炒股就看金麒麟分析師研報,權威,專業,及時,全面,助您挖掘潛力主題機會!
「那個要挑戰 GPT 的 00 後清華男孩」,再一次挑戰了 GPT 背後的 Transformer。2000 年出生於河南的王冠,從 8 歲開始學習編程,後被保送至清華大學計算機系。2024 年,王冠和加拿大西安大略大學校友鄭曉明聯合創辦了 Sapient Intelligence,公司的研發中心分別設在新加坡和美國硅谷。
 圖 | 王冠(來源:資料圖)
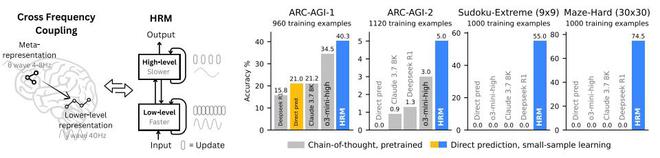
圖 | 王冠(來源:資料圖)幾天前,王冠和團隊僅憑 2700 萬參數以及僅 1000 個樣本的訓練,便解決了那些當前主流大模型和思維鏈模型極難解決的推理問題,比如抽象推理挑戰、數獨和複雜迷宮導航等。同時,該成果不僅克服了標準 Transformer 的計算侷限性,並且能夠模擬任何圖靈機。這便是王冠等人最新打造的分層推理模型——HRM。HRM 的英文全稱為 Hierarchical Reasoning Model,這是一種以人類大腦為啓發而打造的架構,它通過利用層級結構和多時間尺度處理,在不犧牲訓練穩定性或訓練效率的前提下,實現了顯著的計算深度。
儘管人們已經知道大腦高度依賴層級結構來支持大多數認知過程,但是這些概念在很大程度上仍然侷限於學術文獻,並未轉化為實際應用。而當前的主流 AI 方法仍然青睞非層級模型,但是 HRM 對這一既定範式提出了挑戰,並表明層級推理模型能夠作為當前主流思維鏈推理方法的一種可行性替代方案,並能朝着實現圖靈完備通用計算的基礎框架邁進。

助力開發具有通用計算能力的下一代 AI 推理系統
大模型在很大程度上依賴於思維鏈提示來進行推理,思維鏈通過將複雜任務分解為更簡單的中間步驟,將推理外化為 token 級語言,並使用淺層模型按順序生成文本。然而,思維鏈推理只是權宜之計,並非令人滿意的解決方案。它依賴於人為定義的、脆弱的分解過程,其中任何一個步驟的失誤或順序錯誤都可能完全打亂推理過程。這種對於顯式語言步驟的依賴,將推理束縛在了 token 級別的模式上。正因此,思維鏈推理通常需要大量的訓練數據,並會為複雜的推理任務生成大量的 token,從而導致模型響應變得緩慢。因此,需要一種更高效的方法來減少這些數據需求。基於此,王冠等人開展了本次研究。
為實現這一目標,他們探索了「隱式推理」,即讓模型在其內部潛在空間中進行計算。這也與以下認知相符:語言是人類交流的工具,而非思維本身的載體;大腦能在潛在空間中以極高的效率維持漫長且連貫的推理鏈,根本無需不斷將其翻譯回語言形式。然而,隱式推理的能力仍從根本上受到模型有效計算深度的限制。由於梯度消失問題嚴重影響訓練的穩定性和有效性,即使是簡單地堆疊網絡層也很難實現。作為序列任務的一種自然替代方案,循環架構往往存在收斂過早的問題,導致後續計算步驟失效,並且在訓練時依賴時間反向傳播(BPTT,Backpropagation Through Time),而這種方法在生物學上不具合理性,同時不僅計算成本較高,而且內存消耗較大。
人類大腦為實現當代 AI 模型所缺乏的有效計算深度提供了一個極具啓發性的藍圖。它通過在不同時間尺度運行的皮質區域間進行分層計算組織,從而能夠實現具備一定深度的多階段推理。循環反饋迴路會迭代優化內部表徵,使速度較慢的高級區域能夠引導次級加工;而速度較快的低級迴路則負責執行次級加工,同時保持整體連貫性。值得注意的是,大腦在實現這種深度的同時,避免了通常困擾循環神經網絡的反向傳播中昂貴的「信用分配」成本。
受這種分層和多時間尺度的生物架構啓發,王冠等人提出了 HRM,HRM 旨在顯著提高有效計算深度。它包含兩個耦合的循環模塊:一個是用於抽象、審慎推理的高層(H)模塊,另一個是用於快速、詳細計算的低層(L)模塊。這種結構通過被研究團隊稱之為「分層收斂」的過程,避免了標準循環模型的快速收斂。更新速度較慢的 H 模塊只有在更新速度較快的 L 模塊完成多個計算步驟並達到局部平衡後纔會前進,此時 L 模塊會被重置以開始新的計算階段。
此外,他們還提出了一種用於訓練 HRM 的單步梯度近似方法,該方法不僅提高了效率,還能消除對於隨時間反向傳播的依賴。這種設計在整個反向傳播過程中保持恒定的內存佔用,與隨時間反向傳播在 T 個時間步長下的 O(T)相比,其內存佔用為 O(1),這使其具備可擴展性,且在生物學上更具合理性。
得益於其增強的有效深度,HRM 在需要大量搜索與回溯的任務中表現卓越。HRM 僅使用 1000 個輸入-輸出示例,無需預訓練或思維鏈監督,就能學會解決那些即便是最先進的大模型也難以處理的問題。例如,它在複雜的數獨謎題(Sudoku-Extreme Full)中達到了近乎完美的準確率,在 30×30 迷宮中實現了最優路徑尋找,而最先進的思維鏈方法在這些任務上完全失敗(準確率為 0%)。
