炒股就看金麒麟分析師研報,權威,專業,及時,全面,助您挖掘潛力主題機會!

機器之心報道
編輯:澤南、+0
我們知道,大語言模型(LLM)是通過預測對話的下一個單詞的形式產生輸出的。由此產生的對話、推理甚至創作能力已經接近人類智力水平。
但目前看起來,ChatGPT 等大模型與真正的 AGI 還有肉眼可見的差距。如果我們能夠完美地模擬環境中每一個可能的未來,是否就可以創造出強大的 AI 了?回想一下人類:與 ChatGPT 不同,人類的能力組成有具體技能、深度複雜能力的區分。

模擬推理的案例:一個人(可能是自私的)通過心理模擬多個可能結果來幫助一個哭泣的人。
人類可以執行廣泛的複雜任務,所有這些任務都基於相同的人類大腦認知架構。是否存在一個人工智能系統也能完成所有這些任務呢?
近日,來自卡耐基梅隆大學(CMU)、沙特穆罕默德・本・扎耶德人工智能大學(MBZUAI)、加州大學聖迭戈分校(UCSD)的研究者們探討了當前 AI 領域最前沿方向 —— 世界模型(World Models)的侷限性。

研究人員指出了構建、訓練世界模型的五個重點方面:1)識別並準備包含目標世界信息的訓練數據;2)採用一種通用表徵空間來表示潛在世界狀態,其含義可能比直接觀察到的數據更為豐富;3)設計能夠有效對錶徵進行推理的架構;4)選擇能正確指導模型訓練的目標函數;5)確定如何在決策系統中運用世界模型。
基於此,作者提出了一種全新的世界模型架構 PAN(Physical, Agentic, and Nested AGI System),基於分層、多級和混合連續 / 離散表示,並採用了生成式和自監督學習框架。
研究者表示,PAN 世界模型的詳細信息及結果會很快在另一篇論文中展示。MBZUAI 校長、CMU 教授邢波在論文提交後轉推了這篇論文,並表示PAN 模型即將發布 27B 的第一版,這將是第一個可運行的通用世界模擬器。
對世界模型的批判
一個以 Yann LeCun 為代表的學派在構建世界模型的五個維度 ——數據、表徵、架構、目標和用途
該學派還為世界模型提出瞭如圖 4 所示的替代框架,其核心思想可以概括為「預測下一個表徵」,而非「預測下一個數據」:


