炒股就看金麒麟分析師研報,權威,專業,及時,全面,助您挖掘潛力主題機會!

內容來自:機器之心
我們終於擺脫 tokenization 了嗎?
答案是:可能性無限大。
最近,Mamba 作者之一 Albert Gu 又發新研究,他參與的一篇論文《 Dynamic Chunking for End-to-End Hierarchical Sequence Modeling 》提出了一個分層網絡 H-Net,其用模型內部的動態分塊過程取代 tokenization,從而自動發現和操作有意義的數據單元。

「這一研究預示着 Tokenizers 正在退場,智能字節分塊(Smart Byte Chunks)開始登場。或許無需 Tokenizer 訓練的時代真的要來了 —— 可能性無限大。」X 知名博主 Rohan Paul 表示道。

現階段,Tokenization 仍然是語言模型和其他順序數據不可或缺的組成部分,因為它能夠壓縮和縮短序列。然而 Tokenization 存在許多缺點,如可解釋性差,在處理複雜語言(如中文、代碼、DNA 序列)時性能下降等。
迄今為止,尚未有任何端到端的無 tokenizer 模型在計算預算相匹配的情況下超越基於 tokenizer 的語言模型的表現。最近,已經有研究開始致力於在自迴歸序列模型中突破 Tokenization 限制。
在此背景下,來自 CMU、 Cartesia AI 等機構的研究者提出了一系列新技術,通過動態分塊機制實現內容與上下文自適應的分割策略,該機制可與模型其他部分聯合學習。將這一機制融入顯式分層網絡(H-Net)後,原本隱含分層的「tokenization–LM–detokenization」流程可被完全端到端的單一模型取代。
在計算資源和數據量對等的條件下,僅採用單層字節級分層的 H-Net 模型,其表現已優於基於 BPE token 的強 Transformer 語言模型。通過多級分層迭代建模不同抽象層級,模型性能得到進一步提升 —— 這不僅展現出更優的數據規模效應,更能媲美兩倍規模的基於 token 的 Transformer 模型。
在英語預訓練中,H-Net 展現出顯著增強的字符級魯棒性,並能定性學習有意義的、數據依賴的分塊策略,全程無需啓發式規則或顯式監督。
最後,在 tokenization 啓發式方法效果較弱的語言和模態(如中文、代碼或 DNA 序列)中,H-Net 相比 tokenization 流程的優勢進一步擴大(數據效率較基線提升近 4 倍),這證明了真正端到端模型從未經處理數據中實現更優學習和擴展的潛力。

論文地址:https://arxiv.org/pdf/2507.07955v1
沒有 Tokenization 的端到端序列建模
本文提出了一種端到端的分層網絡(H-Net),通過遞歸、數據依賴的動態分塊(DC,dynamic chunking)過程壓縮原始數據(見圖 1)。H-Net 在保持與 token 化流程相同效率的同時,通過用從數據中學習的內容感知和上下文依賴的分割替代手工啓發式方法,顯著提高了建模能力。

