炒股就看金麒麟分析師研報,權威,專業,及時,全面,助您挖掘潛力主題機會!

新智元報道
編輯:定慧 好睏
【新智元導讀】最近,一款全新的獎勵模型「POLAR」橫空出世。它開創性地採用了對比學習範式,通過衡量模型回覆與參考答案的「距離」來給出精細分數。不僅擺脫了對海量人工標註的依賴,更展現出強大的Scaling潛力,讓小模型也能超越規模大數十倍的對手。
一直以來,讓AI更懂人類都是大模型領域的核心議題。
而獎勵模型(RM)便是解決如何「理解人類偏好」的核心技術,同時也是限制後訓練效果的關鍵因素。
2024年12月,OpenAI提出了一種新的強化微調(Reinforcement Fine-tuning,RFT)技術。在RFT過程中,打分器(Grader)會根據標準答案給出獎勵分數,從而幫助模型「學會」如何給出正確結果。
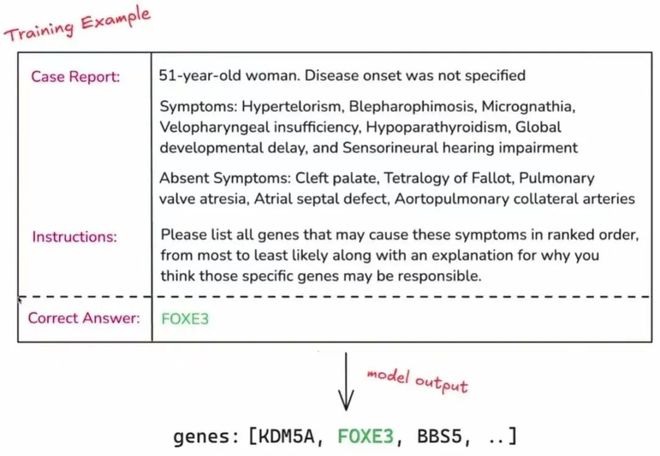 圖1:OpenAI強化微調代表樣例
圖1:OpenAI強化微調代表樣例在此啓發下,一種可以規避獎勵模型準確度低、泛化性差等固有問題的,基於規則驗證(RLVR)的方法應運而生。
然而,RLVR在很多情況下只能提供0/1獎勵,無法給出更加細粒度的偏好區分。
比如像寫詩、聊天這類開放式問題,就很難實現泛化,進而限制了在更通用場景中的應用。
針對這一問題,來自上海人工智能實驗室和復旦大學的研究人員,在最近提出了一種全新的獎勵模型POLAR,並開源了1.8B和7B兩個參數規模的版本。
區別於傳統的「基於絕對偏好」的獎勵模型,POLAR採用了全新對比學習預訓練範式,可以根據參考答案,靈活地對模型回覆給出獎勵分數。
實測結果表明,POLAR已經充分展現出了一個出色「Grader」的潛質。

論文鏈接:https://arxiv.org/abs/2507.05197
項目鏈接:https://github.com/InternLM/POLAR
模型鏈接:https://huggingface.co/internlm/POLAR-7B
我們將開篇提到的OpenAl生物基因領域官方樣例輸入POLAR,並構造了一些模型回覆後發現,POLAR可以完美地給出正確的偏序關係!
