炒股就看金麒麟分析師研報,權威,專業,及時,全面,助您挖掘潛力主題機會!
Agent能「看懂網頁」,像人類一樣上網?
阿里發布WebDancer,就像它的名字一樣,為「網絡舞台」而生。
只要輸入指令,它就可以幫你上網搜索、做攻略,實現自主信息檢索代理和類似深度研究模型的推理。
傳統模型只能按固定流程思考,而WebDancer作為一個端到端的自主信息搜索智能體,具備多步推理、工具使用和泛化能力。
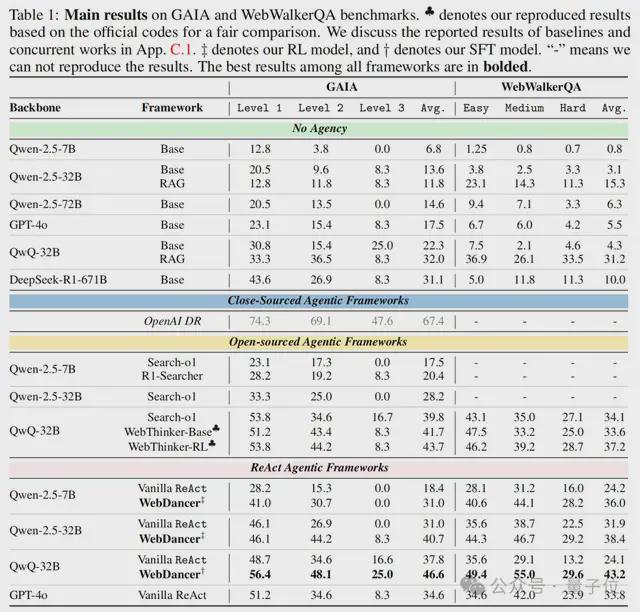
WebDancer在GAIA和WebWalkerQA上分別取得了61.1%和54.6%的Pass@3分數,優於基線模型和部分開源框架。
模型和方法均已開源,網友直呼想試:
WebDancer的祕密武器
不同於其它的推理問答模型,WebDancer要像人類一樣思考、理解並操作,可不是一件簡單的事情。
使用GAIA、WebWalkerQA和日常使用情況對WebDancer進行演示,可以看到,WebDancer能夠執行多步驟和複雜推理的長期任務,例如網頁遍歷、信息搜索和問答。
它的「祕密武器」是一種四階段訓練範式,包括瀏覽數據構建、軌跡採樣、針對有效冷啓動的監督微調以及用於改進泛化能力的強化學習。
阿里開源了這個訓練框架,使除了WebDancer以外的智能代理也能夠自主獲取自主搜索和推理技能:
1、瀏覽數據構建
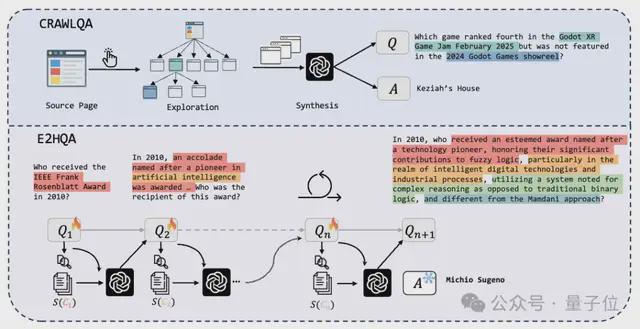
這一步的目標是創建覆蓋真實的網頁環境、需要多步交互的複雜QA對。
可以分為兩個網絡數據生成流程,如上圖所示。
在CRAWLQA中,需要先收集知識性網站(ArXiv、GitHub、Wiki等)的主URL,然後在主頁上系統地點擊和收集通過子鏈接可訪問的子頁面,模擬人類行為。
使用預定義規則,就可以利用GPT4o根據收集到的信息生成QA對(1.0版)了。
對於E2HQA(Easy-to-Hard QA)來說,將初始的簡單問題Q1通過實體檢索→信息擴展→問題重構的步驟,使任務在複雜性上逐步擴展,從簡單的實例到更具挑戰性的實例。
依然是使用GPT-4o重寫問題,直到迭代達到n,QA對足夠成熟。
2、軌跡採樣
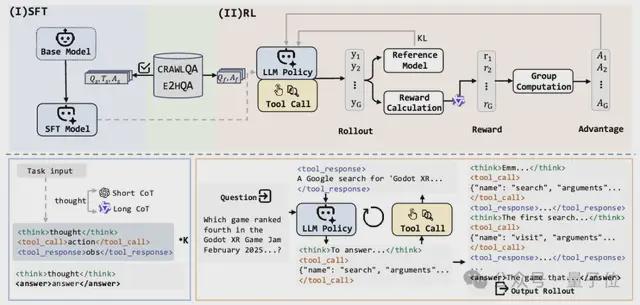
這一步要從QA對中生成高質量的思維-動作-觀察(Thought-Action-Observation)執行軌跡。
WebDancer的代理框架基於ReAct,這是語言代理最流行的方法,一個ReAct軌跡由多個思維-動作-觀察輪次組成:
在思維階段,模型會根據輸入生成推理鏈,然後在動作階段將參數為結構化JSON,最後在觀察階段返回結果(如網頁摘要或搜索片段)。
思維階段生成的思維鏈對智能體執行十分重要,WebDancer採用了雙路徑採樣的方法,可分為短思維鏈和長思維鏈兩條路徑:

