需構建具體的任務獎勵函數,就能讓模型在環境中自己探索起來。動態訓練的 ScreenExplorer 能夠更加適應當前的環境,與調用靜態的 VLM 甚至專門為 GUI 場景訓練的模型相比,能夠獲得更高的探索多樣性:
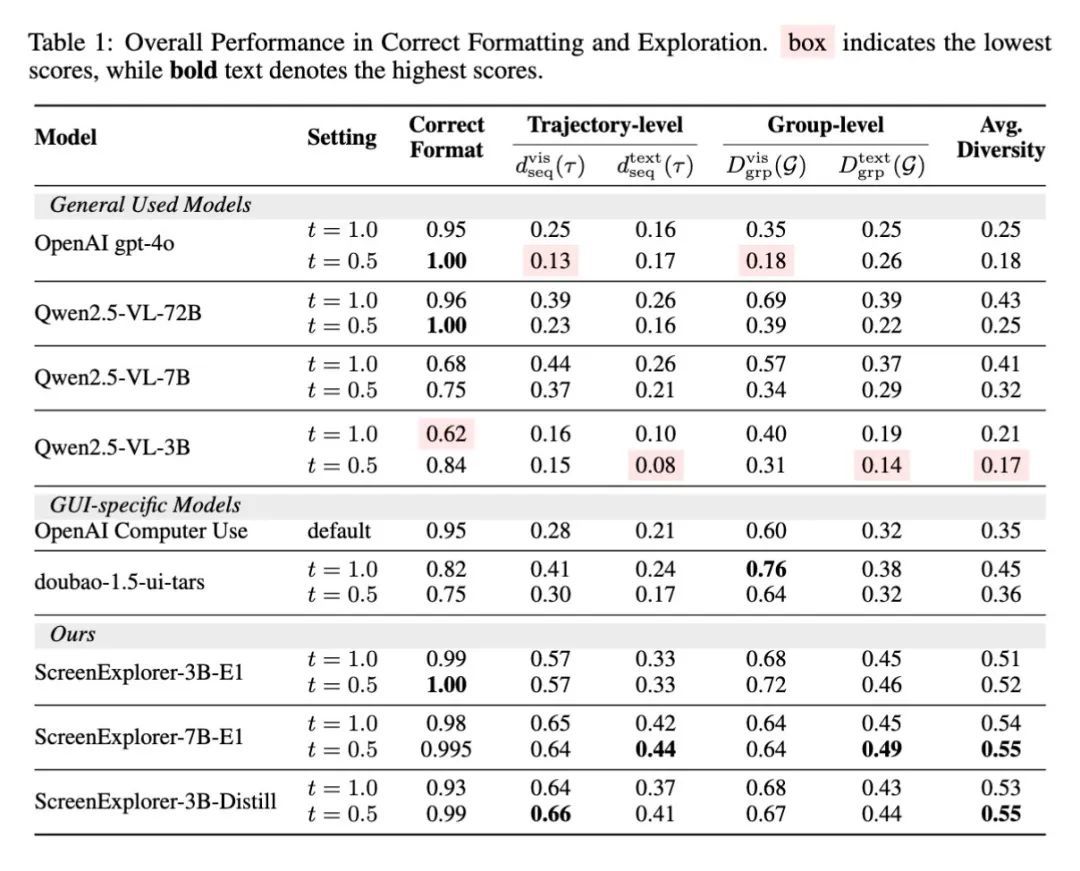
經強化學習訓練,原本探索能力最弱的基礎模型 Qwen 2.5-VL-3B 成功躍升為探索表現最佳的 ScreenExplorer-3B-E1。更高的探索多樣性意味着智能體能夠與環境開展更有效的交互,自驅地打開更多軟件或探索更多頁面,這為接下來訓練完成具體任務,或是從螢幕內容中學習新知識,提供了最基礎的交互和探索能力。
在訓練過程中,各分項的獎勵值不斷升高。此外,World Model 的重建損失一直保持在較高的水平,這也反應了模型一直在探索新的狀態。