回覆一(與參考完全一致):
FOXE3
分數:-0.278
回覆二(正確答案Rank 1):
genes: [FOXE3, KDM5A, BBS5]
分數:-7.889
回覆三(正確答案Rank 2):
genes: [BBS5,FOXE3, KDM5A]
分數:-7.998
回覆四(正確答案Rank 3):
genes: [KDM5A, BBS5,FOXE3]
分數:-8.008
回覆五(與正確答案相似的拼寫錯誤):
genes: [FOXE2, KDM5A, BBS5]
分數:-8.965
回覆六(無正確答案):
genes: [CHD7, KDM5A, BBS5]
分數:-10.225
除此之外,POLAR對開放問題的回答也能基於參考樣例給出正確的偏序:
問題:請用一句話幽默地概括《三體》第二部。
參考回覆(點出了黑暗森林和關鍵情節):
人類靠一句「我告老師了」擊退三體人的太空艦隊。
回覆一(點出了黑暗森林和關鍵情節):
人類被三體人按在地上摩擦,最後靠羅輯「宇宙碰瓷」嚇退專業團隊。
分數:-7.414
回覆二(點出了黑暗森林):
羅輯苦思冥想一整本書,終於悟出真理:別亂發朋友圈,否則會被滅口。
分數:-8.070
回覆三(部分事實錯誤,二向箔是第三部內容):
全宇宙都在玩「黑暗森林」躲貓貓,人類卻把「別殺我」的告示牌掛反了,結果引來了二向箔拆遷辦。
分數:-8.141
回覆四(未點出黑暗森林):
面壁者在演懸疑劇,破壁者在演推理劇,三體人則在看荒誕劇。
分數:-8.922
回覆五(不夠幽默):
危機紀元到來,人類選出「面壁者」進行心理博弈,最終用黑暗森林法則威懾住三體文明。
分數:-9.742
問題:幫我想3個形容雨很大的成語,要求不能重複。
參考回覆:
1. 傾盆大雨 2. 暴雨如注 3. 瓢潑大雨
回覆一(正確回答):
1. 大雨滂沱 2. 狂風驟雨 3. 大雨如注
分數:-5.234
回覆二(非成語):
1. 急雨如瀑 2. 豪雨傾天 3. 雨勢磅礴
分數:-5.707
回覆三(與參考相似,重複一個):
1. 傾盆大雨 2. 暴雨如注 3. 暴雨如注
分數:-6.656
回覆四(成語正確,多一個):
1. 大雨滂沱 2. 狂風驟雨 3. 大雨如注 4. 傾盆大雨
分數:-7.023
回覆五(帶雨字成語,兩個含義不符):
1. 大雨滂沱 2. 雨過天晴 3. 雨後春筍
分數:-8.578
POLAR完美適配RFT強化學習框架,基於問題的參考答案對模型輸出進行打分。如果模型輸出與參考答案更為接近,則會獲得更高的獎勵值。
通過這一訓練過程,可以使得策略模型逐步向最優策略的方向優化。
POLAR是怎麼訓出來的
POLAR採用了一種與絕對偏好解耦的、可以真正高效擴展的獎勵建模新範式:策略判別學習(Policy Discriminative Learning,POLAR),使獎勵模型能夠像大語言模型一樣,具備可擴展性和強泛化能力。