作者的觀點:
儘管視頻等感官數據量大,但其信息冗餘度高、語義含量低。相比之下,自然語言是人類經驗的高度壓縮和抽象形式,它不僅能描述物理現實,還能編碼如「正義」、「動機」等無法直接觀察的抽象概念,並承載了人類的集體知識。
因此,通往通用人工智能的道路不能偏重於任何單一模態。視頻、文本、音頻等不同模態反映了經驗的不同層面:視頻捕捉物理動態,而文本編碼抽象概念。一個成功的世界模型必須融合所有這些分層的數據,才能全面理解世界並處理多樣化的任務,忽略任何一個層面都會導致關鍵信息的缺失。
表示:連續?離散?還是兩者兼有?
待批判的主張:世界狀態應由連續嵌入來表徵,而非離散的詞元,以便於進行基於梯度的優化。
作者的觀點:
僅用連續嵌入來表示世界狀態是脆弱的,因為它難以應對感官數據中固有的噪聲和高變異性 。人類認知通過將原始感知歸類為離散概念來解決此問題,而語言就是這些離散概念的載體,為抽象和推理提供了穩定、可組合的基礎 。
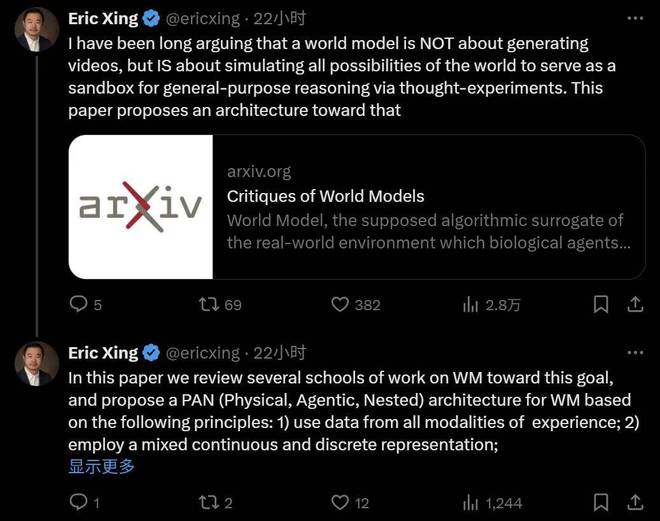
理論上,離散符號序列(即「語言」)足以表達連續數據中任意精度的信息,並且如圖 5 所示,通過增加序列長度來擴展其表達能力,遠比擴大詞彙表更高效 。
因此,最佳路徑是採用混合表示。這種方法結合了離散符號的穩健性、可解釋性和結構化推理能力,同時利用連續嵌入來捕捉細微的感官細節,從而實現優勢互補 。
架構:自迴歸生成並非敵人
待批判的主張:自迴歸生成模型(例如 LLM)註定會失敗,因為它們最終必然會犯錯,並且無法對結果的不確定性進行建模。
作者的觀點:
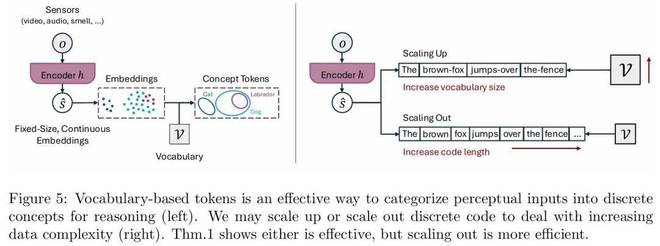
如論文圖 6(左半部分)所示,這種被批判的「編碼器 - 編碼器架構」在潛在空間中進行「確定性的下一嵌入預測」 ,但它在功能上仍是自迴歸的,需要遞歸地預測未來狀態,因此並未真正避免其聲稱要解決的誤差累積問題 。更關鍵的是,通過移除解碼器來避免重構觀察數據,會導致模型學習到的潛在表示與真實世界脫節,難以診斷,甚至可能崩潰到無意義的解 。
更好的方案不是拋棄生成模型,而是採用分層的生成式潛在預測(GLP)架構,這在圖 6(右半部分)中得到了展示 。該架構包含一個解碼器用於「生成式重構」 ,其核心是一個由「增強的 LLM + 擴散模型」構成的分層世界模型 。這種設計既能通過生成式解碼器確保模型與真實數據掛鉤,又能通過分層抽象來隔離底層噪聲,實現更魯棒、更強大的推理 。
目標:在數據空間還是潛在空間中學習?
待批判的主張:概率性的數據重構目標(例如編碼器 - 解碼器方案)是行不通的,因為這類目標難以處理,並且會迫使模型去預測不相關的細節。
作者的觀點:
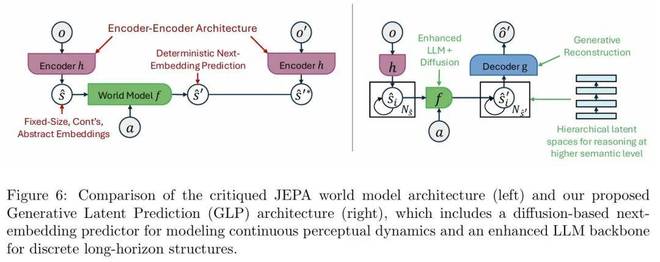
如圖 7(左半部分)所示,在潛在空間計算重構損失的方法,理論上存在「平凡解崩潰」的風險 ,即模型可以輕易將所有輸入映射為常數來使損失為零,從而什麼也學不到 。為了防止崩潰,這類模型不得不依賴複雜且難以調試的正則化項。
相比之下,基於數據空間的生成式重構目標函數,如圖 7(右半部分)所示,要求模型預測並重構出真實的下一刻觀察數據,並通過「生成式損失」進行監督 。這從根本上避免了崩潰問題 ,為模型提供了穩定、可靠且有意義的監督信號 。
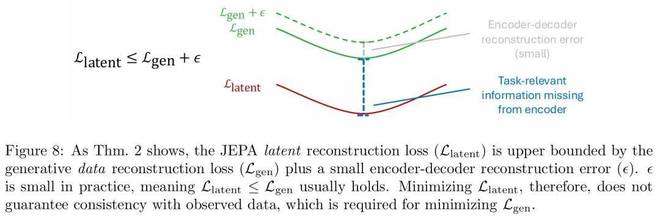
圖 8 進一步從理論上解釋了,潛在空間損失只是生成式損失的一個寬鬆的「上界代理」 。這意味着,即使一個模型的潛在損失很低,也不能保證它在真實世界中的預測是準確的,因為它可能遺漏了對任務至關重要的信息 。
用途:模型預測控制(MPC)還是強化學習(RL)?
待批判的主張:世界模型應該用於模型預測控制(MPC),而不是強化學習(RL)框架,因為後者需要過多的試驗次數。
作者的觀點:
如論文圖 9(左半部分)所示,MPC 在決策時需要反覆進行「模擬下一個潛在狀態」和「基於目標優化動作」的循環 ,這導致其計算開銷巨大,難以應對快速變化的環境,並且通常視野有限,難以進行長時程戰略規劃 。

