炒股就看金麒麟分析師研報,權威,專業,及時,全面,助您挖掘潛力主題機會!
在互聯網信息檢索任務中,即使是很強的LLM,有時也會陷入「信息迷霧」之中:當問題簡單、路徑明確時,模型往往能利用記憶或一兩次搜索就找到答案;但面對高度不確定、線索模糊的問題,模型就很難做對。
舉個例子,我們平常問一個直白的問題(比如「某城市的人口是多少」),搜索引擎一查即可。
但如果問題被設計得非常複雜,比如「這首與南美某首都密切相關的樂曲,其歌詞作者在21世紀初獲頒當地榮譽稱號,其旋律創作者曾就讀於哥倫比亞西部的一所著名藝術學院。這首樂曲叫什麼?」,人類和AI都很難直接找到入口。
這類問題需要閱讀許多網頁、抽絲剝繭地拼湊線索,逐步把迷霧撥開,才能找到答案。這超出了人類有限記憶和注意力的負荷,也遠遠超出了普通開源模型的能力範圍。
有沒有辦法讓開源的大模型也掌握這種撥雲見日的本領?
阿里巴巴通義實驗室最新提出的方案WebSailor通過一整套創新的post-training方法,大幅提升了開源模型在複雜網頁推理任務上的表現。

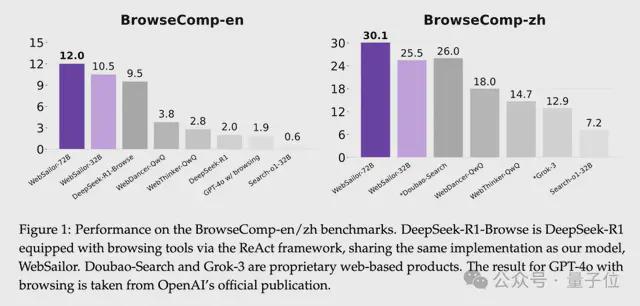
此前開源的Agent在類似BrowseComp這樣複雜的、超越人類能力邊界的基準上幾乎為零,WebSailor成為首個挑戰BrowseComp基準的開源網絡智能體。
BrowseComp難在哪
OpenAI於2025年4月發布BrowseComp,它的挑戰在於將答案線索拆解得極其零碎,並散佈在不同類型和時期的模糊信息源中,形成一張巨大的「信息迷霧網」。這就要求智能體必須主動在廣闊的互聯網中搜集信息,從海量內容中過濾掉無關的噪聲,再通過嚴密的多步推理和交叉驗證,才能將所有線索串聯起來。

比如下面這個問題,要求智能體追蹤一個橫跨大陸、涉及幾代人的間諜網絡:
相比之下,閉源系統近年來顯示出驚人的實力。
OpenAI的DeepResearch在極其複雜的信息檢索挑戰中達到了超越人類的表現。
這些系統能在複雜網頁任務(如BrowseComp中需要跨越衆多網站尋找隱蔽信息的問題)上取得人類專家都難以企及的成績,其關鍵在於「不確定性消解推理能力」。
但遺憾的是,這些閉源方案如同黑盒,其內部原理和訓練方法不得而知。這使研究者和開源社區難以借鑑這些成功經驗,開源模型與閉源頂尖模型之間一直存在明顯的能力鴻溝。
WebSailor的核心方法
WebSailor的技術方案涵蓋從數據到訓練的全流程創新:首先,大規模合成具有高不確定性(uncertainty)的複雜任務數據(稱為SailorFog-QA);
然後,藉助開源reasoning model獲得多輪工具調用軌跡再重構推理過程,並基於Qwen-2.5-72b-instruct和Qwen-2.5-32b-instruct進行RFT冷啓動訓練;最後,引入高效的強化學習算法DUPO進一步提升模型的決策能力。
通過這一系列措施,WebSailor 大幅度提升了開源模型在複雜信息檢索任務上的能力,在 BrowseComp-en/zh等基準上全面超越此前所有開源方案。
SailorFog-QA:高不確定性任務的大規模生成