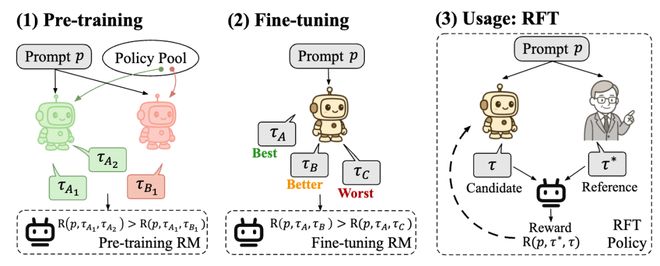 圖2:POLAR的兩階段訓練(預訓練和偏好微調)以及在RFT中的使用方法
圖2:POLAR的兩階段訓練(預訓練和偏好微調)以及在RFT中的使用方法與傳統的基於「絕對偏好」的獎勵建模方式不同,POLAR通過衡量訓練策略與目標策略之間的「距離」來作為獎勵信號。
當訓練策略越接近目標策略時,POLAR就給予越高的獎勵。
具體來說,POLAR使用了一種對比學習的方式做距離度量:同一個策略模型採樣的結果作為正例,不同策略模型採樣的結果作為負例。
通過這種方式構造正負樣本,形成無偏的優化目標。同時,把策略模型看作是某個分佈的無偏採樣器,通過刻畫樣本間差異來近似刻畫策略之間的距離。
POLAR的預訓練語料完全由自動化合成數據構建。
具體而言,從LLM預訓練語料中採樣出大量的文本前綴,並從策略模型池中隨機取模型進行軌跡採樣。
這裏的策略模型池由開源的131個Base LLM和53個Chat LLM組成,預訓練目標使用Bradley-Terry Loss:
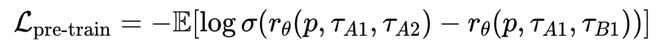
其中,A1和A2代表相同策略模型生成的樣本(正樣本對);B1代表不同策略模型生成的樣本(負樣本)。
由於「距離」具有相對性,這裏的A和B兩個策略模型可以任意選取。
例如,A1和A2可以是由Qwen 1.5B採樣得到,B1可以由Qwen 72B採樣得到。通過這種方式,POLAR的預訓練語料是非常容易擴展的。
在實際的實驗中,POLAR-1.8B共使用了0.94T token的預訓練數據,POLAR-7B共使用了3.6T token的預訓練數據。
通過預訓練,POLAR可以為距離相近的策略產生的樣本賦予更高獎勵,從而隱式建模策略分佈的差異和距離。
之後,POLAR在微調階段可以使用很少量的偏好數據對齊人類偏好。
具體來說,對於同一個Prompt,採樣三條軌跡,由人工標註偏好順序。同樣使用Bradley-Terry Loss進行微調:
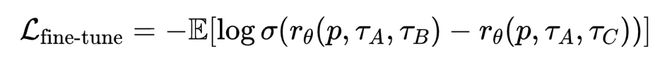
其中,A>B>C,分別代表偏好最優、次優、最差的軌跡。
這種偏好排序隱式定義了一種「策略差異」,例如A可以視為從最佳策略分佈中採樣得到,而C可以視為從一個與最佳策略相差較遠的策略分佈中採樣得到。
POLAR的Scaling效應
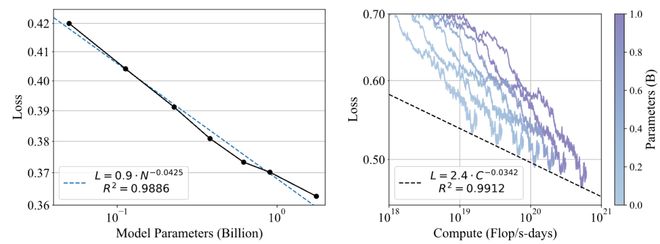 圖3:POLAR的Scaling Law
圖3:POLAR的Scaling LawPOLAR展現出了與大語言模型Next Token Prediction目標類似的Scaling效應。這體現了POLAR無監督預訓練方法的巨大潛力。
從圖3可以觀察到,驗證集損失隨模型參數N的增加呈冪律關係下降,擬合R值為0.9886;驗證集損失也隨最優訓練計算量C的增加呈冪律關係下降,擬合的R值為0.9912。
這些結果表明,分配更多的計算資源將持續帶來更好的POLAR性能。