強化學習(RL)提供了一個更通用、靈活且可擴展的範式,如圖 9(右半部分)所示 。它將世界模型作為一個「模擬器」,讓一個獨立的智能體模型在其中探索並學習 。這個過程是用於「基於目標用 RL 優化智能體模型」 ,將巨大的計算成本從「決策時」轉移到了「訓練時」 。這使智能體不僅能快速行動,還能通過學習積累長期回報,進行更具戰略性的長遠規劃 。
PAN 世界模型
基於對現有世界模型框架的批評,作者得出了關於通用世界模型設計原則。PAN 架構基於以下設計原則:1)涵蓋所有體驗模式的數據;2)結合連續與離散表示;3)基於增強的大語言模型(LLM)主幹的分層生成建模,以及生成式潛在預測架構;4)以觀察數據為基礎的生成損失;5)利用世界模型通過強化學習(RL)來模擬體驗,以訓練智能體。
一個真正多功能且通用的世界模型必須基於能夠反映現實世界推理需求全部複雜性的任務。總體而言,PAN 通過其分層、多級和混合表示架構,以及編碼器 - 解碼器管道,將感知、行動、信念、模擬信念和模擬世界等要素串聯起來。作為通用生成模型,PAN 能夠模擬現實世界中可操作的可能性,使智能體能夠進行有目的的推理。PAN 並不迴避原始感知輸入的多樣性,而是將其模塊化和組織化,從而實現對每一層體驗的更豐富內部模擬,增強智能體的推理和規劃能力。
在訓練時,PAN 需要首先通過自我監督(例如使用大語言模型處理文本數據,使用擴散模型處理視頻數據)獨立預訓練每個模塊。這些特定於模態和級別的模塊在後訓練階段通過多模態數據、級聯嵌入和梯度傳播進行對齊或整合。
PAN 架構的一大優勢在於其數據處理效率,這得益於其採用的多尺度和分層的世界觀。事實上,PAN 的預訓練 - 對齊 / 集成策略能夠充分利用感覺信息簡歷知識基礎,利用 LLM 促進跨模態的泛化能力。
作者概述了一種利用世界模型進行模擬推理的智能體架構。PAN 自然地融入這一範式,不僅作為視頻生成器,更作為一個豐富的內部沙盒,用於模擬、實驗和預見未來。
最後,作者認為,世界模型不是關於視頻或虛擬現實的生成,而是關於模擬現實世界中所有可能性,因此,目前的範式和努力仍然是原始的。作者希望,通過批判性、分析性和建設性的剖析一些關於如何構建世界模型的流行思想,以及 PAN 架構,能夠激發理論和實施更強大世界模型的進一步發展。
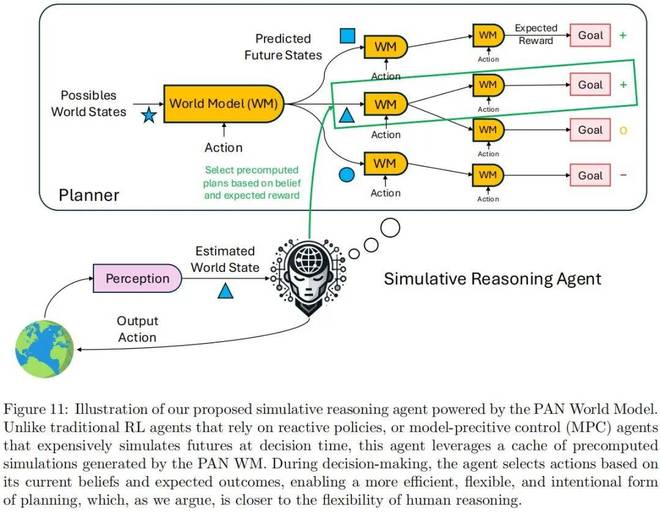
由 PAN 世界模型驅動的模擬推理智能體。與依賴反應策略的傳統強化學習智能體,或在決策時刻昂貴地模擬未來的模型預測控制(MPC)智能體不同,其利用了 PAN 生成的預計算模擬緩存。在決策過程中,智能體根據當前的信念和預期結果選擇行動,從而實現更高效、靈活和有目的的規劃方式。這種方式更接近人類推理的靈活性。
更詳細內容,請查閱論文原文。
(轉自:網易科技)