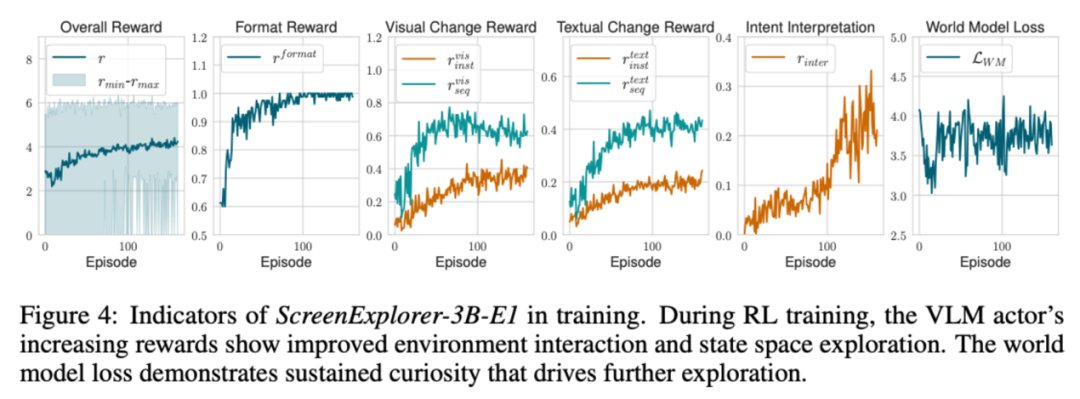
為什麼需要世界模型?
文中通過消融實驗對比了各類獎勵的必要性,尤其關注來自世界模型的好奇心獎勵對探索訓練的影響。實驗發現,一旦去掉來自世界模型的好奇心獎勵,模型就很難學習如何與環境進行有效交互,各項獎勵都未顯現提升的趨勢。
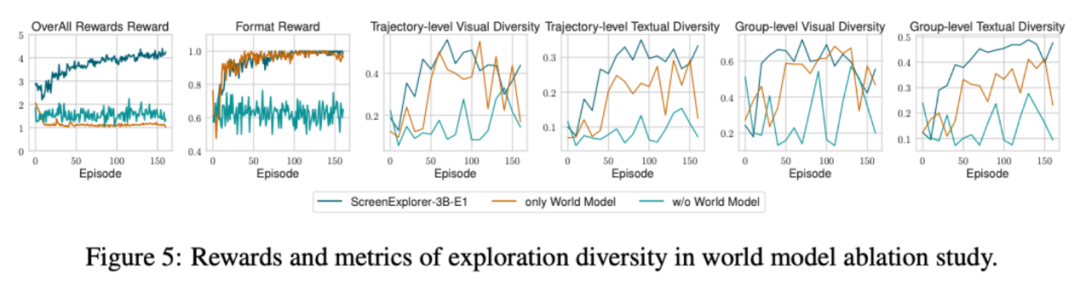
為了進一步了解來自世界模型好奇心獎勵給訓練帶來的影響,文中展示了各種消融設定下 GRPO Advantage 的變化趨勢。
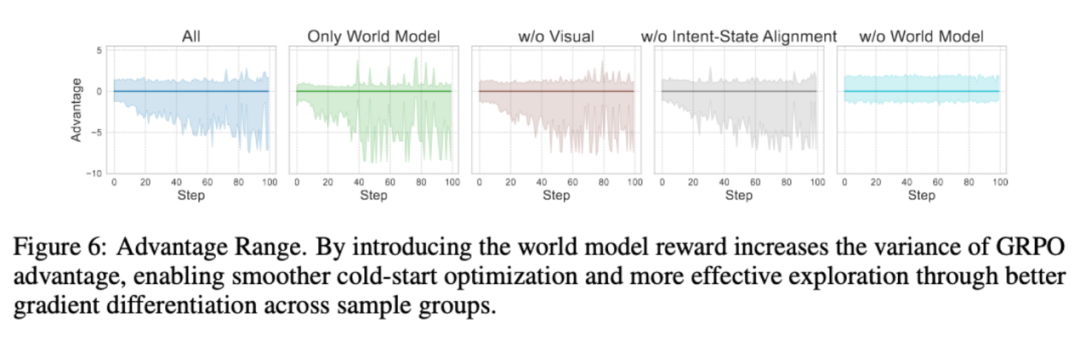
可以發現,來自世界模型的好奇心獎勵加大了 Advantage 的方差,這一點變化使得探索過程渡過了冷啓動階段。而沒有世界模型獎勵的消融組卻一直困於冷啓動階段,很難開展有效的探索。