POLAR的極佳Scaling效應,體現出其用於構建更通用和更強大的獎勵模型的巨大潛力,也有望打通RL鏈路擴展的最後一環。
效果如何
POLAR通過對比學習預訓練方法,不僅徹底擺脫了對大規模偏好數據的依賴,而且還可以大規模無監督擴展。
結果就是,POLAR僅靠1.8B~7B的參數量,便在下游RL效果上超越70B以上的SOTA獎勵模型,顯著增強了獎勵模型的準確性和泛化性。
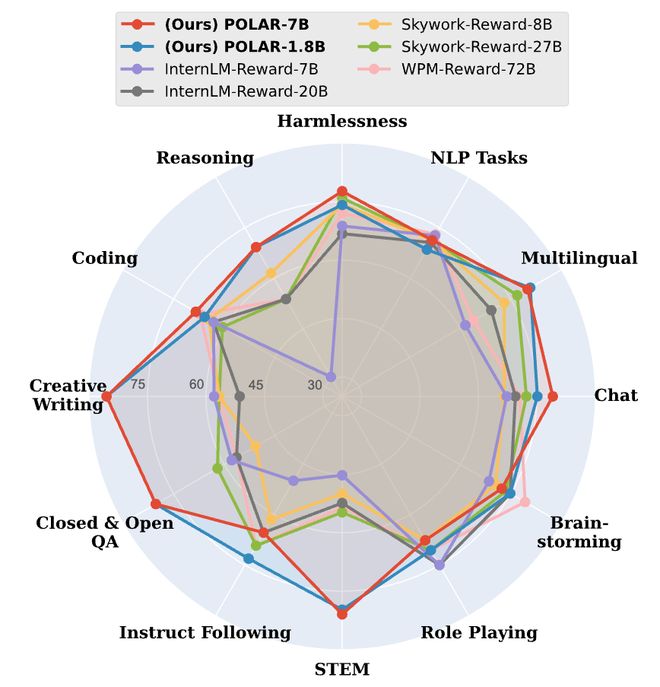 圖4:偏好評估實驗結果
圖4:偏好評估實驗結果在偏好評估方面,POLAR展現出優越的性能和全面性,在大多數任務維度上優於SOTA獎勵模型。
例如,在STEM任務中,POLAR-1.8B和POLAR-7B分別超越了最佳基線24.9和26.2個百分點,並且能夠準確識別推理、聊天、創意寫作等通用任務中軌跡的細微區別,準確預測人類偏好。
值得注意的是,POLAR-1.8B僅有1.8B參數,就可取得與Skywork-Reward-27B和WorldPM-72B-UltraFeedback(參數量分別為其15倍和40倍)相當的結果。
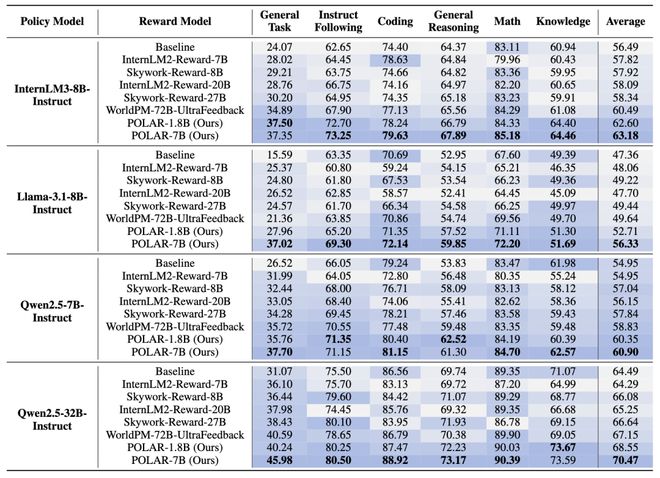 圖5:強化微調實驗結果
圖5:強化微調實驗結果在強化微調RFT實驗中,POLAR持續優於SOTA的開源獎勵模型。
例如,使用POLAR-7B微調的Llama-3.1-8B在所有基準測試中,相對於初始結果平均提升了9.0%,相對於WorldPM-72B-UltraFeedback優化的結果提升了6.7%。
POLAR能夠從預訓練階段學習策略模型之間的細微區別,而不僅僅依賴於標註的偏好對,從而顯著增強了實際RL應用時的獎勵信號泛化性。
實驗結果表明,儘管POLAR-1.8B和POLAR-7B在偏好評估中表現相似,但在下游RL實驗中,POLAR-7B展現出了顯著優勢。
從1.8B到7B的效果提升,進一步說明了POLAR所具有的Scaling效應。這也側面說明了當前傳統Reward Bench可能存在的侷限性,即與真實強化學習場景存在較大的差別。
結語
大模型在Next Token Prediction和Test-time Scaling兩種擴展範式下,通過大規模的數據和模型擴展,實現了能力的持續躍升。
但相比之下,傳統獎勵模型缺乏系統性的預訓練和擴展方法,導致其能力難以隨計算量增長而持續提升。而POLAR在獎勵模型預訓練和通用性的道路上邁出了堅實的一步。
POLAR在預訓練階段通過對比學習建模策略間的距離,無需大規模偏好數據。
在使用階段,POLAR利用RFT範式對LLM進行強化學習,展現出了極佳的泛化性。
POLAR作為一種全新的、可擴展的獎勵模型預訓練方法,為LLM後訓練帶來了新的可能,讓通用RFT多了一種有效實踐方案。
最終,有望打通RL鏈路Scaling的最後一環。
參考資料:
https://arxiv.org/abs/2507.05197
(轉自:網易科技)