再這麼下去,大模型真要成免費電子書城了。
用大模型,就能讓 AI 吐出 90% 以上的《 哈利波特 》全文,你敢信嗎?
前段時間,斯坦福的團隊在 arXiv 上發表了一篇論文,名為《 從開源大模型中提取(受版權保護的)書籍的記憶片段 》。

在這篇文章裏,Meta 的 Llama 被重點點名,而被複刻的對象,是大夥兒都知道的《 哈利波特與魔法石 》。
復刻的過程非常簡單,主打一個古詩詞默寫,你給上半句,Llama 接下半句。而且判定很嚴格,要一字不差纔行。
只有中間一行是成功案例

這麼一來一回,實驗結果表示,《 哈利波特與魔法石 》有 91.14% 的內容都能被 Llama 記住,再給你原封不動地背出來。
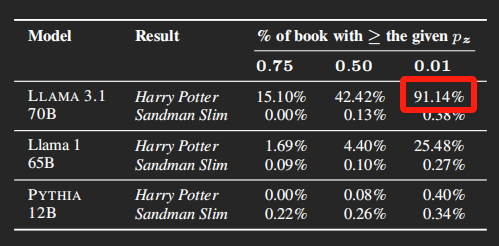

但說實話,這數據有點過於保守了。畢竟大部分人看書,多個字少個字也不影響理解,加上這部分容錯率,Llama 能背出來的比例絕對不止 91.14%。
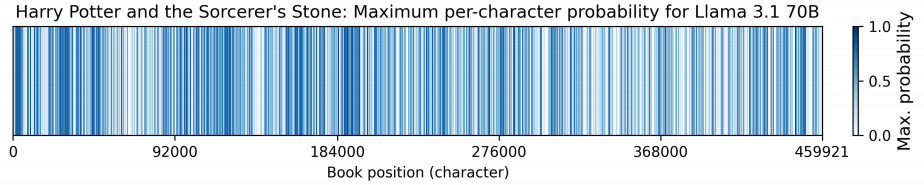
再結合下面這張圖,更是錘上加錘。它不僅記得多,還記得全呢。從小說開頭到結尾,均勻分佈,無一倖免。
從左到右代表小說的開始到結束。
豎線越密,可復刻內容越多,顏色越深,成功概率越高。
我們翻遍全文,發現哈利波特不是唯一一本被記住的,Llama 也不是唯一一個會背書的,大家或多或少都沾點。
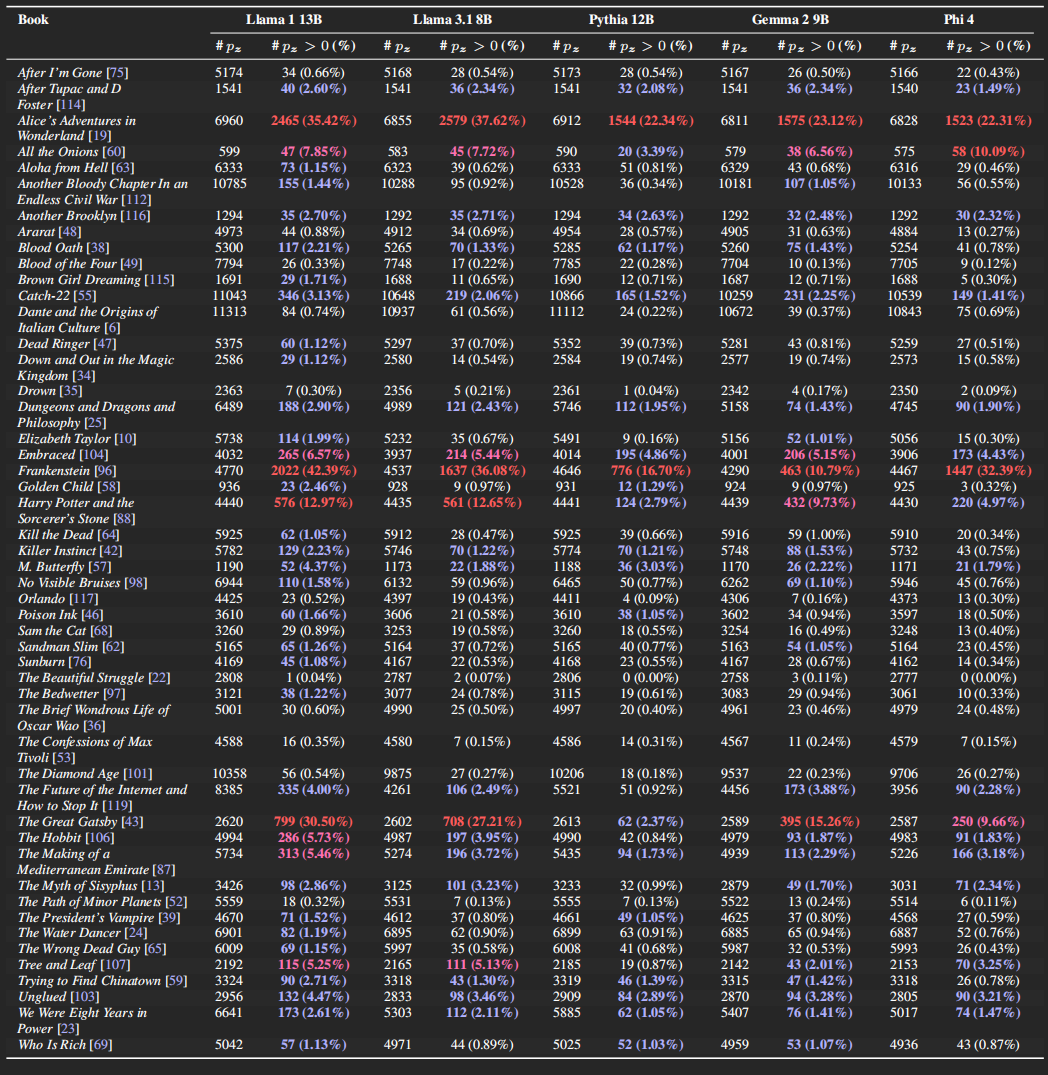
除了 Llama,Pythia、Gemma、Phi 也在這不恰當的時刻展示出了它們驚人的記憶力。文章裏只列出來了 100 本被記住的書,實際上它們背得更多。