WebSailor 團隊首先定義了information seeking任務中的三個層次:
level-1:任務具有較低的不確定性,且易於降低不確定性。這類任務包括模型可以通過自身知識或一次簡單的網絡檢索即可解答的問題。
level-2:如多跳問答(multi-hop QA),初始不確定性較高,但有清晰的解決路徑。雖然需要多步推理,但相關實體之間由明確的邏輯聯繫,通過有序的推理步驟,可以系統性地降低不確定性。
level-3:本研究的重點,涉及高不確定性且難以消除的問題。此類任務中的實體之間關係複雜、難以預先定義推理路徑。解決這類問題需要創造性的探索和新穎的推理方式,而這些往往難以被人工明確規定。
要讓模型學到超越人類的複雜推理模式,首先需要讓模型見過足夠多高不確定性的難題。為此,WebSailor 團隊構建了名為SailorFog-QA的大規模合成數據集。該數據通過圖結構採樣和信息模糊化來生成,專門用於鍛鍊模型在極端不確定環境下的檢索與推理能力。
隨機遊走建圖,構造複雜知識結構:
研究者模仿隨機遊走(random walk)的方式,在真實網頁上爬取信息並構建知識圖譜。首先從維基數據等知識庫中選取冷門實體作為起點,確保問題具有隱蔽性。然後在整個互聯網中不斷隨機擴展圖譜,將更多相關實體和關係加入其中,形成一個高度非線性、稠密連接的知識網絡。與傳統多跳推理那種線性鏈式結構不同,這種隨機圖中沒有預定義的解題路線。它為模型營造了一個迷霧般的信息空間,迫使模型發展出創造性探索策略。
子圖採樣生成問題,模糊細節增加不確定性:
在得到複雜知識圖後,從中隨機採樣子圖,據此設計問答對。這些問題涉及子圖中的多個實體和關係,問題與答案往往橫跨多個領域,組成了豐富多樣的信息集合。為進一步提升難度,WebSailor對問題內容進行了刻意的「模糊化」處理。例如,將確切年份表述成含糊的時間段(「21世紀初」),將人物姓名隱去一部分(「由姓名首字母為F的人創立的機構」),或用定性描述替代精確數值(「市場佔有率不到1%」)。這種信息模糊化直接提高了初始不確定性,使模型無法通過簡單的精確匹配或查找立即得出答案。它必須真正理解、推理和比較大量信息後,才能抽絲剝繭找到線索。
生成的SailorFog-QA數據具有以下突出優點:
真實且貼近真實互聯網分佈:所有問題都源自真實互聯網內容,確保模型訓練所面對的挑戰貼近實際網頁環境。模型需要像現實中那樣在海量雜亂的信息中找尋答案,而非理想化的合成語料,也避免了全部信息來自例如Wikipedia這樣的單一信息源。
多樣的複雜推理模式:不同子圖拓撲結構自然產出了各式各樣的問題類型,涵蓋多步演繹、組合推理、比較分析等複雜推理需求。這迫使模型練習廣譜的推理技能,而非侷限於某單一套路。
規模可擴展:
由於從一個圖譜可以採樣出多種子問題,且圖譜本身可隨機擴展,SailorFog-QA 的生成高度可擴展,能夠非線性地增長產生海量的困難問題。這為大規模訓練提供了充足燃料。
通過上述策略,研究團隊生成了數量龐大、難度空前的訓練問題。其中許多問題之複雜,即使是經驗豐富的人類研究者在有限時間內也難以解答。在內部測試中,一些題目甚至需要OpenAI的o3調用多達40次工具才能找到答案,這充分說明了SailorFog-QA任務的初始不確定性之高,以及要解答它們所需推理鏈條之長。
為了讓模型學習解決這些複雜問題,還需要相應的解決問題的軌跡用於訓練。對此,研究團隊藉助開源的LRM(如QWQ和DeepSeek R1)來嘗試回答SailorFog-QA的問題,收集它們與環境交互的軌跡,雖然開源模型在這些複雜問題上正確率不高,但通過拒絕採樣,依然可以獲得足夠的冷啓動數據。但它們原生的推理輸出並不適合直接進行微調,這些模型表現出高度固定且冗長的思維過程,如果模仿這些模型,可能會限制受訓智能體開發自身靈活探索性策略的能力。此外,在需要數十次工具調用的長周期 Web 任務中,它們冗長的思維鏈很快就會佔滿上下文窗口,導致性能和可讀性下降。為了解決這些問題,研究者提出了一種新方法:使用這些開源 LRM 生成的正確Action-Observation軌跡,然後重構Thought過程。確保每一步Thought的簡潔和行動導向,由此構建了一個乾淨、有效的RFT數據集,可以捕捉LRM解決問題的邏輯過程,而不會繼承它們固定的風格和冗長的推理。
有了高難度的問答對和對應的解題軌跡後,研究者首先進行了RFT冷啓動訓練。RFT(拒絕採樣微調)挑選高質量的解題軌跡對模型進行初步對齊。近年來有研究建議在RL訓練前跳過SFT,但在如此複雜的網頁環境下,團隊發現適度的RFT冷啓動至關重要。因為此類任務的獎勵極其稀疏,如果不先教會模型基本的工具使用和思維框架,直接強化學習將面臨幾乎收集不到有用經驗的問題。WebSailor 僅使用了幾千條高質量軌跡進行冷啓動微調,就有效地讓模型掌握了基本的ReAct式推理和工具調用習慣。這為後續的強化學習階段打下了必要的基礎。
DUPO:高效的強化學習訓練框架
在完成初步微調後,WebSailor 進入強化學習階段,以進一步提升模型的決策策略。複雜網頁任務下的Agent強化學習非常困難:每一次推理都涉及多輪與瀏覽器環境的交互(搜索、閱讀網頁等),導致一條軌跡可能包含數十步。這種多輪工具調用使單次訓練耗時長、樣本效率低。傳統RL方法若不加改進,模型在這樣的環境下學得會非常慢。
為此,團隊提出了全新的高效強化學習算法DUPO(Duplicating Sampling Policy Optimization)。DUPO 在訓練中引入了雙階段動態採樣策略,大幅提高了訓練效率,確保即使在密集工具交互的情境中,也能快速迭代模型。
DUPO的核心思想有兩點:
首先,在正式RL訓練前,剔除掉過於簡單的訓練QA——例如那些模型已經可以輕鬆通過的案例。這些例子對策略改進幾乎沒有貢獻,反而浪費訓練資源。通過預先過濾,保證訓練中模型主要面對具有挑戰性的QA。
具體來說,如果同一批中某些問題的解答結果存在不確定性(不同嘗試間結果差異大),就認為這些問題仍有學習價值。此時,與其用無關的填充來湊滿Batch,不如將這些尚未完全學會的樣本複製多份,重複放入當前批次進行訓練。這樣模型在一次迭代中多次練習這些棘手案例,相當於對困難樣本加大訓練力度。而對於模型已掌握或完全無解的樣本,則不浪費額外精力。這種Batch內動態複製的策略,使每個Batch都被充分利用。
通過以上改進,相比於DAPO這類為batch做填充的動態採樣,DUPO 將複雜Agent的RL訓練速度提升了約2–3倍。訓練過程中,WebSailor 還採用了嚴格的獎勵設計:結合格式正確性和答案準確性兩個方面評估軌跡。模型只有既遵循了預定的思維-行動格式(如正確使用和標籤等),又最終找到正確答案時,才能獲得高分獎勵。這一設計杜絕了獎勵Hack行為,促使模型提升推理鏈條的有效性。
實驗結果:超越DeepSeek R1, GPT-4.1, Grok-3等一系列開閉源模型
經過上述一系列訓練之後,WebSailor在多個benchmark集上表現優秀,成為當前最強的開源網絡智能體。論文在BrowseComp-en、BrowseComp-zh、XBench-DeepSearch和GAIA等挑戰性基準上對WebSailor進行了評測。