新技能湧現
此外,文中還展示了模型在經過強化學習訓練後湧現出的技能,例如:
跨模態翻譯能力:
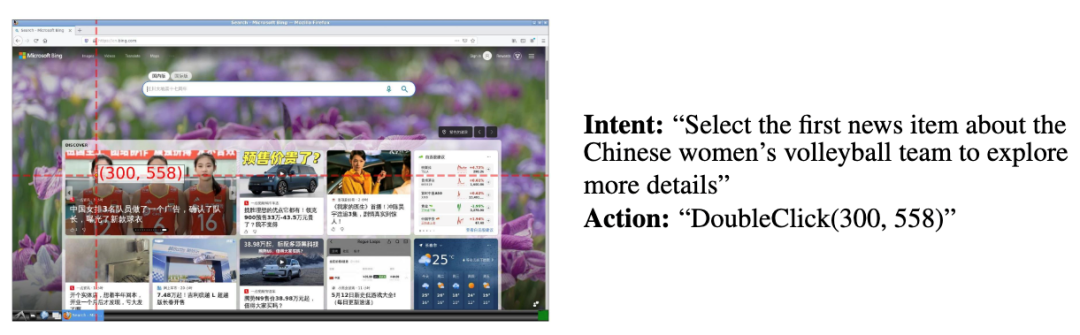
根據現狀制定計劃能力:

複雜推理能力:
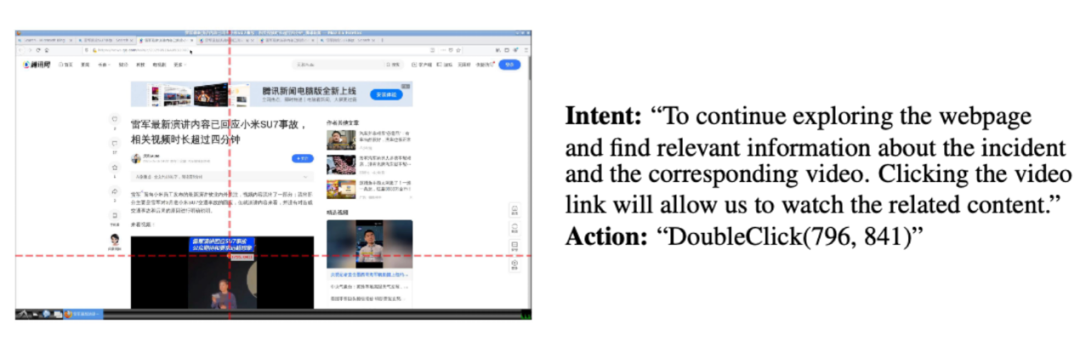
探索產生的樣本中,「意圖」字段可以視為免費的標籤,為之後構造完成具體任務提供數據標註的基礎。
結論
本研究在開放世界 GUI 環境中成功訓練了探索智能體 ScreenExplorer。通過結合探索獎勵、世界模型和 GRPO 強化學習,有效提升了智能體的 GUI 交互能力,經驗流蒸餾技術則進一步增強了其探索效率。該智能體通過穩健的探索直接從環境中獲取經驗流,降低了對人類遙控操作數據的依賴,為實現更自主的智能體、邁向通用人工智能(AGI)提供了一條可行的技術路徑。