(來源:arXiv)
在抽象與推理語料庫(ARC,Abstraction and Reasoning Corpus)AGI 挑戰賽這一歸納推理基準測試中,HRM 模型從零開始訓練,僅使用有着大約 1000 個示例的官方數據集,參數規模僅為 2700 萬,上下文為 30×30 網格(900 個 tokens),卻達到了 40.3% 的性能表現。如下圖所示,o3-mini-high 的性能表現為 34.5%,Claude 3.7 的性能表現為 21.2%。也就是說,儘管 o3-mini-high 和 Claude 3.7 這兩個基於思維鏈的模型的參數規模和上下文長度都遠遠高於 HRM,但是 HRM 的性能仍大幅超越了它們。這代表着它為開發具有通用計算能力的下一代 AI 推理系統提供了一個富有前景的方向。
 (來源:arXiv)
(來源:arXiv)
HRM 靈感:「大腦三大神經計算原理」
此次提出的 HRM,其靈感來源於在大腦中觀察到的神經計算的三個基本原理:
第一個基本原理是分層處理:大腦通過皮層區域的層級結構來處理信息,高級區域會在更長的時間尺度上整合信息並形成抽象表徵,而低級區域則負責處理更即時、更詳細的感官信息和運動信息。
第二個基本原理是時間間隔:大腦中的這些層級以截然不同的內在時間尺度運作,這一點體現在神經節律中。例如,慢 θ 波的頻率為 4–8 赫茲;快 γ 波的頻率為 30–100 赫茲。這種分離使得高級區域能夠穩定地引導快速的低級計算。
第三個基本原理是循環連接:大腦具有廣泛的循環連接。這些反饋迴路能夠實現迭代優化,以額外的處理時間為代價,生成更準確且對上下文更敏感的表徵。此外,大腦在很大程度上避免了與隨時間反向傳播相關的棘手的深度信用分配問題。
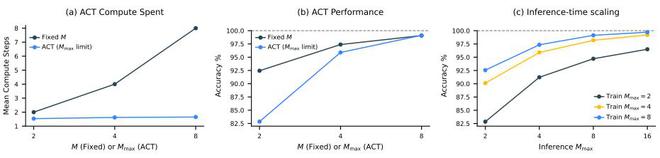
下圖展示了兩種 HRM 變體的性能對比:一種集成了自適應計算時間(ACT,Adaptive Computation Time),另一種採用與自適應計算時間的 Mmax 參數相當的固定計算步數。這表明,自適應計算時間能夠根據任務複雜度有效調整其計算資源,在顯著節省計算資源的同時,對性能的影響微乎其微。
 (來源:arXiv)
(來源:arXiv)對於推理時間擴展來說,一個高效的神經模型應在推理過程中利用額外的計算資源來提升性能。HRM 通過簡單地增加計算限制參數 Mmax,無需進一步訓練或修改架構,即可無縫實現推理時間擴展。
額外的計算能力對於需要更深入推理的任務尤其有效。在數獨遊戲這一經常需要長期規劃的問題上,HRM 展現出了顯著的推理時擴展能力。另一方面,研究團隊發現,在 ARC-AGI 挑戰中,額外的計算資源帶來的收益微乎其微,因為該挑戰的解決方案通常只需要少數幾次轉換操作。
 (來源:arXiv)
(來源:arXiv)
克服標準 Transformer 的計算侷限性
總的來看:
首先,HRM 具有一定的圖靈完備性。與包括通用 Transformer 在內的早期神經推理算法一樣,在給定足夠的內存限制和時間限制時,HRM 具有計算通用性。換句話說,它屬於能夠模擬任何圖靈機的模型類別,從而克服了標準 Transformer 的計算侷限性。由於早期神經算法推理器均採用循環神經網絡架構進行訓練,這些模型普遍存在早熟收斂問題,且需依賴內存密集型的隨時間反向傳播算法。因此,在實踐中它們的有效計算深度仍然有限。而通過解決這兩個挑戰並配備自適應計算能力,HRM 能夠在長推理過程上進行訓練,解決需要大量深度優先搜索和回溯的複雜謎題,並且更接近實際應用中的圖靈完備性。
其次,HRM 在連續空間中自然運行的機制更加合理。除了使用人工標註的思維鏈進行微調之外,強化學習是另一種被廣泛採用的訓練方法。然而,最近有證據表明,強化學習主要是釋放了現有的類思維鏈能力,而非發現了全新的推理機制。此外,與強化學習結合的思維鏈訓練存在不穩定性和數據低效性問題,通常需要大量的探索和精細的獎勵設計。相比之下,HRM 通過密集的梯度監督信號獲取反饋,而非依賴稀疏的獎勵信號。此外,HRM 在連續空間中自然運行,這種機制不僅更具生物合理性,還能根據推理與規劃複雜度的差異動態分配計算資源,避免對每個 token 進行均等化處理。這些結果凸顯了 HRM 在邁向通用計算和通用推理系統方面的潛力。
參考資料:
https://scholar.google.com/citations?user=-D0EgMIAAAAJ&hl=en
https://www.linkedin.com/in/guan-wang-447402338/
https://www.linkedin.com/in/austinzhenguwo/
https://arxiv.org/pdf/2506.21734
運營/排版:何晨龍