分層處理
H-Net 採用了分層架構,其工作流程分為三步:
這種設計形成了天然的認知分層 —— 外層捕捉細粒度的模式,內層處理抽象概念。
關鍵是,主網絡包含了大部分參數,並且可以適配任何標準架構,例如 Transformer 或狀態空間模型(SSM)。
動態分塊
H-Net 的核心是動態分塊(DC)機制,它位於主網絡與編碼器 / 解碼器網絡之間,用於學習如何分割數據,同時使用標準的可微優化方法。DC 由兩種互補的新技術組成:
(i) 路由模塊,通過相似度評分預測相鄰元素之間的邊界;
(ii) 平滑模塊,使用路由器的輸出插值表示,通過減弱不確定邊界的影響,顯著提高學習能力。
通過將這些技術與一個新的輔助損失函數結合,並利用現代基於梯度的離散選擇學習技術,DC 使得 H-Net 能夠以完全端到端的方式學習如何壓縮數據。
信號傳播
本文還引入了幾種架構和訓練技術,以提高端到端優化過程中的穩定性和可擴展性。這些技術包括:(i) 精心佈置的投影層和歸一化層,以平衡交互子網絡之間的信號傳播;(ii) 根據每層的維度和有效批次大小調整其優化參數。
總的來說,H-Net 學習了與主幹網絡聯合優化的分割策略,基於上下文信息動態地將輸入向量壓縮成有意義的數據塊。
H-Net 代表了第一個真正的端到端、無 tokenizer 的語言模型:通過一個動態分塊階段,字節級的 H-Net 在超過 10 億參數的規模下,達到了與強大的 BPE token 化 Transformer 相當的困惑度和下游性能。
從經驗上看,動態分塊模塊自然地將數據壓縮到與 BPE tokenizer 相似的分辨率(每塊 4.5-5 字節),並且在沒有任何外部監督或啓發式方法的情況下,定性地學習到有意義的邊界。
實驗及結果
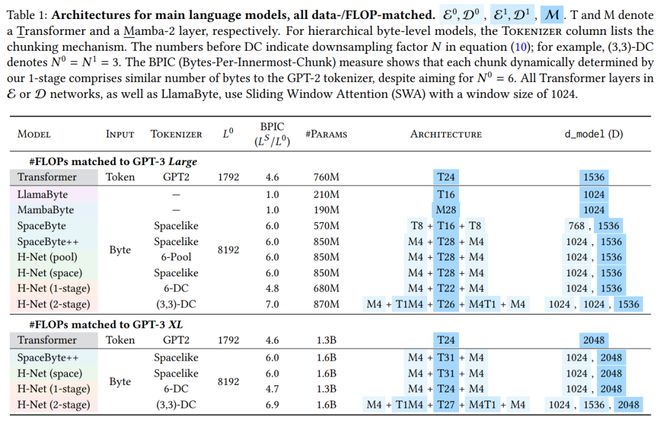
實驗中,本文采用的主要語言模型架構如下所示,如 MambaByte 是使用純 Mamba-2 層的各向同性模型。
 訓練曲線。圖 3 顯示了 Large 和 XL 規模模型在整個訓練過程中的驗證 BPB 指標。
訓練曲線。圖 3 顯示了 Large 和 XL 規模模型在整個訓練過程中的驗證 BPB 指標。
在較大規模上,本文注意到:
所有各向同性模型在性能上都遠遜色於分層模型。在這些模型中,MambaByte 明顯優於 LlamaByte。
SpaceByte 明顯遜色於 SpaceByte++,這一結果驗證了本文在外部網絡中使用 Mamba 的有效性。SpaceByte++ 又比 H-Net(space)差,表明本文提出的改進信號傳播技術的有效性。
H-Net(space)是一個非常強大的模型,達到了與 BPE Transformer 相當的性能,驗證了數據依賴的分塊策略與精心設計的分層架構的效果。
表 2 展示了不同模型在多個下游基準測試上的零樣本準確率。
SpaceByte++、H-Net(space)和 H-Net(1-stage)在大規模上與 BPE Transformer 的性能相似,在 XL 規模上稍微超越了 BPE Transformer。

表 3 評估了模型在 HellaSwag 上的魯棒性。與所有基準模型相比,H-Net(2-stage)顯著提高的魯棒性。

圖 4 提供了 H-Net(1-stage)和 H-Net(2-stage)動態繪製的邊界的可視化圖。這些可視化提供了關於模型如何決定邊界的幾個重要見解。

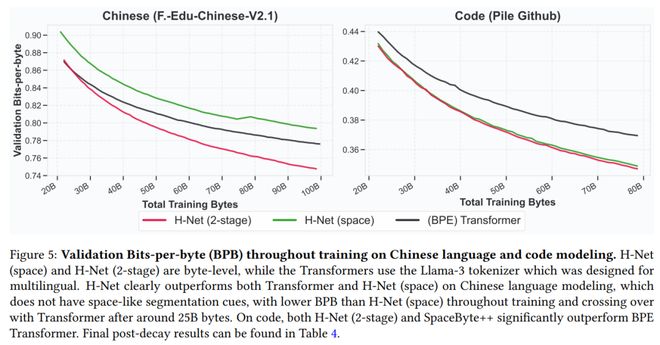
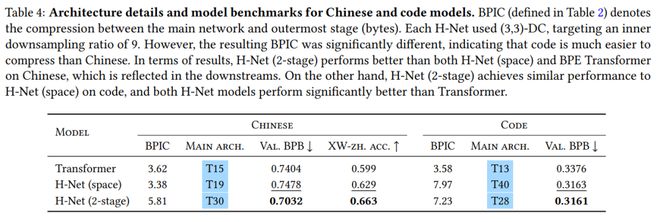
即使使用 Llama3 tokenizer,本文發現 H-Net(2-stage)在中文和代碼處理上,比 BPE Transformer 和 H-Net(space)具有更好的擴展性(圖 5),並且在衰退階段後實現了更低的壓縮率(表 4)。
之前的研究已經證明,SSM 在 DNA 序列建模上比 Transformer 表現更好。實驗(表 5)也驗證了這一點:即使換成 Mamba-2 作為主網絡,SSM 的優勢仍然存在。
實際上,通過直接比較訓練穩定階段的困惑度曲線(圖 6),本文發現 H-Net 模型在數據量僅為 3.6 倍的情況下,能夠達到與各向同性模型相似的性能,這一發現適用於兩種主網絡架構的選擇。

最後,Albert 還撰寫了精彩的博客文章,介紹關於 H-Net 的幕後故事和精彩見解。感興趣的讀者可以前去閱讀。
博客地址:https://goombalab.github.io/blog/2025/hnet-past/
了解更多內容,請參考原論文。
(轉自:網易科技)