綜合來看,WebSailor在各項複雜網頁信息任務中全面刷新了開源成績的紀錄。尤其是在最困難的BrowseComp基準上,WebSailor展示出的能力充分驗證了作者的核心假設:只有讓模型訓練中經歷過那些高度不確定的難題,模型才能學會真正強大的通用推理和規劃策略。換言之,WebSailor通過「製造迷霧再穿越迷霧」的訓練,賦予了模型以前所缺乏的非線性推理能力,超越了DeepSeek R1, GPT-4o, Grok-3等一系列開閉源模型。雖然目前DeepResearch等閉源方案仍保有一定優勢,但WebSailor的崛起無疑證明了開源模型完全有機會迎頭趕上。
對簡單任務的兼容性
WebSailor僅在高難度數據上進行訓練,而BrowseComp-en/zh、GAIA以及Xbench根據我們的定義,都可歸類為level-1或level-2的任務。為了驗證WebSailor在更簡單的一級任務中是否依然表現優異,我們在SimpleQA的子集上評估了其性能。SimpleQA完整數據集包含4326對QA對。由於在整個數據集上測試十分耗時,我們隨機抽取了200對進行評測。該benchmark以高準確性和基於事實的簡單問題為特點,這類問題對於先進的LLM來說直接解答仍具挑戰性。結果如下圖所示,幾乎所有基於Agent的方法都優於直接作答。其中,WebSailor的表現超越了所有其他方法,即使在簡單任務上也展現出極強的兼容性和有效性。

總結與展望
WebSailor的成功具有重要的行業意義。首先,它大幅縮小了開源與閉源網頁智能體之間的能力鴻溝。過去,只有頂尖閉源模型才能實現最先進的推理和信息檢索能力。而WebSailor通過創造性地構造數據和訓練流程,證明了這一差距並非不可逾越。這鼓舞了開源社區:即使在複雜webagent這種高度挑戰性的任務上,開源方案也有希望後來居上。WebSailor已經開源了部分SailorFog-QA數據,並即將開源模型checkpoint,這對資源有限的團隊和研究者來說,無疑是一個令人振奮的消息。
其次,WebSailor提供了一個通用的workflow,可借鑑到其他領域的問題中。它強調的「高難度任務合成 + 小規模冷啓動 + 高效RL優化」的組合拳策略,具有很強的普適性。未來,開源社區可以參考WebSailor的思路,去攻克更多類似「超越人類能力」的任務——比如開放領域的複雜推理問答、學術知識發現,甚至跨模態的信息整合等。
WebSailor的工作表明,要讓AI真正邁向「超越人類能力」的級別,僅靠現有的簡單訓練任務遠遠不夠,必須定義更復雜、更高不確定性的新任務,不斷挑戰模型的極限。下一步他們將繼續探索如何基於開源模型提升Agent的能力上限,不僅是在信息檢索領域,而是追求更廣泛維度上達到「超越人類」的表現。這意味着未來我們可能看到:更復雜的推理任務被構造出來,Agent要在更加開放的世界中自主探索、決策,甚至去完成一些人類尚不能完成的綜合性任務。
GitHub:https://github.com/Alibaba-NLP/WebAgent
arXiv:https://arxiv.org/abs/2507.02592