本來拿版權方的東西去做訓練都忍不了,現在居然還能背出來?要不是現在大模型有上下文長度限制,豈不是一鍵輸出全文了?
咱認真研究了一下這個事,發現鍋一部分在科技公司頭上,另一部分在一個叫 Books3 的數據集上。
Books3 是一個包含 196640 本 txt 的數據集,裏面偷了不少盜版書。幾乎所有大模型都用它做訓練,不過數據集明面上很早就被下架,變成了不能說的祕密。
Paperwithcode 網站上留存的 Book3 悼詞

很顯然,大家都用了 Books3 搞訓練,只不過有些大模型沒做好安全防禦機制,才被抓住了把柄。

於是,經常被 gank 的 Meta 又一次被 13 位作家送上了法庭。
沒經我們允許,就拿我們的作品去訓練大模型。這回證據確鑿,還能一字不差吐出來,你認不認?
連一向討厭 JK 羅琳的喫瓜羣衆也紛紛覺得,拿盜版書訓練模型就是侵權,沒啥可洗的。
出乎所有人意料的是,Meta 居然贏了官司。看完了前因後果,我們覺得版權方純粹是輸在了智商。。。
版權方提出的舉證,是 Llama 把書背出來,損害到了他們真書的銷量。
但要說現在,有人用大模型生成哈利波特直接當成電子書看,那也太高難了,不可能在市場上和真書產生競爭關係。
再看看 Meta 方的辯詞:美國版權法 「允許未經授權,複製作品並將其轉化為新作品」,並且聊天機器人產生的人工智能表達,與訓練用的書籍有着根本的不同。
用人話講,科學的東西,你得看原理。大模型輸出的東西都是它學習理解再轉述出來的,就跟人讀書寫作似的,屬於 「新作品」 了。

最終法官表示,作者未能提供足夠證據證明,大模型會搶真書的份額,但用盜版訓練大模型,確實不地道。
意思就是,版權方論點對了,論據給錯了。

而版權方和大模型互撕,這不是第一次,肯定也不是最後一次。
2023 年,紐約時報起訴 OpenAI 訓練集涉及侵權。近期,還有 Reddit 起訴 Claude、迪士尼和環球聯合告 Midjourney、作家組團和微軟 Megatron 打官司等等。。。

感覺一個大模型要是沒被告過,只能說明它做得太拉了,無人在意。
在雷區反覆橫跳

那天天上法庭,科技公司就沒啥預防手段嗎?我們查了一下相關資料,發現為了不被告,有的公司選擇買斷網站數據庫,比如谷歌買斷 Reddit 數據包,而有的公司真是什麼匪夷所思的事都做得出來。
舉個最近的例子,2024 年 Claude 背後的 Anthropic 意識到使用盜版數據集的法律風險,於是花了數百萬美元購買實體圖書。

考慮到成本,收來的書裏很多是二手,掃描入庫製成數據集後立刻銷燬。數據集只在公司內部用於訓練,不可外傳。
這單純是為了迎合美國的首次銷售原則,只要你買了第一次,之後想怎麼處理它都可以。
咱也不知道這些實體書裏有沒有啥珍貴孤本,反正為了不侵權,Anthropic 沒坑儒,只焚書了。
這個舉動確實成為了 Anthropic 在法庭上的制勝一擊,但問題是,這麼做真的合理嗎?


喫完這個瓜,我能理解為啥那麼多版權方想手撕大模型,也能理解科技公司為啥非得幹這麼不地道的事兒。
從大模型訓練的角度,它無法避免對大量高質量數據的需求,科技發展不等人,也沒有時間等待各種授權。它能做到最好的,也就是把侵權的內容厚碼一下,儘量減小對正主的影響。
而從版權方的角度,大模型這樣發展下去,他們的利益遲早會被徹底侵犯。不止現在啃他們一口又一口,未來還可能被盜版訓練出來的模型取而代之。
這種不可調和的矛盾,造成為了形式正義而毀書一類的荒謬舉動。
只能說,爭取權益是必要的,但在這場爭端裏,恐怕沒有真正的贏家。
撰文:莫莫莫甜甜
編輯:江江 & 面線
美編:子曰
圖片、資料來源:
Reddit、Youtube、ChatGPT 、Reddit
https://arxiv.org/pdf/2505.12546
https://arstechnica.com/features/2025/06/study-metas-llama-3-1-can-recall-42-percent-of-the-first-harry-potter-book/
https://www.understandingai.org/p/the-ai-community-needs-to-take-copyright
https://paperswithcode.com/dataset/books3