因為LRM、QwQ-Plus在訓練過程中沒有接觸過多步推理輸入,在進一步推理時,WebDancer排除了之前的思維,但它們作為有價值的監督信號保留在了生成的軌跡中。
隨後,WebDancer採用了一個基於漏斗的三階段軌跡過濾框架,僅保留滿足以下三個標準的軌跡:信息非冗餘、目標一致性以及邏輯推理準確性。
3、有監督微調
在獲得ReAct格式的優質軌跡後,就可以將其無縫整合到智能體的有監督微調(Supervised Fine-Tuning,SFT)訓練階段,這個步驟可以教會模型基礎的任務分解與工具調用能力,同時儘可能保留其原有的推理能力。
在SFT階段,要先將軌跡轉換為標記化輸入,明確分隔符,然後計算Thought和Action部分的損失(忽略Observation噪聲),損失公式如下:
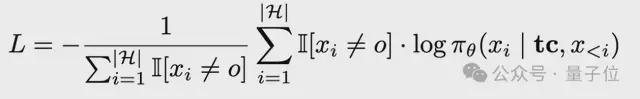
其中tc
是任務上下文,
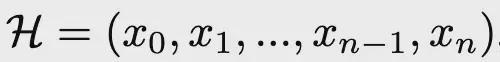
為完整的智能體執行軌跡,每個

代表思考/行動/觀察,
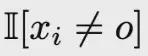
過濾掉對應外部反饋的標記,確保損失是在代理的自主決策步驟上計算的。
SFT階段為後續的RL階段提供了強大的初始化。
4、強化學習
這一步的目標是優化代理在真實網絡環境中的決策能力和泛化能力。
在SFT階段的基礎上,本階段採用解耦裁剪動態採樣策略優化算法(Decoupled Clip and Dynamic Sampling Policy Optimization,DAPO)來精調策略模型。
DAPO是一種基於獎勵模型R的策略優化算法,其工作原理如下:
首先,對於每個包含部分答案
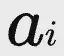
的階段軌跡
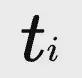
,算法生成一組候選執行序列
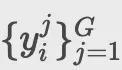
。通過最大化以下目標更新策略:
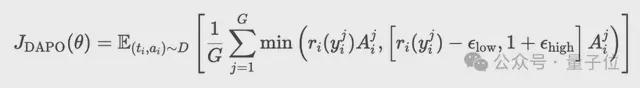
隨後,過採樣並過濾準確率為1或0的提示(prompts),確保智能體聚焦於高質量信號的學習。
最後,採用新舊策略的概率比替代固定KL懲罰項:
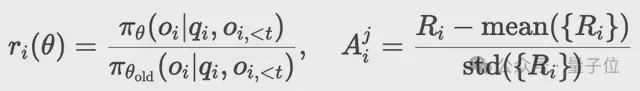

獎勵設計在RL訓練過程中起着至關重要的作用,WebDancer的獎勵機制主要由兩種類型的獎勵組成,分別為格式獎勵和答案獎勵,權重分別為0.1和0.9。
最終獎勵函數為:
有效性分析
在GAIA和WebWalkerQA這兩個成熟的基準數據集上測試WebDancer,結果顯示,WebDancer在GAIA上達到46.6%的平均準確率,WebWalkerQA上達到43.2%,優於基線模型和部分開源智能體框架。
可以看到,不具備代理能力的框架(No Agency)在GAIA和WebWalkerQA基準測試中均表現不佳,這突出了主動信息搜索和代理決策對於這些任務的重要性。
閉源代理系統OpenAI DR通過端到端強化學習訓練實現了最高分,在開源框架中,基於原生強推理模型(如QwQ-32B)構建的代理方法始終優於非代理對應方法,證明了在代理構建中利用推理專用模型的有效性。
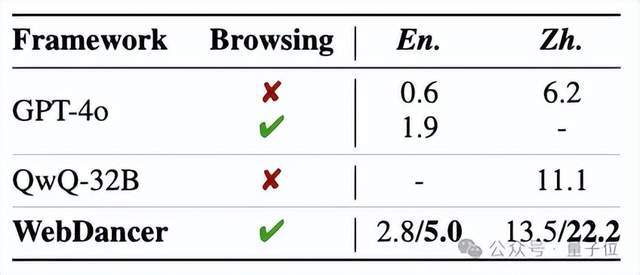
在兩個更具挑戰性的數據集BrowseComp(英文)和BrowseComp-zh(中文)上測試WebDancer,均表現出持續強勁的性能,突顯了其在處理困難推理和信息搜索任務中的魯棒性和有效性。
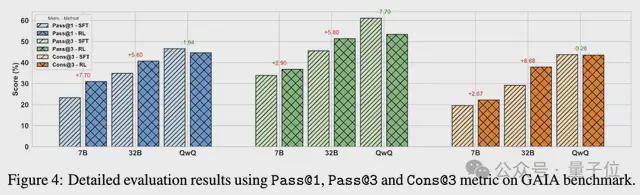
鑑於智能體環境的動態性和複雜性,以及GAIA測試集相對較小且變化較大的特點,對Pass@3和Cons@3進行細粒度分析。
值得注意的是,經過RL後的Pass@1性能與SFT基線的Pass@3相當,表明RL能夠更有效地採樣正確響應。
對於語言推理模型(LRMs),雖然經過RL後Pass@1、Pass@3或Cons@3沒有顯著提升,但在一致性方面有明顯的改善;這可能是過長軌跡導致的稀疏獎勵信號所致。
參考鏈接:
https://x.com/_akhaliq/status/1937997314737553873
論文:https://arxiv.org/abs/2505.22648
github:https://github.com/Alibaba-NLP/WebAgent/tree/main/WebDancer
模型:https://huggingface.co/Alibaba-NLP/WebDancer-32B